a small NumPy challenge collection the place I attempt to truly construct one thing with NumPy as a substitute of simply going by random capabilities and documentation. I’ve all the time felt that one of the best ways to study is by doing, so on this challenge, I needed to create one thing each sensible and private.
The concept was easy: analyze my every day habits — sleep, examine hours, display time, train, and temper — and see how they have an effect on my productiveness and common well-being. The info isn’t actual; it’s fictional, simulated over 30 days. However the objective isn’t the accuracy of the information — it’s studying learn how to use NumPy meaningfully.
So let’s stroll by the method step-by-step.
Step 1 — Loading and Understanding the Knowledge
I began by making a easy NumPy array that contained 30 rows (one for every day) and 6 columns — every column representing a distinct behavior metric. Then I saved it as a .npy file so I might simply load it later.
# TODO: Import NumPy and cargo the .npy knowledge file
import numpy as np
knowledge = np.load(‘activity_data.npy’)As soon as loaded, I needed to substantiate that the whole lot regarded as anticipated. So I checked the form (to know what number of rows and columns there have been) and the variety of dimensions (to substantiate it’s a 2D desk, not a 1D listing).
# TODO: Print array form, first few rows, and many others.
knowledge.form
knowledge.ndimOUTPUT: 30 rows, 6 columns, and ndim=2
I additionally printed out the primary few rows simply to visually verify that every worth regarded nice — as an illustration, that sleep hours weren’t detrimental or that the temper values had been inside an inexpensive vary.
# TODO: Prime 5 rows
knowledge[:5]Output:
array([[ 1. , 6.5, 5. , 4.2, 20. , 6. ],
[ 2. , 7.2, 6. , 3.1, 35. , 7. ],
[ 3. , 5.8, 4. , 5.5, 0. , 5. ],
[ 4. , 8. , 7. , 2.5, 30. , 8. ],
[ 5. , 6. , 5. , 4.8, 10. , 6. ]])Step 2 — Validating the Knowledge
Earlier than doing any evaluation, I needed to verify the information made sense. It’s one thing we frequently skip when working with fictional knowledge, however it’s nonetheless good observe.
So I checked:
- No detrimental sleep hours
- No temper scores lower than 1 or better than 10
For sleep, that meant choosing the sleep column (index 1 in my array) and checking if any values had been under zero.
# Be sure that values are affordable (no detrimental sleep)
knowledge[:, 1] < 0Output:
array([False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False])This implies no negatives. Then I did the identical for temper. I counted to search out that the temper column was at index 5, and checked if any had been under 1 or above 10.
# Is temper out of vary?
knowledge[:, 5] < 1
knowledge[:, 5] > 10We acquired the identical output.
The whole lot regarded good, so we might transfer on.
Step 3 — Splitting the Knowledge into Weeks
I had 30 days of information, and I needed to investigate it week by week. The primary intuition was to make use of NumPy’s break up() operate, however that failed as a result of 30 isn’t evenly divisible by 4. So as a substitute, I used np.array_split(), which permits uneven splits.
That gave me:
- Week 1 → 8 days
- Week 2 → 8 days
- Week 3 → 7 days
- Week 4 → 7 days
# TODO: Slice knowledge into week 1, week 2, week 3, week 4
weekly_data = np.array_split(knowledge, 4)
weekly_dataOutput:
[array([[ 1. , 6.5, 5. , 4.2, 20. , 6. ],
[ 2. , 7.2, 6. , 3.1, 35. , 7. ],
[ 3. , 5.8, 4. , 5.5, 0. , 5. ],
[ 4. , 8. , 7. , 2.5, 30. , 8. ],
[ 5. , 6. , 5. , 4.8, 10. , 6. ],
[ 6. , 7.5, 6. , 3.3, 25. , 7. ],
[ 7. , 8.2, 3. , 6.1, 40. , 7. ],
[ 8. , 6.3, 4. , 5. , 15. , 6. ]]),
array([[ 9. , 7. , 6. , 3.2, 30. , 7. ],
[10. , 5.5, 3. , 6.8, 0. , 5. ],
[11. , 7.8, 7. , 2.9, 25. , 8. ],
[12. , 6.1, 5. , 4.5, 15. , 6. ],
[13. , 7.4, 6. , 3.7, 30. , 7. ],
[14. , 8.1, 2. , 6.5, 50. , 7. ],
[15. , 6.6, 5. , 4.1, 20. , 6. ],
[16. , 7.3, 6. , 3.4, 35. , 7. ]]),
array([[17. , 5.9, 4. , 5.6, 5. , 5. ],
[18. , 8.3, 7. , 2.6, 30. , 8. ],
[19. , 6.2, 5. , 4.3, 10. , 6. ],
[20. , 7.6, 6. , 3.1, 25. , 7. ],
[21. , 8.4, 3. , 6.3, 40. , 7. ],
[22. , 6.4, 4. , 5.1, 15. , 6. ],
[23. , 7.1, 6. , 3.3, 30. , 7. ]]),
array([[24. , 5.7, 3. , 6.7, 0. , 5. ],
[25. , 7.9, 7. , 2.8, 25. , 8. ],
[26. , 6.2, 5. , 4.4, 15. , 6. ],
[27. , 7.5, 6. , 3.5, 30. , 7. ],
[28. , 8. , 2. , 6.4, 50. , 7. ],
[29. , 6.5, 5. , 4.2, 20. , 6. ],
[30. , 7.4, 6. , 3.6, 35. , 7. ]])]Now the information was in 4 chunks, and I might simply analyze every one individually.
Step 4 — Calculating Weekly Metrics
I needed to get a way of how every behavior modified from week to week. So I targeted on 4 most important issues:
- Common sleep
- Common examine hours
- Common display time
- Common temper rating
I saved every week’s array in a separate variable, then used np.imply() to calculate the averages for every metric.
Common sleep hours
# retailer into variables
week_1 = weekly_data[0]
week_2 = weekly_data[1]
week_3 = weekly_data[2]
week_4 = weekly_data[3]
# TODO: Compute common sleep
week1_avg_sleep = np.imply(week_1[:, 1])
week2_avg_sleep = np.imply(week_2[:, 1])
week3_avg_sleep = np.imply(week_3[:, 1])
week4_avg_sleep = np.imply(week_4[:, 1])Common examine hours
# TODO: Compute common examine hours
week1_avg_study = np.imply(week_1[:, 2])
week2_avg_study = np.imply(week_2[:, 2])
week3_avg_study = np.imply(week_3[:, 2])
week4_avg_study = np.imply(week_4[:, 2])Common display time
# TODO: Compute common display time
week1_avg_screen = np.imply(week_1[:, 3])
week2_avg_screen = np.imply(week_2[:, 3])
week3_avg_screen = np.imply(week_3[:, 3])
week4_avg_screen = np.imply(week_4[:, 3])Common temper rating
# TODO: Compute common temper rating
week1_avg_mood = np.imply(week_1[:, 5])
week2_avg_mood = np.imply(week_2[:, 5])
week3_avg_mood = np.imply(week_3[:, 5])
week4_avg_mood = np.imply(week_4[:, 5])Then, to make the whole lot simpler to learn, I formatted the outcomes properly.
# TODO: Show weekly outcomes clearly
print(f”Week 1 — Common sleep: {week1_avg_sleep:.2f} hrs, Examine: {week1_avg_study:.2f} hrs, “
f”Display screen time: {week1_avg_screen:.2f} hrs, Temper rating: {week1_avg_mood:.2f}”)
print(f”Week 2 — Common sleep: {week2_avg_sleep:.2f} hrs, Examine: {week2_avg_study:.2f} hrs, “
f”Display screen time: {week2_avg_screen:.2f} hrs, Temper rating: {week2_avg_mood:.2f}”)
print(f”Week 3 — Common sleep: {week3_avg_sleep:.2f} hrs, Examine: {week3_avg_study:.2f} hrs, “
f”Display screen time: {week3_avg_screen:.2f} hrs, Temper rating: {week3_avg_mood:.2f}”)
print(f”Week 4 — Common sleep: {week4_avg_sleep:.2f} hrs, Examine: {week4_avg_study:.2f} hrs, “
f”Display screen time: {week4_avg_screen:.2f} hrs, Temper rating: {week4_avg_mood:.2f}”)Output:
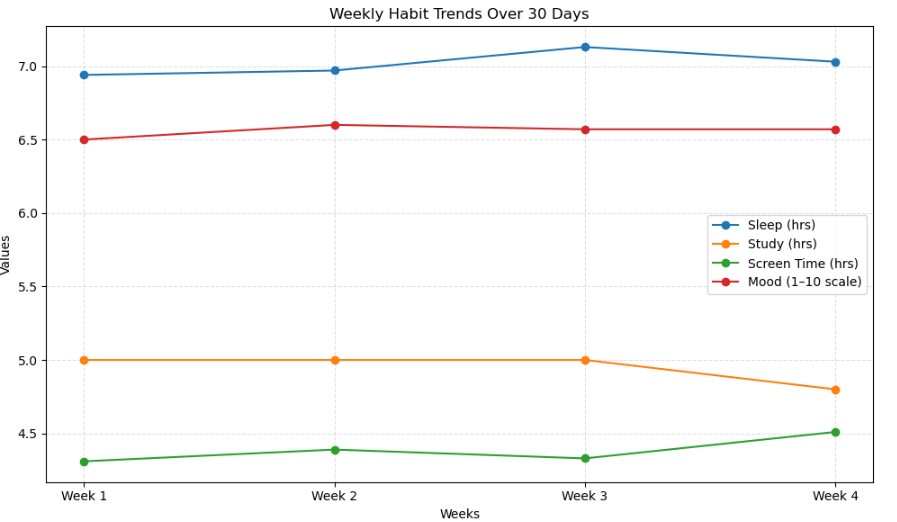
Week 1 – Common sleep: 6.94 hrs, Examine: 5.00 hrs, Display screen time: 4.31 hrs, Temper rating: 6.50
Week 2 – Common sleep: 6.97 hrs, Examine: 5.00 hrs, Display screen time: 4.39 hrs, Temper rating: 6.62
Week 3 – Common sleep: 7.13 hrs, Examine: 5.00 hrs, Display screen time: 4.33 hrs, Temper rating: 6.57
Week 4 – Common sleep: 7.03 hrs, Examine: 4.86 hrs, Display screen time: 4.51 hrs, Temper rating: 6.57Step 5 — Making Sense of the Outcomes
As soon as I printed out the numbers, some patterns began to point out up.
My sleep hours had been fairly regular for the primary two weeks (round 6.9 hours), however in week three, they jumped to round 7.1 hours. Which means I used to be “sleeping higher” because the month went on. By week 4, it stayed roughly round 7.0 hours.
For examine hours, it was the alternative. Week one and two had a median of round 5 hours per day, however by week 4, it had dropped to about 4 hours. Principally, I began off robust however slowly misplaced momentum — which, truthfully, sounds about proper.
Then got here display time. This one harm a bit. In week one, it was roughly 4.3 hours per day, and it simply stored creeping up each week. The basic cycle of being productive early on, then slowly drifting into extra “scrolling breaks” later within the month.
Lastly, there was temper. My temper rating began at round 6.5 in week one, went barely as much as 6.6 in week two, after which type of hovered there for the remainder of the interval. It didn’t transfer dramatically, however it was attention-grabbing to see a small spike in week two — proper earlier than my examine hours dropped and my display time elevated.
To make issues interactive, I believed it’d be nice to visualise utilizing matplotlib.

Step 6 — On the lookout for Patterns
Now that I had the numbers, I needed to know why my temper went up in week two.
So I in contrast the weeks aspect by aspect. Week two had respectable sleep, excessive examine hours, and comparatively low display time in comparison with the later weeks.
That may clarify why my temper rating peaked there. By week three, though I slept extra, my examine hours had began to dip — perhaps I used to be resting extra however getting much less achieved, which didn’t enhance my temper as a lot as I anticipated.
That is what I preferred in regards to the challenge: it’s not in regards to the knowledge being actual, however about how one can use NumPy to discover patterns, relationships, and small insights. Even fictional knowledge can inform a narrative once you take a look at it the correct approach.
Step 7 — Wrapping Up and Subsequent Steps
On this little challenge, I discovered just a few key issues — each about NumPy and about structuring evaluation like this.
We began with a uncooked array of fictional every day habits, discovered learn how to verify its construction and validity, break up it into significant chunks (weeks), after which used easy NumPy operations to investigate every section.
It’s the type of small challenge that reminds you that knowledge evaluation doesn’t all the time should be advanced. Typically it’s nearly asking easy questions like “How is my display time altering over time?” or “When do I really feel one of the best?”
If I needed to take this additional (which I in all probability will), there are such a lot of instructions to go:
- Discover the greatest and worst days general
- Evaluate weekdays vs weekends
- And even create a easy “wellbeing rating” primarily based on a number of habits mixed
However that’ll in all probability be for the following a part of the collection.
For now, I’m blissful that I acquired to use NumPy to one thing that feels actual and relatable — not simply summary arrays and numbers, however habits and feelings. That’s the type of studying that sticks.
Thanks for studying.
Should you’re following together with the collection, strive recreating this by yourself fictional knowledge. Even when your numbers are random, the method will educate you learn how to slice, break up, and analyze arrays like a professional.


{kind=link}