
This publish is the second a part of the GPT-OSS sequence specializing in mannequin customization with Amazon SageMaker AI. In Half 1, we demonstrated fine-tuning GPT-OSS fashions utilizing open supply Hugging Face libraries with SageMaker coaching jobs, which helps distributed multi-GPU and multi-node configurations, so you may spin up high-performance clusters on demand.
On this publish, we present how one can fine-tune GPT OSS fashions on utilizing recipes on SageMaker HyperPod and Coaching Jobs. SageMaker HyperPod recipes assist you to get began with coaching and fine-tuning in style publicly out there basis fashions (FMs) comparable to Meta’s Llama, Mistral, and DeepSeek in simply minutes, utilizing both SageMaker HyperPod or coaching jobs. The recipes present pre-built, validated configurations that alleviate the complexity of organising distributed coaching environments whereas sustaining enterprise-grade efficiency and scalability for fashions. We define steps to fine-tune the GPT-OSS mannequin on a multilingual reasoning dataset, HuggingFaceH4/Multilingual-Pondering, so GPT-OSS can deal with structured, chain-of-thought (CoT) reasoning throughout a number of languages.
Resolution overview
This resolution makes use of SageMaker HyperPod recipes to run a fine-tuning job on HyperPod utilizing Amazon Elastic Kubernetes Service (Amazon EKS) orchestration or coaching jobs. Recipes are processed via the SageMaker HyperPod recipe launcher, which serves because the orchestration layer chargeable for launching a job on the corresponding structure comparable to SageMaker HyperPod (Slurm or Amazon EKS) or coaching jobs. To study extra, see SageMaker HyperPod recipes.
For particulars on fine-tuning the GPT-OSS mannequin, see High quality-tune OpenAI GPT-OSS fashions on Amazon SageMaker AI utilizing Hugging Face libraries.
Within the following sections, we focus on the conditions for each choices, after which transfer on to the information preparation. The ready knowledge is saved to Amazon FSx for Lustre, which is used because the persistent file system for SageMaker HyperPod, or Amazon Easy Storage Service (Amazon S3) for coaching jobs. We then use recipes to submit the fine-tuning job, and eventually deploy the educated mannequin to a SageMaker endpoint for testing and evaluating the mannequin. The next diagram illustrates this structure.
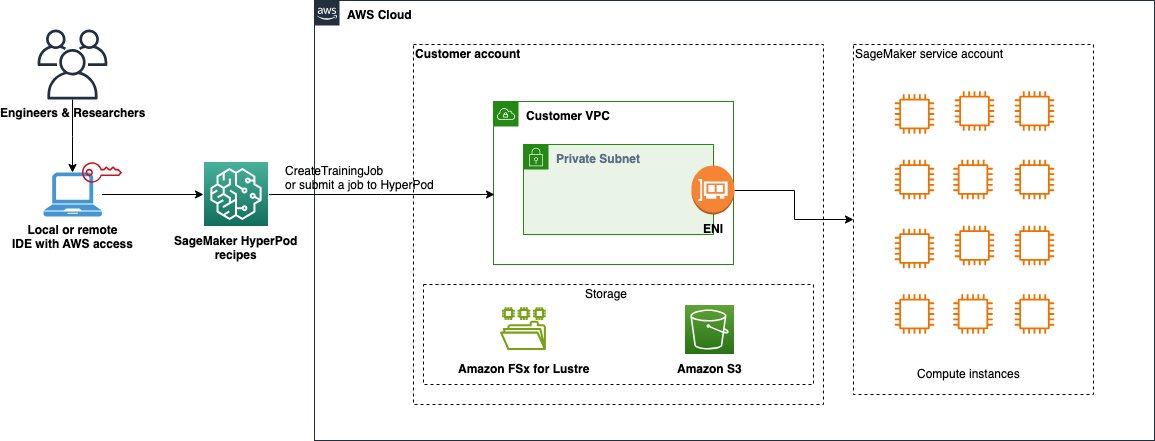
Stipulations
To comply with alongside, it’s essential to have the next conditions:
- An area growth atmosphere with AWS credentials configured for creating and accessing SageMaker sources, or a distant atmosphere comparable to Amazon SageMaker Studio.
- For SageMaker HyperPod fine-tuning, full the next:
- For fine-tuning the mannequin utilizing SageMaker coaching jobs, it’s essential to have one ml.p5.48xlarge occasion (with 8 x NVIDIA H100 GPUs) for coaching jobs utilization. If you happen to don’t have enough limits, request the next SageMaker quotas on the Service Quotas console: P5 occasion (ml.p5.48xlarge) for coaching jobs (ml.p5.48xlarge for cluster utilization): 1.
It would take as much as 24 hours for these limits to be authorised. It’s also possible to use SageMaker coaching plans to order these cases for a particular timeframe and use case (cluster or coaching jobs utilization). For extra particulars, see Reserve coaching plans to your coaching jobs or HyperPod clusters.
Subsequent, use your most well-liked growth atmosphere to arrange the dataset for fine-tuning. Yow will discover the complete code within the Generative AI utilizing Amazon SageMaker repository on GitHub.
Information tokenization
We use the Hugging FaceH4/Multilingual-Pondering dataset, which is a multilingual reasoning dataset containing CoT examples translated into languages comparable to French, Spanish, and German. The recipe helps a sequence size of 4,000 tokens for the GPT-OSS 120B mannequin. The next instance code demonstrates learn how to tokenize the multilingual-thinking dataset. The recipe accepts knowledge in Hugging Face format (arrow). After it’s tokenized, it can save you the processed dataset to disk.
Now that you’ve got ready and tokenized the dataset, you may fine-tune the GPT-OSS mannequin in your dataset, utilizing both SageMaker HyperPod or coaching jobs. SageMaker coaching jobs are perfect for one-off or periodic coaching workloads that want non permanent compute sources, making it a completely managed, on-demand expertise to your coaching wants. SageMaker HyperPod is perfect for steady growth and experimentation, offering a persistent, preconfigured, and failure-resilient cluster. Relying in your selection, skip to the suitable part for subsequent steps.
High quality-tune the mannequin utilizing SageMaker HyperPod
To fine-tune the mannequin utilizing HyperPod, begin by organising the digital atmosphere and putting in the required dependencies to execute the coaching job on the EKS cluster. Be certain that the cluster is InService earlier than continuing, and also you’re utilizing Python 3.9 or better in your growth atmosphere.
Subsequent, obtain and arrange the SageMaker HyperPod recipes repository:
Now you can use the SageMaker HyperPod recipe launch scripts to submit your coaching job. Utilizing the recipe entails updating the k8s.yaml configuration file and executing the launch script.
In recipes_collection/cluster/k8s.yaml, replace the persistent_volume_claims part. It mounts the FSx declare to the /fsx listing of every computing pod:
SageMaker HyperPod recipes present a launch script for every recipe inside the launcher_scripts listing. To fine-tune the GPT-OSS-120B mannequin, replace the launch scripts situated at launcher_scripts/gpt_oss/run_hf_gpt_oss_120b_seq4k_gpu_lora.sh and replace the cluster_type parameter.
The up to date launch script ought to look just like the next code when working SageMaker HyperPod with Amazon EKS. Guarantee that cluster=k8s and cluster_type=k8s are up to date within the launch script:
When the script is prepared, you may launch fine-tuning of the GPT OSS 120B mannequin utilizing the next code:
After submitting a job for fine-tuning, you should use the next command to confirm profitable submission. It is best to be capable to see the pods working in your cluster:
To test logs for the job, you should use the kubectl logs command:
kubectl logs -f hf-gpt-oss-120b-lora-h2cwd-worker-0
It is best to be capable to see the next logs when the coaching begins and completes. One can find the checkpoints written to the /fsx/experiment/checkpoints folder.
When the coaching is full, the ultimate merged mannequin might be discovered within the experiment listing path you outlined within the launcher script underneath /fsx/experiment/checkpoints/peft_full/steps_50/final-model.
High quality-tune utilizing SageMaker coaching jobs
It’s also possible to use recipes straight with SageMaker coaching jobs utilizing the SageMaker Python SDK. The coaching jobs routinely spin up the compute, load the enter knowledge, run the coaching script, save the mannequin to your output location, and tear down the cases, for a clean coaching expertise.
The next code snippet reveals learn how to use recipes with the PyTorch estimator. You should use the training_recipe parameter to specify the coaching or fine-tuning recipe for use, and recipe_overrides for any parameters that want substitute. For coaching jobs, replace the enter, output, and outcomes directories to areas in /decide/ml as required by SageMaker coaching jobs.
After the job is submitted, you may monitor the standing of your coaching job on the SageMaker console, by selecting Coaching jobs underneath Coaching within the navigation pane. Select the coaching job that begins with gpt-oss-recipe to view its particulars and logs. When the coaching job is full, the outputs will probably be saved to an S3 location. You may get the situation of the output artifacts from the S3 mannequin artifact part on the job particulars web page.
Run inference
After you fine-tune your GPT-OSS mannequin with SageMaker recipes on both SageMaker coaching jobs or SageMaker HyperPod, the output is a personalized mannequin artifact that merges the bottom mannequin with the personalized PEFT adapters. This last mannequin is saved in Amazon S3 and might be deployed straight from Amazon S3 to SageMaker endpoints for real-time inference.
To serve GPT-OSS fashions, it’s essential to have the most recent vLLM containers (v0.10.1 or later). A full checklist of vllm-openai Docker picture variations is on the market on Docker hub.
The steps to deploy your fine-tuned GPT-OSS mannequin are outlined on this part.
Construct the most recent GPT-OSS container to your SageMaker endpoint
If you happen to’re deploying the mannequin from SageMaker Studio utilizing JupyterLab or the Code Editor, each environments include Docker preinstalled. Just be sure you’re utilizing the SageMaker Distribution picture v3.0 or later for compatibility.You possibly can construct your deployment container by working the next instructions:
If you happen to’re working these instructions from a neighborhood terminal or different atmosphere, merely omit the %%bash line and run the instructions as normal shell instructions.
The construct.sh script is chargeable for routinely constructing and pushing a vllm-openai container that’s optimized for SageMaker endpoints. After it’s constructed, the customized SageMaker endpoint suitable vllm picture is pushed to Amazon Elastic Container Registry (Amazon ECR). SageMaker endpoints can then pull this picture from Amazon ECR at runtime to spin up the container for inference.
The next is an instance of the construct.sh script:
The Dockerfile defines how we convert an open supply vLLM Docker picture right into a SageMaker hosting-compatible picture. This entails extending the bottom vllm-openai picture, including the serve entrypoint script, and making it executable. See the next instance Dockerfile:
The serve script acts as a translation layer between SageMaker internet hosting conventions and the vLLM runtime. You possibly can preserve the identical deployment workflow you’re accustomed to when internet hosting fashions on SageMaker endpoints, whereas routinely changing SageMaker-specific configurations into the format anticipated by vLLM.
Key factors to notice about this script:
- It enforces the usage of port 8080, which SageMaker requires for inference containers
- It dynamically interprets atmosphere variables prefixed with
OPTION_into CLI arguments for vLLM (for instance,OPTION_MAX_MODEL_LEN=4096modifications to--max-model-len 4096) - It prints the ultimate set of arguments for visibility
- It lastly launches the vLLM API server with the translated arguments
The next is an instance serve script:
Host personalized GPT-OSS as a SageMaker real-time endpoint
Now you may deploy your fine-tuned GPT-OSS mannequin utilizing the ECR picture URI you constructed within the earlier step. On this instance, the mannequin artifacts are saved securely in an S3 bucket, and SageMaker will obtain them into the container at runtime.Full the next configurations:
- Set
model_datato level to the S3 prefix the place your mannequin artifacts are situated - Set the
OPTION_MODELatmosphere variable to/decide/ml/mannequin, which is the place SageMaker mounts the mannequin contained in the container - (Non-obligatory) If you happen to’re serving a mannequin from Hugging Face Hub as an alternative of Amazon S3, you may set
OPTION_MODELon to the Hugging Face mannequin ID as an alternative
The endpoint startup may take a number of minutes because the mannequin artifacts are downloaded and the container is initialized.The next is an instance deployment code:
Pattern inference
After your endpoint is deployed and within the InService state, you may invoke your fine-tuned GPT-OSS mannequin utilizing the SageMaker Python SDK.
The next is an instance predictor setup:
The modified vLLM container is absolutely suitable with the OpenAI-style messages enter format, making it easy to ship chat-style requests:
You have got efficiently deployed and invoked your customized fine-tuned GPT-OSS mannequin on SageMaker real-time endpoints, utilizing the vLLM framework for optimized, low-latency inference. Yow will discover extra GPT-OSS internet hosting examples within the OpenAI gpt-oss examples GitHub repo.
Clear up
To keep away from incurring extra fees, full the next steps to scrub up the sources used on this publish:
- Delete the SageMaker endpoint:
pretrained_predictor.delete_endpoint()
- If you happen to created a SageMaker HyperPod cluster for the needs of this publish, delete the cluster by following the directions in Deleting a SageMaker HyperPod cluster.
- Clear up the FSx for Lustre quantity if it’s not wanted by following directions in Deleting a file system.
- If you happen to used coaching jobs, the coaching cases are routinely deleted when the roles are full.
Conclusion
On this publish, we confirmed learn how to fine-tune OpenAI’s GPT-OSS fashions (gpt-oss-120b and gpt-oss-20b) on SageMaker AI utilizing SageMaker HyperPod recipes. We mentioned how SageMaker HyperPod recipes present a robust but accessible resolution for organizations to scale their AI mannequin coaching capabilities with giant language fashions (LLMs) together with GPT-OSS, utilizing both a persistent cluster via SageMaker HyperPod, or an ephemeral cluster utilizing SageMaker coaching jobs. The structure streamlines advanced distributed coaching workflows via its intuitive recipe-based method, lowering setup time from weeks to minutes. We additionally confirmed how these fine-tuned fashions might be seamlessly deployed to manufacturing utilizing SageMaker endpoints with vLLM optimization, offering enterprise-grade inference capabilities with OpenAI-compatible APIs. This end-to-end workflow, from coaching to deployment, helps organizations construct and serve customized LLM options whereas utilizing the scalable infrastructure of AWS and complete ML platform capabilities of SageMaker.
To start utilizing the SageMaker HyperPod recipes, go to the Amazon SageMaker HyperPod recipes GitHub repo for complete documentation and instance implementations. If you happen to’re all for exploring the fine-tuning additional, the Generative AI utilizing Amazon SageMaker GitHub repo has the required code and notebooks. Our crew continues to broaden the recipe ecosystem based mostly on buyer suggestions and rising ML traits, ensuring that you’ve got the instruments wanted for profitable AI mannequin coaching.
Particular because of everybody who contributed to the launch: Hengzhi Pei, Zach Kimberg, Andrew Tian, Leonard Lausen, Sanjay Dorairaj, Manish Agarwal, Sareeta Panda, Chang Ning Tsai, Maxwell Nuyens, Natasha Sivananjaiah, and Kanwaljit Khurmi.
Concerning the authors
 Durga Sury is a Senior Options Architect at Amazon SageMaker, the place she helps enterprise clients construct safe and scalable AI/ML programs. When she’s not architecting options, yow will discover her having fun with sunny walks together with her canine, immersing herself in homicide thriller books, or catching up on her favourite Netflix reveals.
Durga Sury is a Senior Options Architect at Amazon SageMaker, the place she helps enterprise clients construct safe and scalable AI/ML programs. When she’s not architecting options, yow will discover her having fun with sunny walks together with her canine, immersing herself in homicide thriller books, or catching up on her favourite Netflix reveals.
 Pranav Murthy is a Senior Generative AI Information Scientist at AWS, specializing in serving to organizations innovate with Generative AI, Deep Studying, and Machine Studying on Amazon SageMaker AI. Over the previous 10+ years, he has developed and scaled superior pc imaginative and prescient (CV) and pure language processing (NLP) fashions to sort out high-impact issues—from optimizing international provide chains to enabling real-time video analytics and multilingual search. When he’s not constructing AI options, Pranav enjoys taking part in strategic video games like chess, touring to find new cultures, and mentoring aspiring AI practitioners. Yow will discover Pranav on LinkedIn.
Pranav Murthy is a Senior Generative AI Information Scientist at AWS, specializing in serving to organizations innovate with Generative AI, Deep Studying, and Machine Studying on Amazon SageMaker AI. Over the previous 10+ years, he has developed and scaled superior pc imaginative and prescient (CV) and pure language processing (NLP) fashions to sort out high-impact issues—from optimizing international provide chains to enabling real-time video analytics and multilingual search. When he’s not constructing AI options, Pranav enjoys taking part in strategic video games like chess, touring to find new cultures, and mentoring aspiring AI practitioners. Yow will discover Pranav on LinkedIn.
 Sumedha Swamy is a Senior Supervisor of Product Administration at Amazon Internet Providers (AWS), the place he leads a number of areas of the Amazon SageMaker, together with SageMaker Studio – the industry-leading built-in growth atmosphere for machine studying, developer and administrator experiences, AI infrastructure, and SageMaker SDK.
Sumedha Swamy is a Senior Supervisor of Product Administration at Amazon Internet Providers (AWS), the place he leads a number of areas of the Amazon SageMaker, together with SageMaker Studio – the industry-leading built-in growth atmosphere for machine studying, developer and administrator experiences, AI infrastructure, and SageMaker SDK.
 Dmitry Soldatkin is a Senior AI/ML Options Architect at Amazon Internet Providers (AWS), serving to clients design and construct AI/ML options. Dmitry’s work covers a variety of ML use instances, with a major curiosity in Generative AI, deep studying, and scaling ML throughout the enterprise. He has helped corporations in lots of industries, together with insurance coverage, monetary providers, utilities, and telecommunications. You possibly can join with Dmitry on LinkedIn.
Dmitry Soldatkin is a Senior AI/ML Options Architect at Amazon Internet Providers (AWS), serving to clients design and construct AI/ML options. Dmitry’s work covers a variety of ML use instances, with a major curiosity in Generative AI, deep studying, and scaling ML throughout the enterprise. He has helped corporations in lots of industries, together with insurance coverage, monetary providers, utilities, and telecommunications. You possibly can join with Dmitry on LinkedIn.
 Arun Kumar Lokanatha is a Senior ML Options Architect with the Amazon SageMaker crew. He focuses on giant language mannequin coaching workloads, serving to clients construct LLM workloads utilizing SageMaker HyperPod, SageMaker coaching jobs, and SageMaker distributed coaching. Exterior of labor, he enjoys working, mountaineering, and cooking.
Arun Kumar Lokanatha is a Senior ML Options Architect with the Amazon SageMaker crew. He focuses on giant language mannequin coaching workloads, serving to clients construct LLM workloads utilizing SageMaker HyperPod, SageMaker coaching jobs, and SageMaker distributed coaching. Exterior of labor, he enjoys working, mountaineering, and cooking.
 Anirudh Viswanathan is a Senior Product Supervisor, Technical, at AWS with the SageMaker crew, the place he focuses on Machine Studying. He holds a Grasp’s in Robotics from Carnegie Mellon College and an MBA from the Wharton Faculty of Enterprise. Anirudh is a named inventor on greater than 50 AI/ML patents. He enjoys long-distance working, exploring artwork galleries, and attending Broadway reveals.
Anirudh Viswanathan is a Senior Product Supervisor, Technical, at AWS with the SageMaker crew, the place he focuses on Machine Studying. He holds a Grasp’s in Robotics from Carnegie Mellon College and an MBA from the Wharton Faculty of Enterprise. Anirudh is a named inventor on greater than 50 AI/ML patents. He enjoys long-distance working, exploring artwork galleries, and attending Broadway reveals.



{kind=link}