On this article, you’ll learn the way vector databases work, from the essential thought of similarity search to the indexing methods that make large-scale retrieval sensible.
Subjects we’ll cowl embody:
- How embeddings flip unstructured information into vectors that may be searched by similarity.
- How vector databases help nearest neighbor search, metadata filtering, and hybrid retrieval.
- How indexing strategies equivalent to HNSW, IVF, and PQ assist vector search scale in manufacturing.
Let’s not waste any extra time.
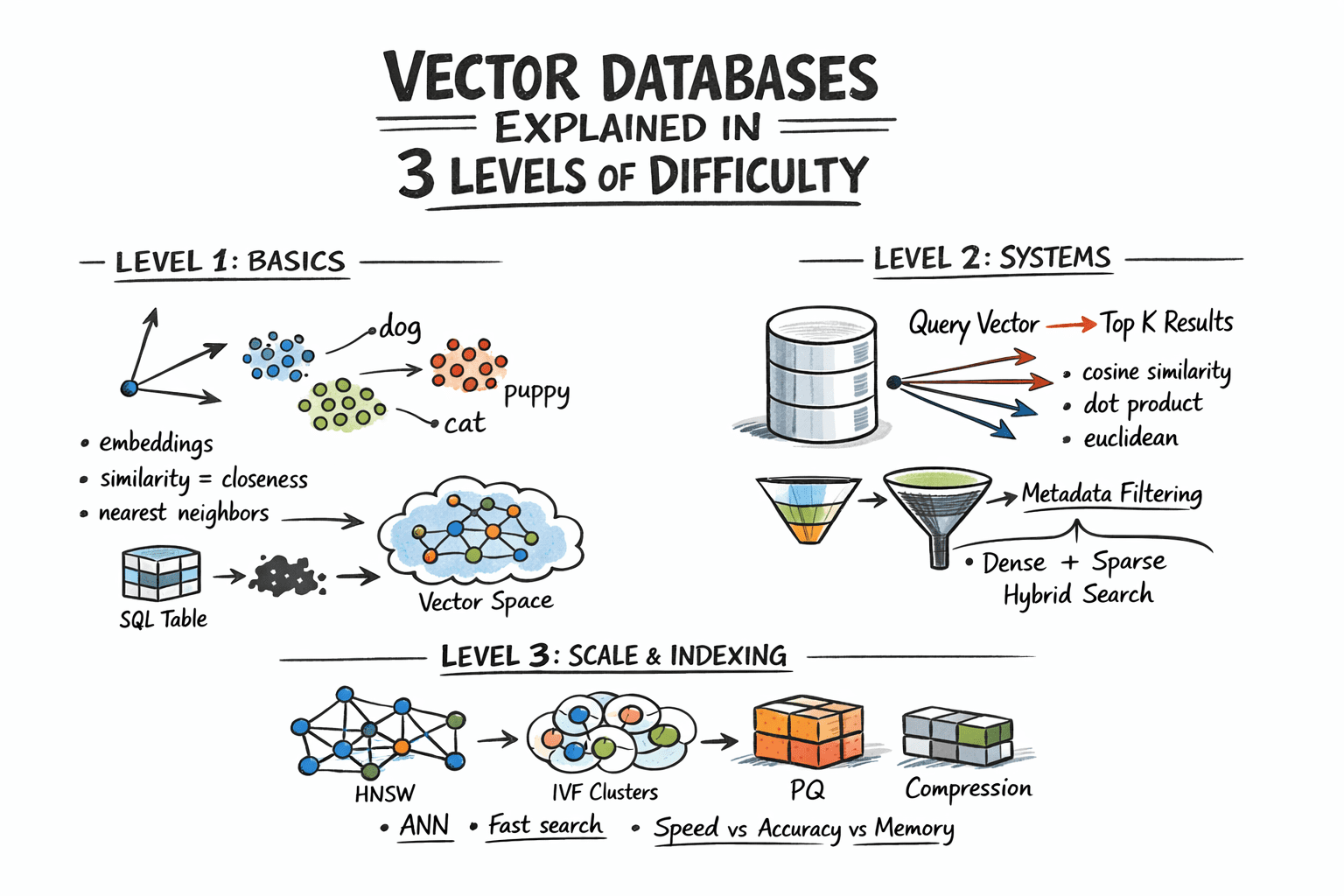
Vector Databases Defined in 3 Ranges of Issue
Picture by Writer
Introduction
Conventional databases reply a well-defined query: does the document matching these standards exist? Vector databases reply a unique one: which data are most much like this? This shift issues as a result of an enormous class of contemporary information — paperwork, photos, consumer conduct, audio — can’t be searched by actual match. So the suitable question will not be “discover this,” however “discover what’s near this.” Embedding fashions make this attainable by changing uncooked content material into vectors, the place geometric proximity corresponds to semantic similarity.
The issue, nonetheless, is scale. Evaluating a question vector towards each saved vector means billions of floating-point operations at manufacturing information sizes, and that math makes real-time search impractical. Vector databases remedy this with approximate nearest neighbor algorithms that skip the overwhelming majority of candidates and nonetheless return outcomes almost equivalent to an exhaustive search, at a fraction of the associated fee.
This text explains how that works at three ranges: the core similarity downside and what vectors allow, how manufacturing techniques retailer and question embeddings with filtering and hybrid search, and eventually the indexing algorithms and structure selections that make all of it work at scale.
Stage 1: Understanding the Similarity Drawback
Conventional databases retailer structured information — rows, columns, integers, strings — and retrieve it with actual lookups or vary queries. SQL is quick and exact for this. However a whole lot of real-world information will not be structured. Textual content paperwork, photos, audio, and consumer conduct logs don’t match neatly into columns, and “actual match” is the incorrect question for them.
The answer is to characterize this information as vectors: fixed-length arrays of floating-point numbers. An embedding mannequin like OpenAI’s text-embedding-3-small, or a imaginative and prescient mannequin for photos, converts uncooked content material right into a vector that captures its semantic that means. Related content material produces comparable vectors. For instance, the phrase “canine” and the phrase “pet” find yourself geometrically shut in vector area. A photograph of a cat and a drawing of a cat additionally find yourself shut.
A vector database shops these embeddings and allows you to search by similarity: “discover me the ten vectors closest to this question vector.” That is referred to as nearest neighbor search.
Stage 2: Storing and Querying Vectors
Embeddings
Earlier than a vector database can do something, content material must be transformed into vectors. That is completed by embedding fashions — neural networks that map enter right into a dense vector area, usually with 256 to 4096 dimensions relying on the mannequin. The precise numbers within the vector should not have direct interpretations; what issues is the geometry: shut vectors imply comparable content material.
You name an embedding API or run a mannequin your self, get again an array of floats, and retailer that array alongside your doc metadata.
Distance Metrics
Similarity is measured as geometric distance between vectors. Three metrics are frequent:
- Cosine similarity measures the angle between two vectors, ignoring magnitude. It’s typically used for textual content embeddings, the place course issues greater than size.
- Euclidean distance measures straight-line distance in vector area. It’s helpful when magnitude carries that means.
- Dot product is quick and works nicely when vectors are normalized. Many embedding fashions are skilled to make use of it.
The selection of metric ought to match how your embedding mannequin was skilled. Utilizing the incorrect metric degrades consequence high quality.
The Nearest Neighbor Drawback
Discovering actual nearest neighbors is trivial in small datasets: compute the space from the question to each vector, type the outcomes, and return the highest Okay. That is referred to as brute-force or flat search, and it’s 100% correct. It additionally scales linearly with dataset dimension. At 10 million vectors with 1536 dimensions every, a flat search is simply too gradual for real-time queries.
The answer is approximate nearest neighbor (ANN) algorithms. These commerce a small quantity of accuracy for big beneficial properties in pace. Manufacturing vector databases run ANN algorithms underneath the hood. The precise algorithms, their parameters, and their tradeoffs are what we’ll study within the subsequent degree.
Metadata Filtering
Pure vector search returns essentially the most semantically comparable objects globally. In follow, you often need one thing nearer to: “discover essentially the most comparable paperwork that belong to this consumer and have been created after this date.” That’s hybrid retrieval: vector similarity mixed with attribute filters.
Implementations differ. Pre-filtering applies the attribute filter first, then runs ANN on the remaining subset. Publish-filtering runs ANN first, then filters the outcomes. Pre-filtering is extra correct however costlier for selective queries. Most manufacturing databases use some variant of pre-filtering with good indexing to maintain it quick.
Hybrid Search: Dense + Sparse
Pure dense vector search can miss keyword-level precision. A question for “GPT-5 launch date” would possibly semantically drift towards common AI subjects relatively than the particular doc containing the precise phrase. Hybrid search combines dense ANN with sparse retrieval (BM25 or TF-IDF) to get semantic understanding and key phrase precision collectively.
The usual method is to run dense and sparse search in parallel, then mix scores utilizing reciprocal rank fusion (RRF) — a rank-based merging algorithm that doesn’t require rating normalization. Most manufacturing techniques now help hybrid search natively.
Stage 3: Indexing for Scale
Approximate Nearest Neighbor Algorithms
The three most essential approximate nearest neighbor algorithms every occupy a unique level on the tradeoff floor between pace, reminiscence utilization, and recall.
Hierarchical navigable small world (HNSW) builds a multi-layer graph the place every vector is a node, with edges connecting comparable neighbors. Larger layers are sparse and allow quick long-range traversal; decrease layers are denser for exact native search. At question time, the algorithm hops by this graph towards the closest neighbors. HNSW is quick, memory-hungry, and delivers glorious recall. It’s the default in lots of fashionable techniques.
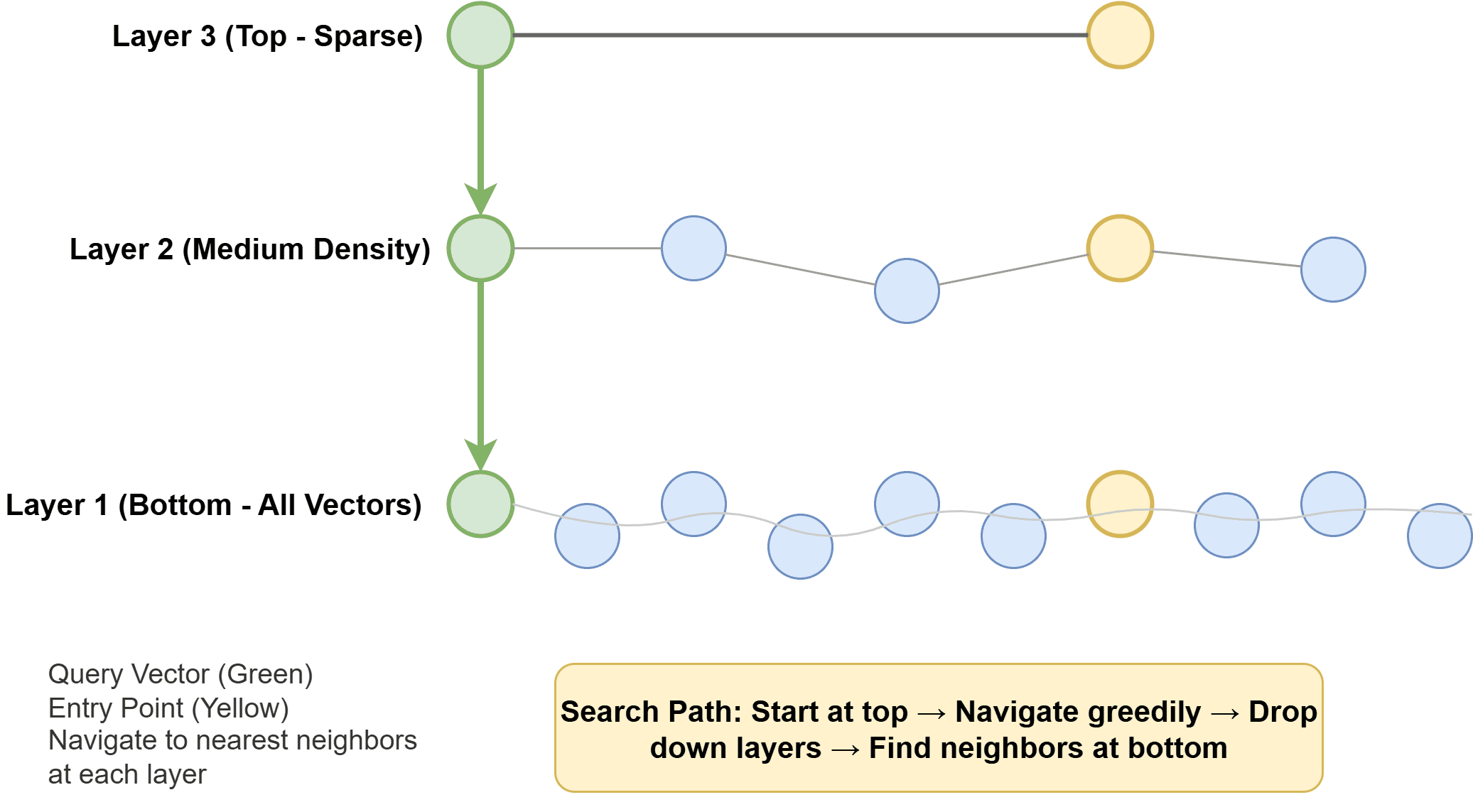
How Hierarchical Navigable Small World Works
Inverted file index (IVF) clusters vectors into teams utilizing k-means, builds an inverted index that maps every cluster to its members, after which searches solely the closest clusters at question time. IVF makes use of much less reminiscence than HNSW however is commonly considerably slower and requires a coaching step to construct the clusters.
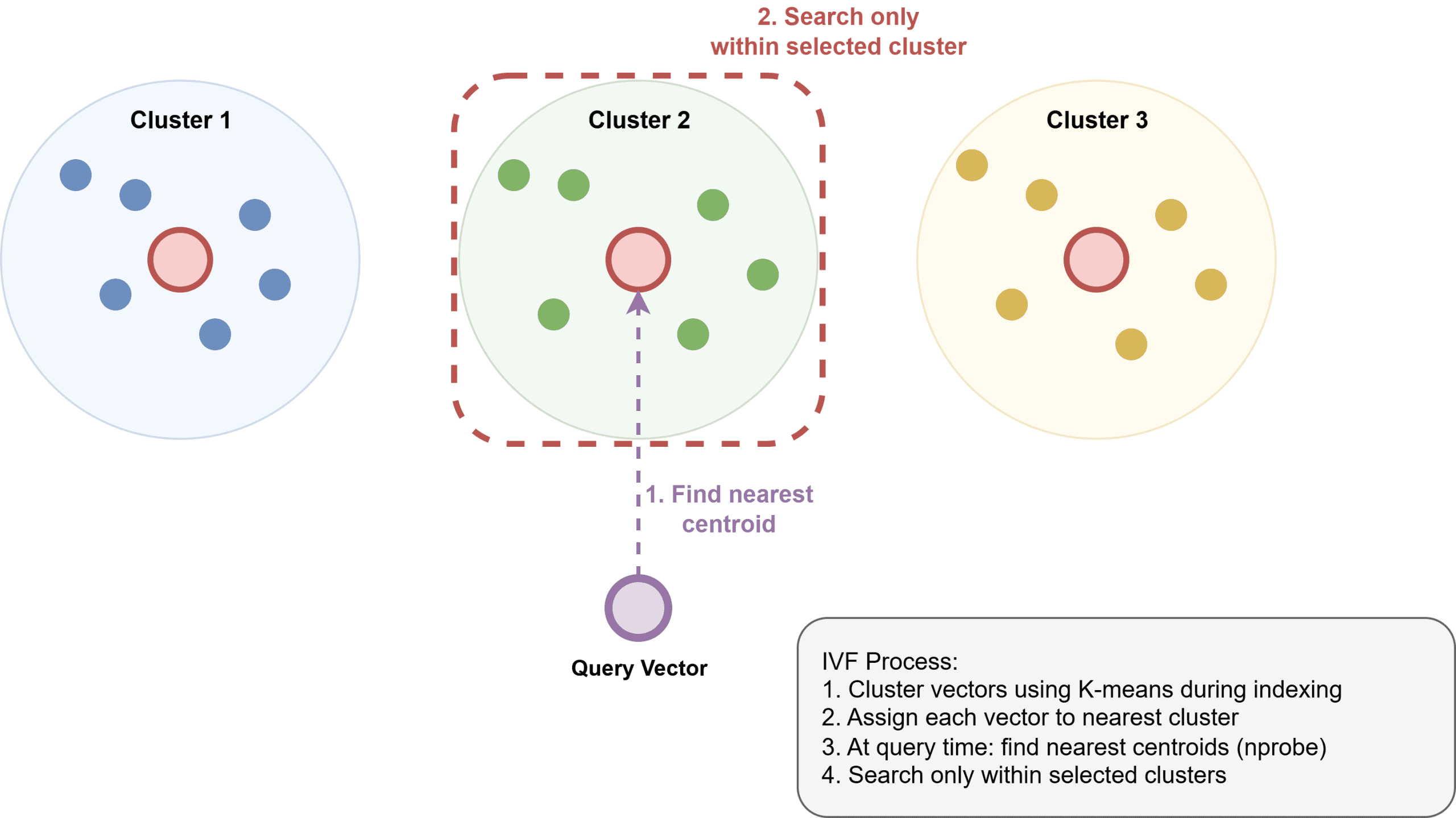
How Inverted File Index Works
Product Quantization (PQ) compresses vectors by dividing them into subvectors and quantizing every one to a codebook. This may scale back reminiscence use by 4–32x, enabling billion-scale datasets. It’s typically utilized in mixture with IVF as IVF-PQ in techniques like Faiss.
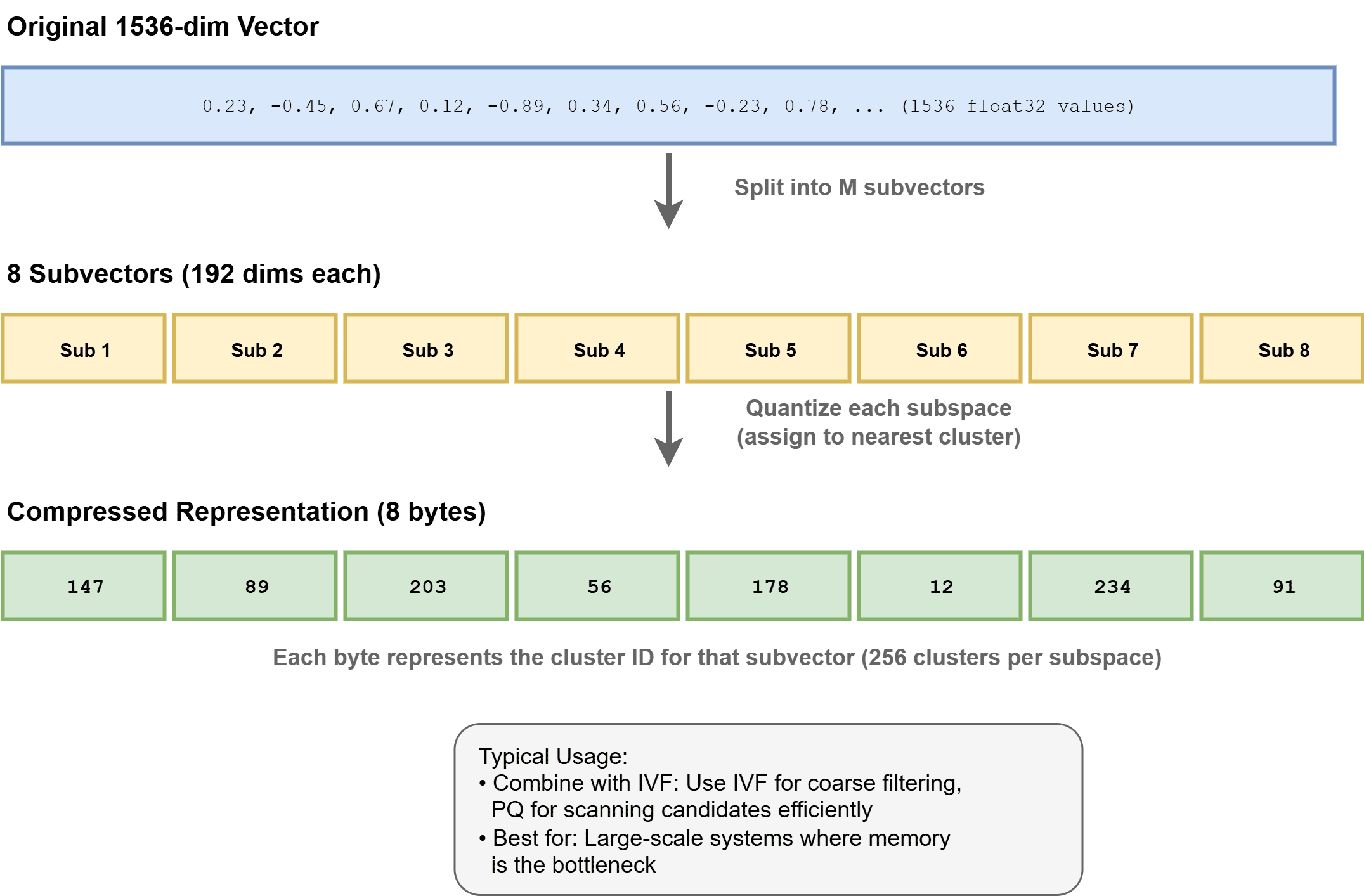
How Product Quantization Works
Index Configuration
HNSW has two principal parameters: ef_construction and M:
ef_constructioncontrols what number of neighbors are thought-about throughout index development. Larger values typically enhance recall however take longer to construct.Mcontrols the variety of bi-directional hyperlinks per node. LargerMoften improves recall however will increase reminiscence utilization.
You tune these based mostly in your recall, latency, and reminiscence finances.
At question time, ef_search controls what number of candidates are explored. Growing it improves recall at the price of latency. This can be a runtime parameter you’ll be able to tune with out rebuilding the index.
For IVF, nlist units the variety of clusters, and nprobe units what number of clusters to go looking at question time. Extra clusters can enhance precision but in addition require extra reminiscence. Larger nprobe improves recall however will increase latency. Learn How can the parameters of an IVF index (just like the variety of clusters nlist and the variety of probes nprobe) be tuned to attain a goal recall on the quickest attainable question pace? to study extra.
Recall vs. Latency
ANN lives on a tradeoff floor. You may at all times get higher recall by looking extra of the index, however you pay for it in latency and compute. Benchmark your particular dataset and question patterns. A recall@10 of 0.95 could be nice for a search software; a advice system would possibly want 0.99.
Scale and Sharding
A single HNSW index can slot in reminiscence on one machine as much as roughly 50–100 million vectors, relying on dimensionality and out there RAM. Past that, you shard: partition the vector area throughout nodes and fan out queries throughout shards, then merge the outcomes. This introduces coordination overhead and requires cautious shard-key choice to keep away from scorching spots. To study extra, learn How does vector search scale with information dimension?
Storage Backends
Vectors are sometimes saved in RAM for quick ANN search. Metadata is often saved individually, typically in a key-value or columnar retailer. Some techniques help memory-mapped recordsdata to index datasets which might be bigger than RAM, spilling to disk when wanted. This trades some latency for scale.
On-disk ANN indexes like DiskANN (developed by Microsoft) are designed to run from SSDs with minimal RAM. They obtain good recall and throughput for very massive datasets the place reminiscence is the binding constraint.
Vector Database Choices
Vector search instruments typically fall into three classes.
First, you’ll be able to select from purpose-built vector databases equivalent to:
- Pinecone: a completely managed, no-operations resolution
- Qdrant: an open-source, Rust-based system with robust filtering capabilities
- Weaviate: an open-source choice with built-in schema and modular options
- Milvus: a high-performance, open-source vector database designed for large-scale similarity search with help for distributed deployments and GPU acceleration
Second, there are extensions to current techniques, equivalent to pgvector for Postgres, which works nicely at small to medium scale.
Third, there are libraries equivalent to:
For brand spanking new retrieval-augmented technology (RAG) purposes at average scale, pgvector is commonly place to begin in case you are already utilizing Postgres as a result of it minimizes operational overhead. As your wants develop — particularly with bigger datasets or extra complicated filtering — Qdrant or Weaviate can turn out to be extra compelling choices, whereas Pinecone is good in case you choose a completely managed resolution with no infrastructure to keep up.
Wrapping Up
Vector databases remedy an actual downside: discovering what’s semantically comparable at scale, shortly. The core thought is easy: embed content material as vectors and search by distance. The implementation particulars — HNSW vs. IVF, recall tuning, hybrid search, and sharding — matter so much at manufacturing scale.
Listed here are just a few sources you’ll be able to discover additional:
Completely satisfied studying!


{kind=link}