This put up is a joint collaboration between Salesforce and AWS and is being cross-published on each the Salesforce Engineering Weblog and the AWS Machine Studying Weblog.
The Salesforce AI Platform Mannequin Serving staff is devoted to creating and managing companies that energy massive language fashions (LLMs) and different AI workloads inside Salesforce. Their fundamental focus is on mannequin onboarding, offering clients with a sturdy infrastructure to host a wide range of ML fashions. Their mission is to streamline mannequin deployment, improve inference efficiency and optimize price effectivity, guaranteeing seamless integration into Agentforce and different functions requiring inference. They’re dedicated to enhancing the mannequin inferencing efficiency and general effectivity by integrating state-of-the-art options and collaborating with main know-how suppliers, together with open supply communities and cloud companies corresponding to Amazon Internet Companies (AWS) and constructing it right into a unified AI platform. This helps guarantee Salesforce clients obtain probably the most superior AI know-how accessible whereas optimizing the cost-performance of the serving infrastructure.
On this put up, we share how the Salesforce AI Platform staff optimized GPU utilization, improved useful resource effectivity and achieved price financial savings utilizing Amazon SageMaker AI, particularly inference parts.
The problem with internet hosting fashions for inference: Optimizing compute and cost-to-serve whereas sustaining efficiency
Deploying fashions effectively, reliably, and cost-effectively is a important problem for organizations of all sizes. The Salesforce AI Platform staff is liable for deploying their proprietary LLMs corresponding to CodeGen and XGen on SageMaker AI and optimizing them for inference. Salesforce has a number of fashions distributed throughout single mannequin endpoints (SMEs), supporting a various vary of mannequin sizes from a couple of gigabytes (GB) to 30 GB, every with distinctive efficiency necessities and infrastructure calls for.
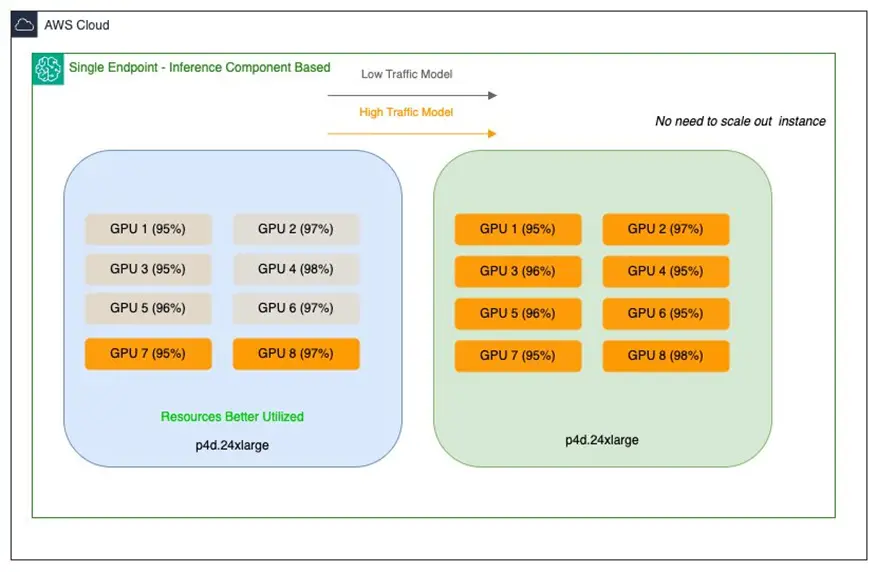
The staff confronted two distinct optimization challenges. Their bigger fashions (20–30 GB) with decrease visitors patterns had been working on high-performance GPUs, leading to underutilized multi-GPU cases and inefficient useful resource allocation. In the meantime, their medium-sized fashions (roughly 15 GB) dealing with high-traffic workloads demanded low-latency, high-throughput processing capabilities. These fashions usually incurred increased prices because of over-provisioning on comparable multi-GPU setups. Right here’s a pattern illustration of Salesforce’s massive and medium SageMaker endpoints and the place assets are under-utilized:
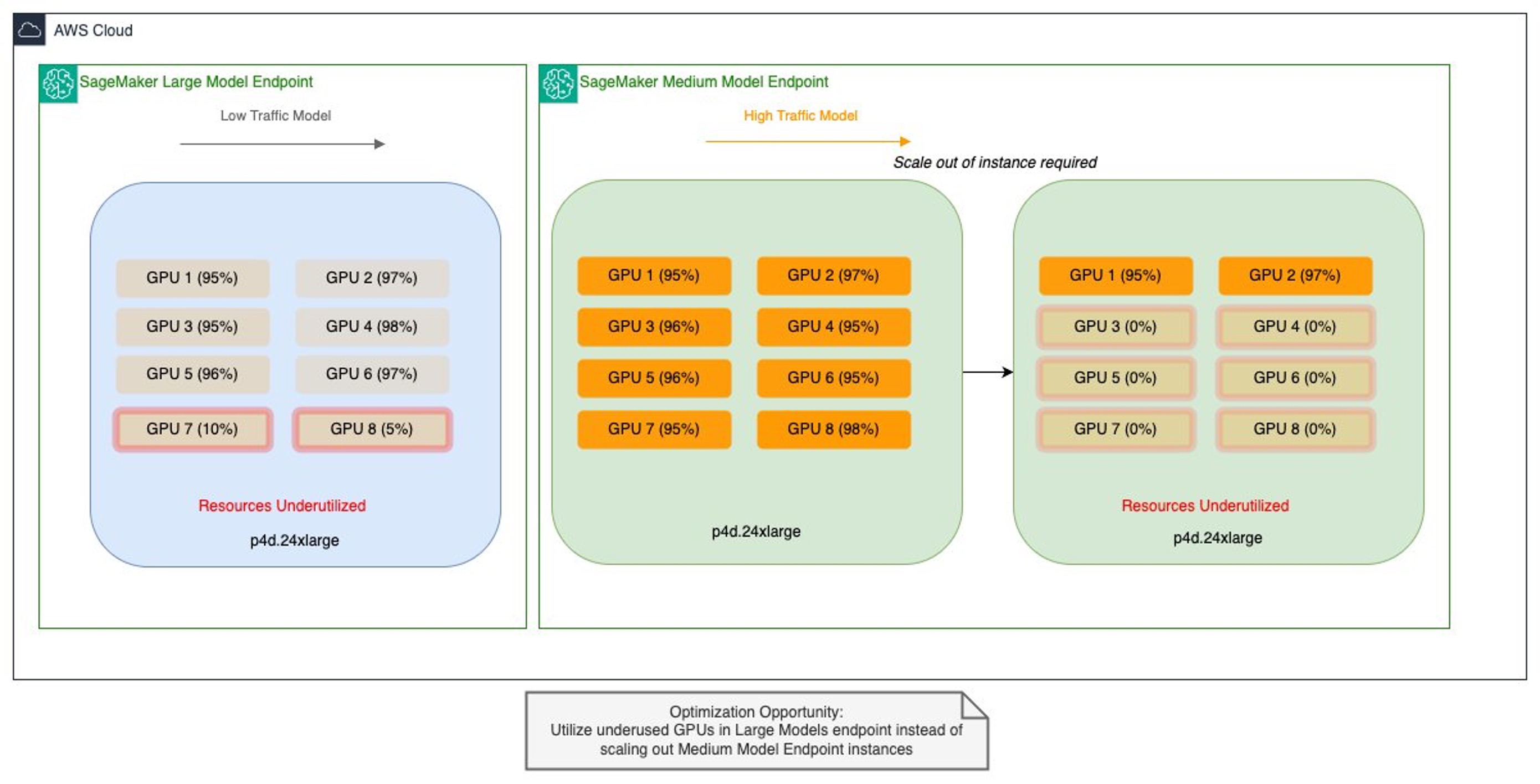
Working on Amazon EC2 P4d cases at this time, with plans to make use of the most recent technology P5en cases geared up with NVIDIA H200 Tensor Core GPUs, the staff sought an environment friendly useful resource optimization technique that will maximize GPU utilization throughout their SageMaker AI endpoints whereas enabling scalable AI operations and extracting most worth from their high-performance cases—all with out compromising efficiency or over-provisioning {hardware}.
This problem displays a important stability that enterprises should strike when scaling their AI operations: maximizing the efficiency of refined AI workloads whereas optimizing infrastructure prices and useful resource effectivity. Salesforce wanted an answer that will not solely resolve their speedy deployment challenges but in addition create a versatile basis able to supporting their evolving AI initiatives.
To deal with these challenges, the Salesforce AI Platform staff used SageMaker AI inference parts that enabled deployment of a number of basis fashions (FMs) on a single SageMaker AI endpoint with granular management over the variety of accelerators and reminiscence allocation per mannequin. This helps enhance useful resource utilization, reduces mannequin deployment prices, and allows you to scale endpoints collectively together with your use instances.
Answer: Optimizing mannequin deployment with Amazon SageMaker AI inference parts
With Amazon SageMaker AI inference parts, you’ll be able to deploy a number of FMs on the identical SageMaker AI endpoint and management what number of accelerators and the way a lot reminiscence is reserved for every FM. This helps to enhance useful resource utilization, reduces mannequin deployment prices, and allows you to scale endpoints collectively together with your use instances. For every FM, you’ll be able to outline separate scaling insurance policies to adapt to mannequin utilization patterns whereas additional optimizing infrastructure prices. Right here’s the illustration of Salesforce’s massive and medium SageMaker endpoints after utilization has been improved with Inference Elements:
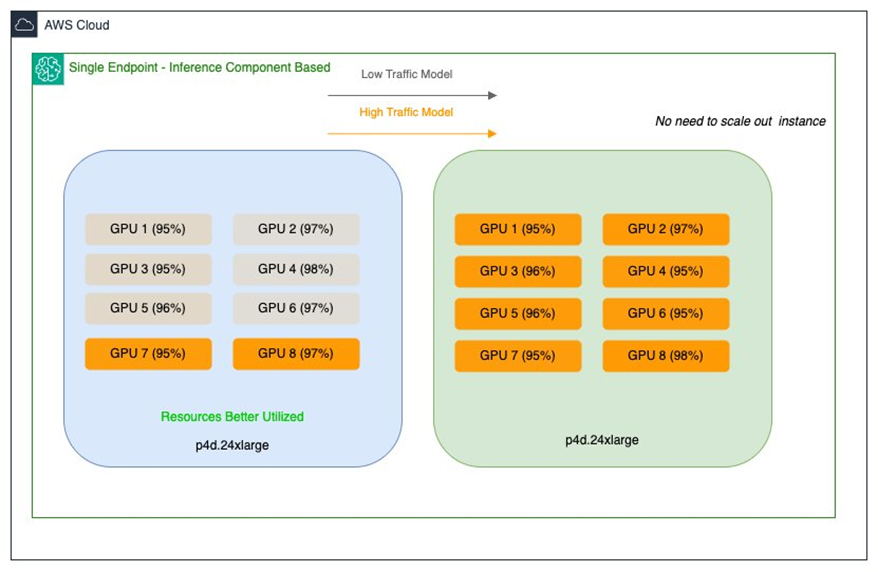
An inference part abstracts ML fashions and allows assigning CPUs, GPU, and scaling insurance policies per mannequin. Inference parts provide the next advantages:
- SageMaker AI will optimally place and pack fashions onto ML cases to maximise utilization, resulting in price financial savings.
- Every mannequin scales independently primarily based on customized configurations, offering optimum useful resource allocation to satisfy particular utility necessities.
- SageMaker AI will scale so as to add and take away cases dynamically to take care of availability whereas holding idle compute to a minimal.
- Organizations can scale right down to zero copies of a mannequin to liberate assets for different fashions or specify to maintain vital fashions all the time loaded and able to serve visitors for important workloads.
Configuring and managing inference part endpoints
You create the SageMaker AI endpoint with an endpoint configuration that defines the occasion kind and preliminary occasion depend for the endpoint. The mannequin is configured in a brand new assemble, an inference part. Right here, you specify the variety of accelerators and quantity of reminiscence you wish to allocate to every copy of a mannequin, along with the mannequin artifacts, container picture, and variety of mannequin copies to deploy.
As inference requests enhance or lower, the variety of copies of your inference parts also can scale up or down primarily based in your auto scaling insurance policies. SageMaker AI will deal with the location to optimize the packing of your fashions for availability and value.
As well as, for those who allow managed occasion auto scaling, SageMaker AI will scale compute cases in accordance with the variety of inference parts that must be loaded at a given time to serve visitors. SageMaker AI will scale up the cases and pack your cases and inference parts to optimize for price whereas preserving mannequin efficiency.
Discuss with Cut back mannequin deployment prices by 50% on common utilizing the most recent options of Amazon SageMaker for extra particulars on use inference parts.
How Salesforce used Amazon SageMaker AI inference parts
Salesforce has a number of totally different proprietary fashions corresponding to CodeGen initially unfold throughout a number of SMEs. CodeGen is Salesforce’s in-house open supply LLM for code understanding and code technology. Builders can use the CodeGen mannequin to translate pure language, corresponding to English, into programming languages, corresponding to Python. Salesforce developed an ensemble of CodeGen fashions (Inline for automated code completion, BlockGen for code block technology, and FlowGPT for course of circulate technology) particularly tuned for the Apex programming language. The fashions are being utilized in ApexGuru, an answer inside the Salesforce platform that helps Salesforce builders sort out important anti-patterns and hotspots of their Apex code.
Inference parts allow a number of fashions to share GPU assets effectively on the identical endpoint. This consolidation not solely delivers discount in infrastructure prices via clever useful resource sharing and dynamic scaling, it additionally reduces operational overhead with lesser endpoints to handle. For his or her CodeGen ensemble fashions, the answer enabled model-specific useful resource allocation and impartial scaling primarily based on visitors patterns, offering optimum efficiency whereas maximizing infrastructure utilization.
To increase internet hosting choices on SageMaker AI with out affecting stability, efficiency, or usability, Salesforce launched inference part endpoints alongside the present SME.
This hybrid strategy makes use of the strengths of every. SMEs present devoted internet hosting for every mannequin and predictable efficiency for important workloads with constant visitors patterns, and inference parts optimize useful resource utilization for variable workloads via dynamic scaling and environment friendly GPU sharing.
The Salesforce AI Platform staff created a SageMaker AI endpoint with the specified occasion kind and preliminary occasion depend for the endpoint to deal with their baseline inference necessities. Mannequin packages are then hooked up dynamically, spinning up particular person containers as wanted. They configured every mannequin, for instance, BlockGen and TextEval fashions as particular person inference parts specifying exact useful resource allocations, together with accelerator depend, reminiscence necessities, mannequin artifacts, container picture, and variety of mannequin copies to deploy. With this strategy, Salesforce might effectively host a number of mannequin variants on the identical endpoint whereas sustaining granular management over useful resource allocation and scaling behaviors.
Through the use of the auto scaling capabilities, inference parts can arrange endpoints with a number of copies of fashions and mechanically modify GPU assets as visitors fluctuates. This enables every mannequin to dynamically scale up or down inside an endpoint primarily based on configured GPU limits. By internet hosting a number of fashions on the identical endpoint and mechanically adjusting capability in response to visitors fluctuations, Salesforce was in a position to considerably cut back the prices related to visitors spikes. Which means that Salesforce AI fashions can deal with various workloads effectively with out compromising efficiency. The graphic under exhibits Salesforce’s endpoints earlier than and after the fashions had been deployed with inference parts:
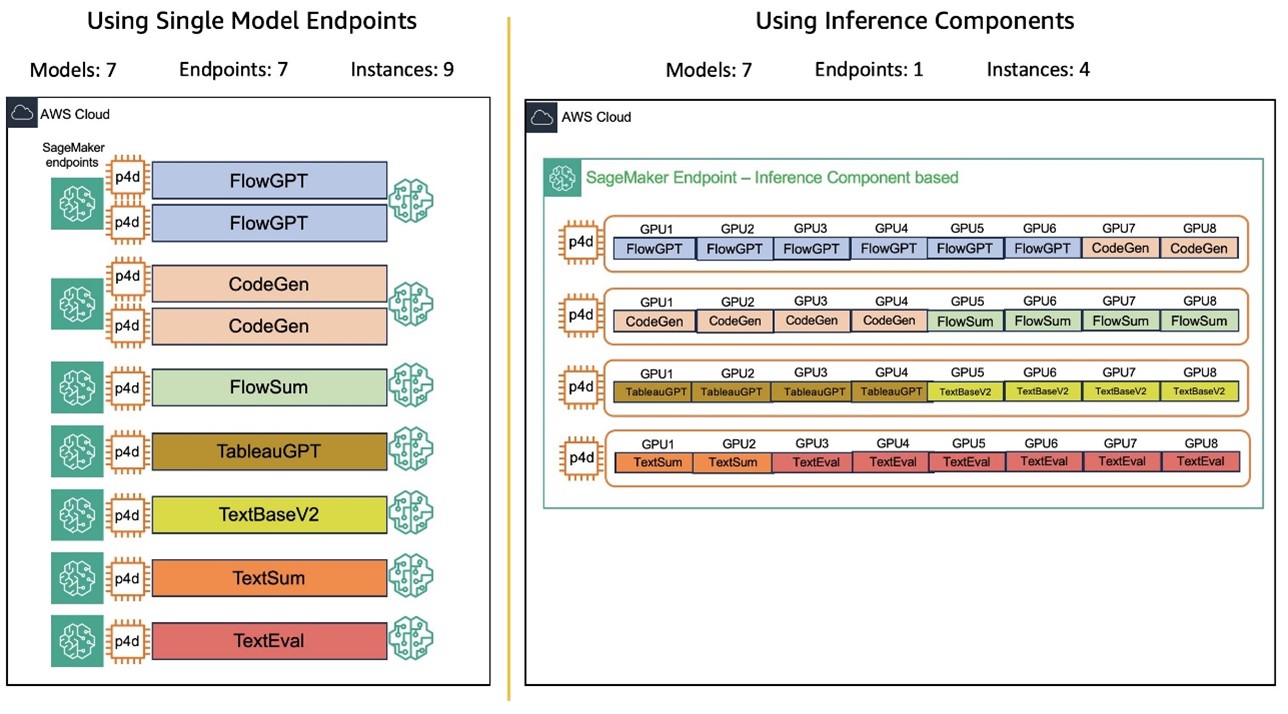
This answer has introduced a number of key advantages:
- Optimized useful resource allocation – A number of fashions now effectively share GPU assets, eliminating pointless provisioning whereas sustaining optimum efficiency.
- Price financial savings – By means of clever GPU useful resource administration and dynamic scaling, Salesforce achieved vital discount in infrastructure prices whereas eliminating idle compute assets.
- Enhanced efficiency for smaller fashions – Smaller fashions now use high-performance GPUs to satisfy their latency and throughput wants with out incurring extreme prices.
By refining GPU allocation on the mannequin stage via inference parts, Salesforce improved useful resource effectivity and achieved a considerable discount in operational price whereas sustaining the high-performance requirements their clients anticipate throughout a variety of AI workloads. The associated fee financial savings are substantial and open up new alternatives for utilizing high-end, costly GPUs in an economical method.
Conclusion
By means of their implementation of Amazon SageMaker AI inference parts, Salesforce has remodeled their AI infrastructure administration, reaching as much as an eight-fold discount in deployment and infrastructure prices whereas sustaining excessive efficiency requirements. The staff realized that clever mannequin packing and dynamic useful resource allocation had been keys to fixing their GPU utilization challenges throughout their numerous mannequin portfolio. This implementation has remodeled efficiency economics, permitting smaller fashions to make use of excessive efficiency GPUs, offering excessive throughput and low latency with out the standard price overhead.
At present, their AI platform effectively serves each massive proprietary fashions corresponding to CodeGen and smaller workloads on the identical infrastructure, with optimized useful resource allocation guaranteeing high-performance supply. With this strategy, Salesforce can maximize the utilization of compute cases, scale to a whole bunch of fashions, and optimize prices whereas offering predictable efficiency. This answer has not solely solved their speedy challenges of optimizing GPU utilization and value administration however has additionally positioned them for future progress. By establishing a extra environment friendly and scalable infrastructure basis, Salesforce can now confidently increase their AI choices and discover extra superior use instances with costly, high-performance GPUs corresponding to P4d, P5, and P5en, realizing they will maximize the worth of each computing useful resource. This transformation represents a big step ahead of their mission to ship enterprise-grade AI options whereas sustaining operational effectivity and cost-effectiveness.
Trying forward, Salesforce is poised to make use of the brand new Amazon SageMaker AI rolling updates functionality for inference part endpoints, a function designed to streamline updates for fashions of various sizes whereas minimizing operational overhead. This development will allow them to replace their fashions batch by batch, moderately than utilizing the standard blue/inexperienced deployment technique, offering larger flexibility and management over mannequin updates whereas utilizing minimal further cases, moderately than requiring doubled cases as prior to now. By implementing these rolling updates alongside their current dynamic scaling infrastructure and incorporating real-time security checks, Salesforce is constructing a extra resilient and adaptable AI platform. This strategic strategy not solely offers cost-effective and dependable deployments for his or her GPU-intensive workloads but in addition units the stage for seamless integration of future AI improvements and mannequin enhancements.
Take a look at How Salesforce achieves high-performance mannequin deployment with Amazon SageMaker AI to study extra. For extra data on get began with SageMaker AI, confer with Information to getting arrange with Amazon SageMaker AI. To study extra about Inference Elements, confer with Amazon SageMaker provides new inference capabilities to assist cut back basis mannequin deployment prices and latency.
In regards to the Authors
 Rishu Aggarwal is a Director of Engineering at Salesforce primarily based in Bangalore, India. Rishu leads the Salesforce AI Platform Mannequin Serving Engineering staff in fixing the complicated issues of inference optimizations and deployment of LLMs at scale inside the Salesforce ecosystem. Rishu is a staunch Tech Evangelist for AI and has deep pursuits in Synthetic Intelligence, Generative AI, Neural Networks and Large Knowledge.
Rishu Aggarwal is a Director of Engineering at Salesforce primarily based in Bangalore, India. Rishu leads the Salesforce AI Platform Mannequin Serving Engineering staff in fixing the complicated issues of inference optimizations and deployment of LLMs at scale inside the Salesforce ecosystem. Rishu is a staunch Tech Evangelist for AI and has deep pursuits in Synthetic Intelligence, Generative AI, Neural Networks and Large Knowledge.
 Rielah De Jesus is a Principal Options Architect at AWS who has efficiently helped numerous enterprise clients within the DC, Maryland, and Virginia space transfer to the cloud. In her present position, she acts as a buyer advocate and technical advisor targeted on serving to organizations like Salesforce obtain success on the AWS platform. She can also be a staunch supporter of ladies in IT and could be very obsessed with discovering methods to creatively use know-how and information to resolve on a regular basis challenges.
Rielah De Jesus is a Principal Options Architect at AWS who has efficiently helped numerous enterprise clients within the DC, Maryland, and Virginia space transfer to the cloud. In her present position, she acts as a buyer advocate and technical advisor targeted on serving to organizations like Salesforce obtain success on the AWS platform. She can also be a staunch supporter of ladies in IT and could be very obsessed with discovering methods to creatively use know-how and information to resolve on a regular basis challenges.
 Pavithra Hariharasudhan is a Senior Technical Account Supervisor and Enterprise Assist Lead at AWS, supporting main AWS Strategic clients with their world cloud operations. She assists organizations in resolving operational challenges and sustaining environment friendly AWS environments, empowering them to realize operational excellence whereas accelerating enterprise outcomes.
Pavithra Hariharasudhan is a Senior Technical Account Supervisor and Enterprise Assist Lead at AWS, supporting main AWS Strategic clients with their world cloud operations. She assists organizations in resolving operational challenges and sustaining environment friendly AWS environments, empowering them to realize operational excellence whereas accelerating enterprise outcomes.
 Ruchita Jadav is a Senior Member of Technical Employees at Salesforce, with over 10 years of expertise in software program and machine studying engineering. Her experience lies in constructing scalable platform options throughout the retail and CRM domains. At Salesforce, she leads initiatives targeted on mannequin internet hosting, inference optimization, and LLMOps, enabling environment friendly and scalable deployment of AI and enormous language fashions. She holds a Bachelor of Know-how in Electronics & Communication from Gujarat Technological College (GTU).
Ruchita Jadav is a Senior Member of Technical Employees at Salesforce, with over 10 years of expertise in software program and machine studying engineering. Her experience lies in constructing scalable platform options throughout the retail and CRM domains. At Salesforce, she leads initiatives targeted on mannequin internet hosting, inference optimization, and LLMOps, enabling environment friendly and scalable deployment of AI and enormous language fashions. She holds a Bachelor of Know-how in Electronics & Communication from Gujarat Technological College (GTU).
 Marc Karp is an ML Architect with the Amazon SageMaker Service staff. He focuses on serving to clients design, deploy, and handle ML workloads at scale. In his spare time, he enjoys touring and exploring new locations.
Marc Karp is an ML Architect with the Amazon SageMaker Service staff. He focuses on serving to clients design, deploy, and handle ML workloads at scale. In his spare time, he enjoys touring and exploring new locations.



{kind=link}