This submit is co-written with Ken Tsui, Edward Tsoi and Mickey Yip from Apoidea Group.
The banking business has lengthy struggled with the inefficiencies related to repetitive processes equivalent to info extraction, doc evaluate, and auditing. These duties, which require important human sources, decelerate crucial operations equivalent to Know Your Buyer (KYC) procedures, mortgage functions, and credit score evaluation. Consequently, banks face operational challenges, together with restricted scalability, gradual processing speeds, and excessive prices related to workers coaching and turnover.
To handle these inefficiencies, the implementation of superior info extraction techniques is essential. These techniques allow the fast extraction of knowledge from numerous monetary paperwork—together with financial institution statements, KYC types, and mortgage functions—lowering each guide errors and processing time. As such, info extraction know-how is instrumental in accelerating buyer onboarding, sustaining regulatory compliance, and driving the digital transformation of the banking sector, notably in high-volume doc processing duties.
The challenges in doc processing are compounded by the necessity for specialised options that keep excessive accuracy whereas dealing with delicate monetary information equivalent to banking statements, monetary statements, and firm annual experiences. That is the place Apoidea Group, a number one AI-focused FinTech unbiased software program vendor (ISV) primarily based in Hong Kong, has made a big affect. By utilizing cutting-edge generative AI and deep studying applied sciences, Apoidea has developed modern AI-powered options that deal with the distinctive wants of multinational banks. Their flagship product, SuperAcc, is a complicated doc processing service that includes a set of proprietary doc understanding fashions able to processing various doc sorts equivalent to financial institution statements, monetary statements, and KYC paperwork.
SuperAcc has demonstrated important enhancements within the banking sector. For example, the monetary spreading course of, which beforehand required 4–6 hours, can now be accomplished in simply 10 minutes, with workers needing lower than half-hour to evaluate the outcomes. Equally, in small and medium-sized enterprise (SME) banking, the evaluate course of for a number of financial institution statements spanning 6 months—used to extract crucial information equivalent to gross sales turnover and interbank transactions—has been decreased to simply 10 minutes. This substantial discount in processing time not solely accelerates workflows but in addition minimizes the chance of guide errors. By automating repetitive duties, SuperAcc enhances each operational effectivity and accuracy, utilizing Apoidea’s self-trained machine studying (ML) fashions to ship constant, high-accuracy leads to stay manufacturing environments. These developments have led to a formidable return on funding (ROI) of over 80%, showcasing the tangible advantages of implementing SuperAcc in banking operations.
AI transformation in banking faces a number of challenges, primarily on account of stringent safety and regulatory necessities. Monetary establishments demand banking-grade safety, necessitating compliance with requirements equivalent to ISO 9001 and ISO 27001. Moreover, AI options should align with accountable AI ideas to facilitate transparency and equity. Integration with legacy banking techniques additional complicates adoption, as a result of these infrastructures are sometimes outdated in comparison with quickly evolving tech landscapes. Regardless of these challenges, SuperAcc has been efficiently deployed and trusted by over 10 monetary providers business (FSI) purchasers, demonstrating its reliability, safety, and compliance in real-world banking environments.
To additional improve the capabilities of specialised info extraction options, superior ML infrastructure is crucial. Amazon SageMaker HyperPod presents an efficient resolution for provisioning resilient clusters to run ML workloads and develop state-of-the-art fashions. SageMaker HyperPod accelerates the event of basis fashions (FMs) by eradicating the undifferentiated heavy lifting concerned in constructing and sustaining large-scale compute clusters powered by 1000’s of accelerators equivalent to AWS Trainium and NVIDIA A100 and H100 GPUs. Its resiliency options routinely monitor cluster situations, detecting and changing defective {hardware} routinely, permitting builders to concentrate on working ML workloads with out worrying about infrastructure administration.
Constructing on this basis of specialised info extraction options and utilizing the capabilities of SageMaker HyperPod, we collaborate with APOIDEA Group to discover the usage of giant imaginative and prescient language fashions (LVLMs) to additional enhance desk construction recognition efficiency on banking and monetary paperwork. On this submit, we current our work and step-by-step code on fine-tuning the Qwen2-VL-7B-Instruct mannequin utilizing LLaMA-Manufacturing facility on SageMaker HyperPod. Our outcomes show important enhancements in desk construction recognition accuracy and effectivity in comparison with the unique base mannequin and conventional strategies, with explicit success in dealing with complicated monetary tables and multi-page paperwork. Following the steps described on this submit, you may also fine-tune your individual mannequin with domain-specific information to unravel your info extraction challenges utilizing the open supply implementation.
Challenges in banking info extraction techniques with multimodal fashions
Growing info extraction techniques for banks presents a number of challenges, primarily because of the delicate nature of paperwork, their complexity, and selection. For instance, financial institution assertion codecs fluctuate considerably throughout monetary establishments, with every financial institution utilizing distinctive layouts, completely different columns, transaction descriptions, and methods of presenting monetary info. In some circumstances, paperwork are scanned with low high quality and are poorly aligned, blurry, or light, creating challenges for Optical Character Recognition (OCR) techniques trying to transform them into machine-readable textual content. Creating sturdy ML fashions is difficult because of the shortage of unpolluted coaching information. Present options depend on orchestrating fashions for duties equivalent to structure evaluation, entity extraction, and desk construction recognition. Though this modular strategy addresses the problem of restricted sources for coaching end-to-end ML fashions, it considerably will increase system complexity and fails to completely use out there info.
Fashions developed primarily based on particular doc options are inherently restricted of their scope, limiting entry to various and wealthy coaching information. This limitation leads to upstream fashions, notably these chargeable for visible illustration, missing robustness. Moreover, single-modality fashions fail to make use of the multi-faceted nature of data, probably resulting in much less exact and correct predictions. For example, in desk construction recognition duties, fashions usually lack the potential to purpose about textual content material whereas inferring row and column constructions. Consequently, a typical error is the wrong subdivision of single rows or columns into a number of situations. Moreover, downstream fashions that closely depend upon upstream mannequin outputs are prone to error propagation, probably compounding inaccuracies launched in earlier levels of processing.
Furthermore, the substantial computational necessities of those multimodal techniques current scalability and effectivity challenges. The need to keep up and replace a number of fashions will increase the operational burden, rendering large-scale doc processing each resource-intensive and troublesome to handle successfully. This complexity impedes the seamless integration and deployment of such techniques in banking environments, the place effectivity and accuracy are paramount.
The current advances in multimodal fashions have demonstrated outstanding capabilities in processing complicated visible and textual info. LVLMs symbolize a paradigm shift in doc understanding, combining the sturdy textual processing capabilities of conventional language fashions with superior visible comprehension. These fashions excel at duties requiring simultaneous interpretation of textual content, visible components, and their spatial relationships, making them notably efficient for monetary doc processing. By integrating visible and textual understanding right into a unified framework, multimodal fashions provide a transformative strategy to doc evaluation. Not like conventional info extraction techniques that depend on fragmented processing pipelines, these fashions can concurrently analyze doc layouts, extract textual content content material, and interpret visible components. This built-in strategy considerably improves accuracy by lowering error propagation between processing levels whereas sustaining computational effectivity.
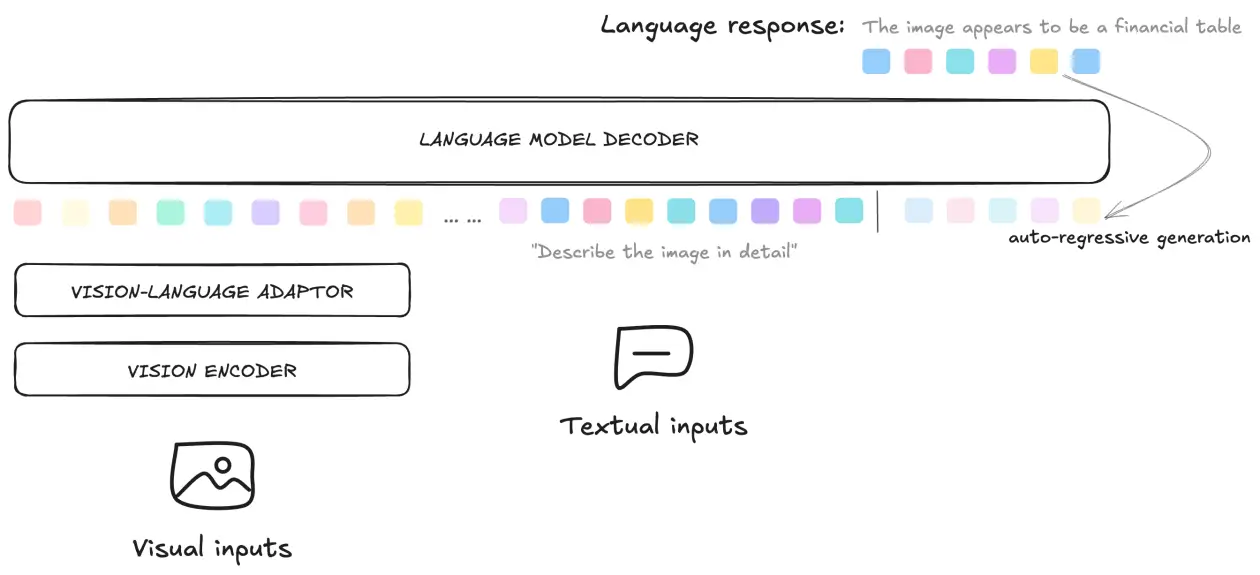
Superior imaginative and prescient language fashions are sometimes pre-trained on large-scale multimodal datasets that embrace each picture and textual content information. The pre-training course of sometimes includes coaching the mannequin on various datasets containing hundreds of thousands of photographs and related textual content descriptions, sourced from publicly out there datasets equivalent to image-text pairs LAION-5B, Visible Query Answering (VQAv2.0), DocVQA, and others. These datasets present a wealthy number of visible content material paired with textual descriptions, enabling the mannequin to be taught significant representations of each modalities. Throughout pre-training, these fashions are educated utilizing auto-regressive loss, the place the mannequin predicts the following token in a sequence given the earlier tokens and the visible enter. This strategy permits the mannequin to successfully align visible and textual options and generate coherent textual content responses primarily based on the visible context. For picture information particularly, trendy vision-language fashions use pre-trained imaginative and prescient encoders, equivalent to imaginative and prescient transformers (ViTs), as their spine to extract visible options. These options are then fused with textual embeddings in a multimodal transformer structure, permitting the mannequin to know the relationships between photographs and textual content. By pre-training on such various and large-scale datasets, these fashions develop a powerful foundational understanding of visible content material, which will be fine-tuned for downstream duties like OCR, picture captioning, or visible query answering. This pre-training section is crucial for enabling the mannequin to generalize properly throughout a variety of vision-language duties. The mannequin structure is illustrated within the following diagram.

High-quality-tuning vision-language fashions for visible doc understanding duties presents important benefits on account of their superior structure and pre-trained capabilities. The mannequin’s potential to know and course of each visible and textual information makes it inherently well-suited for extracting and decoding textual content from photographs. By fine-tuning on domain-specific datasets, the mannequin can obtain superior efficiency in recognizing textual content throughout various fonts, kinds, and backgrounds. That is notably priceless in banking functions, the place paperwork usually comprise specialised terminology, complicated layouts, and ranging high quality scans.
Furthermore, fine-tuning these fashions for visible doc understanding duties permits for domain-specific adaptation, which is essential for attaining excessive precision in specialised functions. The mannequin’s pre-trained information gives a powerful basis, lowering the necessity for intensive coaching information and computational sources. High-quality-tuning additionally permits the mannequin to be taught domain-specific nuances, equivalent to distinctive terminologies or formatting conventions, additional enhancing its efficiency. By combining a mannequin’s general-purpose vision-language understanding with task-specific fine-tuning, you possibly can create a extremely environment friendly and correct info extraction system that outperforms conventional strategies, particularly in difficult or area of interest use circumstances. This makes vision-language fashions highly effective instruments for advancing visible doc understanding know-how in each analysis and sensible functions.
Resolution overview
LLaMA-Manufacturing facility is an open supply framework designed for coaching and fine-tuning giant language fashions (LLMs) effectively. It helps over 100 well-liked fashions, together with LLaMA, Mistral, Qwen, Baichuan, and ChatGLM, and integrates superior methods equivalent to LoRA (Low-Rank Adaptation), QLoRA (Quantized LoRA), and full-parameter fine-tuning. The framework gives a user-friendly interface, together with a web-based software referred to as LlamaBoard, which permits customers to fine-tune fashions with out writing code. LLaMA-Manufacturing facility additionally helps numerous coaching strategies like supervised fine-tuning (SFT), reinforcement studying from human suggestions (RLHF), and direct desire optimization (DPO), making it versatile for various duties and functions.
The benefit of LLaMA-Manufacturing facility lies in its effectivity and suppleness. It considerably reduces the computational and reminiscence necessities for fine-tuning giant fashions through the use of methods like LoRA and quantization, enabling customers to fine-tune fashions even on {hardware} with restricted sources. Moreover, its modular design and integration of cutting-edge algorithms, equivalent to FlashAttention-2 and GaLore, facilitate excessive efficiency and scalability. The framework additionally simplifies the fine-tuning course of, making it accessible to each rookies and skilled builders. This democratization of LLM fine-tuning permits customers to adapt fashions to particular duties shortly, fostering innovation and software throughout numerous domains. The answer structure is introduced within the following diagram.

For the coaching infrastructure, we use SageMaker HyperPod for distributed coaching. SageMaker HyperPod gives a scalable and versatile setting for coaching and fine-tuning large-scale fashions. SageMaker HyperPod presents a complete set of options that considerably improve the effectivity and effectiveness of ML workflows. Its purpose-built infrastructure simplifies distributed coaching setup and administration, permitting versatile scaling from single-GPU experiments to multi-GPU information parallelism and enormous mannequin parallelism. The service’s shared file system integration with Amazon FSx for Lustre permits seamless information synchronization throughout employee nodes and Amazon Easy Storage Service (Amazon S3) buckets, whereas customizable environments enable tailor-made installations of frameworks and instruments.
SageMaker HyperPod integrates with Slurm, a well-liked open supply cluster administration and job scheduling system, to offer environment friendly job scheduling and useful resource administration, enabling parallel experiments and distributed coaching. The service additionally enhances productiveness by Visible Studio Code connectivity, providing a well-known growth setting for code enhancing, script execution, and Jupyter pocket book experimentation. These options collectively allow ML practitioners to concentrate on mannequin growth whereas utilizing the facility of distributed computing for sooner coaching and innovation.
Consult with our GitHub repo for a step-by-step information on fine-tuning Qwen2-VL-7B-Instruct on SageMaker HyperPod.
We begin the information preprocessing utilizing the picture enter and HTML output. We select the HTML construction because the output format as a result of it’s the commonest format for representing tabular information in net functions. It’s easy to parse and visualize, and it’s suitable with most net browsers for rendering on the web site for guide evaluate or modification if wanted. The info preprocessing is crucial for the mannequin to be taught the patterns of the anticipated output format and adapt the visible structure of the desk. The next is one instance of enter picture and output HTML as the bottom reality.

We then use LLaMA-Manufacturing facility to fine-tune the Qwen2-VL-7B-Instruct mannequin on the preprocessed information. We use Slurm sbatch to orchestrate the distributed coaching script. An instance of the script could be submit_train_multinode.sh. The coaching script makes use of QLoRA and information parallel distributed coaching on SageMaker HyperPod. Following the steering supplied, you will notice output just like the next coaching log.
Throughout inference, we use vLLM for internet hosting the quantized mannequin, which gives environment friendly reminiscence administration and optimized consideration mechanisms for high-throughput inference. vLLM natively helps the Qwen2-VL collection mannequin and continues so as to add help for newer fashions, making it notably appropriate for large-scale doc processing duties. The deployment course of includes making use of 4-bit quantization to scale back mannequin measurement whereas sustaining accuracy, configuring the vLLM server with optimum parameters for batch processing and reminiscence allocation, and exposing the mannequin by RESTful APIs for fast integration with present doc processing pipelines. For particulars on mannequin deployment configuration, seek advice from the internet hosting script.
Outcomes
Our analysis centered on the FinTabNet dataset, which comprises complicated tables from S&P 500 annual experiences. This dataset presents distinctive challenges on account of its various desk constructions, together with merged cells, hierarchical headers, and ranging layouts. The next instance demonstrates a monetary desk and its corresponding model-generated HTML output, rendered in a browser for visible comparability.

For quantitative analysis, we employed the Tree Edit Distance-based Similarity (TEDS) metric, which assesses each structural and content material similarity between generated HTML tables and floor reality. TEDS measures the minimal variety of edit operations required to rework one tree construction into one other, and TEDS-S focuses particularly on structural similarity. The next desk summarizes the output on completely different fashions.
| Mannequin | TEDS | TEDS-S |
| Anthropic’s Claude 3 Haiku | 69.9 | 76.2 |
| Anthropic’s Claude 3.5 Sonnet | 86.4 | 87.1 |
| Qwen2-VL-7B-Instruct (Base) | 23.4 | 25.3 |
| Qwen2-VL-7B-Instruct (High-quality-tuned) | 81.1 | 89.7 |
The analysis outcomes reveal important developments in our fine-tuned mannequin’s efficiency. Most notably, the Qwen2-VL-7B-Instruct mannequin demonstrated substantial enhancements in each content material recognition and structural understanding after fine-tuning. When in comparison with its base model, the mannequin confirmed enhanced capabilities in precisely decoding complicated desk constructions and sustaining content material constancy. The fine-tuned model not solely surpassed the efficiency of Anthropic’s Claude 3 Haiku, but in addition approached the accuracy ranges of Anthropic’s Claude 3.5 Sonnet, whereas sustaining extra environment friendly computational necessities. Significantly spectacular was the mannequin’s improved potential to deal with intricate desk layouts, suggesting a deeper understanding of doc construction and group. These enhancements spotlight the effectiveness of our fine-tuning strategy in adapting the mannequin to specialised monetary doc processing duties.
Finest practices
Based mostly on our experiments, we recognized a number of key insights and greatest practices for fine-tuning multimodal desk construction recognition fashions:
- Mannequin efficiency is extremely depending on the standard of fine-tuning information. The nearer the fine-tuning information resembles real-world datasets, the higher the mannequin performs. Utilizing domain-specific information, we achieved a 5-point enchancment in TEDS rating with solely 10% of the information in comparison with utilizing normal datasets. Notably, fine-tuning doesn’t require huge datasets; we achieved comparatively good efficiency with just some thousand samples. Nonetheless, we noticed that imbalanced datasets, notably these missing ample examples of complicated components like lengthy tables and types with merged cells, can result in biased efficiency. Sustaining a balanced distribution of doc sorts throughout fine-tuning facilitates constant efficiency throughout numerous codecs.
- The selection of base mannequin considerably impacts efficiency. Extra highly effective base fashions yield higher outcomes. In our case, Qwen2-VL’s pre-trained visible and linguistic options supplied a powerful basis. By freezing most parameters by QLoRA in the course of the preliminary fine-tuning levels, we achieved sooner convergence and higher utilization of pre-trained information, particularly with restricted information. Curiously, the mannequin’s multilingual capabilities had been preserved; fine-tuning on English datasets alone nonetheless yielded good efficiency on Chinese language analysis datasets. This highlights the significance of choosing a suitable base mannequin for optimum efficiency.
- When real-world annotated information is proscribed, artificial information era (utilizing particular doc information synthesizers) will be an efficient resolution. Combining actual and artificial information throughout fine-tuning helps mitigate out-of-domain points, notably for uncommon or domain-specific textual content sorts. This strategy proved particularly priceless for dealing with specialised monetary terminology and sophisticated doc layouts.
Safety
One other necessary facet of our challenge includes addressing the safety concerns important when working with delicate monetary paperwork. As anticipated within the monetary providers business, sturdy safety measures have to be integrated all through the ML lifecycle. These sometimes embrace information safety by encryption at relaxation utilizing AWS Key Administration Service (AWS KMS) and in transit utilizing TLS, implementing strict S3 bucket insurance policies with digital non-public cloud (VPC) endpoints, and following least-privilege entry controls by AWS Id and Entry Administration IAM roles. For coaching environments like SageMaker HyperPod, safety concerns contain working inside non-public subnets in devoted VPCs utilizing the built-in encryption capabilities of SageMaker. Safe mannequin internet hosting with vLLM requires deployment in non-public VPC subnets with correct Amazon API Gateway protections and token-based authentication. These safety greatest practices for monetary providers be sure that delicate monetary info stays protected all through the complete ML pipeline whereas enabling modern doc processing options in extremely regulated environments.
Conclusion
Our exploration of multi-modality fashions for desk construction recognition in banking paperwork has demonstrated important enhancements in each accuracy and effectivity. The fine-tuned Qwen2-VL-7B-Instruct mannequin, educated utilizing LLaMA-Manufacturing facility on SageMaker HyperPod, has proven outstanding capabilities in dealing with complicated monetary tables and various doc codecs. These outcomes spotlight how multimodal approaches symbolize a transformative leap ahead from conventional multistage and single modality strategies, providing an end-to-end resolution for contemporary doc processing challenges.
Moreover, utilizing LLaMA-Manufacturing facility on SageMaker HyperPod considerably streamlines the fine-tuning course of, making it each extra environment friendly and accessible. The scalable infrastructure of SageMaker HyperPod permits fast experimentation by permitting seamless scaling of coaching sources. This functionality facilitates sooner iteration cycles, enabling researchers and builders to check a number of configurations and optimize mannequin efficiency extra successfully.
Discover our GitHub repository to entry the implementation and step-by-step steering, and start customizing fashions in your particular necessities. Whether or not you’re processing monetary statements, KYC paperwork, or complicated experiences, we encourage you to judge its potential for optimizing your doc workflows.
Concerning the Authors
 Tony Wong is a Options Architect at AWS primarily based in Hong Kong, specializing in monetary providers. He works with FSI prospects, notably in banking, on digital transformation journeys that deal with safety and regulatory compliance. With entrepreneurial background and expertise as a Options Architect Supervisor at an area System Integrator, Tony applies drawback administration abilities in enterprise environments. He holds an M.Sc. from The Chinese language College of Hong Kong and is passionate to leverage new applied sciences like Generative AI to assist organizations improve enterprise capabilities.
Tony Wong is a Options Architect at AWS primarily based in Hong Kong, specializing in monetary providers. He works with FSI prospects, notably in banking, on digital transformation journeys that deal with safety and regulatory compliance. With entrepreneurial background and expertise as a Options Architect Supervisor at an area System Integrator, Tony applies drawback administration abilities in enterprise environments. He holds an M.Sc. from The Chinese language College of Hong Kong and is passionate to leverage new applied sciences like Generative AI to assist organizations improve enterprise capabilities.
 Yanwei Cui, PhD, is a Senior Machine Studying Specialist Options Architect at AWS. He began machine studying analysis at IRISA (Analysis Institute of Laptop Science and Random Methods), and has a number of years of expertise constructing AI-powered industrial functions in laptop imaginative and prescient, pure language processing, and on-line consumer habits prediction. At AWS, he shares his area experience and helps prospects unlock enterprise potentials and drive actionable outcomes with machine studying at scale. Exterior of labor, he enjoys studying and touring.
Yanwei Cui, PhD, is a Senior Machine Studying Specialist Options Architect at AWS. He began machine studying analysis at IRISA (Analysis Institute of Laptop Science and Random Methods), and has a number of years of expertise constructing AI-powered industrial functions in laptop imaginative and prescient, pure language processing, and on-line consumer habits prediction. At AWS, he shares his area experience and helps prospects unlock enterprise potentials and drive actionable outcomes with machine studying at scale. Exterior of labor, he enjoys studying and touring.
 Zhihao Lin is a Deep Studying Architect on the AWS Generative AI Innovation Heart. With a Grasp’s diploma from Peking College and publications in high conferences like CVPR and IJCAI, he brings intensive AI/ML analysis expertise to his function. At AWS, He focuses on creating generative AI options, leveraging cutting-edge know-how for modern functions. He focuses on fixing complicated laptop imaginative and prescient and pure language processing challenges and advancing the sensible use of generative AI in enterprise.
Zhihao Lin is a Deep Studying Architect on the AWS Generative AI Innovation Heart. With a Grasp’s diploma from Peking College and publications in high conferences like CVPR and IJCAI, he brings intensive AI/ML analysis expertise to his function. At AWS, He focuses on creating generative AI options, leveraging cutting-edge know-how for modern functions. He focuses on fixing complicated laptop imaginative and prescient and pure language processing challenges and advancing the sensible use of generative AI in enterprise.
 Ken Tsui, VP of Machine Studying at Apoidea Group, is a seasoned machine studying engineer with over a decade of expertise in utilized analysis and B2B and B2C AI product growth. Specializing in language fashions, laptop imaginative and prescient, information curation, artificial information era, and distributed coaching, he additionally excels in credit score scoring and stress-testing. As an lively open-source researcher, he contributes to giant language mannequin and vision-language mannequin pretraining and post-training datasets.
Ken Tsui, VP of Machine Studying at Apoidea Group, is a seasoned machine studying engineer with over a decade of expertise in utilized analysis and B2B and B2C AI product growth. Specializing in language fashions, laptop imaginative and prescient, information curation, artificial information era, and distributed coaching, he additionally excels in credit score scoring and stress-testing. As an lively open-source researcher, he contributes to giant language mannequin and vision-language mannequin pretraining and post-training datasets.
 Edward Tsoi Po Wa is a Senior Information Scientist at Apoidea Group. Enthusiastic about Synthetic Intelligence, he focuses on Machine Studying, engaged on tasks like Doc Intelligence System, Giant Language Fashions R&D and Retrieval-Augmented Technology Software. Edward drives impactful AI options, optimizing techniques for industries like banking. Beside working, he holds a B.S. in Physics from Hong Kong College of Science and Expertise. In his spare time, he likes to discover science, arithmetic, and philosophy.
Edward Tsoi Po Wa is a Senior Information Scientist at Apoidea Group. Enthusiastic about Synthetic Intelligence, he focuses on Machine Studying, engaged on tasks like Doc Intelligence System, Giant Language Fashions R&D and Retrieval-Augmented Technology Software. Edward drives impactful AI options, optimizing techniques for industries like banking. Beside working, he holds a B.S. in Physics from Hong Kong College of Science and Expertise. In his spare time, he likes to discover science, arithmetic, and philosophy.
 Mickey Yip is the Vice President of Product at Apoidea Group, the place he makes use of his expertises to spearhead groundbreaking AI and digital transformation initiatives. With intensive expertise, Mickey has efficiently led complicated tasks for multinational banks, property administration companies, and world companies, delivering impactful and measurable outcomes. His experience lies in designing and launching modern AI SaaS merchandise tailor-made for the banking sector, considerably enhancing operational effectivity and enhancing shopper success.
Mickey Yip is the Vice President of Product at Apoidea Group, the place he makes use of his expertises to spearhead groundbreaking AI and digital transformation initiatives. With intensive expertise, Mickey has efficiently led complicated tasks for multinational banks, property administration companies, and world companies, delivering impactful and measurable outcomes. His experience lies in designing and launching modern AI SaaS merchandise tailor-made for the banking sector, considerably enhancing operational effectivity and enhancing shopper success.


{kind=link}