In nowadays, it’s extra frequent to firms adopting AI-first technique to remain aggressive and extra environment friendly. As generative AI adoption grows, the expertise’s capacity to unravel issues can be enhancing (an instance is the use case to generate complete market report). One option to simplify the rising complexity of issues to be solved is thru graphs, which excel at modeling relationships and extracting significant insights from interconnected information and entities.
On this put up, we discover how you can use Graph-based Retrieval-Augmented Era (GraphRAG) in Amazon Bedrock Information Bases to construct clever purposes. In contrast to conventional vector search, which retrieves paperwork based mostly on similarity scores, information graphs encode relationships between entities, permitting massive language fashions (LLMs) to retrieve info with context-aware reasoning. Which means that as a substitute of solely discovering probably the most related doc, the system can infer connections between entities and ideas, enhancing response accuracy and decreasing hallucinations. To examine the graph constructed, Graph Explorer is a superb instrument.
Introduction to GraphRAG
Conventional Retrieval-Augmented Era (RAG) approaches enhance generative AI by fetching related paperwork from a information supply, however they typically battle with context fragmentation, when related info is unfold throughout a number of paperwork or sources.
That is the place GraphRAG is available in. GraphRAG was created to boost information retrieval and reasoning by leveraging information graphs, which construction info as entities and their relationships. In contrast to conventional RAG strategies that rely solely on vector search or key phrase matching, GraphRAG permits multi-hop reasoning (logical connections between totally different items of context), higher entity linking, and contextual retrieval. This makes it significantly helpful for advanced doc interpretation, similar to authorized contracts, analysis papers, compliance pointers, and technical documentation.
Amazon Bedrock Information Bases GraphRAG
Amazon Bedrock Information Bases is a managed service for storing, retrieving, and structuring enterprise information. It seamlessly integrates with the muse fashions out there by Amazon Bedrock, enabling AI purposes to generate extra knowledgeable and reliable responses. Amazon Bedrock Information Bases now helps GraphRAG, a sophisticated function that enhances conventional RAG by integrating graph-based retrieval. This permits LLMs to know relationships between entities, info, and ideas, making responses extra contextually related and explainable.
How Amazon Bedrock Information Bases GraphRAG works
Graphs are generated by making a structured illustration of knowledge as nodes (entities) and edges (relationships) between these nodes. The method sometimes entails figuring out key entities throughout the information, figuring out how these entities relate to one another, after which modeling these relationships as connections within the graph. After the normal RAG course of, Amazon Bedrock Information Bases GraphRAG performs further steps to enhance the standard of the generated response:
- It identifies and retrieves associated graph nodes or chunk identifiers which are linked to the initially retrieved doc chunks.
- The system then expands on this info by traversing the graph construction, retrieving further particulars about these associated chunks from the vector retailer.
- By utilizing this enriched context, which incorporates related entities and their key connections, GraphRAG can generate extra complete responses.
How graphs are constructed
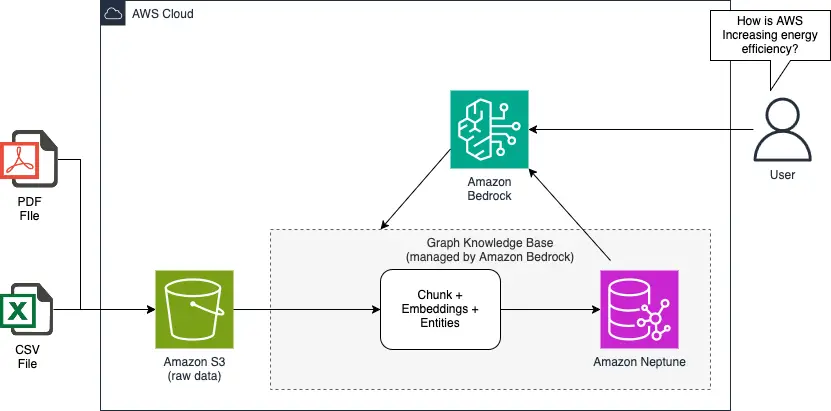
Think about extracting info from unstructured information similar to PDF recordsdata. In Amazon Bedrock Information Bases, graphs are constructed by a course of that extends conventional PDF ingestion. The system creates three kinds of nodes: chunk, doc, and entity. The ingestion pipeline begins by splitting paperwork from an Amazon Easy Storage Service (Amazon S3) folder into chunks utilizing customizable strategies (you possibly can select between primary fixed-size chunking to extra advanced LLM-based chunking mechanisms). Every chunk is then embedded, and an ExtractChunkEntity step makes use of an LLM to determine key entities throughout the chunk. This info, together with the chunk’s embedding, textual content, and doc ID, is distributed to Amazon Neptune Analytics for storage. The insertion course of creates interconnected nodes and edges, linking chunks to their supply paperwork and extracted entities utilizing the bulk load API in Amazon Neptune. The next determine illustrates this course of.

Use case
Contemplate an organization that should analyze a wide variety of paperwork, and must correlate entities which are unfold throughout these paperwork to reply some questions (for instance, Which firms has Amazon invested in or acquired in recent times?). Extracting significant insights from this unstructured information and connecting it with different inner and exterior info poses a big problem. To handle this, the corporate decides to construct a GraphRAG software utilizing Amazon Bedrock Information Bases, usign the graph databases to signify advanced relationships throughout the information.
One enterprise requirement for the corporate is to generate a complete market report that gives an in depth evaluation of how inner and exterior info are correlated with business tendencies, the corporate’s actions, and efficiency metrics. By utilizing Amazon Bedrock Information Bases, the corporate can create a information graph that represents the intricate connections between press releases, merchandise, firms, individuals, monetary information, exterior paperwork and business occasions. The Graph Explorer instrument turns into invaluable on this course of, serving to information scientists and analysts to visualise these connections, export related subgraphs, and seamlessly combine them with the LLMs in Amazon Bedrock. After the graph is nicely structured, anybody within the firm can ask questions in pure language utilizing Amazon Bedrock LLMs and generate deeper insights from a information base with correlated info throughout a number of paperwork and entities.
Answer overview
On this GraphRAG software utilizing Amazon Bedrock Information Bases, we’ve designed a streamlined course of to remodel uncooked paperwork right into a wealthy, interconnected graph of information. Right here’s the way it works:
- Doc ingestion: Customers can add paperwork manually to Amazon S3 or arrange computerized ingestion pipelines.
- Chunk, entity extraction, and embeddings era: Within the information base, paperwork are first break up into chunks utilizing fastened dimension chunking or customizable strategies, then embeddings are computed for every chunk. Lastly, an LLM is prompted to extract key entities from every chunk, making a GraphDocument that features the entity record, chunk embedding, chunked textual content, and doc ID.
- Graph building: The embeddings, together with the extracted entities and their relationships, are used to assemble a information graph. The constructed graph information, together with nodes (entities) and edges (relationships), is robotically inserted into Amazon Neptune.
- Knowledge exploration: With the graph database populated, customers can rapidly discover the information utilizing Graph Explorer. This intuitive interface permits for visible navigation of the information graph, serving to customers perceive relationships and connections throughout the information.
- LLM-powered software: Lastly, customers can leverage LLMs by Amazon Bedrock to question the graph and retrieve correlated info throughout paperwork. This allows highly effective, context-aware responses that draw insights from your complete corpus of ingested paperwork.
The next determine illustrates this resolution.

Conditions
The instance resolution on this put up makes use of datasets from the next web sites:
Additionally, it’s good to:
- Create an S3 bucket to retailer the recordsdata on AWS. On this instance, we named this bucket: blog-graphrag-s3.
- Obtain and add the PDF and XLS recordsdata from the web sites into the S3 bucket.
Constructing the Graph RAG Software
- Open the AWS Administration Console for Amazon Bedrock.
- Within the navigation pane, below Information Bases, select Create.
- Choose Information Base with vector retailer, and select Create.

- Enter a reputation for Information Base identify (for instance:
knowledge-base-graphrag-demo) and optionally available description. - Choose Create and use a brand new service function.
- Choose Knowledge supply as Amazon S3.
- Go away every little thing else as default and select Subsequent to proceed.
- Enter a Knowledge supply identify (for instance:
knowledge-base-graphrag-data-source). - Choose an S3 bucket by selecting Browse S3. (In case you don’t have an S3 bucket in your account, create one. Be certain to add all the mandatory recordsdata.)
- After the S3 bucket is created and recordsdata are uploaded, select
blog-graphrag-s3bucket. - Go away every little thing else as default and select Subsequent.
- Select Choose mannequin after which choose an embeddings mannequin (on this instance, we selected the Titan Textual content Embeddings V2 mannequin).
- Within the Vector database part, below Vector retailer creation methodology choose Fast create a brand new vector retailer, for the Vector retailer choose Amazon Neptune Analytics (GraphRAG),and select Subsequent to proceed.
- Evaluate all the main points.
- Select Create Information Base after reviewing all the main points.
- Making a information base on Amazon Bedrock would possibly take a number of minutes to finish relying on the dimensions of the information current within the information supply. It is best to see the standing of the information base as Obtainable after it’s created efficiently.

Replace and sync the graph along with your information
- Choose the Knowledge supply identify (on this instance,
knowledge-base-graphrag-data-source) to view the synchronization historical past. - Select Sync to replace the information supply.

Visualize the graph utilizing Graph Explorer
Let’s take a look at the graph created by the information base by navigating to the Amazon Neptune console. Just remember to’re in the identical AWS Area the place you created the information base.
- Open the Amazon Neptune console.
- Within the navigation pane, select Analytics after which Graphs.
- It is best to see the graph created by the information base.

To view the graph in Graph Discoverr, it’s good to create a pocket book by going to the Notebooks part.
You may create the pocket book occasion manually or by utilizing an AWS CloudFormation template. On this put up, we are going to present you how you can do it utilizing the Amazon Neptune console (guide).
To create a pocket book occasion:
- Select Notebooks.
- Select Create pocket book.
- Choose the Analytics because the Neptune Service
- Affiliate the pocket book with the graph you simply created (on this case:
bedrock-knowledge-base-imwhqu). - Choose the pocket book occasion sort.
- Enter a reputation for the pocket book occasion within the Pocket book identify
- Create an AWS Id and Entry Administration (IAM) function and use the Neptune default configuration.
- Choose VPC, Subnet, and Safety group.
- Go away Web entry as default and select Create pocket book.

Pocket book occasion creation would possibly take a couple of minutes. After the Pocket book is created, you must see the standing as Prepared.
To see the Graph Explorer:
- Go to Actions and select Open Graph Explorer.

By default, public connectivity is disabled for the graph database. To connect with the graph, you need to both have a non-public graph endpoint or allow public connectivity. For this put up, you’ll allow public connectivity for this graph.
To arrange a public connection to view the graph (optionally available):
- Return to the graph you created earlier (below Analytics, Graphs).
- Choose your graph by selecting the spherical button to the left of the Graph Identifier.
- Select Modify.
- Choose the verify field Allow public connectivity within the Community
- Select Subsequent.
- Evaluate modifications and select Submit.

To open the Graph Explorer:
- Return to Notebooks.
- After the the Pocket book Occasion is created, click on on within the occasion identify (on this case:
aws-neptune-analytics-neptune-analytics-demo-notebook). - Then, select Actions after which select Open Graph Discover

- It is best to now see Graph Explorer. To see the graph, add a node to the canvas, then discover and navigate into the graph.

Playground: Working with LLMs to extract insights from the information base utilizing GraphRAG
You’re prepared to check the information base.
- Select the information base, choose a mannequin, and select Apply.
- Select Run after including the immediate. Within the instance proven within the following screenshot, we requested How is AWS Rising vitality effectivity?).

- Select Present particulars to see the Supply chunk.
- Select Metadata related to this chunk to view the chunk ID, information supply ID, and supply URI.

- Within the subsequent instance, we requested a extra advanced query: Which firms has AMAZON invested in or acquired in recent times?

One other means to enhance the relevance of question responses is to make use of a reranker mannequin. Utilizing the reranker mannequin in GraphRAG entails offering a question and an inventory of paperwork to be reordered based mostly on relevance. The reranker calculates relevance scores for every doc in relation to the question, enhancing the accuracy and pertinence of retrieved outcomes for subsequent use in producing responses or prompts. Within the Amazon Bedrock Playgrounds, you possibly can see the outcomes generated by the reranking mannequin in two methods: the information ranked by the reranking solitary (the next determine), or a mix of the reranking mannequin and the LLM to generate new insights.

To make use of the reranker mannequin:
- Examine the provision of the reranker mannequin
- Go to AWS Administration Console for Amazon Bedrock.
- From the navigation pane, below Builder instruments, select Information Bases
- Select the identical information base we created within the steps earlier than knowledge-base-graphrag-demo.
- Click on on Take a look at Information Base.
- Select Configurations, increase the Reranking part, select Choose mannequin, and choose a reranker mannequin (on this put up, we select Cohere Rerank 3.5).
Clear up
To scrub up your assets, full the next duties:
- Delete the Neptune notebooks:
aws-neptune-graphrag. - Delete the Amazon Bedrock Information Bases:
knowledge-base-graphrag-demo. - Delete content material from the Amazon S3 bucket
blog-graphrag-s3.
Conclusion
Utilizing Graph Explorer together with Amazon Neptune and Amazon Bedrock LLMs gives an answer for constructing subtle GraphRAG purposes. Graph Explorer presents intuitive visualization and exploration of advanced relationships inside information, making it simple to know and analyze firm connections and investments. You should use Amazon Neptune graph database capabilities to arrange environment friendly querying of interconnected information, permitting for fast correlation of knowledge throughout varied entities and relationships.
By utilizing this strategy to investigate Amazon’s funding and acquisition historical past of Amazon, we are able to rapidly determine patterns and insights which may in any other case be missed. As an illustration, when analyzing the questions “Which firms has Amazon invested in or acquired in recent times?” or “How is AWS rising vitality effectivity?” The GraphRAG software can cross the information graph, correlating press releases, investor relations info, entities, and monetary information to supply a complete overview of Amazon’s strategic strikes.
The mixing of Amazon Bedrock LLMs additional enhances the accuracy and relevance of generated outcomes. These fashions can contextualize the graph information, serving to you to know the nuances in firm relationships and funding tendencies, and be supportive in producing complete market reviews. This mix of graph-based information and pure language processing permits extra exact solutions and information interpretation, going past primary truth retrieval to supply evaluation of Amazon’s funding technique.
In abstract, the synergy between Graph Explorer, Amazon Neptune, and Amazon Bedrock LLMs creates a framework for constructing GraphRAG purposes that may extract significant insights from advanced datasets. This strategy streamlines the method of analyzing company investments and create new methods to investigate unstructured information throughout varied industries and use circumstances.
Concerning the authors
 Ruan Roloff is a ProServe Cloud Architect specializing in Knowledge & AI at AWS. Throughout his time at AWS, he was chargeable for the information journey and information product technique of consumers throughout a variety of industries, together with finance, oil and gasoline, manufacturing, digital natives and public sector — serving to these organizations obtain multi-million greenback use circumstances. Outdoors of labor, Ruan likes to assemble and disassemble issues, fish on the seashore with associates, play SFII, and go mountain climbing within the woods along with his household.
Ruan Roloff is a ProServe Cloud Architect specializing in Knowledge & AI at AWS. Throughout his time at AWS, he was chargeable for the information journey and information product technique of consumers throughout a variety of industries, together with finance, oil and gasoline, manufacturing, digital natives and public sector — serving to these organizations obtain multi-million greenback use circumstances. Outdoors of labor, Ruan likes to assemble and disassemble issues, fish on the seashore with associates, play SFII, and go mountain climbing within the woods along with his household.
 Sai Devisetty is a Technical Account Supervisor at AWS. He helps clients within the Monetary Providers business with their operations in AWS. Outdoors of labor, Sai cherishes household time and enjoys exploring new locations.
Sai Devisetty is a Technical Account Supervisor at AWS. He helps clients within the Monetary Providers business with their operations in AWS. Outdoors of labor, Sai cherishes household time and enjoys exploring new locations.
 Madhur Prashant is a Generative AI Options Architect at Amazon Net Providers. He’s passionate concerning the intersection of human pondering and generative AI. His pursuits lie in generative AI, particularly constructing options which are useful and innocent, and most of all optimum for purchasers. Outdoors of labor, he loves doing yoga, mountain climbing, spending time along with his twin, and taking part in the guitar.
Madhur Prashant is a Generative AI Options Architect at Amazon Net Providers. He’s passionate concerning the intersection of human pondering and generative AI. His pursuits lie in generative AI, particularly constructing options which are useful and innocent, and most of all optimum for purchasers. Outdoors of labor, he loves doing yoga, mountain climbing, spending time along with his twin, and taking part in the guitar.
 Qingwei Li is a Machine Studying Specialist at Amazon Net Providers. He acquired his Ph.D. in Operations Analysis after he broke his advisor’s analysis grant account and did not ship the Nobel Prize he promised. Presently he helps clients within the monetary service and insurance coverage business construct machine studying options on AWS. In his spare time, he likes studying and educating.
Qingwei Li is a Machine Studying Specialist at Amazon Net Providers. He acquired his Ph.D. in Operations Analysis after he broke his advisor’s analysis grant account and did not ship the Nobel Prize he promised. Presently he helps clients within the monetary service and insurance coverage business construct machine studying options on AWS. In his spare time, he likes studying and educating.



{kind=link}