Generative synthetic intelligence (AI) purposes are generally constructed utilizing a way referred to as Retrieval Augmented Era (RAG) that gives basis fashions (FMs) entry to extra knowledge they didn’t have throughout coaching. This knowledge is used to complement the generative AI immediate to ship extra context-specific and correct responses with out constantly retraining the FM, whereas additionally bettering transparency and minimizing hallucinations.
On this publish, we reveal an answer utilizing Amazon Elastic Kubernetes Service (EKS) with Amazon Bedrock to construct scalable and containerized RAG options in your generative AI purposes on AWS whereas bringing your unstructured person file knowledge to Amazon Bedrock in a simple, quick, and safe method.
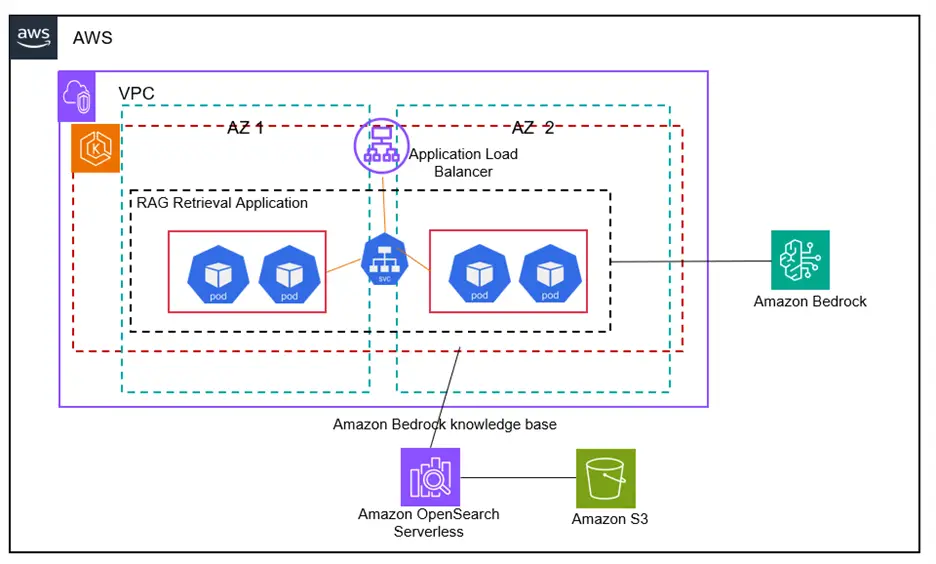
Amazon EKS gives a scalable, safe, and cost-efficient surroundings for constructing RAG purposes with Amazon Bedrock and in addition allows environment friendly deployment and monitoring of AI-driven workloads whereas leveraging Bedrock’s FMs for inference. It enhances efficiency with optimized compute situations, auto-scales GPU workloads whereas decreasing prices by way of Amazon EC2 Spot Situations and AWS Fargate and gives enterprise-grade safety by way of native AWS mechanisms reminiscent of Amazon VPC networking and AWS IAM.
Our answer makes use of Amazon S3 because the supply of unstructured knowledge and populates an Amazon OpenSearch Serverless vector database by way of the usage of Amazon Bedrock Information Bases with the person’s present recordsdata and folders and related metadata. This permits a RAG situation with Amazon Bedrock by enriching the generative AI immediate utilizing Amazon Bedrock APIs along with your company-specific knowledge retrieved from the OpenSearch Serverless vector database.
Resolution overview
The answer makes use of Amazon EKS managed node teams to automate the provisioning and lifecycle administration of nodes (Amazon EC2 situations) for the Amazon EKS Kubernetes cluster. Each managed node within the cluster is provisioned as a part of an Amazon EC2 Auto Scaling group that’s managed for you by EKS.
The EKS cluster consists of a Kubernetes deployment that runs throughout two Availability Zones for prime availability the place every node within the deployment hosts a number of replicas of a Bedrock RAG container picture registered and pulled from Amazon Elastic Container Registry (ECR). This setup makes positive that sources are used effectively, scaling up or down based mostly on the demand. The Horizontal Pod Autoscaler (HPA) is ready as much as additional scale the variety of pods in our deployment based mostly on their CPU utilization.
The RAG Retrieval Utility container makes use of Bedrock Information Bases APIs and Anthropic’s Claude 3.5 Sonnet LLM hosted on Bedrock to implement a RAG workflow. The answer gives the top person with a scalable endpoint to entry the RAG workflow utilizing a Kubernetes service that’s fronted by an Amazon Utility Load Balancer (ALB) provisioned by way of an EKS ingress controller.
The RAG Retrieval Utility container orchestrated by EKS allows RAG with Amazon Bedrock by enriching the generative AI immediate obtained from the ALB endpoint with knowledge retrieved from an OpenSearch Serverless index that’s synced by way of Bedrock Information Bases out of your company-specific knowledge uploaded to Amazon S3.
The next structure diagram illustrates the assorted parts of our answer:

Stipulations
Full the next stipulations:
- Guarantee mannequin entry in Amazon Bedrock. On this answer, we use Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock.
- Set up the AWS Command Line Interface (AWS CLI).
- Set up Docker.
- Set up Kubectl.
- Set up Terraform.
Deploy the answer
The answer is on the market for obtain on the GitHub repo. Cloning the repository and utilizing the Terraform template will provision the parts with their required configurations:
- Clone the Git repository:
- From the
terraformfolder, deploy the answer utilizing Terraform:
Configure EKS
- Configure a secret for the ECR registry:
- Navigate to the
kubernetes/ingressfolder:- Be sure that the
AWS_Regionvariable within thebedrockragconfigmap.yamlfile factors to your AWS area. - Substitute the picture URI in line 20 of the
bedrockragdeployment.yamlfile with the picture URI of yourbedrockragpicture out of your ECR repository.
- Be sure that the
- Provision the EKS deployment, service and ingress:
Create a information base and add knowledge
To create a information base and add knowledge, comply with these steps:
- Create an S3 bucket and add your knowledge into the bucket. In our weblog publish, we uploaded these two recordsdata, Amazon Bedrock Person Information and the Amazon FSx for ONTAP Person Information, into our S3 bucket.
- Create an Amazon Bedrock information base. Comply with the steps right here to create a information base. Settle for all of the defaults together with utilizing the Fast create a brand new vector retailer possibility in Step 7 of the directions that creates an Amazon OpenSearch Serverless vector search assortment as your information base.
- In Step 5c of the directions to create a information base, present the S3 URI of the article containing the recordsdata for the information supply for the information base
- As soon as the information base is provisioned, get hold of the Information Base ID from the Bedrock Information Bases console in your newly created information base.
Question utilizing the Utility Load Balancer
You’ll be able to question the mannequin straight utilizing the API entrance finish supplied by the AWS ALB provisioned by the Kubernetes (EKS) Ingress Controller. Navigate to the AWS ALB console and procure the DNS identify in your ALB to make use of as your API:
Cleanup
To keep away from recurring costs, clear up your account after making an attempt the answer:
- From the terraform folder, delete the Terraform template for the answer:
terraform apply --destroy - Delete the Amazon Bedrock information base. From the Amazon Bedrock console, choose the information base you created on this answer, choose Delete, and comply with the steps to delete the information base.
Conclusion
On this publish, we demonstrated an answer that makes use of Amazon EKS with Amazon Bedrock and gives you with a framework to construct your personal containerized, automated, scalable, and extremely accessible RAG-based generative AI purposes on AWS. Utilizing Amazon S3 and Amazon Bedrock Information Bases, our answer automates bringing your unstructured person file knowledge to Amazon Bedrock inside the containerized framework. You should utilize the method demonstrated on this answer to automate and containerize your AI-driven workloads whereas utilizing Amazon Bedrock FMs for inference with built-in environment friendly deployment, scalability, and availability from a Kubernetes-based containerized deployment.
For extra details about tips on how to get began constructing with Amazon Bedrock and EKS for RAG eventualities, confer with the next sources:
Concerning the Authors
 Kanishk Mahajan is Principal, Options Structure at AWS. He leads cloud transformation and answer structure for AWS prospects and companions. Kanishk makes a speciality of containers, cloud operations, migrations and modernizations, AI/ML, resilience and safety and compliance. He’s a Technical Area Neighborhood (TFC) member in every of these domains at AWS.
Kanishk Mahajan is Principal, Options Structure at AWS. He leads cloud transformation and answer structure for AWS prospects and companions. Kanishk makes a speciality of containers, cloud operations, migrations and modernizations, AI/ML, resilience and safety and compliance. He’s a Technical Area Neighborhood (TFC) member in every of these domains at AWS.
 Sandeep Batchu is a Senior Safety Architect at Amazon Net Companies, with intensive expertise in software program engineering, options structure, and cybersecurity. Enthusiastic about bridging enterprise outcomes with technological innovation, Sandeep guides prospects by means of their cloud journey, serving to them design and implement safe, scalable, versatile, and resilient cloud architectures.
Sandeep Batchu is a Senior Safety Architect at Amazon Net Companies, with intensive expertise in software program engineering, options structure, and cybersecurity. Enthusiastic about bridging enterprise outcomes with technological innovation, Sandeep guides prospects by means of their cloud journey, serving to them design and implement safe, scalable, versatile, and resilient cloud architectures.


{kind=link}