In our earlier weblog posts, we explored numerous strategies equivalent to fine-tuning giant language fashions (LLMs), immediate engineering, and Retrieval Augmented Technology (RAG) utilizing Amazon Bedrock to generate impressions from the findings part in radiology stories utilizing generative AI. Half 1 centered on mannequin fine-tuning. Half 2 launched RAG, which mixes LLMs with exterior information bases to cut back hallucinations and enhance accuracy in medical functions. By means of real-time retrieval of related medical data, RAG techniques can present extra dependable and contextually applicable responses, making them notably worthwhile for healthcare functions the place precision is essential. In each earlier posts, we used conventional metrics like ROUGE scores for efficiency analysis. This metric is appropriate for evaluating common summarization duties, however can’t successfully assess whether or not a RAG system efficiently integrates retrieved medical information or maintains medical accuracy.
In Half 3, we’re introducing an strategy to guage healthcare RAG functions utilizing LLM-as-a-judge with Amazon Bedrock. This progressive analysis framework addresses the distinctive challenges of medical RAG techniques, the place each the accuracy of retrieved medical information and the standard of generated medical content material should align with stringent requirements equivalent to clear and concise communication, medical accuracy, and grammatical accuracy. Through the use of the newest fashions from Amazon and the newly launched RAG analysis function for Amazon Bedrock Information Bases, we will now comprehensively assess how properly these techniques retrieve and use medical data to generate correct, contextually applicable responses.
This development in analysis methodology is especially essential as healthcare RAG functions turn into extra prevalent in medical settings. The LLM-as-a-judge strategy gives a extra nuanced analysis framework that considers each the standard of data retrieval and the medical accuracy of generated content material, aligning with the rigorous requirements required in healthcare.
On this submit, we display implement this analysis framework utilizing Amazon Bedrock, examine the efficiency of various generator fashions, together with Anthropic’s Claude and Amazon Nova on Amazon Bedrock, and showcase use the brand new RAG analysis function to optimize information base parameters and assess retrieval high quality. This strategy not solely establishes new benchmarks for medical RAG analysis, but additionally gives practitioners with sensible instruments to construct extra dependable and correct healthcare AI functions that may be trusted in medical settings.
Overview of the answer
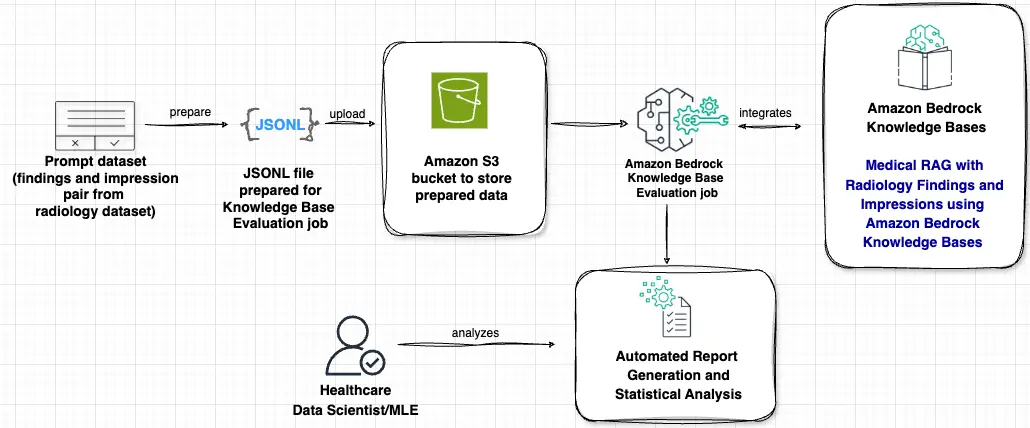
The answer makes use of Amazon Bedrock Information Bases analysis capabilities to evaluate and optimize RAG functions particularly for radiology findings and impressions. Let’s study the important thing parts of this structure within the following determine, following the info stream from left to proper.

The workflow consists of the next phases:
- Information preparation – Our analysis course of begins with a immediate dataset containing paired radiology findings and impressions. This medical information undergoes a metamorphosis course of the place it’s transformed right into a structured JSONL format, which is crucial for compatibility with the information base analysis system. After it’s ready, this formatted information is securely uploaded to an Amazon Easy Storage Service (Amazon S3) bucket, offering accessibility and information safety all through the analysis course of.
- Analysis processing – On the coronary heart of our answer lies an Amazon Bedrock Information Bases analysis job. This element processes the ready information whereas seamlessly integrating with Amazon Bedrock Information Bases. This integration is essential as a result of it allows the system to create specialised medical RAG capabilities particularly tailor-made for radiology findings and impressions, ensuring that the analysis considers each medical context and accuracy.
- Evaluation – The ultimate stage empowers healthcare information scientists with detailed analytical capabilities. By means of a sophisticated automated report technology system, professionals can entry detailed evaluation of efficiency metrics of the summarization process for impression technology. This complete reporting system allows thorough evaluation of each retrieval high quality and technology accuracy, offering worthwhile insights for system optimization and high quality assurance.
This structure gives a scientific and thorough strategy to evaluating medical RAG functions, offering each accuracy and reliability in healthcare contexts the place precision and dependability are paramount.
Dataset and background
The MIMIC Chest X-ray (MIMIC-CXR) database v2.0.0 is a big, publicly accessible dataset of chest radiographs in DICOM format with free-text radiology stories. We used the MIMIC CXR dataset consisting of 91,544 stories, which might be accessed by way of a knowledge use settlement. This requires consumer registration and the completion of a credentialing course of.
Throughout routine medical care, clinicians educated in decoding imaging research (radiologists) will summarize their findings for a selected examine in a free-text observe. The stories have been de-identified utilizing a rule-based strategy to take away protected well being data. As a result of we used solely the radiology report textual content information, we downloaded only one compressed report file (mimic-cxr-reports.zip) from the MIMIC-CXR web site. For analysis, 1,000 of the entire 2,000 stories from a subset of MIMIC-CXR dataset have been used. That is known as the dev1 dataset. One other set of 1,000 of the entire 2,000 radiology stories (known as dev2) from the chest X-ray assortment from the Indiana College hospital community have been additionally used.
RAG with Amazon Bedrock Information Bases
Amazon Bedrock Information Bases helps reap the benefits of RAG, a well-liked approach that entails drawing data from a knowledge retailer to enhance the responses generated by LLMs. We used Amazon Bedrock Information Bases to generate impressions from the findings part of the radiology stories by enriching the question with context that’s obtained from querying the information base. The information base is about as much as comprise findings and corresponding impression sections of 91,544 MIMIC-CXR radiology stories as {immediate, completion} pairs.
LLM-as-a-judge and high quality metrics
LLM-as-a-judge represents an progressive strategy to evaluating AI-generated medical content material through the use of LLMs as automated evaluators. This methodology is especially worthwhile in healthcare functions the place conventional metrics would possibly fail to seize the nuanced necessities of medical accuracy and medical relevance. Through the use of specialised prompts and analysis standards, LLM-as-a-judge can assess a number of dimensions of generated medical content material, offering a extra complete analysis framework that aligns with healthcare professionals’ requirements.
Our analysis framework encompasses 5 vital metrics, every designed to evaluate particular facets of the generated medical content material:
- Correctness – Evaluated on a 3-point Likert scale, this metric measures the factual accuracy of generated responses by evaluating them in opposition to floor reality responses. Within the medical context, this makes positive that the medical interpretations and findings align with the supply materials and accepted medical information.
- Completeness – Utilizing a 5-point Likert scale, this metric assesses whether or not the generated response comprehensively addresses the immediate holistically whereas contemplating the bottom reality response. It makes positive that vital medical findings or interpretations are usually not omitted from the response.
- Helpfulness – Measured on a 7-point Likert scale, this metric evaluates the sensible utility of the response in medical contexts, contemplating elements equivalent to readability, relevance, and actionability of the medical data offered.
- Logical coherence – Assessed on a 5-point Likert scale, this metric examines the response for logical gaps, inconsistencies, or contradictions, ensuring that medical reasoning flows naturally and maintains medical validity all through the response.
- Faithfulness – Scored on a 5-point Likert scale, this metric particularly evaluates whether or not the response incorporates data not present in or rapidly inferred from the immediate, serving to establish potential hallucinations or fabricated medical data that might be harmful in medical settings.
These metrics are normalized within the closing output and job report card, offering standardized scores that allow constant comparability throughout completely different fashions and analysis eventualities. This complete analysis framework not solely helps keep the reliability and accuracy of medical RAG techniques, but additionally gives detailed insights for steady enchancment and optimization. For particulars in regards to the metric and analysis prompts, see Evaluator prompts utilized in a information base analysis job.
Conditions
Earlier than continuing with the analysis setup, ensure you have the next:
The answer code might be discovered on the following GitHub repo.
Ensure that your information base is totally synced and prepared earlier than initiating an analysis job.
Convert the take a look at dataset into JSONL for RAG analysis
In preparation for evaluating our RAG system’s efficiency on radiology stories, we applied a knowledge transformation pipeline to transform our take a look at dataset into the required JSONL format. The next code exhibits the format of the unique dev1 and dev2 datasets:
{
"immediate": "worth of immediate key",
"completion": "worth of completion key"
}
Output Format
{
"conversationTurns": [{
"referenceResponses": [{
"content": [{
"text": "value from completion key"
}]
}],
"immediate": {
"content material": [{
"text": "value from prompt key"
}]
}
}]
}
Drawing from Wilcox’s seminal paper The Written Radiology Report, we rigorously structured our immediate to incorporate complete pointers for producing high-quality impressions:
import json
import random
import boto3
# Initialize the S3 consumer
s3 = boto3.consumer('s3')
# S3 bucket title
bucket_name = ""
# Operate to rework a single document
def transform_record(document):
return {
"conversationTurns": [
{
"referenceResponses": [
{
"content": [
{
"text": record["completion"]
}
]
}
],
"immediate": {
"content material": [
{
"text": """You're given a radiology report findings to generate a concise radiology impression from it.
A Radiology Impression is the radiologist's final concise interpretation and conclusion of medical imaging findings, typically appearing at the end of a radiology report.
n Follow these guidelines when writing the impression:
n- Use clear, understandable language avoiding obscure terms.
n- Number each impression.
n- Order impressions by importance.
n- Keep impressions concise and shorter than the findings section.
n- Write for the intended reader's understanding.n
Findings: n""" + record["prompt"]
}
]
}
}
]
}
The script processes particular person information, restructuring them to incorporate dialog turns with each the unique radiology findings and their corresponding impressions, ensuring every report maintains the skilled requirements outlined within the literature. To keep up a manageable dataset measurement set utilized by this function, we randomly sampled 1,000 information from the unique dev1 and dev2 datasets, utilizing a set random seed for reproducibility:
# Learn from enter file and write to output file
def convert_file(input_file_path, output_file_path, sample_size=1000):
# First, learn all information into a listing
information = []
with open(input_file_path, 'r', encoding='utf-8') as input_file:
for line in input_file:
information.append(json.masses(line.strip()))
# Randomly pattern 1000 information
random.seed(42) # Set the seed first
sampled_records = random.pattern(information, sample_size)
# Write the sampled and remodeled information to the output file
with open(output_file_path, 'w', encoding='utf-8') as output_file:
for document in sampled_records:
transformed_record = transform_record(document)
output_file.write(json.dumps(transformed_record) + 'n')
# Utilization
input_file_path=".jsonl" # Change along with your enter file path
output_file_path=".jsonl" # Change along with your desired output file path
convert_file(input_file_path, output_file_path)
# File paths and S3 keys for the remodeled recordsdata
transformed_files = [
{'local_file': '.jsonl', 'key': '/.jsonl'},
{'local_file': '.jsonl', 'key': '/.jsonl'}
]
# Add recordsdata to S3
for file in transformed_files:
s3.upload_file(file['local_file'], bucket_name, file['key'])
print(f"Uploaded {file['local_file']} to s3://{bucket_name}/{file['key']}")
Arrange a RAG analysis job
Our RAG analysis setup begins with establishing core configurations for the Amazon Bedrock analysis job, together with the collection of analysis and technology fashions (Anthropic’s Claude 3 Haiku and Amazon Nova Micro, respectively). The implementation incorporates a hybrid search technique with a retrieval depth of 10 outcomes, offering complete protection of the information base throughout analysis. To keep up group and traceability, every analysis job is assigned a singular identifier with timestamp data, and enter information and outcomes are systematically managed by way of designated S3 paths. See the next code:
import boto3
from datetime import datetime
# Generate distinctive title for the job
job_name = f"rag-eval-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
# Configure information base and mannequin settings
knowledge_base_id = ""
evaluator_model = "anthropic.claude-3-haiku-20240307-v1:0"
generator_model = "amazon.nova-micro-v1:0"
role_arn = ""
# Specify S3 areas
input_data = ""
output_path = ""
# Configure retrieval settings
num_results = 10
search_type = "HYBRID"
# Create Bedrock consumer
bedrock_client = boto3.consumer('bedrock')
With the core configurations in place, we provoke the analysis job utilizing the Amazon Bedrock create_evaluation_job API, which orchestrates a complete evaluation of our RAG system’s efficiency. The analysis configuration specifies 5 key metrics—correctness, completeness, helpfulness, logical coherence, and faithfulness—offering a multi-dimensional evaluation of the generated radiology impressions. The job is structured to make use of the information base for retrieval and technology duties, with the desired fashions dealing with their respective roles: Amazon Nova Micro for technology and Anthropic’s Claude 3 Haiku for analysis, and the outcomes are systematically saved within the designated S3 output location for subsequent evaluation. See the next code:
retrieve_generate_job = bedrock_client.create_evaluation_job(
jobName=job_name,
jobDescription="Consider retrieval and technology",
roleArn=role_arn,
applicationType="RagEvaluation",
inferenceConfig={
"ragConfigs": [{
"knowledgeBaseConfig": {
"retrieveAndGenerateConfig": {
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": knowledge_base_id,
"modelArn": generator_model,
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults": num_results,
"overrideSearchType": search_type
}
}
}
}
}
}]
},
outputDataConfig={
"s3Uri": output_path
},
evaluationConfig={
"automated": {
"datasetMetricConfigs": [{
"taskType": "Custom",
"dataset": {
"name": "RagDataset",
"datasetLocation": {
"s3Uri": input_data
}
},
"metricNames": [
"Builtin.Correctness",
"Builtin.Completeness",
"Builtin.Helpfulness",
"Builtin.LogicalCoherence",
"Builtin.Faithfulness"
]
}],
"evaluatorModelConfig": {
"bedrockEvaluatorModels": [{
"modelIdentifier": evaluator_model
}]
}
}
}
)
Analysis outcomes and metrics comparisons
The analysis outcomes for the healthcare RAG functions, utilizing datasets dev1 and dev2, display robust efficiency throughout the desired metrics. For the dev1 dataset, the scores have been as follows: correctness at 0.98, completeness at 0.95, helpfulness at 0.83, logical coherence at 0.99, and faithfulness at 0.79. Equally, the dev2 dataset yielded scores of 0.97 for correctness, 0.95 for completeness, 0.83 for helpfulness, 0.98 for logical coherence, and 0.82 for faithfulness. These outcomes point out that the RAG system successfully retrieves and makes use of medical data to generate correct and contextually applicable responses, with notably excessive scores in correctness and logical coherence, suggesting strong factual accuracy and logical consistency within the generated content material.
The next screenshot exhibits the analysis abstract for the dev1 dataset.

The next screenshot exhibits the analysis abstract for the dev2 dataset.

Moreover, as proven within the following screenshot, the LLM-as-a-judge framework permits for the comparability of a number of analysis jobs throughout completely different fashions, datasets, and prompts, enabling detailed evaluation and optimization of the RAG system’s efficiency.

Moreover, you’ll be able to carry out an in depth evaluation by drilling down and investigating the outlier circumstances with least efficiency metrics equivalent to correctness, as proven within the following screenshot.

Metrics explainability
The next screenshot showcases the detailed metrics explainability interface of the analysis system, displaying instance conversations with their corresponding metrics evaluation. Every dialog entry contains 4 key columns: Dialog enter, Technology output, Retrieved sources, and Floor reality, together with a Rating column. The system gives a complete view of 1,000 examples, with navigation controls to flick thru the dataset. Of explicit observe is the retrieval depth indicator exhibiting 10 for every dialog, demonstrating constant information base utilization throughout examples.
The analysis framework allows detailed monitoring of technology metrics and gives transparency into how the information base arrives at its outputs. Every instance dialog presents the whole chain of data, from the preliminary immediate by way of to the ultimate evaluation. The system shows the retrieved context that knowledgeable the technology, the precise generated response, and the bottom reality for comparability. A scoring mechanism evaluates every response, with an in depth rationalization of the decision-making course of seen by way of an expandable interface (as proven by the pop-up within the screenshot). This granular stage of element permits for thorough evaluation of the RAG system’s efficiency and helps establish areas for optimization in each retrieval and technology processes.

On this particular instance from the Indiana College Medical System dataset (dev2), we see a transparent evaluation of the system’s efficiency in producing a radiology impression for chest X-ray findings. The information base efficiently retrieved related context (proven by 10 retrieved sources) to generate an impression stating “Regular coronary heart measurement and pulmonary vascularity 2. Unremarkable mediastinal contour 3. No focal consolidation, pleural effusion, or pneumothorax 4. No acute bony findings.” The analysis system scored this response with an ideal correctness rating of 1, noting within the detailed rationalization that the candidate response precisely summarized the important thing findings and accurately concluded there was no acute cardiopulmonary course of, aligning exactly with the bottom reality response.

Within the following screenshot, the analysis system scored this response with a low rating of 0.5, noting within the detailed rationalization the bottom reality response offered is “Average hiatal hernia. No particular pneumonia.” This means that the important thing findings from the radiology report are the presence of a average hiatal hernia and the absence of any particular pneumonia. The candidate response covers the important thing discovering of the average hiatal hernia, which is accurately recognized as one of many impressions. Nevertheless, the candidate response additionally contains extra impressions that aren’t talked about within the floor reality, equivalent to regular lung fields, regular coronary heart measurement, unfolded aorta, and degenerative modifications within the backbone. Though these extra impressions is perhaps correct primarily based on the offered findings, they don’t seem to be explicitly said within the floor reality response. Due to this fact, the candidate response is partially right and partially incorrect primarily based on the bottom reality.
Clear up
To keep away from incurring future prices, delete the S3 bucket, information base, and different assets that have been deployed as a part of the submit.
Conclusion
The implementation of LLM-as-a-judge for evaluating healthcare RAG functions represents a big development in sustaining the reliability and accuracy of AI-generated medical content material. By means of this complete analysis framework utilizing Amazon Bedrock Information Bases, we’ve demonstrated how automated evaluation can present detailed insights into the efficiency of medical RAG techniques throughout a number of vital dimensions. The high-performance scores throughout each datasets point out the robustness of this strategy, although these metrics are only the start.
Trying forward, this analysis framework might be expanded to embody broader healthcare functions whereas sustaining the rigorous requirements important for medical functions. The dynamic nature of medical information and medical practices necessitates an ongoing dedication to analysis, making steady evaluation a cornerstone of profitable implementation.
By means of this sequence, we’ve demonstrated how you should use Amazon Bedrock to create and consider healthcare generative AI functions with the precision and reliability required in medical settings. As organizations proceed to refine these instruments and methodologies, prioritizing accuracy, security, and medical utility in healthcare AI functions stays paramount.
Concerning the Authors
 Adewale Akinfaderin is a Sr. Information Scientist–Generative AI, Amazon Bedrock, the place he contributes to innovative improvements in foundational fashions and generative AI functions at AWS. His experience is in reproducible and end-to-end AI/ML strategies, sensible implementations, and serving to world prospects formulate and develop scalable options to interdisciplinary issues. He has two graduate levels in physics and a doctorate in engineering.
Adewale Akinfaderin is a Sr. Information Scientist–Generative AI, Amazon Bedrock, the place he contributes to innovative improvements in foundational fashions and generative AI functions at AWS. His experience is in reproducible and end-to-end AI/ML strategies, sensible implementations, and serving to world prospects formulate and develop scalable options to interdisciplinary issues. He has two graduate levels in physics and a doctorate in engineering.
 Priya Padate is a Senior Companion Answer Architect supporting healthcare and life sciences worldwide at Amazon Net Companies. She has over 20 years of healthcare business expertise main architectural options in areas of medical imaging, healthcare associated AI/ML options and techniques for cloud migrations. She is obsessed with utilizing expertise to rework the healthcare business to drive higher affected person care outcomes.
Priya Padate is a Senior Companion Answer Architect supporting healthcare and life sciences worldwide at Amazon Net Companies. She has over 20 years of healthcare business expertise main architectural options in areas of medical imaging, healthcare associated AI/ML options and techniques for cloud migrations. She is obsessed with utilizing expertise to rework the healthcare business to drive higher affected person care outcomes.
 Dr. Ekta Walia Bhullar is a principal AI/ML/GenAI advisor with AWS Healthcare and Life Sciences enterprise unit. She has in depth expertise in growth of AI/ML functions for healthcare particularly in Radiology. Throughout her tenure at AWS she has actively contributed to functions of AI/ML/GenAI inside lifescience area equivalent to for medical, drug growth and industrial traces of enterprise.
Dr. Ekta Walia Bhullar is a principal AI/ML/GenAI advisor with AWS Healthcare and Life Sciences enterprise unit. She has in depth expertise in growth of AI/ML functions for healthcare particularly in Radiology. Throughout her tenure at AWS she has actively contributed to functions of AI/ML/GenAI inside lifescience area equivalent to for medical, drug growth and industrial traces of enterprise.



{kind=link}