Retrieval Augmented Era (RAG) purposes have grow to be more and more fashionable on account of their capacity to boost generative AI duties with contextually related data. Implementing RAG-based purposes requires cautious consideration to safety, notably when dealing with delicate knowledge. The safety of personally identifiable data (PII), protected well being data (PHI), and confidential enterprise knowledge is essential as a result of this data flows by means of RAG programs. Failing to deal with these safety concerns can result in important dangers and potential knowledge breaches. For healthcare organizations, monetary establishments, and enterprises dealing with confidential data, these dangers may end up in regulatory compliance violations and breach of buyer belief. See the OWASP Prime 10 for Massive Language Mannequin Purposes to be taught extra concerning the distinctive safety dangers related to generative AI purposes.
Growing a complete risk mannequin on your generative AI purposes may help you determine potential vulnerabilities associated to delicate knowledge leakage, immediate injections, unauthorized knowledge entry, and extra. To help on this effort, AWS gives a spread of generative AI safety methods that you should use to create acceptable risk fashions.
Amazon Bedrock Information Bases is a totally managed functionality that simplifies the administration of the complete RAG workflow, empowering organizations to present basis fashions (FMs) and brokers contextual data out of your non-public knowledge sources to ship extra related and correct responses tailor-made to your particular wants. Moreover, with Amazon Bedrock Guardrails, you’ll be able to implement safeguards in your generative AI purposes which might be personalized to your use circumstances and accountable AI insurance policies. You’ll be able to redact delicate data similar to PII to guard privateness utilizing Amazon Bedrock Guardrails.
RAG workflow: Changing knowledge to actionable data
RAG consists of two main steps:
- Ingestion – Preprocessing unstructured knowledge, which incorporates changing the information into textual content paperwork and splitting the paperwork into chunks. Doc chunks are then encoded with an embedding mannequin to transform them to doc embeddings. These encoded doc embeddings together with the unique doc chunks within the textual content are then saved to a vector retailer, similar to Amazon OpenSearch Service.
- Augmented retrieval – At question time, the consumer’s question is first encoded with the identical embedding mannequin to transform the question into a question embedding. The generated question embedding is then used to carry out a similarity search on the saved doc embeddings to seek out and retrieve semantically related doc chunks to the question. After the doc chunks are retrieved, the consumer immediate is augmented by passing the retrieved chunks as further context, in order that the textual content era mannequin can reply the consumer question utilizing the retrieved context. If delicate knowledge isn’t sanitized earlier than ingestion, this may result in retrieving delicate knowledge from the vector retailer and inadvertently leak the delicate knowledge to unauthorized customers as a part of the mannequin response.
The next diagram reveals the architectural workflow of a RAG system, illustrating how a consumer’s question is processed by means of a number of phases to generate an knowledgeable response

Resolution overview
On this put up we current two structure patterns: knowledge redaction at storage stage and role-based entry, for shielding delicate knowledge when constructing RAG-based purposes utilizing Amazon Bedrock Information Bases.
Information redaction at storage stage – Figuring out and redacting (or masking) delicate knowledge earlier than storing them to the vector retailer (ingestion) utilizing Amazon Bedrock Information Bases. This zero-trust method to knowledge sensitivity reduces the chance of delicate data being inadvertently disclosed to unauthorized customers.
Function-based entry to delicate knowledge – Controlling selective entry to delicate data primarily based on consumer roles and permissions throughout retrieval. This method is finest in conditions the place delicate knowledge must be saved within the vector retailer, similar to in healthcare settings with distinct consumer roles like directors (medical doctors) and non-administrators (nurses or help personnel).
For all knowledge saved in Amazon Bedrock, the AWS shared duty mannequin applies.
Let’s dive in to grasp implement the information redaction at storage stage and role-based entry structure patterns successfully.
Situation 1: Establish and redact delicate knowledge earlier than ingesting into the vector retailer
The ingestion circulation implements a four-step course of to assist shield delicate knowledge when constructing RAG purposes with Amazon Bedrock:
- Supply doc processing – An AWS Lambda operate displays the incoming textual content paperwork touchdown to a supply Amazon Easy Storage Service (Amazon S3) bucket and triggers an Amazon Comprehend PII redaction job to determine and redact (or masks) delicate knowledge within the paperwork. An Amazon EventBridge rule triggers the Lambda operate each 5 minutes. The doc processing pipeline described right here solely processes textual content paperwork. To deal with paperwork containing embedded pictures, it’s best to implement further preprocessing steps to extract and analyze pictures individually earlier than ingestion.
- PII identification and redaction – The Amazon Comprehend PII redaction job analyzes the textual content content material to determine and redact PII entities. For instance, the job identifies and redacts delicate knowledge entities like identify, electronic mail, tackle, and different monetary PII entities.
- Deep safety scanning – After redaction, paperwork transfer to a different folder the place Amazon Macie verifies redaction effectiveness and identifies any remaining delicate knowledge objects. Paperwork flagged by Macie go to a quarantine bucket for guide overview, whereas cleared paperwork transfer to a redacted bucket prepared for ingestion. For extra particulars on knowledge ingestion, see Sync your knowledge along with your Amazon Bedrock data base.
- Safe data base integration – Redacted paperwork are ingested into the data base by means of a knowledge ingestion job. In case of multi-modal content material, for enhanced safety, contemplate implementing:
- A devoted picture extraction and processing pipeline.
- Picture evaluation to detect and redact delicate visible data.
- Amazon Bedrock Guardrails to filter inappropriate picture content material throughout retrieval.
This multi-layered method focuses on securing textual content content material whereas highlighting the significance of implementing further safeguards for picture processing. Organizations ought to consider their multi-modal doc necessities and lengthen the safety framework accordingly.
Ingestion circulation
The next illustration demonstrates a safe doc processing pipeline for dealing with delicate knowledge earlier than ingestion into Amazon Bedrock Information Bases.

The high-level steps are as follows:
- The doc ingestion circulation begins when paperwork containing delicate knowledge are uploaded to a monitored
inputsfolder within the supply bucket. An EventBridge rule triggers a Lambda operate (ComprehendLambda). - The
ComprehendLambdaoperate displays for brand spanking new information within theinputsfolder of the supply bucket and strikes landed information to aprocessingfolder. It then launches an asynchronous Amazon Comprehend PII redaction evaluation job and information the job ID and standing in an Amazon DynamoDBJobTrackingdesk for monitoring job completion. The Amazon Comprehend PII redaction job routinely redacts and masks delicate components similar to names, addresses, cellphone numbers, Social Safety numbers, driver’s license IDs, and banking data with the entity sort. The job replaces these recognized PII entities with placeholder tokens, similar to[NAME],[SSN]and so forth. The entities to masks may be configured utilizing RedactionConfig. For extra data, see Redacting PII entities with asynchronous jobs (API). TheMaskModein RedactionConfig is about toREPLACE_WITH_PII_ENTITY_TYPEas a substitute ofMASK; redacting with aMaskCharacterwould have an effect on the standard of retrieved paperwork as a result of many paperwork might include the identicalMaskCharacter, thereby affecting the retrieval high quality. After completion, the redacted information transfer to thefor_macie_scanfolder for secondary scanning. - The secondary verification part employs Macie for added delicate knowledge detection on the redacted information. One other Lambda operate (
MacieLambda) displays the completion of the Amazon Comprehend PII redaction job. When the job is full, the operate triggers a Macie one-time delicate knowledge detection job with information within thefor_macie_scanfolder. - The ultimate stage integrates with the Amazon Bedrock data base. The findings from Macie decide the following steps: information with excessive severity rankings (3 or larger) are moved to a
quarantinefolder for human overview by approved personnel with acceptable permissions and entry controls, whereas information with low severity rankings are moved to a chosenredactedbucket, which then triggers a knowledge ingestion job to the Amazon Bedrock data base.
This course of helps forestall delicate particulars from being uncovered when the mannequin generates responses primarily based on retrieved knowledge.
Augmented retrieval circulation
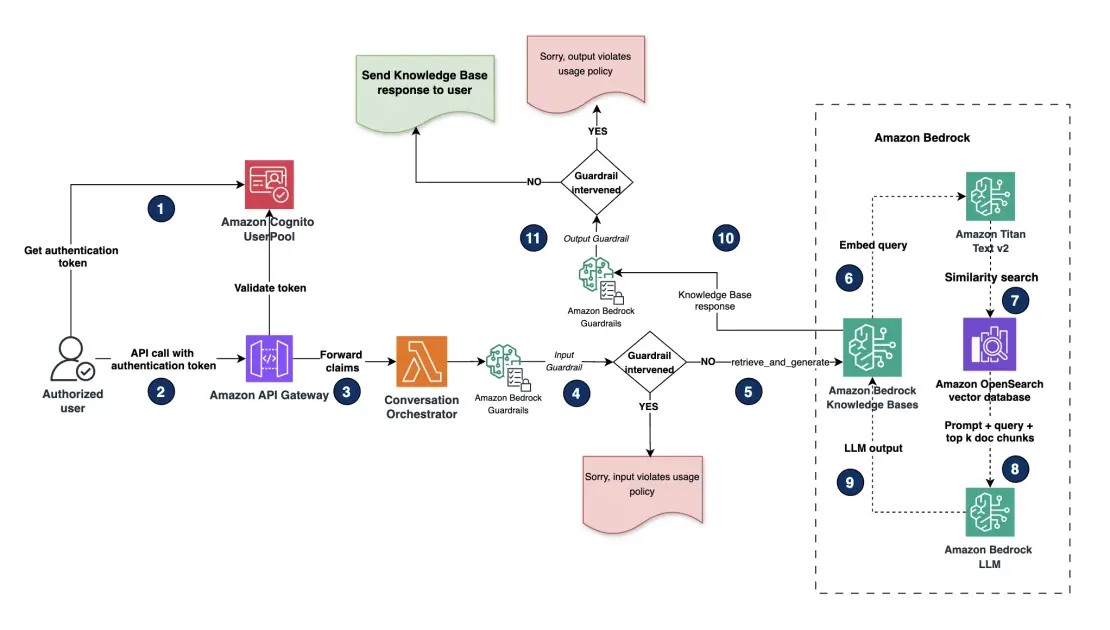
The augmented retrieval circulation diagram reveals how consumer queries are processed securely. It illustrates the entire workflow from consumer authentication by means of Amazon Cognito to response era with Amazon Bedrock, together with guardrail interventions that assist forestall coverage violations in each inputs and outputs.

The high-level steps are as follows:
- For our demo, we use an internet utility UI constructed utilizing Streamlit. The net utility launches with a login type with consumer identify and password fields.
- The consumer enters the credentials and logs in. Person credentials are authenticated utilizing Amazon Cognito consumer swimming pools. Amazon Cognito acts as our OpenID join (OIDC) identification supplier (IdP) to offer authentication and authorization companies for this utility. After authentication, Amazon Cognito generates and returns identification, entry and refresh tokens in JSON internet token (JWT) format again to the net utility. Discuss with Understanding consumer pool JSON internet tokens (JWTs) for extra data.
- After the consumer is authenticated, they’re logged in to the net utility, the place an AI assistant UI is introduced to the consumer. The consumer enters their question (immediate) within the assistant’s textual content field. The question is then forwarded utilizing a REST API name to an Amazon API Gateway endpoint together with the entry tokens within the header.
- API Gateway forwards the payload together with the claims included within the header to a dialog orchestrator Lambda operate.
- The dialog orchestrator Lambda operate processes the consumer immediate and mannequin parameters obtained from the UI and calls the RetrieveAndGenerate API to the Amazon Bedrock data base. Enter guardrails are first utilized to this request to carry out enter validation on the consumer question.
- The guardrail evaluates and applies predefined accountable AI insurance policies utilizing content material filters, denied matter filters and phrase filters on consumer enter. For extra data on creating guardrail filters, see Create a guardrail.
- If the predefined enter guardrail insurance policies are triggered on the consumer enter, the guardrails intervene and return a preconfigured message like, “Sorry, your question violates our utilization coverage.”
- Requests that don’t set off a guardrail coverage will retrieve the paperwork from the data base and generate a response utilizing the RetrieveAndGenerate. Optionally, if customers select to run Retrieve individually, guardrails may also be utilized at this stage. Guardrails throughout doc retrieval may help block delicate knowledge returned from the vector retailer.
- Throughout retrieval, Amazon Bedrock Information Bases encodes the consumer question utilizing the Amazon Titan Textual content v2 embeddings mannequin to generate a question embedding.
- Amazon Bedrock Information Bases performs a similarity search with the question embedding in opposition to the doc embeddings within the OpenSearch Service vector retailer and retrieves top-k chunks. Optionally, post-retrieval, you’ll be able to incorporate a reranking mannequin to enhance the retrieved outcomes high quality from the OpenSearch vector retailer. Discuss with Enhance the relevance of question responses with a reranker mannequin in Amazon Bedrock for extra particulars.
- Lastly, the consumer immediate is augmented with the retrieved doc chunks from the vector retailer as context and the ultimate immediate is shipped to an Amazon Bedrock basis mannequin (FM) for inference. Output guardrail insurance policies are once more utilized post-response era. If the predefined output guardrail insurance policies are triggered, the mannequin generates a predefined response like “Sorry, your question violates our utilization coverage.” If no insurance policies are triggered, then the massive language mannequin (LLM) generated response is shipped to the consumer.
To deploy Situation 1, discover the directions right here on Github
Situation 2: Implement role-based entry to PII knowledge throughout retrieval
On this situation, we reveal a complete safety method that mixes role-based entry management (RBAC) with clever PII guardrails for RAG purposes. It integrates Amazon Bedrock with AWS identification companies to routinely implement safety by means of totally different guardrail configurations for admin and non-admin customers.
The answer makes use of the metadata filtering capabilities of Amazon Bedrock Information Bases to dynamically filter paperwork throughout similarity searches utilizing metadata attributes assigned earlier than ingestion. For instance, admin and non-admin metadata attributes are created and connected to related paperwork earlier than the ingestion course of. Throughout retrieval, the system returns solely the paperwork with metadata matching the consumer’s safety function and permissions and applies the related guardrail insurance policies to both masks or block delicate knowledge detected on the LLM output.
This metadata-driven method, mixed with options like customized guardrails, real-time PII detection, masking, and complete entry logging creates a sturdy framework that maintains the safety and utility of the RAG utility whereas implementing RBAC.
The next diagram illustrates how RBAC works with metadata filtering within the vector database.

For an in depth understanding of how metadata filtering works, see Amazon Bedrock Information Bases now helps metadata filtering to enhance retrieval accuracy.
Augmented retrieval circulation
The augmented retrieval circulation diagram reveals how consumer queries are processed securely primarily based on role-based entry.

The workflow consists of the next steps:
- The consumer is authenticated utilizing an Amazon Cognito consumer pool. It generates a validation token after profitable authentication.
- The consumer question is shipped utilizing an API name together with the authentication token by means of Amazon API Gateway.
- Amazon API Gateway forwards the payload and claims to an integration Lambda operate.
- The Lambda operate extracts the claims from the header and checks for consumer function and determines whether or not to make use of an admin guardrail or a non-admin guardrail primarily based on the entry stage.
- Subsequent, the Amazon Bedrock Information Bases RetrieveAndGenerate API is invoked together with the guardrail utilized on the consumer enter.
- Amazon Bedrock Information Bases embeds the question utilizing the Amazon Titan Textual content v2 embeddings mannequin.
- Amazon Bedrock Information Bases performs similarity searches on the OpenSearch Service vector database and retrieves related chunks (optionally, you’ll be able to enhance the relevance of question responses utilizing a reranker mannequin within the data base).
- The consumer immediate is augmented with the retrieved context from the earlier step and despatched to the Amazon Bedrock FM for inference.
- Based mostly on the consumer function, the LLM output is evaluated in opposition to outlined Accountable AI insurance policies utilizing both admin or non-admin guardrails.
- Based mostly on guardrail analysis, the system both returns a “Sorry! Can’t Reply” message if the guardrail intervenes, or delivers an acceptable response with no masking on the output for admin customers or delicate knowledge masked for non-admin customers.
To deploy Situation 2, discover the directions right here on Github
This safety structure combines Amazon Bedrock guardrails with granular entry controls to routinely handle delicate data publicity primarily based on consumer permissions. The multi-layered method makes certain organizations preserve safety compliance whereas totally using their data base, proving safety and performance can coexist.
Customizing the answer
The answer provides a number of customization factors to boost its flexibility and adaptableness:
- Integration with exterior APIs – You’ll be able to combine current PII detection and redaction options with this method. The Lambda operate may be modified to make use of customized APIs for PHI or PII dealing with earlier than calling the Amazon Bedrock Information Bases API.
- Multi-modal processing – Though the present resolution focuses on textual content, it may be prolonged to deal with pictures containing PII by incorporating image-to-text conversion and caption era. For extra details about utilizing Amazon Bedrock for processing multi-modal content material throughout ingestion, see Parsing choices on your knowledge supply.
- Customized guardrails – Organizations can implement further specialised safety measures tailor-made to their particular use circumstances.
- Structured knowledge dealing with – For queries involving structured knowledge, the answer may be personalized to incorporate Amazon Redshift as a structured knowledge retailer versus OpenSearch Service. Information masking and redaction on Amazon Redshift may be achieved by making use of dynamic knowledge masking (DDM) insurance policies, together with fine-grained DDM insurance policies like role-based entry management and column-level insurance policies utilizing conditional dynamic knowledge masking.
- Agentic workflow integration – When incorporating an Amazon Bedrock data base with an agentic workflow, further safeguards may be carried out to guard delicate knowledge from exterior sources, similar to API calls, software use, agent motion teams, session state, and long-term agentic reminiscence.
- Response streaming help – The present resolution makes use of a REST API Gateway endpoint that doesn’t help streaming. For streaming capabilities, contemplate WebSocket APIs in API Gateway, Software Load Balancer (ALB), or customized options with chunked responses utilizing client-side reassembly or long-polling methods.
With these customization choices, you’ll be able to tailor the answer to your particular wants, offering a sturdy and versatile safety framework on your RAG purposes. This method not solely protects delicate knowledge but in addition maintains the utility and effectivity of the data base, permitting customers to work together with the system whereas routinely implementing role-appropriate data entry and PII dealing with.
Shared safety duty: The client’s function
At AWS, safety is our prime precedence and safety within the cloud is a shared duty between AWS and our clients. With AWS, you management your knowledge by utilizing AWS companies and instruments to find out the place your knowledge is saved, how it’s secured, and who has entry to it. Companies similar to AWS Id and Entry Administration (IAM) present strong mechanisms for securely controlling entry to AWS companies and sources.
To reinforce your safety posture additional, companies like AWS CloudTrail and Amazon Macie supply superior compliance, detection, and auditing capabilities. With regards to encryption, AWS CloudHSM and AWS Key Administration Service (KMS) allow you to generate and handle encryption keys with confidence.
For organizations in search of to ascertain governance and preserve knowledge residency controls, AWS Management Tower provides a complete resolution. For extra data on Information safety and Privateness, seek advice from Information Safety and Privateness at AWS.
Whereas our resolution demonstrates using PII detection and redaction methods, it doesn’t present an exhaustive checklist of all PII sorts or detection strategies. As a buyer, you bear the duty for implementing the suitable PII detection sorts and redaction strategies utilizing AWS companies, together with Amazon Bedrock Guardrails and different open-source libraries. The common expressions configured in Bedrock Guardrails inside this resolution function a reference instance solely and don’t cowl all attainable variations for detecting PII sorts. As an example, date of start (DOB) codecs can range broadly. Due to this fact, it falls on you to configure Bedrock Guardrails and insurance policies to precisely detect the PII sorts related to your use case. Amazon Bedrock maintains strict knowledge privateness requirements. The service doesn’t retailer or log your prompts and completions, nor does it use them to coach AWS fashions or share them with third events. We implement this by means of our Mannequin Deployment Account structure – every AWS Area the place Amazon Bedrock is out there has a devoted deployment account per mannequin supplier, managed completely by the Amazon Bedrock service workforce. Mannequin suppliers haven’t any entry to those accounts. When a mannequin is delivered to AWS, Amazon Bedrock performs a deep copy of the supplier’s inference and coaching software program into these managed accounts for deployment, ensuring that mannequin suppliers can not entry Amazon Bedrock logs or buyer prompts and completions.
Finally, whereas we offer the instruments and infrastructure, the duty for securing your knowledge utilizing AWS companies rests with you, the shopper. This shared duty mannequin makes certain that you’ve got the pliability and management to implement safety measures that align along with your distinctive necessities and compliance wants, whereas we preserve the safety of the underlying cloud infrastructure. For complete details about Amazon Bedrock safety, please seek advice from the Amazon Bedrock Safety documentation.
Conclusion
On this put up, we explored two approaches for securing delicate knowledge in RAG purposes utilizing Amazon Bedrock. The primary method centered on figuring out and redacting delicate knowledge earlier than ingestion into an Amazon Bedrock data base, and the second demonstrated a fine-grained RBAC sample for managing entry to delicate data throughout retrieval. These options characterize simply two attainable approaches amongst many for securing delicate knowledge in generative AI purposes.
Safety is a multi-layered concern that requires cautious consideration throughout all facets of your utility structure. Trying forward, we plan to dive deeper into RBAC for delicate knowledge inside structured knowledge shops when used with Amazon Bedrock Information Bases. This will present further granularity and management over knowledge entry patterns whereas sustaining safety and compliance necessities. Securing delicate knowledge in RAG purposes requires ongoing consideration to evolving safety finest practices, common auditing of entry patterns, and steady refinement of your safety controls as your purposes and necessities develop.
To reinforce your understanding of Amazon Bedrock safety implementation, discover these further sources:
The whole supply code and deployment directions for these options can be found in our GitHub repository.
We encourage you to discover the repository for detailed implementation steering and customise the options primarily based in your particular necessities utilizing the customization factors mentioned earlier.
In regards to the authors
 Praveen Chamarthi brings distinctive experience to his function as a Senior AI/ML Specialist at Amazon Net Companies, with over 20 years within the business. His ardour for Machine Studying and Generative AI, coupled along with his specialization in ML inference on Amazon SageMaker and Amazon Bedrock, permits him to empower organizations throughout the Americas to scale and optimize their ML operations. When he’s not advancing ML workloads, Praveen may be discovered immersed in books or having fun with science fiction movies. Join with him on LinkedIn to observe his insights.
Praveen Chamarthi brings distinctive experience to his function as a Senior AI/ML Specialist at Amazon Net Companies, with over 20 years within the business. His ardour for Machine Studying and Generative AI, coupled along with his specialization in ML inference on Amazon SageMaker and Amazon Bedrock, permits him to empower organizations throughout the Americas to scale and optimize their ML operations. When he’s not advancing ML workloads, Praveen may be discovered immersed in books or having fun with science fiction movies. Join with him on LinkedIn to observe his insights.
 Srikanth Reddy is a Senior AI/ML Specialist with Amazon Net Companies. He’s chargeable for offering deep, domain-specific experience to enterprise clients, serving to them use AWS AI and ML capabilities to their fullest potential. You’ll find him on LinkedIn.
Srikanth Reddy is a Senior AI/ML Specialist with Amazon Net Companies. He’s chargeable for offering deep, domain-specific experience to enterprise clients, serving to them use AWS AI and ML capabilities to their fullest potential. You’ll find him on LinkedIn.
 Dhawal Patel is a Principal Machine Studying Architect at AWS. He has labored with organizations starting from giant enterprises to mid-sized startups on issues associated to distributed computing and synthetic intelligence. He focuses on deep studying, together with NLP and pc imaginative and prescient domains. He helps clients obtain high-performance mannequin inference on Amazon SageMaker.
Dhawal Patel is a Principal Machine Studying Architect at AWS. He has labored with organizations starting from giant enterprises to mid-sized startups on issues associated to distributed computing and synthetic intelligence. He focuses on deep studying, together with NLP and pc imaginative and prescient domains. He helps clients obtain high-performance mannequin inference on Amazon SageMaker.
 Vivek Bhadauria is a Principal Engineer at Amazon Bedrock with nearly a decade of expertise in constructing AI/ML companies. He now focuses on constructing generative AI companies similar to Amazon Bedrock Brokers and Amazon Bedrock Guardrails. In his free time, he enjoys biking and mountaineering.
Vivek Bhadauria is a Principal Engineer at Amazon Bedrock with nearly a decade of expertise in constructing AI/ML companies. He now focuses on constructing generative AI companies similar to Amazon Bedrock Brokers and Amazon Bedrock Guardrails. In his free time, he enjoys biking and mountaineering.
 Brandon Rooks Sr. is a Cloud Safety Skilled with 20+ years of expertise within the IT and Cybersecurity area. Brandon joined AWS in 2019, the place he dedicates himself to serving to clients proactively improve the safety of their cloud purposes and workloads. Brandon is a lifelong learner, and holds the CISSP, AWS Safety Specialty, and AWS Options Architect Skilled certifications. Exterior of labor, he cherishes moments along with his household, partaking in numerous actions similar to sports activities, gaming, music, volunteering, and touring.
Brandon Rooks Sr. is a Cloud Safety Skilled with 20+ years of expertise within the IT and Cybersecurity area. Brandon joined AWS in 2019, the place he dedicates himself to serving to clients proactively improve the safety of their cloud purposes and workloads. Brandon is a lifelong learner, and holds the CISSP, AWS Safety Specialty, and AWS Options Architect Skilled certifications. Exterior of labor, he cherishes moments along with his household, partaking in numerous actions similar to sports activities, gaming, music, volunteering, and touring.
 Vikash Garg is a Principal Engineer at Amazon Bedrock with nearly 4 years of expertise in constructing AI/ML companies. He has a decade of expertise in constructing large-scale programs. He now focuses on constructing the generative AI service AWS Bedrock Guardrails. In his free time, he enjoys mountaineering and touring.
Vikash Garg is a Principal Engineer at Amazon Bedrock with nearly 4 years of expertise in constructing AI/ML companies. He has a decade of expertise in constructing large-scale programs. He now focuses on constructing the generative AI service AWS Bedrock Guardrails. In his free time, he enjoys mountaineering and touring.



{kind=link}