
Think about harnessing the facility of 72 cutting-edge NVIDIA Blackwell GPUs in a single system for the subsequent wave of AI innovation, unlocking 360 petaflops of dense 8-bit floating level (FP8) compute and 1.4 exaflops of sparse 4-bit floating level (FP4) compute. At present, that’s precisely what Amazon SageMaker HyperPod delivers with the launch of help for P6e-GB200 UltraServers. Accelerated by NVIDIA GB200 NVL72, P6e-GB200 UltraServers present industry-leading GPU efficiency, community throughput, and reminiscence for creating and deploying trillion-parameter AI fashions at scale. By seamlessly integrating these UltraServers with the distributed coaching setting of SageMaker HyperPod, organizations can quickly scale mannequin growth, scale back downtime, and simplify the transition from coaching to large-scale deployment. With the automated, resilient, and extremely scalable machine studying infrastructure of SageMaker HyperPod, organizations can seamlessly distribute huge AI workloads throughout 1000’s of accelerators and handle mannequin growth end-to-end with unprecedented effectivity. Utilizing SageMaker HyperPod with P6e-GB200 UltraServers marks a pivotal shift in direction of quicker, extra resilient, and cost-effective coaching and deployment for state-of-the-art generative AI fashions.
On this submit, we evaluation the technical specs of P6e-GB200 UltraServers, talk about their efficiency advantages, and spotlight key use circumstances. We then stroll although methods to buy UltraServer capability by way of versatile coaching plans and get began utilizing UltraServers with SageMaker HyperPod.
Contained in the UltraServer
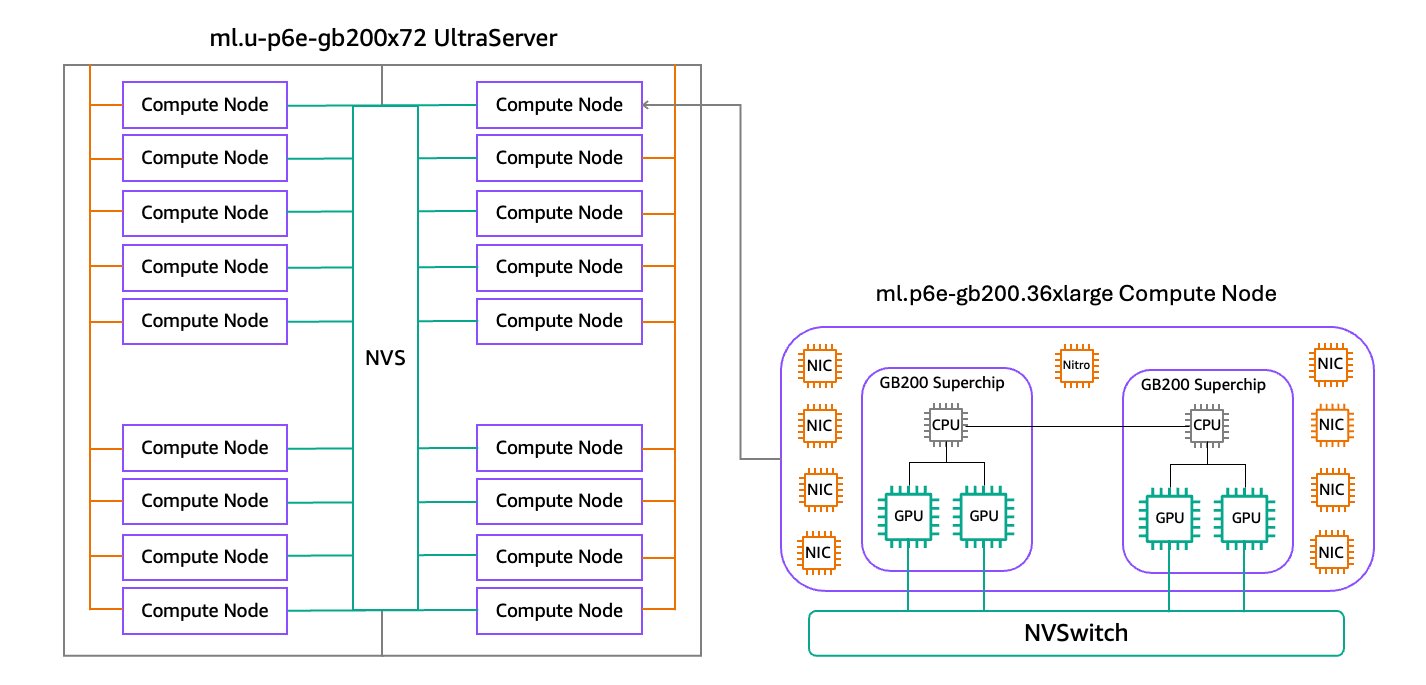
P6e-GB200 UltraServers are accelerated by NVIDIA GB200 NVL72, connecting 36 NVIDIA Grace™ CPUs and 72 Blackwell GPUs in the identical NVIDIA NVLink™ area. Every ml.p6e-gb200.36xlarge compute node inside an UltraServer consists of two NVIDIA GB200 Grace Blackwell Superchips, every connecting two high-performance NVIDIA Blackwell GPUs and an Arm-based NVIDIA Grace CPU with the NVIDIA NVLink chip-to-chip (C2C) interconnect. SageMaker HyperPod is launching P6e-GB200 UltraServers in two sizes. The ml.u-p6e-gb200x36 UltraServer features a rack of 9 compute nodes absolutely linked with NVSwitch (NVS), offering a complete of 36 Blackwell GPUs in the identical NVLink area, and the ml.u-p6e-gb200x72 UltraServer features a rack-pair of 18 compute nodes with a complete of 72 Blackwell GPUs in the identical NVLink area. The next diagram illustrates this configuration.
Efficiency advantages of UltraServers
On this part, we talk about among the efficiency advantages of UltraServers.
GPU and compute energy
With P6e-GB200 UltraServers, you may entry as much as 72 NVIDIA Blackwell GPUs inside a single NVLink area, with a complete of 360 petaflops of FP8 compute (with out sparsity), 1.4 exaflops of FP4 compute (with sparsity) and 13.4 TB of high-bandwidth reminiscence (HBM3e). EveryGrace Blackwell Superchip pairs two Blackwell GPUs with one Grace CPU by way of the NVLink-C2C interconnect, delivering 10 petaflops of dense FP8 compute, 40 petaflops of sparse FP4 compute, as much as 372 GB HBM3e, and 850GB of cache-coherent quick reminiscence per module. This co-location boosts bandwidth between GPU and CPU by an order of magnitude in comparison with previous-generation situations. Every NVIDIA Blackwell GPU includes a second-generation Transformer Engine and helps the most recent AI precision microscaling (MX) knowledge codecs similar to MXFP6 and MXFP4, in addition to NVIDIA NVFP4. When mixed with frameworks like NVIDIA Dynamo, NVIDA TensorRT-LLM and NVIDIA NeMo, these Transformer Engines considerably speed up inference and coaching for giant language fashions (LLMs) and Combination-of-Specialists (MoE) fashions, supporting increased effectivity and efficiency for contemporary AI workloads.
Excessive-performance networking
P6e-GB200 UltraServers ship as much as 130 TBps of low-latency NVLink bandwidth between GPUs for environment friendly large-scale AI workload communication. At double the bandwidth of its predecessor, the fifth-generation NVIDIA NVLink offers as much as 1.8 TBps of bidirectional, direct GPU-to-GPU interconnect, drastically enhancing intra-server communication. Every compute node inside an UltraServer will be configured with as much as 17 bodily community interface playing cards (NICs), every supporting as much as 400 Gbps of bandwidth. P6e-GB200 UltraServers present as much as 28.8 Tbps of complete Elastic Cloth Adapter (EFA) v4 networking, utilizing the Scalable Dependable Datagram (SRD) protocol to intelligently route community site visitors throughout a number of paths, offering easy operation even throughout congestion or {hardware} failures. For extra info, seek advice from EFA configuration for a P6e-GB200 situations.
Storage and knowledge throughput
P6e-GB200 UltraServers help as much as 405 TB of native NVMe SSD storage, very best for large-scale datasets and quick checkpointing throughout AI mannequin coaching. For prime-performance shared storage, Amazon FSx for Lustre file methods will be accessed over EFA with GPUDirect Storage (GDS), offering direct knowledge switch between the file system and the GPU reminiscence with TBps of throughput and hundreds of thousands of enter/output operations per second (IOPS) for demanding AI coaching and inference.
Topology-aware scheduling
Amazon Elastic Compute Cloud (Amazon EC2) offers topology info that describes the bodily and community relationships between situations in your cluster. For UltraServer compute nodes, Amazon EC2 exposes which situations belong to the identical UltraServer, so that you’re coaching and inference algorithms can perceive NVLink connectivity patterns. This topology info helps optimize distributed coaching by permitting frameworks just like the NVIDIA Collective Communications Library (NCCL) to make clever choices about communication patterns and knowledge placement. For extra info, see How Amazon EC2 occasion topology works.
With Amazon Elastic Kubernetes Service (Amazon EKS) orchestration, SageMaker HyperPod mechanically labels UltraServer compute nodes with their respective AWS Area, Availability Zone, Community Node Layers (1–4), and UltraServer ID. These topology labels can be utilized with node affinities, and pod topology unfold constraints to assign Pods to cluster nodes for optimum efficiency.
With Slurm orchestration, SageMaker HyperPod mechanically permits the topology plugin and creates a topology.conf file with the respective BlockName, Nodes, and BlockSizes to match your UltraServer capability. This manner, you may group and phase your compute nodes to optimize job efficiency.
Use circumstances for UltraServers
P6e-GB200 UltraServers can effectively practice fashions with over a trillion parameters attributable to their unified NVLink area, ultrafast reminiscence, and excessive cross-node bandwidth, making them very best for state-of-the-art AI growth. The substantial interconnect bandwidth makes certain even extraordinarily massive fashions will be partitioned and educated in a extremely parallel and environment friendly method with out the efficiency setbacks seen in disjointed multi-node methods. This ends in quicker iteration cycles and higher-quality AI fashions, serving to organizations push the boundaries of state-of-the-art AI analysis and innovation.
For real-time trillion-parameter mannequin inference, P6e-GB200 UltraServers allow 30 instances quicker inference on frontier trillion-parameter LLMs in comparison with prior platforms, reaching real-time efficiency for advanced fashions utilized in generative AI, pure language understanding, and conversational brokers. When paired with NVIDIA Dynamo, P6e-GB200 UltraServers ship important efficiency good points, particularly for lengthy context lengths. NVIDIA Dynamo disaggregates the compute-heavy prefill section and the memory-heavy decode section onto totally different GPUs, supporting unbiased optimization and useful resource allocation throughout the massive 72-GPU NVLink area. This permits extra environment friendly administration of huge context home windows and high-concurrency functions.
P6e-GB200 UltraServers supply substantial advantages to startup, analysis, and enterprise prospects with a number of groups that must run numerous distributed coaching and inference workloads on shared infrastructure. When used along side SageMaker HyperPod job governance, UltraServers present distinctive scalability and useful resource pooling, so totally different groups can launch simultaneous jobs with out bottlenecks. Enterprises can maximize infrastructure utilization, scale back general prices, and speed up undertaking timelines, all whereas supporting the advanced wants of groups creating and serving superior AI fashions, together with huge LLMs for high-concurrency real-time inference, throughout a single, resilient platform.
Versatile coaching plans for UltraServer capability
SageMaker AI presently provides P6e-GB200 UltraServer capability by way of versatile coaching plans within the Dallas AWS Native Zone (us-east-1-dfw-2a). UltraServers can be utilized for each SageMaker HyperPod and SageMaker coaching jobs.
To get began, navigate to the SageMaker AI coaching plans console, which features a new UltraServer compute sort, from which you’ll choose your UltraServer sort: ml.u-p6e-gb200x36 (containing 9 ml.p6e-gb200.36xlarge compute nodes) or ml.u-p6e-gb200x72 (containing 18 ml.p6e-gb200.36xlarge compute nodes).
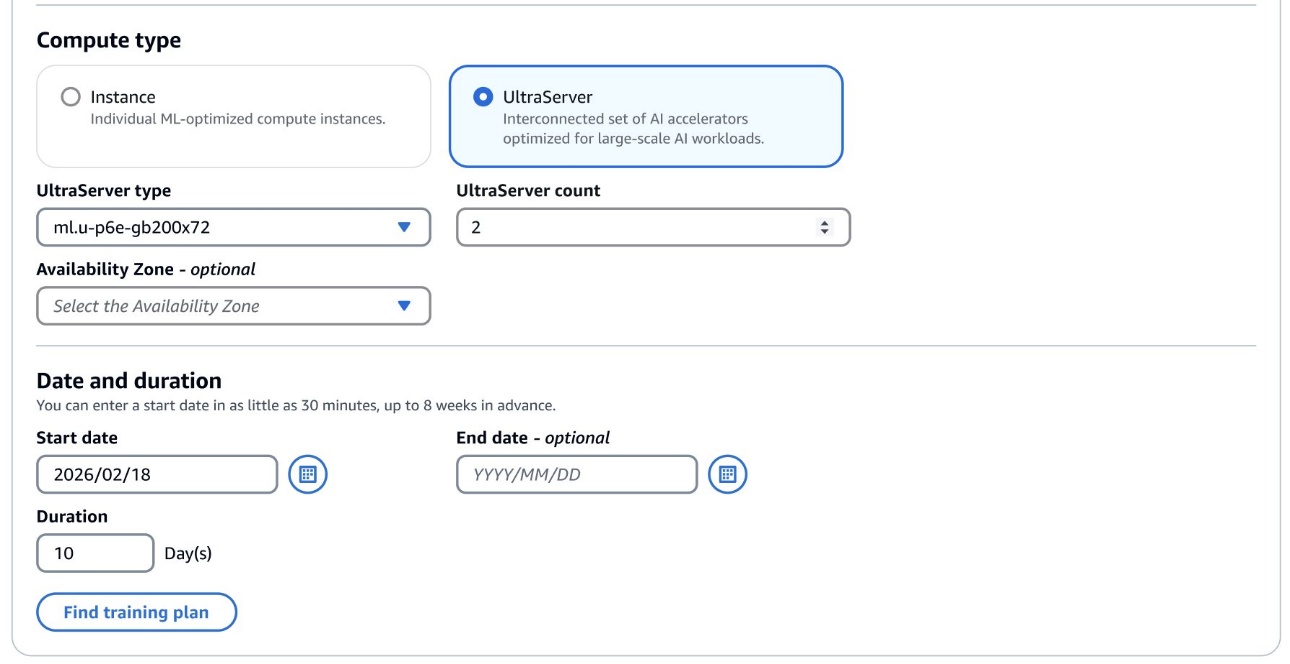
After discovering the coaching plan that matches your wants, it’s endorsed that you simply configure not less than one spare ml.p6e-gb200.36xlarge compute node to verify defective situations will be rapidly changed with minimal disruption.

Create an UltraServer cluster with SageMaker HyperPod
After buying an UltraServer coaching plan, you may add the capability to an ml.p6e-gb200.36xlarge sort occasion group inside your SageMaker HyperPod cluster and specify the amount of situations that you simply wish to provision as much as the quantity out there throughout the coaching plan. For instance, should you bought a coaching plan for one ml.u-p6e-gb200x36 UltraServer, you would provision as much as 9 compute nodes, whereas should you bought a coaching plan for one ml.u-p6e-gb200x72 UltraServer, you would provision as much as 18 compute nodes.
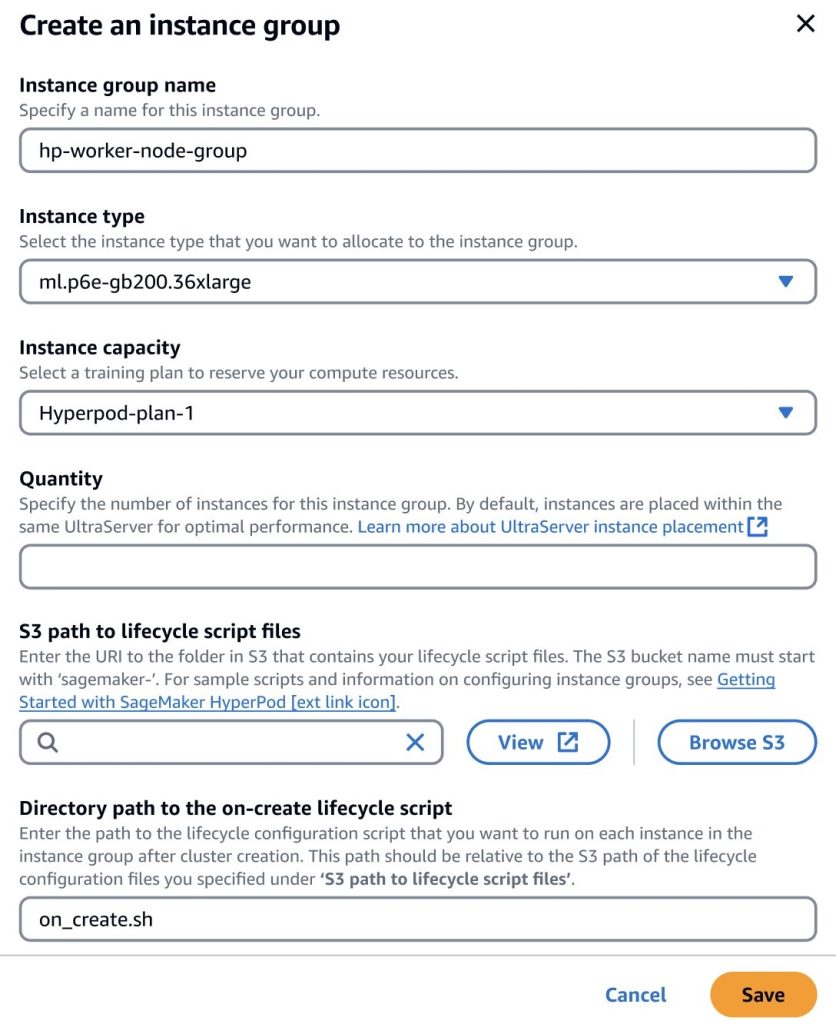
By default, SageMaker will optimize the location of occasion group nodes throughout the identical UltraServer in order that GPUs throughout nodes are interconnected throughout the identical NVLink area to attain the perfect knowledge switch efficiency to your jobs. For instance, if you buy two ml.u-p6e-gb200x72 UltraServers with 17 compute nodes out there every (assuming you configured two spares), then create an occasion group with 24 nodes, the primary 17 compute nodes can be positioned on UltraServer A, and the opposite 7 compute nodes can be positioned on UltraServer B.
Conclusion
P6e-GB200 UltraServers assist organizations practice, fine-tune, and serve the world’s most formidable AI fashions at scale. By combining extraordinary GPU sources, ultrafast networking, and industry-leading reminiscence with the automation and scalability of SageMaker HyperPod, enterprises can speed up the totally different phases of the AI lifecycle, from experimentation and distributed coaching by way of seamless inference and deployment. This highly effective answer breaks new floor in efficiency and suppleness and reduces operational complexity and prices, in order that innovators can unlock new potentialities and lead the subsequent period of AI development.
Concerning the authors
 Nathan Arnold is a Senior AI/ML Specialist Options Architect at AWS based mostly out of Austin Texas. He helps AWS prospects—from small startups to massive enterprises—practice and deploy basis fashions effectively on AWS. When he’s not working with prospects, he enjoys mountain climbing, path working, and enjoying along with his canines.
Nathan Arnold is a Senior AI/ML Specialist Options Architect at AWS based mostly out of Austin Texas. He helps AWS prospects—from small startups to massive enterprises—practice and deploy basis fashions effectively on AWS. When he’s not working with prospects, he enjoys mountain climbing, path working, and enjoying along with his canines.



{kind=link}