
Media and leisure, promoting, training, and enterprise coaching content material combines visible, audio, and movement components to inform tales and convey data, making it much more advanced than textual content the place particular person phrases have clear meanings. This creates distinctive challenges for AI techniques that want to grasp video content material. Video content material is multidimensional, combining visible components (scenes, objects, actions), temporal dynamics (movement, transitions), audio elements (dialogue, music, sound results), and textual content overlays (subtitles, captions). This complexity creates vital enterprise challenges as organizations battle to go looking by means of video archives, find particular scenes, categorize content material mechanically and extract insights from their media belongings for efficient decision-making.
The mannequin addresses this drawback with a multi-vector structure that creates separate embeddings for various content material modalities. As an alternative of forcing all data into one vector, the mannequin generates specialised representations. This method preserves the wealthy, multifaceted nature of video information, enabling extra correct evaluation throughout visible, temporal, and audio dimensions.
Amazon Bedrock has expanded its capabilities to assist the TwelveLabs Marengo Embed 3.0 mannequin with real-time textual content and picture processing by means of synchronous inference. With this integration companies can implement sooner video search performance utilizing pure language queries, whereas additionally supporting interactive product discovery by means of refined picture similarity matching.
On this publish, we’ll present how the TwelveLabs Marengo embedding mannequin, accessible on Amazon Bedrock, enhances video understanding by means of multimodal AI. We’ll construct a video semantic search and evaluation resolution utilizing embeddings from the Marengo mannequin with Amazon OpenSearch Serverless because the vector database, for semantic search capabilities that transcend easy metadata matching to ship clever content material discovery.
Understanding video embeddings
Embeddings are dense vector representations that seize the semantic which means of knowledge in a high-dimensional house. Consider them as numerical fingerprints that encode the essence of content material in a approach machines can perceive and evaluate. For textual content, embeddings may seize that “king” and “queen” are associated ideas, or that “Paris” and “France” have a geographical relationship. For photos, embeddings can perceive {that a} golden retriever and labrador are each canines, even when they appear totally different. The next warmth map exhibits the semantic similarity scores between these sentence fragments: “two folks having a dialog,” “a person and a lady speaking,” and “cats and canines are pretty animals.”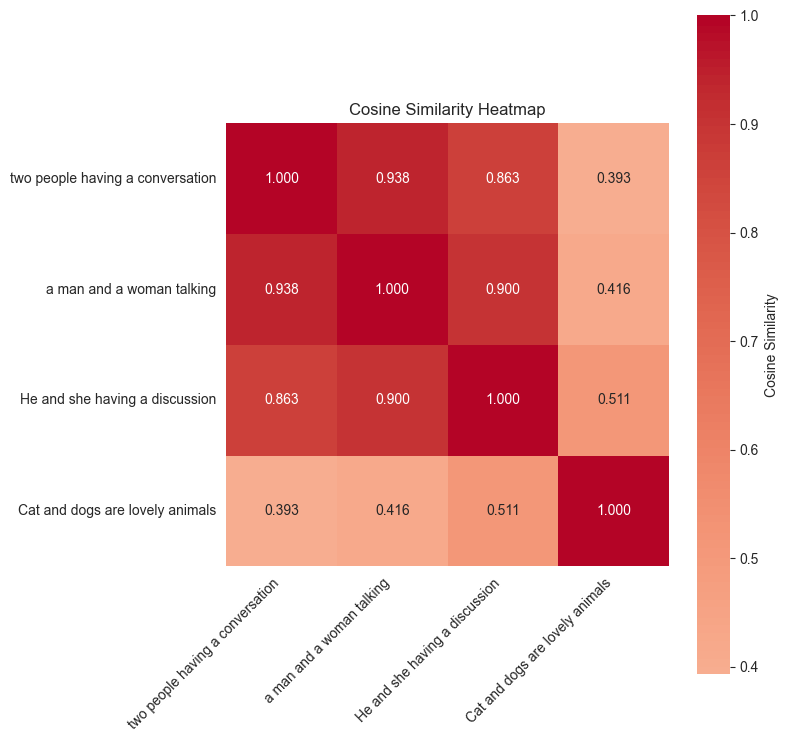
Video embeddings challenges
Video presents distinctive challenges as a result of it’s inherently multimodal:
- Visible data: Objects, scenes, folks, actions, and visible aesthetics
- Audio data: Speech, music, sound results, and ambient noise
- Textual data: Captions, on-screen textual content, and transcribed speech
Conventional single-vector approaches compress all this wealthy data into one illustration, typically shedding vital nuances. That is the place the method by TwelveLabs Marengo is exclusive in addressing this problem successfully.
Twelvelabs Marengo: A multimodal embedding mannequin
The Marengo 3.0 mannequin generates a number of specialised vectors, every capturing totally different facets of the video content material. A typical film or TV present combines visible and auditory components to create a unified storytelling expertise. Marengo’s multi-vector structure offers vital benefits for understanding this advanced video content material. Every vector captures a selected modality, avoiding data loss from compressing various information varieties into single representations. This allows versatile searches focusing on particular content material facets—visual-only, audio-only, or mixed queries. Specialised vectors ship superior accuracy in advanced multimodal situations whereas sustaining environment friendly scalability for big enterprise video datasets.
Resolution overview: Marengo mannequin capabilities
Within the following part, we’ll show the ability of Marengo’s embedding expertise by means of code samples. The examples illustrate how Marengo processes several types of content material and ship distinctive search accuracy. The entire code pattern might be discovered on this GitHub repository.
Stipulations
Earlier than we start, confirm you have got:
Pattern video
Netflix Open Content material is an open supply content material accessible underneath the Inventive Commons Attribution 4.0 Worldwide license. We shall be utilizing one of many movies known as Meridian for demonstrating the TwelveLabs Marengo mannequin on Amazon Bedrock.

Create a video embedding
Amazon Bedrock makes use of asynchronous API for Marengo video embedding generations. The next is a python code snippet that exhibits an instance of invoking an API that takes a video from an S3 bucket location. Please confer with the documentation for full supported performance.
The instance above produces 280 particular person embeddings from a single video – one for every section, enabling exact temporal search and evaluation. The kind of embeddings for multi-vector output from the video may include the next:
- visible – visible embeddings of the video
- transcription – embeddings of the transcribed textual content
- audio – embeddings of the audio within the video
When processing audio or video content material, you possibly can set how lengthy every clip section ought to be for embedding creation. By default, video clips are mechanically divided at pure scene adjustments (shot boundaries). Audio clips are cut up into even segments which can be as near 10 seconds as doable—for instance, a 50-second audio file turns into 5 segments of 10 seconds every, whereas a 16-second file turns into 2 segments of 8 seconds every. By default, a single Marengo video embedding API generates visual-text, visual-image, and audio embedding. It’s also possible to change the default setting to solely output particular embedding varieties. Use the next code snippet to generate embeddings for a video with configurable choices with the Amazon Bedrock API:
Vector database: Amazon OpenSearch Serverless
In our instance, we’ll use Amazon OpenSearch Serverless as vector database for storing the textual content, photos, audio, and video embeddings generated from the given video through Marengo mannequin. As a vector database, OpenSearch Serverless lets you rapidly discover related content material utilizing semantic search with out worrying about managing servers or infrastructure. The next code snippet demonstrates the best way to create an Amazon OpenSearch Serverless assortment:
As soon as the OpenSearch Serverless assortment is created, we’ll create an index that incorporates properties, together with a vector subject:
Index Marengo embeddings
The next code snippet demonstrates the best way to ingest the embedding output from the Marengo mannequin into the OpenSearch index:
Cross-modal semantic search
With Marengo’s multi-vector design you possibly can search throughout totally different modalities that’s not possible with single-vector fashions. By creating separate however aligned embeddings for visible, audio, movement, and contextual components, you possibly can search movies utilizing an enter kind of your selection. For instance, “jazz music taking part in” returns video clips of musicians performing, jazz audio tracks, and live performance corridor scenes from one textual content question.
The next examples showcase Marengo’s distinctive search capabilities throughout totally different modalities:
Textual content search
Right here’s a code snippet that demonstrates the cross modal semantic search functionality utilizing textual content:
The highest search consequence from the textual content question: “an individual smoking in a room” yields the next video clip:

Picture search
The next code snippet demonstrates the cross modal semantic search functionality for a given picture:

The highest search consequence from the picture above yields the next video clip:

Along with semantic looking utilizing textual content and pictures on the video, the Marengo mannequin also can search movies utilizing audio embeddings that concentrate on dialogue and speech. The audio search capabilities assist customers discover movies primarily based on particular audio system, dialogue content material, or spoken subjects. This creates a complete video search expertise that mixes textual content, picture, audio for video understanding.
Conclusion
The mixture of TwelveLabs Marengo and Amazon Bedrock opens up thrilling new prospects for video understanding by means of its multi-vector, multimodal method. All through this publish, we’ve explored sensible examples like image-to-video search with temporal precision and detailed text-to-video matching. With only a single Bedrock API name, we reworked one video file into 336 searchable segments that reply to textual content, visible, and audio queries. These capabilities create alternatives for pure language content material discovery, streamlined media asset administration, and different functions that may assist organizations higher perceive and make the most of their video content material at scale.
As video continues to dominate digital experiences, fashions like Marengo present a stable basis for constructing extra clever video evaluation techniques. Take a look at the pattern code and uncover how multimodal video understanding can remodel your functions.
Concerning the authors
 Wei Teh is an Machine Studying Options Architect at AWS. He’s obsessed with serving to clients obtain their enterprise targets utilizing cutting-edge machine studying options. Exterior of labor, he enjoys outside actions like tenting, fishing, and mountain climbing together with his household.
Wei Teh is an Machine Studying Options Architect at AWS. He’s obsessed with serving to clients obtain their enterprise targets utilizing cutting-edge machine studying options. Exterior of labor, he enjoys outside actions like tenting, fishing, and mountain climbing together with his household.
 Lana Zhang is a Senior Specialist Options Architect for Generative AI at AWS inside the Worldwide Specialist Group. She makes a speciality of AI/ML, with a concentrate on use circumstances reminiscent of AI voice assistants and multimodal understanding. She works intently with clients throughout various industries, together with media and leisure, gaming, sports activities, promoting, monetary companies, and healthcare, to assist them remodel their enterprise options by means of AI.
Lana Zhang is a Senior Specialist Options Architect for Generative AI at AWS inside the Worldwide Specialist Group. She makes a speciality of AI/ML, with a concentrate on use circumstances reminiscent of AI voice assistants and multimodal understanding. She works intently with clients throughout various industries, together with media and leisure, gaming, sports activities, promoting, monetary companies, and healthcare, to assist them remodel their enterprise options by means of AI.
 Yanyan Zhang is a Senior Generative AI Information Scientist at Amazon Net Companies, the place she has been engaged on cutting-edge AI/ML applied sciences as a Generative AI Specialist, serving to clients use generative AI to realize their desired outcomes. Yanyan graduated from Texas A&M College with a PhD in Electrical Engineering. Exterior of labor, she loves touring, understanding, and exploring new issues.
Yanyan Zhang is a Senior Generative AI Information Scientist at Amazon Net Companies, the place she has been engaged on cutting-edge AI/ML applied sciences as a Generative AI Specialist, serving to clients use generative AI to realize their desired outcomes. Yanyan graduated from Texas A&M College with a PhD in Electrical Engineering. Exterior of labor, she loves touring, understanding, and exploring new issues.



{kind=link}