A fast heads-up earlier than we begin:
- I’m a developer at Google Cloud. I’m comfortable to share this text and hope you’ll study a couple of issues. Ideas and opinions are solely my very own.
- The supply code for this text (and future updates) is out there in this pocket book (Apache License model 2.0).
- You’ll be able to experiment totally free with Gemini in Google AI Studio and get an API key to name Gemini programmatically.
- All pictures, until in any other case famous, are by me.
✨ Overview
Conventional machine studying (ML) notion fashions sometimes give attention to particular options and single modalities, deriving insights solely from pure language, speech, or imaginative and prescient evaluation. Traditionally, extracting and consolidating info from a number of modalities has been difficult as a consequence of siloed processing, advanced architectures, and the chance of knowledge being “misplaced in translation.” Nevertheless, multimodal and long-context giant language fashions (LLMs) like Gemini can overcome these points by processing all modalities throughout the similar context, opening new potentialities.
Shifting past speech-to-text, this pocket book explores how one can obtain complete video transcriptions by leveraging all accessible modalities. It covers the next matters:
- A technique for addressing new or advanced issues with a multimodal LLM
- A immediate method for decoupling knowledge and preserving consideration: tabular extraction
- Methods for taking advantage of Gemini’s 1M-token context in a single request
- Sensible examples of multimodal video transcriptions
- Suggestions & optimizations
🔥 Problem
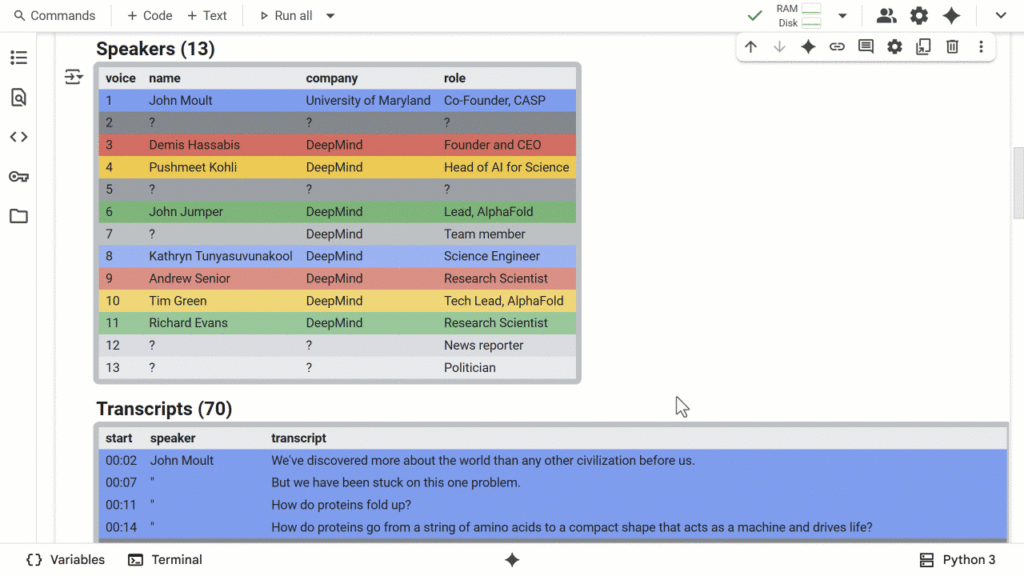
To totally transcribe a video, we’re seeking to reply the next questions:
- 1️⃣ What was stated and when?
- 2️⃣ Who’re the audio system?
- 3️⃣ Who stated what?
Can we resolve this drawback in a simple and environment friendly method?
🌟 State-of-the-art
1️⃣ What was stated and when?
This can be a recognized drawback with an present answer:
- Speech-to-Textual content (STT) is a course of that takes an audio enter and transforms speech into textual content. STT can present timestamps on the phrase stage. It’s also generally known as computerized speech recognition (ASR).
Within the final decade, task-specific ML fashions have most successfully addressed this.
2️⃣ Who’re the audio system?
We are able to retrieve speaker names in a video from two sources:
- What’s written (e.g., audio system will be launched with on-screen info once they first converse)
- What’s spoken (e.g., “Hi there Bob! Alice! How are you doing?”)
Imaginative and prescient and Pure Language Processing (NLP) fashions can assist with the next options:
- Imaginative and prescient: Optical Character Recognition (OCR), additionally referred to as textual content detection, extracts the textual content seen in pictures.
- Imaginative and prescient: Individual Detection identifies if and the place individuals are in a picture.
- NLP: Entity Extraction can establish named entities in textual content.
3️⃣ Who stated what?
That is one other recognized drawback with a partial answer (complementary to Speech-to-Textual content):
- Speaker Diarization (also called speaker flip segmentation) is a course of that splits an audio stream into segments for the completely different detected audio system (“Speaker A”, “Speaker B”, and many others.).
Researchers have made vital progress on this subject for many years, significantly with ML fashions in recent times, however that is nonetheless an lively subject of analysis. Current options have shortcomings, resembling requiring human supervision and hints (e.g., the minimal and most variety of audio system, the language spoken), and supporting a restricted set of languages.
🏺 Conventional ML pipeline
Fixing all of 1️⃣, 2️⃣, and three️⃣ isn’t easy. This might probably contain establishing an elaborate supervised processing pipeline, based mostly on a couple of state-of-the-art ML fashions, resembling the next:
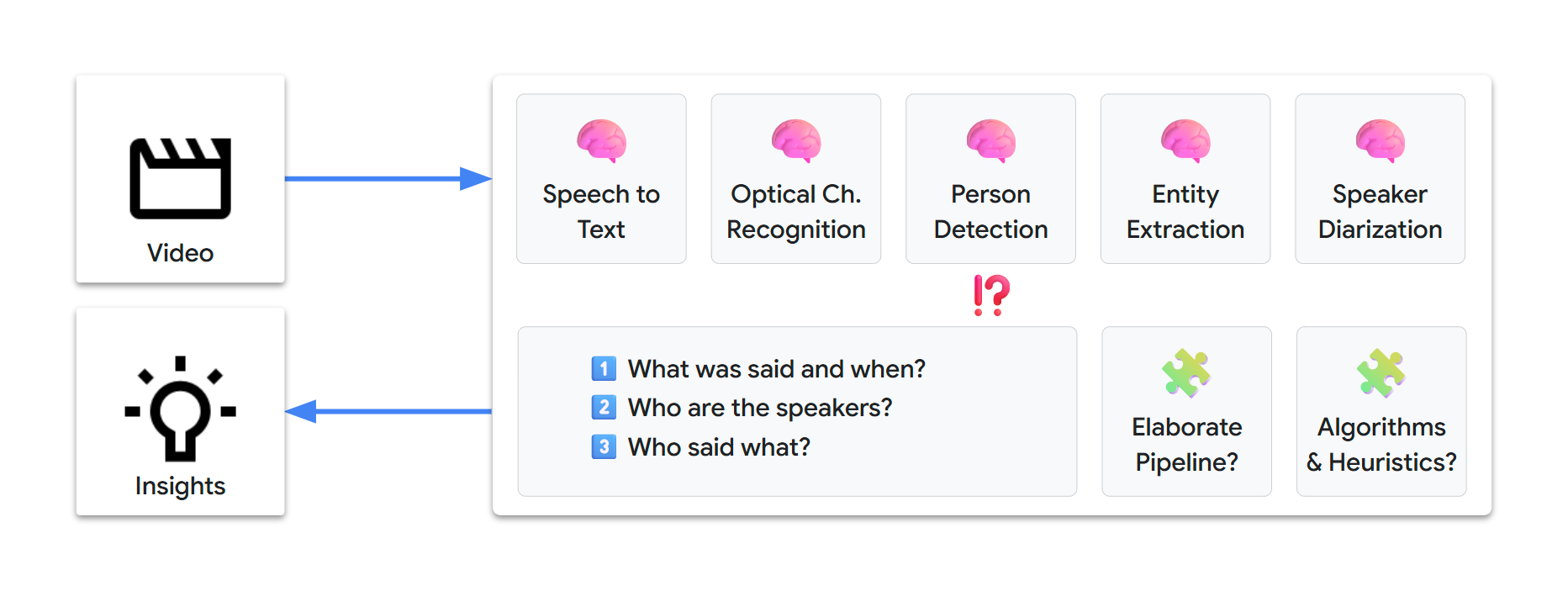
We would want days or even weeks to design and arrange such a pipeline. Moreover, on the time of writing, our multimodal-video-transcription problem is just not a solved drawback, so there’s completely no certainty of reaching a viable answer.
Gemini permits for fast prompt-based drawback fixing. With simply textual content directions, we are able to extract info and rework it into new insights, by way of a simple and automatic workflow.
🎬 Multimodal
Gemini is natively multimodal, which implies it could course of several types of inputs:
- textual content
- picture
- audio
- video
- doc
🌐 Multilingual
Gemini can also be multilingual:
- It might probably course of inputs and generate outputs in 100+ languages
- If we are able to resolve the video problem for one language, that answer ought to naturally prolong to all different languages
🧰 A natural-language toolbox
Multimodal and multilingual understanding in a single mannequin lets us shift from counting on task-specific ML fashions to utilizing a single versatile LLM.
Our problem now appears rather a lot easier:

In different phrases, let’s rephrase our problem: Can we absolutely transcribe a video with simply the next?
- 1 video
- 1 immediate
- 1 request
Let’s strive with Gemini…
🏁 Setup
🐍 Python packages
We’ll use the next packages:
google-genai: the Google Gen AI Python SDK lets us name Gemini with a couple of strains of codepandasfor knowledge visualization
We’ll additionally use these packages (dependencies of google-genai):
pydanticfor knowledge administrationtenacityfor request administration
pip set up --quiet "google-genai>=1.31.0" "pandas[output-formatting]"🔗 Gemini API
We have now two fundamental choices to ship requests to Gemini:
- Vertex AI: Construct enterprise-ready tasks on Google Cloud
- Google AI Studio: Experiment, prototype, and deploy small tasks
The Google Gen AI SDK supplies a unified interface to those APIs and we are able to use atmosphere variables for the configuration.
Possibility A – Gemini API by way of Vertex AI 🔽
Requirement:
- A Google Cloud undertaking
- The Vertex AI API have to be enabled for this undertaking
Gen AI SDK atmosphere variables:
Be taught extra about establishing a undertaking and a improvement atmosphere.
Possibility B – Gemini API by way of Google AI Studio 🔽
Requirement:
Gen AI SDK atmosphere variables:
GOOGLE_GENAI_USE_VERTEXAI="False"GOOGLE_API_KEY=""
Be taught extra about getting a Gemini API key from Google AI Studio.
💡 You’ll be able to retailer your atmosphere configuration outdoors of the supply code:
| Atmosphere | Technique |
|---|---|
| IDE | .env file (or equal) |
| Colab | Colab Secrets and techniques (🗝️ icon in left panel, see code beneath) |
| Colab Enterprise | Google Cloud undertaking and site are robotically outlined |
| Vertex AI Workbench | Google Cloud undertaking and site are robotically outlined |
Outline the next atmosphere detection capabilities. You can even outline your configuration manually if wanted. 🔽
import os
import sys
from collections.abc import Callable
from google import genai
# Guide setup (go away unchanged if setup is environment-defined)
# @markdown **Which API: Vertex AI or Google AI Studio?**
GOOGLE_GENAI_USE_VERTEXAI = True # @param {sort: "boolean"}
# @markdown **Possibility A - Google Cloud undertaking [+location]**
GOOGLE_CLOUD_PROJECT = "" # @param {sort: "string"}
GOOGLE_CLOUD_LOCATION = "international" # @param {sort: "string"}
# @markdown **Possibility B - Google AI Studio API key**
GOOGLE_API_KEY = "" # @param {sort: "string"}
def check_environment() -> bool:
check_colab_user_authentication()
return check_manual_setup() or check_vertex_ai() or check_colab() or check_local()
def check_manual_setup() -> bool:
return check_define_env_vars(
GOOGLE_GENAI_USE_VERTEXAI,
GOOGLE_CLOUD_PROJECT.strip(), # May need been pasted with line return
GOOGLE_CLOUD_LOCATION,
GOOGLE_API_KEY,
)
def check_vertex_ai() -> bool:
# Workbench and Colab Enterprise
match os.getenv("VERTEX_PRODUCT", ""):
case "WORKBENCH_INSTANCE":
move
case "COLAB_ENTERPRISE":
if not running_in_colab_env():
return False
case _:
return False
return check_define_env_vars(
True,
os.getenv("GOOGLE_CLOUD_PROJECT", ""),
os.getenv("GOOGLE_CLOUD_REGION", ""),
"",
)
def check_colab() -> bool:
if not running_in_colab_env():
return False
# Colab Enterprise was checked earlier than, so that is Colab solely
from google.colab import auth as colab_auth # sort: ignore
colab_auth.authenticate_user()
# Use Colab Secrets and techniques (🗝️ icon in left panel) to retailer the atmosphere variables
# Secrets and techniques are personal, seen solely to you and the notebooks that you choose
# - Vertex AI: Retailer your settings as secrets and techniques
# - Google AI: Straight import your Gemini API key from the UI
vertexai, undertaking, location, api_key = get_vars(get_colab_secret)
return check_define_env_vars(vertexai, undertaking, location, api_key)
def check_local() -> bool:
vertexai, undertaking, location, api_key = get_vars(os.getenv)
return check_define_env_vars(vertexai, undertaking, location, api_key)
def running_in_colab_env() -> bool:
# Colab or Colab Enterprise
return "google.colab" in sys.modules
def check_colab_user_authentication() -> None:
if running_in_colab_env():
from google.colab import auth as colab_auth # sort: ignore
colab_auth.authenticate_user()
def get_colab_secret(secret_name: str, default: str) -> str:
from google.colab import userdata # sort: ignore
strive:
return userdata.get(secret_name)
besides Exception as e:
return default
def get_vars(getenv: Callable[[str, str], str]) -> tuple[bool, str, str, str]:
# Restrict getenv calls to the minimal (might set off UI affirmation for secret entry)
vertexai_str = getenv("GOOGLE_GENAI_USE_VERTEXAI", "")
if vertexai_str:
vertexai = vertexai_str.decrease() in ["true", "1"]
else:
vertexai = bool(getenv("GOOGLE_CLOUD_PROJECT", ""))
undertaking = getenv("GOOGLE_CLOUD_PROJECT", "") if vertexai else ""
location = getenv("GOOGLE_CLOUD_LOCATION", "") if undertaking else ""
api_key = getenv("GOOGLE_API_KEY", "") if not undertaking else ""
return vertexai, undertaking, location, api_key
def check_define_env_vars(
vertexai: bool,
undertaking: str,
location: str,
api_key: str,
) -> bool:
match (vertexai, bool(undertaking), bool(location), bool(api_key)):
case (True, True, _, _):
# Vertex AI - Google Cloud undertaking [+location]
location = location or "international"
define_env_vars(vertexai, undertaking, location, "")
case (True, False, _, True):
# Vertex AI - API key
define_env_vars(vertexai, "", "", api_key)
case (False, _, _, True):
# Google AI Studio - API key
define_env_vars(vertexai, "", "", api_key)
case _:
return False
return True
def define_env_vars(vertexai: bool, undertaking: str, location: str, api_key: str) -> None:
os.environ["GOOGLE_GENAI_USE_VERTEXAI"] = str(vertexai)
os.environ["GOOGLE_CLOUD_PROJECT"] = undertaking
os.environ["GOOGLE_CLOUD_LOCATION"] = location
os.environ["GOOGLE_API_KEY"] = api_key
def check_configuration(consumer: genai.Shopper) -> None:
service = "Vertex AI" if consumer.vertexai else "Google AI Studio"
print(f"Utilizing the {service} API", finish="")
if consumer._api_client.undertaking:
print(f' with undertaking "{consumer._api_client.undertaking[:7]}…"', finish="")
print(f' in location "{consumer._api_client.location}"')
elif consumer._api_client.api_key:
api_key = consumer._api_client.api_key
print(f' with API key "{api_key[:5]}…{api_key[-5:]}"', finish="")
print(f" (in case of error, be sure it was created for {service})")🤖 Gen AI SDK
To ship Gemini requests, create a google.genai consumer:
from google import genai
check_environment()
consumer = genai.Shopper()Examine your configuration:
check_configuration(consumer)Utilizing the Vertex AI API with undertaking "lpdemo-…" in location "europe-west9"🧠 Gemini mannequin
Gemini is available in completely different variations.
Let’s get began with Gemini 2.0 Flash, because it provides each excessive efficiency and low latency:
GEMINI_2_0_FLASH = "gemini-2.0-flash"
💡 We choose Gemini 2.0 Flash deliberately. The Gemini 2.5 mannequin household is usually accessible and much more succesful, however we need to experiment and perceive Gemini’s core multimodal conduct. If we full our problem with 2.0, this also needs to work with newer fashions.
⚙️ Gemini configuration
Gemini can be utilized in numerous methods, starting from factual to artistic mode. The issue we’re making an attempt to resolve is a knowledge extraction use case. We would like outcomes as factual and deterministic as attainable. For this, we are able to change the content material technology parameters.
We’ll set the temperature, top_p, and seed parameters to reduce randomness:
temperature=0.0top_p=0.0seed=42(arbitrary mounted worth)
🎞️ Video sources
Listed below are the primary video sources that Gemini can analyze:
| supply | URI | Vertex AI | Google AI Studio |
|---|---|---|---|
| Google Cloud Storage | gs://bucket/path/to/video.* |
✅ | |
| Internet URL | https://path/to/video.* |
✅ | |
| YouTube | https://www.youtube.com/watch?v=YOUTUBE_ID |
✅ | ✅ |
⚠️ Vital notes
- Our video check suite primarily makes use of public YouTube movies. That is for simplicity.
- When analyzing YouTube sources, Gemini receives uncooked audio/video streams with none further metadata, precisely as if processing the corresponding video information from Cloud Storage.
- YouTube does provide caption/subtitle/transcript options (user-provided or auto-generated). Nevertheless, these options give attention to word-level speech-to-text and are restricted to 40+ languages. Gemini doesn’t obtain any of this knowledge and also you’ll see {that a} multimodal transcription with Gemini supplies further advantages.
- Moreover, our problem additionally entails figuring out audio system and extracting speaker knowledge, a novel new functionality.
🛠️ Helpers
Outline our helper capabilities and knowledge 🔽
import enum
from dataclasses import dataclass
from datetime import timedelta
import IPython.show
import tenacity
from google.genai.errors import ClientError
from google.genai.sorts import (
FileData,
FinishReason,
GenerateContentConfig,
GenerateContentResponse,
Half,
VideoMetadata,
)
class Mannequin(enum.Enum):
# Typically Obtainable (GA)
GEMINI_2_0_FLASH = "gemini-2.0-flash"
GEMINI_2_5_FLASH = "gemini-2.5-flash"
GEMINI_2_5_PRO = "gemini-2.5-pro"
# Default mannequin
DEFAULT = GEMINI_2_0_FLASH
# Default configuration for extra deterministic outputs
DEFAULT_CONFIG = GenerateContentConfig(
temperature=0.0,
top_p=0.0,
seed=42, # Arbitrary mounted worth
)
YOUTUBE_URL_PREFIX = "https://www.youtube.com/watch?v="
CLOUD_STORAGE_URI_PREFIX = "gs://"
def url_for_youtube_id(youtube_id: str) -> str:
return f"{YOUTUBE_URL_PREFIX}{youtube_id}"
class Video(enum.Enum):
move
class TestVideo(Video):
# For testing functions, video period is statically specified within the enum identify
# Suffix (ISO 8601 based mostly): _PT[H][M][S]
# Google DeepMind | The Podcast | Season 3 Trailer | 59s
GDM_PODCAST_TRAILER_PT59S = url_for_youtube_id("0pJn3g8dfwk")
# Google Maps | Stroll within the footsteps of Jane Goodall | 2min 42s
JANE_GOODALL_PT2M42S = "gs://cloud-samples-data/video/JaneGoodall.mp4"
# Google DeepMind | AlphaFold | The making of a scientific breakthrough | 7min 54s
GDM_ALPHAFOLD_PT7M54S = url_for_youtube_id("gg7WjuFs8F4")
# Brut | French reportage | 8min 28s
BRUT_FR_DOGS_WATER_LEAK_PT8M28S = url_for_youtube_id("U_yYkb-ureI")
# Google DeepMind | The Podcast | AI for science | 54min 23s
GDM_AI_FOR_SCIENCE_FRONTIER_PT54M23S = url_for_youtube_id("nQKmVhLIGcs")
# Google I/O 2025 | Developer Keynote | 1h 10min 03s
GOOGLE_IO_DEV_KEYNOTE_PT1H10M03S = url_for_youtube_id("GjvgtwSOCao")
# Google Cloud | Subsequent 2025 | Opening Keynote | 1h 40min 03s
GOOGLE_CLOUD_NEXT_PT1H40M03S = url_for_youtube_id("Md4Fs-Zc3tg")
# Google I/O 2025 | Keynote | 1h 56min 35s
GOOGLE_IO_KEYNOTE_PT1H56M35S = url_for_youtube_id("o8NiE3XMPrM")
class ShowAs(enum.Enum):
DONT_SHOW = enum.auto()
TEXT = enum.auto()
MARKDOWN = enum.auto()
@dataclass
class VideoSegment:
begin: timedelta
finish: timedelta
def generate_content(
immediate: str,
video: Video | None = None,
video_segment: VideoSegment | None = None,
mannequin: Mannequin | None = None,
config: GenerateContentConfig | None = None,
show_as: ShowAs = ShowAs.TEXT,
) -> None:
immediate = immediate.strip()
mannequin = mannequin or Mannequin.DEFAULT
config = config or DEFAULT_CONFIG
model_id = mannequin.worth
if video:
if not (video_part := get_video_part(video, video_segment)):
return
contents = [video_part, prompt]
caption = f"{video.identify} / {model_id}"
else:
contents = immediate
caption = f"{model_id}"
print(f" {caption} ".heart(80, "-"))
for try in get_retrier():
with try:
response = consumer.fashions.generate_content(
mannequin=model_id,
contents=contents,
config=config,
)
display_response_info(response)
display_response(response, show_as)
def get_video_part(
video: Video,
video_segment: VideoSegment | None = None,
fps: float | None = None,
) -> Half | None:
video_uri: str = video.worth
if not consumer.vertexai:
video_uri = convert_to_https_url_if_cloud_storage_uri(video_uri)
if not video_uri.startswith(YOUTUBE_URL_PREFIX):
print("Google AI Studio API: Solely YouTube URLs are at the moment supported")
return None
file_data = FileData(file_uri=video_uri, mime_type="video/*")
video_metadata = get_video_part_metadata(video_segment, fps)
return Half(file_data=file_data, video_metadata=video_metadata)
def get_video_part_metadata(
video_segment: VideoSegment | None = None,
fps: float | None = None,
) -> VideoMetadata:
def offset_as_str(offset: timedelta) -> str:
return f"{offset.total_seconds()}s"
if video_segment:
start_offset = offset_as_str(video_segment.begin)
end_offset = offset_as_str(video_segment.finish)
else:
start_offset = None
end_offset = None
return VideoMetadata(start_offset=start_offset, end_offset=end_offset, fps=fps)
def convert_to_https_url_if_cloud_storage_uri(uri: str) -> str:
if uri.startswith(CLOUD_STORAGE_URI_PREFIX):
return f"https://storage.googleapis.com/{uri.removeprefix(CLOUD_STORAGE_URI_PREFIX)}"
else:
return uri
def get_retrier() -> tenacity.Retrying:
return tenacity.Retrying(
cease=tenacity.stop_after_attempt(7),
wait=tenacity.wait_incrementing(begin=10, increment=1),
retry=should_retry_request,
reraise=True,
)
def should_retry_request(retry_state: tenacity.RetryCallState) -> bool:
if not retry_state.final result:
return False
err = retry_state.final result.exception()
if not isinstance(err, ClientError):
return False
print(f"❌ ClientError {err.code}: {err.message}")
retry = False
match err.code:
case 400 if err.message is just not None and " strive once more " in err.message:
# Workshop: undertaking accessing Cloud Storage for the primary time (service agent provisioning)
retry = True
case 429:
# Workshop: non permanent undertaking with 1 QPM quota
retry = True
print(f"🔄 Retry: {retry}")
return retry
def display_response_info(response: GenerateContentResponse) -> None:
if usage_metadata := response.usage_metadata:
if usage_metadata.prompt_token_count:
print(f"Enter tokens : {usage_metadata.prompt_token_count:9,d}")
if usage_metadata.candidates_token_count:
print(f"Output tokens : {usage_metadata.candidates_token_count:9,d}")
if usage_metadata.thoughts_token_count:
print(f"Ideas tokens: {usage_metadata.thoughts_token_count:9,d}")
if not response.candidates:
print("❌ No `response.candidates`")
return
if (finish_reason := response.candidates[0].finish_reason) != FinishReason.STOP:
print(f"❌ {finish_reason = }")
if not response.textual content:
print("❌ No `response.textual content`")
return
def display_response(
response: GenerateContentResponse,
show_as: ShowAs,
) -> None:
if show_as == ShowAs.DONT_SHOW:
return
if not (response_text := response.textual content):
return
response_text = response.textual content.strip()
print(" begin of response ".heart(80, "-"))
match show_as:
case ShowAs.TEXT:
print(response_text)
case ShowAs.MARKDOWN:
display_markdown(response_text)
print(" finish of response ".heart(80, "-"))
def display_markdown(markdown: str) -> None:
IPython.show.show(IPython.show.Markdown(markdown))
def display_video(video: Video) -> None:
video_url = convert_to_https_url_if_cloud_storage_uri(video.worth)
assert video_url.startswith("https://")
video_width = 600
if video_url.startswith(YOUTUBE_URL_PREFIX):
youtube_id = video_url.removeprefix(YOUTUBE_URL_PREFIX)
ipython_video = IPython.show.YouTubeVideo(youtube_id, width=video_width)
else:
ipython_video = IPython.show.Video(video_url, width=video_width)
display_markdown(f"### Video ([source]({video_url}))")
IPython.show.show(ipython_video) 🧪 Prototyping
🌱 Pure conduct
Earlier than diving any deeper, it’s fascinating to see how Gemini responds to easy directions, to develop some instinct about its pure conduct.
Let’s first see what we get with minimalistic prompts and a brief English video.
video = TestVideo.GDM_PODCAST_TRAILER_PT59S
display_video(video)
immediate = "Transcribe the video's audio with time info."
generate_content(immediate, video)
Video (supply)
----------------- GDM_PODCAST_TRAILER_PT59S / gemini-2.0-flash -----------------
Enter tokens : 16,708
Output tokens : 421
------------------------------ begin of response -------------------------------
[00:00:00] Do I've to name you Sir Demis now?
[00:00:01] Oh, you do not.
[00:00:02] Completely not.
[00:00:04] Welcome to Google DeepMind the podcast with me, your host Professor Hannah Fry.
[00:00:06] We need to take you to the center of the place these concepts are coming from.
[00:00:12] We need to introduce you to the people who find themselves main the design of our collective future.
[00:00:19] Getting the security proper might be, I might say, probably the most essential challenges of our time.
[00:00:25] I need secure and succesful.
[00:00:27] I need a bridge that won't collapse.
[00:00:30] simply give these scientists a superpower that they'd not imagined earlier.
[00:00:34] autonomous automobiles.
[00:00:35] It is arduous to fathom that once you're engaged on a search engine.
[00:00:38] We might even see solely new style or solely new types of artwork come up.
[00:00:42] There could also be a brand new phrase that's not music, portray, pictures, film making, and that AI could have helped us create it.
[00:00:48] You actually need AGI to have the ability to peer into the mysteries of the universe.
[00:00:51] Sure, quantum mechanics, string idea, effectively, and the character of actuality.
[00:00:55] Ow.
[00:00:57] the magic of AI.
------------------------------- finish of response --------------------------------Outcomes:
- Gemini naturally outputs a listing of
[time] transcriptstrains. - That’s Speech-to-Textual content in a single line!
- It appears like we are able to reply “1️⃣ What was stated and when?”.
Now, what about “2️⃣ Who’re the audio system?”
immediate = "Record the audio system identifiable within the video."
generate_content(immediate, video)----------------- GDM_PODCAST_TRAILER_PT59S / gemini-2.0-flash -----------------
Enter tokens : 16,705
Output tokens : 46
------------------------------ begin of response -------------------------------
Listed below are the audio system identifiable within the video:
* Professor Hannah Fry
* Demis Hassabis
* Anca Dragan
* Pushmeet Kohli
* Jeff Dean
* Douglas Eck
------------------------------- finish of response --------------------------------Outcomes:
- Gemini can consolidate the names seen on title playing cards in the course of the video.
- That’s OCR + entity extraction in a single line!
- “2️⃣ Who’re the audio system?” appears solved too!
⏩ Not so quick!
The pure subsequent step is to leap to the ultimate directions, to resolve our drawback as soon as and for all.
immediate = """
Transcribe the video's audio together with speaker names (use "?" if not discovered).
Format instance:
[00:02] John Doe - Hi there Alice!
"""
generate_content(immediate, video)----------------- GDM_PODCAST_TRAILER_PT59S / gemini-2.0-flash -----------------
Enter tokens : 16,732
Output tokens : 378
------------------------------ begin of response -------------------------------
Right here is the audio transcription of the video:
[00:00] ? - Do I've to name you Sir Demis now?
[00:01] Demis Hassabis - Oh, you do not. Completely not.
[00:04] Professor Hannah Fry - Welcome to Google DeepMind the podcast with me, your host, Professor Hannah Fry.
[00:06] Professor Hannah Fry - We need to take you to the center of the place these concepts are coming from. We need to introduce you to the people who find themselves main the design of our collective future.
[00:19] Anca Dragan - Getting the security proper might be, I might say, probably the most essential challenges of our time. I need secure and succesful. I need a bridge that won't collapse.
[00:29] Pushmeet Kohli - Simply give these scientists a superpower that they'd not imagined earlier.
[00:34] Jeff Dean - Autonomous automobiles. It is arduous to fathom that once you're engaged on a search engine.
[00:38] Douglas Eck - We might even see solely new style or solely new types of artwork come up. There could also be a brand new phrase that's not music, portray, pictures, film making, and that AI could have helped us create it.
[00:48] Professor Hannah Fry - You actually need AGI to have the ability to peer into the mysteries of the universe.
[00:51] Demis Hassabis - Sure, quantum mechanics, string idea, effectively, and the character of actuality.
[00:55] Professor Hannah Fry - Ow!
[00:57] Douglas Eck - The magic of AI.
------------------------------- finish of response --------------------------------That is virtually appropriate. The primary section isn’t attributed to the host (who is just launched a bit later), however every little thing else appears appropriate.
Nonetheless, these aren’t real-world situations:
- The video could be very brief (lower than a minute)
- The video can also be slightly easy (audio system are clearly launched with on-screen title playing cards)
Let’s strive with this 8-minute (and extra advanced) video:
generate_content(immediate, TestVideo.GDM_ALPHAFOLD_PT7M54S)Output 🔽
------------------- GDM_ALPHAFOLD_PT7M54S / gemini-2.0-flash -------------------
Enter tokens : 134,177
Output tokens : 2,689
------------------------------ begin of response -------------------------------
[00:02] ? - We have found extra concerning the world than some other civilization earlier than us.
[00:08] ? - However we have now been caught on this one drawback.
[00:11] ? - How do proteins fold up?
[00:13] ? - How do proteins go from a string of amino acids to a compact form that acts as a machine and drives life?
[00:22] ? - If you discover out about proteins, it is rather thrilling.
[00:25] ? - You possibly can consider them as little organic nano machines.
[00:28] ? - They're basically the elemental constructing blocks that energy every little thing dwelling on this planet.
[00:34] ? - If we are able to reliably predict protein constructions utilizing AI, that might change the way in which we perceive the pure world.
[00:46] ? - Protein folding is certainly one of these holy grail sort issues in biology.
[00:50] Demis Hassabis - We have at all times hypothesized that AI must be useful to make these varieties of huge scientific breakthroughs extra rapidly.
[00:58] ? - After which I am going to in all probability be taking a look at little tunings which may make a distinction.
[01:02] ? - It must be making a histogram on and a background talent.
[01:04] ? - We have been engaged on our system AlphaFold actually arduous now for over two years.
[01:08] ? - Slightly than having to do painstaking experiments, sooner or later biologists may have the ability to as an alternative depend on AI strategies to instantly predict constructions rapidly and effectively.
[01:17] Kathryn Tunyasuvunakool - Typically talking, biologists are usually fairly skeptical of computational work, and I feel that skepticism is wholesome and I respect it, however I really feel very enthusiastic about what AlphaFold can obtain.
[01:28] Andrew Senior - CASP is once we, we are saying, look, DeepMind is doing protein folding.
[01:31] Andrew Senior - That is how good we're, and perhaps it is higher than everyone else, perhaps it is not.
[01:37] ? - We determined to enter CASP competitors as a result of it represented the Olympics of protein folding.
[01:44] John Moult - CASP, we began to try to velocity up the answer to the protein folding drawback.
[01:50] John Moult - After we began CASP in 1994, I actually was naive about how arduous this was going to be.
[01:58] ? - It was very cumbersome to do this as a result of it took a very long time.
[02:01] ? - Let's examine what, what, what are we doing nonetheless to enhance?
[02:03] ? - Sometimes 100 completely different teams from world wide take part in CASP, and we take a set of 100 proteins and we ask the teams to ship us what they suppose the constructions appear to be.
[02:15] ? - We are able to attain 57.9 GDT on CASP 12 floor reality.
[02:19] John Jumper - CASP has a metric on which you'll be scored, which is that this GDT metric.
[02:25] John Jumper - On a scale of zero to 100, you'll anticipate a GDT over 90 to be an answer to the issue.
[02:33] ? - If we do obtain this, this has unimaginable medical relevance.
[02:37] Pushmeet Kohli - The implications are immense, from how ailments progress, how one can uncover new medicine.
[02:45] Pushmeet Kohli - It is countless.
[02:46] ? - I wished to make a, a very easy system and the outcomes have been surprisingly good.
[02:50] ? - The group acquired some outcomes with a brand new method, not solely is it extra correct, nevertheless it's a lot quicker than the previous system.
[02:56] ? - I feel we'll considerably exceed what we're doing proper now.
[02:59] ? - This can be a recreation, recreation changer, I feel.
[03:01] John Moult - In CASP 13, one thing very vital had occurred.
[03:06] John Moult - For the primary time, we noticed the efficient software of synthetic intelligence.
[03:11] ? - We have superior the cutting-edge within the subject, in order that's implausible, however we nonetheless acquired a protracted strategy to go earlier than we have solved it.
[03:18] ? - The shapes have been now roughly appropriate for most of the proteins, however the particulars, precisely the place every atom sits, which is basically what we'd name an answer, we're not but there.
[03:29] ? - It does not assist you probably have the tallest ladder when you are going to the moon.
[03:33] ? - We hit slightly little bit of a brick wall, um, since we gained CASP, then it was again to the drafting board and like what are our new concepts?
[03:41] ? - Um, after which it is taken a short time, I'd say, for them to get again to the place they have been, however with the brand new concepts.
[03:51] ? - They'll go additional, proper?
[03:52] ? - So, um, in order that's a very essential second.
[03:55] ? - I've seen that second so many occasions now, however I do know what which means now, and I do know that is the time now to press.
[04:02] ? - We have to double down and go as quick as attainable from right here.
[04:05] ? - I feel we have no time to lose.
[04:07] ? - So the intention is to enter CASP once more.
[04:09] ? - CASP is deeply aggravating.
[04:12] ? - There's one thing bizarre happening with, um, the educational as a result of it's studying one thing that is correlated with GDT, nevertheless it's not calibrated.
[04:18] ? - I really feel barely uncomfortable.
[04:20] ? - We must be studying this, you understand, within the blink of an eye fixed.
[04:23] ? - The expertise advancing outdoors DeepMind can also be doing unimaginable work.
[04:27] Richard Evans - And there is at all times the chance one other group has come someplace on the market subject that we do not even find out about.
[04:32] ? - Somebody requested me, effectively, ought to we panic now?
[04:33] ? - After all, we should always have been panicking earlier than.
[04:35] ? - It does appear to do higher, however nonetheless does not do fairly in addition to one of the best mannequin.
[04:39] ? - Um, so it appears like there's room for enchancment.
[04:42] ? - There's at all times a danger that you've got missed one thing, and that is why blind assessments like CASP are so essential to validate whether or not our outcomes are actual.
[04:49] ? - Clearly, I am excited to see how CASP 14 goes.
[04:51] ? - My expectation is we get our heads down, we give attention to the complete purpose, which is to resolve the entire drawback.
[05:14] ? - We have been ready for CASP to begin on April fifteenth as a result of that is when it was initially scheduled to begin, and it has been delayed by a month as a consequence of coronavirus.
[05:24] ? - I actually miss everybody.
[05:25] ? - No, I struggled slightly bit simply form of getting right into a routine, particularly, uh, my spouse, she got here down with the, the virus.
[05:32] ? - I imply, fortunately it did not end up too critical.
[05:34] ? - CASP began on Monday.
[05:37] Demis Hassabis - Can I simply examine this diagram you have acquired right here, John, this one the place we ask floor reality.
[05:40] Demis Hassabis - Is that this one we have finished badly on?
[05:42] ? - We're truly fairly good on this area.
[05:43] ? - If you happen to think about that we hadn't have stated it got here round this fashion, however had put it in.
[05:47] ? - Yeah, and that as an alternative.
[05:48] ? - Yeah.
[05:49] ? - One of many hardest proteins we have gotten in CASP to date is a SARS-CoV-2 protein, uh, referred to as Orf8.
[05:55] ? - Orf8 is a coronavirus protein.
[05:57] ? - We tried actually arduous to enhance our prediction, like actually, actually arduous, in all probability probably the most time that we have now ever spent on a single goal.
[06:05] ? - So we're about two-thirds of the way in which by way of CASP, and we have gotten three solutions again.
[06:11] ? - We now have a floor reality for Orf8, which is among the coronavirus proteins.
[06:17] ? - And it seems we did very well in predicting that.
[06:20] Demis Hassabis - Wonderful job, everybody, the entire group.
[06:23] Demis Hassabis - It has been an unimaginable effort.
[06:24] John Moult - Right here what we noticed in CASP 14 was a gaggle delivering atomic accuracy off the bat, basically fixing what in our world is 2 issues.
[06:34] John Moult - How do you look to search out the appropriate answer, after which how do you acknowledge you have acquired the appropriate answer once you're there?
[06:41] ? - All proper, are we, are we principally right here?
[06:46] ? - I will learn an e-mail.
[06:48] ? - Uh, I acquired this from John Moult.
[06:50] ? - Now I am going to simply learn it.
[06:51] ? - It says, John, as I anticipate you understand, your group has carried out amazingly effectively in CASP 14, each relative to different teams and in absolute mannequin accuracy.
[07:02] ? - Congratulations on this work.
[07:05] ? - It's actually excellent.
[07:07] Demis Hassabis - AlphaFold represents an enormous leap ahead that I hope will actually speed up drug discovery and assist us to higher perceive illness.
[07:13] John Moult - It is fairly mind-blowing.
[07:16] John Moult - You recognize, these outcomes have been, for me, having labored on this drawback so lengthy, after many, many stops and begins and can this ever get there, immediately this can be a answer.
[07:28] John Moult - We have solved the issue.
[07:29] John Moult - This provides you such pleasure about the way in which science works, about how one can by no means see precisely and even roughly what is going on to occur subsequent.
[07:37] John Moult - There are at all times these surprises, and that actually, as a scientist, is what retains you going.
[07:41] John Moult - What is going on to be the following shock?
------------------------------- finish of response --------------------------------This falls aside: Most segments haven’t any recognized speaker!
As we try to resolve a brand new advanced drawback, LLMs haven’t been educated on any recognized answer. That is probably why direct directions don’t yield the anticipated reply.
At this stage:
- We would conclude that we are able to’t resolve the issue with real-world movies.
- Persevering by making an attempt an increasing number of elaborate prompts for this unsolved drawback may end in a waste of time.
Let’s take a step again and take into consideration what occurs below the hood…
⚛️ Below the hood
Fashionable LLMs are principally constructed upon the Transformer structure, a brand new neural community design detailed in a 2017 paper by Google researchers titled Consideration Is All You Want. The paper launched the self-attention mechanism, a key innovation that essentially modified the way in which machines course of language.
🪙 Tokens
Tokens are the LLM constructing blocks. We are able to take into account a token to signify a chunk of knowledge.
Examples of Gemini multimodal tokens (with default parameters):
| content material | tokens | particulars |
|---|---|---|
hi there |
1 | 1 token for widespread phrases/sequences |
passionately |
2 | ardour•ately |
passionnément |
3 | ardour•né•ment (similar adverb in French) |
| picture | 258 | per picture (or per tile relying on picture decision) |
| audio with out timecodes | 25 / second | dealt with by the audio tokenizer |
| video with out audio | 258 / body | dealt with by the video tokenizer at 1 body per second |
MM:SS timecode |
5 | audio chunk or video body temporal reference |
H:MM:SS timecode |
7 | equally, for content material longer than 1 hour |
🎞️ Sampling body fee
By default, video frames are sampled at 1 body per second (1 FPS). These frames are included within the context with their corresponding timecodes.
You should utilize a customized sampling body fee with the Half.video_metadata.fps parameter:
| video sort | change | fps vary |
|---|---|---|
| static, gradual | lower the body fee | 0.0 < fps < 1.0 |
| dynamic, quick | improve the body fee | 1.0 < fps <= 24.0 |
💡 For
1.0 < fps, Gemini was educated to knowMM:SS.sssandH:MM:SS.ssstimecodes.
🔍 Media decision
By default, every sampled body is represented with 258 tokens.
You’ll be able to specify a medium or low media decision with the GenerateContentConfig.media_resolution parameter:
| media_resolution for video inputs | tokens/ body | profit |
|---|---|---|
MEDIA_RESOLUTION_MEDIUM (default) |
258 | increased precision, permits extra detailed understanding |
MEDIA_RESOLUTION_LOW |
66 | quicker and cheaper inference, permits longer movies |
💡 The “media decision” will be seen because the “picture token decision”: the variety of tokens used to signify a picture.
🧮 Possibilities all the way in which down
The power of LLMs to speak in flawless pure language could be very spectacular, nevertheless it’s straightforward to get carried away and make incorrect assumptions.
Be mindful how LLMs work:
- An LLM is educated on a large tokenized dataset, which represents its data (its long-term reminiscence)
- Through the coaching, its neural community learns token patterns
- If you ship a request to an LLM, your inputs are remodeled into tokens (tokenization)
- To reply your request, the LLM predicts, token by token, the following probably tokens
- Total, LLMs are distinctive statistical token prediction machines that appear to imitate how some elements of our mind work
This has a couple of penalties:
- LLM outputs are simply statistically probably follow-ups to your inputs
- LLMs present some types of reasoning: they will match advanced patterns however haven’t any precise deep understanding
- LLMs haven’t any consciousness: they’re designed to generate tokens and can accomplish that based mostly in your directions
- Order issues: Tokens which are generated first will affect tokens which are generated subsequent
For the following step, some methodical immediate crafting may assist…
🏗️ Immediate crafting
🪜 Methodology
Immediate crafting, additionally referred to as immediate engineering, is a comparatively new subject. It entails designing and refining textual content directions to information LLMs in direction of producing desired outputs. Like writing, it’s each an artwork and a science, a talent that everybody can develop with observe.
We are able to discover numerous reference supplies about immediate crafting. Some prompts will be very lengthy, advanced, and even scary. Crafting prompts with a high-performing LLM like Gemini is way easier. Listed below are three key adjectives to bear in mind:
- iterative
- exact
- concise
Iterative
Immediate crafting is often an iterative course of. Listed below are some suggestions:
- Craft your immediate step-by-step
- Preserve observe of your successive iterations
- At each iteration, be sure to measure what’s working versus what’s not
- If you happen to attain a regression, backtrack to a profitable iteration
Exact
Precision is vital:
- Use phrases as particular as attainable
- Phrases with a number of meanings can introduce variability, so use exact expressions
- Precision will affect possibilities in your favor
Concise
Concision has further benefits:
- A brief immediate is simpler for us builders to know (and keep!)
- The longer your immediate is, the extra probably you might be to introduce inconsistencies and even contradictions, which ends up in variable interpretations of your directions
- Check and belief the LLM’s data: this information acts as an implicit context and might make your immediate shorter and clearer
Total, although this will likely appear contradictory, when you take the time to be iterative, exact, and concise, you might be prone to save plenty of time.
💡 If you wish to discover this subject, take a look at Prompting methods (Google Cloud reference) and Immediate engineering (68-page PDF by Lee Boonstra).
📚 Terminology
We’re not consultants in video transcription (but!) however we wish Gemini to behave as one. Consequently, we’d like to jot down prompts as particular as attainable for this use case. Whereas LLMs course of directions based mostly on their coaching data, they will additionally share this information with us.
We are able to study rather a lot by instantly asking Gemini:
immediate = """
What's the terminology used for video transcriptions?
Please present a typical output instance.
"""
generate_content(immediate, show_as=ShowAs.MARKDOWN)Output 🔽
------------------------------- gemini-2.0-flash -------------------------------
Enter tokens : 18
Output tokens : 1,814
------------------------------ begin of response -------------------------------## Terminology Used for Video Transcriptions
This is a breakdown of widespread terminology used when discussing video transcriptions:
* **Transcription:** The overall time period for changing audio or video content material into textual content.
* **Video Transcription:** Particularly refers to transcribing the audio portion of a video.
* **Verbatim Transcription:** A transcription that features each spoken phrase, together with filler phrases ("um," "ah"), false begins, stutters, and background noises (if related). It goals for a extremely correct illustration of the spoken phrase.
* **Clear Verbatim Transcription (or Edited Transcription):** A transcription that removes filler phrases, false begins, and stutters to create a extra readable and polished textual content. It focuses on conveying the which means clearly.
* **Clever Verbatim Transcription:** A center floor between verbatim and clear verbatim. It removes some filler phrases and stutters however retains components that contribute to the speaker's model or the context of the dialog.
* **Abstract Transcription:** A short overview of the video's content material, highlighting the details.
* **Timecoding (or Timestamping):** Including timestamps to the transcription to point when every part of textual content was spoken within the video. That is essential for accessibility and navigation.
* **Speaker Identification:** Figuring out and labeling completely different audio system within the video.
* **Captioning (or Subtitling):** Creating textual content variations of the video's audio which are displayed on the display, often synchronized with the video. Captions are sometimes used for accessibility (for deaf or hard-of-hearing viewers) and for viewers preferring to learn alongside.
* **Closed Captions:** Captions that may be turned on or off by the viewer.
* **Open Captions:** Captions which are completely embedded within the video and can't be turned off.
* **SRT (SubRip Subtitle):** A standard file format for storing captions and subtitles.
* **VTT (Video Textual content Tracks):** A extra trendy file format for captions and subtitles, typically used with HTML5 video.
* **Burned-in Captions:** Captions which are completely embedded into the video file.
* **Transcriber:** The particular person or software program that performs the transcription.
* **Accuracy Fee:** The share of phrases transcribed appropriately.
* **Turnaround Time:** The time it takes to finish the transcription.
## Typical Output Instance
As an example we have now a brief video clip of an interview. This is how several types of transcriptions may look:
**Situation:** A brief clip of an interview with a chef discussing their new restaurant.
**1. Verbatim Transcription (with Timecoding):**
```
00:00:00 --> 00:00:03 Interviewer: So, Chef, welcome to the present!
00:00:03 --> 00:00:06 Chef: Thanks for having me. It is, uh, nice to be right here.
00:00:06 --> 00:00:12 Interviewer: So, inform us slightly bit about your new restaurant, "The Golden Spoon."
00:00:12 --> 00:00:20 Chef: Effectively, um, it is, it has been a dream of mine for, like, years, you understand? To, like, open a spot that actually focuses on, um, seasonal elements.
00:00:20 --> 00:00:25 Interviewer: And what sort of delicacies can individuals anticipate?
00:00:25 --> 00:00:32 Chef: We're doing, uh, trendy American, however with, like, an actual emphasis on, uh, native farms and, you understand, sustainable practices.
```
**2. Clear Verbatim Transcription (with Timecoding):**
```
00:00:00 --> 00:00:03 Interviewer: So, Chef, welcome to the present!
00:00:03 --> 00:00:06 Chef: Thanks for having me. It is nice to be right here.
00:00:06 --> 00:00:12 Interviewer: So, inform us slightly bit about your new restaurant, "The Golden Spoon."
00:00:12 --> 00:00:20 Chef: Effectively, it has been a dream of mine for years to open a spot that actually focuses on seasonal elements.
00:00:20 --> 00:00:25 Interviewer: And what sort of delicacies can individuals anticipate?
00:00:25 --> 00:00:32 Chef: We're doing trendy American, however with an actual emphasis on native farms and sustainable practices.
```
**3. Clever Verbatim Transcription (with Timecoding):**
```
00:00:00 --> 00:00:03 Interviewer: So, Chef, welcome to the present!
00:00:03 --> 00:00:06 Chef: Thanks for having me. It is nice to be right here.
00:00:06 --> 00:00:12 Interviewer: So, inform us slightly bit about your new restaurant, "The Golden Spoon."
00:00:12 --> 00:00:20 Chef: Effectively, it has been a dream of mine for, like, years, you understand? To open a spot that actually focuses on seasonal elements.
00:00:20 --> 00:00:25 Interviewer: And what sort of delicacies can individuals anticipate?
00:00:25 --> 00:00:32 Chef: We're doing trendy American, however with, like, an actual emphasis on native farms and, you understand, sustainable practices.
```
**4. Abstract Transcription:**
```
Chef discusses their new restaurant, "The Golden Spoon," which focuses on seasonal elements and trendy American delicacies with an emphasis on native farms and sustainable practices.
```
**5. SRT File (for Captions):**
```
1
00:00:00,000 --> 00:00:03,000
Interviewer: So, Chef, welcome to the present!
2
00:00:03,000 --> 00:00:06,000
Chef: Thanks for having me. It is nice to be right here.
3
00:00:06,000 --> 00:00:12,000
Interviewer: So, inform us slightly bit about your new restaurant, "The Golden Spoon."
4
00:00:12,000 --> 00:00:20,000
Chef: Effectively, it has been a dream of mine for years to open a spot that actually focuses on seasonal elements.
5
00:00:20,000 --> 00:00:25,000
Interviewer: And what sort of delicacies can individuals anticipate?
6
00:00:25,000 --> 00:00:32,000
Chef: We're doing trendy American, however with an actual emphasis on native farms and sustainable practices.
```
**Key Variations:**
* **Verbatim:** Captures each element, together with imperfections in speech.
* **Clear Verbatim:** Focuses on readability and readability by eradicating pointless components.
* **Clever Verbatim:** A steadiness between accuracy and readability.
* **Abstract:** Supplies a concise overview.
* **SRT:** A structured file format for displaying captions synchronized with the video.
The very best sort of transcription is dependent upon the particular wants of the undertaking. For authorized or analysis functions, a verbatim transcription is likely to be mandatory. For normal accessibility or advertising functions, a clear verbatim or clever verbatim transcription is commonly most popular. Abstract transcriptions are helpful for rapidly understanding the content material of a video. SRT information are important for including captions to movies.------------------------------- finish of response --------------------------------To date, we’ve seen the next:
- We didn’t handle to get the complete transcription with recognized audio system all of sudden
- Order issues (as a result of a generated token influences the possibilities for subsequent tokens)
To deal with our problem, we want Gemini to deduce from the next multimodal info:
- textual content (our directions + what could also be written within the video)
- audio cues (every little thing stated or audible within the video’s audio)
- visible cues (every little thing seen within the video)
- time (when issues occur)
That’s fairly a combination of knowledge sorts!
As video transcription is a knowledge extraction use case, if we take into consideration the ultimate end result as a database, our remaining purpose will be seen because the technology of two associated tables (transcripts and audio system). If we write it down, our preliminary three sub-problems now look decoupled:
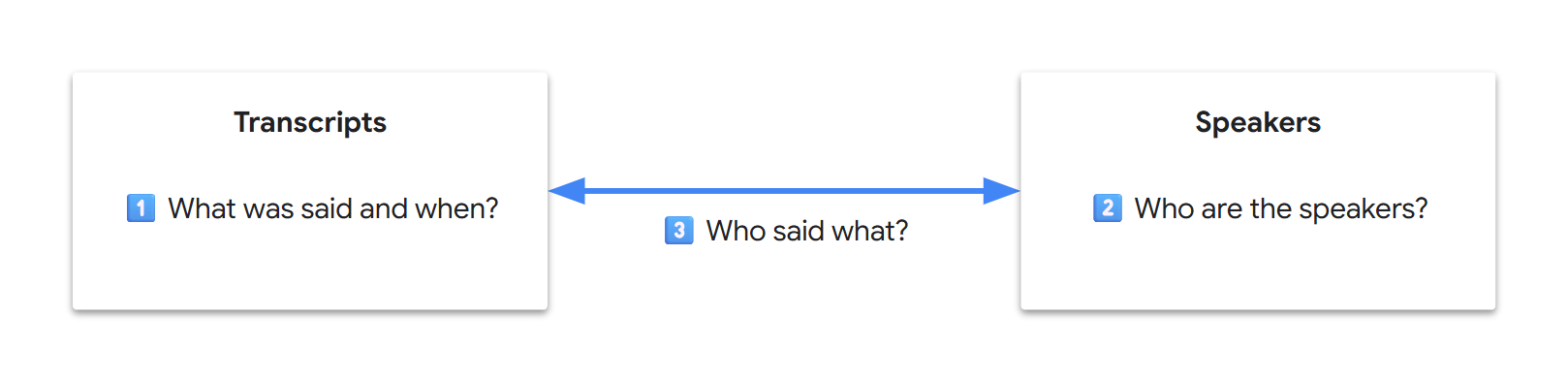
💡 In pc science, knowledge decoupling enhances knowledge locality, typically yielding improved efficiency throughout areas resembling cache utilization, knowledge entry, semantic understanding, or system upkeep. Throughout the LLM Transformer structure, core efficiency depends closely on the eye mechanism. Nonetheless, the eye pool is finite and tokens compete for consideration. Researchers typically seek advice from “consideration dilution” for long-context, million-token-scale benchmarks. Whereas we can’t instantly debug LLMs as customers, intuitively, knowledge decoupling might enhance the mannequin’s focus, resulting in a greater consideration span.
Since Gemini is extraordinarily good with patterns, it could robotically generate identifiers to hyperlink our tables. As well as, since we finally need an automatic workflow, we are able to begin reasoning when it comes to knowledge and fields:

Let’s name this strategy “tabular extraction”, break up our directions into two duties (tables), nonetheless in a single request, and organize them in a significant order…
💬 Transcripts
Initially, let’s give attention to getting the audio transcripts:
- Gemini has confirmed to be natively good at audio transcription
- This requires much less inference than picture evaluation
- It’s central and unbiased info
💡 Producing an output that begins with appropriate solutions ought to assist to attain an total appropriate output.
We’ve additionally seen what a typical transcription entry can appear to be:
00:02 speaker_1: Welcome!However, straight away, there will be some ambiguities in our multimodal use case:
- What’s a speaker?
- Is it somebody we see/hear?
- What if the particular person seen within the video is just not the one talking?
- What if the particular person talking isn’t seen within the video?
How can we unconsciously establish who’s talking in a video?
- First, in all probability by figuring out the completely different voices on the fly?
- Then, in all probability by consolidating further audio and visible cues?
Can Gemini perceive voice traits?
immediate = """
Utilizing solely the video's audio, checklist the next audible traits:
- Voice tones
- Voice pitches
- Languages
- Accents
- Talking types
"""
video = TestVideo.GDM_PODCAST_TRAILER_PT59S
generate_content(immediate, video, show_as=ShowAs.MARKDOWN)----------------- GDM_PODCAST_TRAILER_PT59S / gemini-2.0-flash -----------------
Enter tokens : 16,730
Output tokens : 168
------------------------------ begin of response -------------------------------Okay, here is a breakdown of the audible traits within the video's audio:
- **Voice Tones:** The tones vary from conversational and pleasant to extra critical and considerate. There are additionally moments of pleasure and humor.
- **Voice Pitches:** There's a mixture of excessive and low pitches, relying on the speaker. The feminine audio system are likely to have increased pitches, whereas the male audio system have decrease pitches.
- **Languages:** The first language is English.
- **Accents:** There are a selection of accents, together with British, American, and presumably others which are tougher to pinpoint with out extra context.
- **Talking Types:** The talking types differ from formal {and professional} (like in an interview setting) to extra informal and conversational. Some audio system are extra articulate and exact, whereas others are extra relaxed.------------------------------- finish of response --------------------------------What a couple of French video?
video = TestVideo.BRUT_FR_DOGS_WATER_LEAK_PT8M28S
generate_content(immediate, video, show_as=ShowAs.MARKDOWN)-------------- BRUT_FR_DOGS_WATER_LEAK_PT8M28S / gemini-2.0-flash --------------
Enter tokens : 144,055
Output tokens : 147
------------------------------ begin of response -------------------------------This is a breakdown of the audible traits within the video, based mostly on the audio:
* **Languages:** Primarily French.
* **Accents:** French accents are current, with some variations relying on the speaker.
* **Voice Tones:** The voice tones differ relying on the speaker and the context. Some are conversational and informative, whereas others are extra enthusiastic and inspiring, particularly when interacting with the canines.
* **Voice Pitches:** The voice pitches differ relying on the speaker and the context.
* **Talking Types:** The talking types differ relying on the speaker and the context. Some are conversational and informative, whereas others are extra enthusiastic and inspiring, particularly when interacting with the canines.------------------------------- finish of response --------------------------------⚠️ We have now to be cautious right here: responses can consolidate multimodal info and even normal data. For instance, if an individual is known, their identify is most definitely a part of the LLM’s data. If they’re recognized to be from the UK, a attainable inference is that they’ve a British accent. Because of this we made our immediate extra particular by together with “utilizing solely the video’s audio”.
💡 If you happen to conduct extra exams, for instance on personal audio information (i.e., not a part of widespread data and with no further visible cues), you’ll see that Gemini’s audio tokenizer performs exceptionally effectively and extracts semantic speech info!
After a couple of iterations, we are able to arrive at a transcription immediate specializing in the audio and voices:
immediate = """
Job:
- Watch the video and hear rigorously to the audio.
- Determine every distinctive voice utilizing a `voice` ID (1, 2, 3, and many others.).
- Transcribe the video's audio verbatim with voice diarization.
- Embrace the `begin` timecode (MM:SS) for every speech section.
- Output a JSON array the place every object has the next fields:
- `begin`
- `textual content`
- `voice`
"""
video = TestVideo.GDM_PODCAST_TRAILER_PT59S
generate_content(immediate, video, show_as=ShowAs.MARKDOWN)Output 🔽
----------------- GDM_PODCAST_TRAILER_PT59S / gemini-2.0-flash -----------------
Enter tokens : 16,800
Output tokens : 635
------------------------------ begin of response -------------------------------[
{
"start": "00:00",
"text": "Do I have to call you Sir Demis now?",
"voice": 1
},
{
"start": "00:01",
"text": "Oh, you don't. Absolutely not.",
"voice": 2
},
{
"start": "00:03",
"text": "Welcome to Google Deep Mind the podcast with me, your host Professor Hannah Fry.",
"voice": 1
},
{
"start": "00:06",
"text": "We want to take you to the heart of where these ideas are coming from. We want to introduce you to the people who are leading the design of our collective future.",
"voice": 1
},
{
"start": "00:19",
"text": "Getting the safety right is probably, I'd say, one of the most important challenges of our time. I want safe and capable.",
"voice": 3
},
{
"start": "00:26",
"text": "I want a bridge that will not collapse.",
"voice": 3
},
{
"start": "00:30",
"text": "just give these scientists a superpower that they had not imagined earlier.",
"voice": 4
},
{
"start": "00:34",
"text": "autonomous vehicles. It's hard to fathom that when you're working on a search engine.",
"voice": 5
},
{
"start": "00:38",
"text": "We may see entirely new genre or entirely new forms of art come up. There may be a new word that is not music, painting, photography, movie making, and that AI will have helped us create it.",
"voice": 6
},
{
"start": "00:48",
"text": "You really want AGI to be able to peer into the mysteries of the universe.",
"voice": 1
},
{
"start": "00:51",
"text": "Yes, quantum mechanics, string theory, well, and the nature of reality.",
"voice": 2
},
{
"start": "00:55",
"text": "Ow.",
"voice": 1
},
{
"start": "00:56",
"text": "the magic of AI.",
"voice": 6
}
]------------------------------- finish of response --------------------------------That is trying good! And when you check these directions on extra advanced movies, you’ll get equally promising outcomes.
Discover how the immediate reuses cherry-picked phrases from the terminology beforehand offered by Gemini, whereas aiming for precision and concision:
verbatimis unambiguous (not like “spoken phrases”)1, 2, 3, and many others.is an ellipsis (Gemini can infer the sample)timecodeis particular (timestamphas extra meanings)MM:SSclarifies the timecode format
💡 Gemini 2.0 was educated to know the particular
MM:SStimecode format. Gemini 2.5 additionally helps theH:MM:SSformat for longer movies. For the most recent updates, seek advice from the video understanding documentation.
We’re midway there. Let’s full our database technology with a second job…
🧑 Audio system
The second job is fairly easy: we need to extract speaker info right into a second desk. The 2 tables are logically linked by the voice ID.
After a couple of iterations, we are able to attain a two-task immediate like the next:
immediate = """
Generate a JSON object with keys `task1_transcripts` and `task2_speakers` for the next duties.
**Job 1 - Transcripts**
- Watch the video and hear rigorously to the audio.
- Determine every distinctive voice utilizing a `voice` ID (1, 2, 3, and many others.).
- Transcribe the video's audio verbatim with voice diarization.
- Embrace the `begin` timecode (MM:SS) for every speech section.
- Output a JSON array the place every object has the next fields:
- `begin`
- `textual content`
- `voice`
**Job 2 - Audio system**
- For every `voice` ID from Job 1, extract details about the corresponding speaker.
- Use visible and audio cues.
- If a speaker's identify can't be discovered, use a query mark (`?`) as the worth.
- Output a JSON array the place every object has the next fields:
- `voice`
- `identify`
JSON:
"""
video = TestVideo.GDM_PODCAST_TRAILER_PT59S
generate_content(immediate, video, show_as=ShowAs.MARKDOWN)Output 🔽
----------------- GDM_PODCAST_TRAILER_PT59S / gemini-2.0-flash -----------------
Enter tokens : 16,920
Output tokens : 806
------------------------------ begin of response -------------------------------{
"task1_transcripts": [
{
"start": "00:00",
"text": "Do I have to call you Sir Demis now?",
"voice": 1
},
{
"start": "00:01",
"text": "Oh, you don't. Absolutely not.",
"voice": 2
},
{
"start": "00:04",
"text": "Welcome to Google Deep Mind the podcast with me, your host Professor Hannah Fry.",
"voice": 1
},
{
"start": "00:06",
"text": "We want to take you to the heart of where these ideas are coming from. We want to introduce you to the people who are leading the design of our collective future.",
"voice": 1
},
{
"start": "00:19",
"text": "Getting the safety right is probably, I'd say, one of the most important challenges of our time. I want safe and capable.",
"voice": 3
},
{
"start": "00:26",
"text": "I want a bridge that will not collapse.",
"voice": 3
},
{
"start": "00:30",
"text": "That just give these scientists a superpower that they had not imagined earlier.",
"voice": 4
},
{
"start": "00:34",
"text": "autonomous vehicles. It's hard to fathom that when you're working on a search engine.",
"voice": 5
},
{
"start": "00:38",
"text": "We may see entirely new genre or entirely new forms of art come up. There may be a new word that is not music, painting, photography, movie making, and that AI will have helped us create it.",
"voice": 6
},
{
"start": "00:48",
"text": "You really want AGI to be able to peer into the mysteries of the universe.",
"voice": 1
},
{
"start": "00:51",
"text": "Yes, quantum mechanics, string theory, well, and the nature of reality.",
"voice": 2
},
{
"start": "00:55",
"text": "Ow.",
"voice": 1
},
{
"start": "00:56",
"text": "the magic of AI.",
"voice": 6
}
],
"task2_speakers": [
{
"voice": 1,
"name": "Professor Hannah Fry"
},
{
"voice": 2,
"name": "Demis Hassabis"
},
{
"voice": 3,
"name": "Anca Dragan"
},
{
"voice": 4,
"name": "Pushmeet Kohli"
},
{
"voice": 5,
"name": "Jeff Dean"
},
{
"voice": 6,
"name": "Douglas Eck"
}
]
}------------------------------- finish of response --------------------------------Check this immediate on extra advanced movies: it’s nonetheless trying good!
🚀 Finalization
🧩 Structured output
We’ve iterated in direction of a exact and concise immediate. Now, we are able to give attention to Gemini’s response:
- The response is obvious textual content containing fenced code blocks
- As a substitute, we’d like a structured output, to obtain constantly formatted responses
- Ideally, we’d additionally wish to keep away from having to parse the response, which generally is a upkeep burden
Getting structured outputs is an LLM function additionally referred to as “managed technology”. Since we’ve already crafted our immediate when it comes to knowledge tables and JSON fields, that is now a formality.
In our request, we are able to add the next parameters:
response_mime_type="software/json"response_schema="YOUR_JSON_SCHEMA"(docs)
In Python, this will get even simpler:
- Use the
pydanticlibrary - Mirror your output construction with courses derived from
pydantic.BaseModel
We are able to simplify the immediate by eradicating the output specification elements:
Generate a JSON object with keys `task1_transcripts` and `task2_speakers` for the next duties.
…
- Output a JSON array the place every object has the next fields:
- `begin`
- `textual content`
- `voice`
…
- Output a JSON array the place every object has the next fields:
- `voice`
- `identify`… to maneuver them to matching Python courses as an alternative:
import pydantic
class Transcript(pydantic.BaseModel):
begin: str
textual content: str
voice: int
class Speaker(pydantic.BaseModel):
voice: int
identify: str
class VideoTranscription(pydantic.BaseModel):
task1_transcripts: checklist[Transcript] = pydantic.Subject(default_factory=checklist)
task2_speakers: checklist[Speaker] = pydantic.Subject(default_factory=checklist)… and request a structured response:
response = consumer.fashions.generate_content(
# …
config=GenerateContentConfig(
# …
response_mime_type="software/json",
response_schema=VideoTranscription,
# …
),
)Lastly, retrieving the objects from the response can also be direct:
if isinstance(response.parsed, VideoTranscription):
video_transcription = response.parsed
else:
video_transcription = VideoTranscription() # Empty transcriptionThe fascinating points of this strategy are the next:
- The immediate focuses on the logic and the courses give attention to the output
- It’s simpler to replace and keep typed courses
- The JSON schema is robotically generated by the Gen AI SDK from the category offered in
response_schemaand dispatched to Gemini - The response is robotically parsed by the Gen AI SDK and deserialized into the corresponding Python objects
⚠️ If you happen to preserve output specs in your immediate, guarantee there aren’t any contradictions between the immediate and the schema (e.g., similar subject names and order), as this could negatively influence the standard of the responses.
💡 It’s attainable to have extra structural info instantly within the schema (e.g., detailed subject definitions). See Managed technology.
✨ Implementation
Let’s finalize our code. As well as, now that we have now a secure immediate, we are able to even enrich our answer to extract every speaker’s firm, place, and role_in_video:
Last code 🔽
import re
import pydantic
from google.genai.sorts import MediaResolution, ThinkingConfig
SamplingFrameRate = float
VIDEO_TRANSCRIPTION_PROMPT = """
**Job 1 - Transcripts**
- Watch the video and hear rigorously to the audio.
- Determine every distinctive voice utilizing a `voice` ID (1, 2, 3, and many others.).
- Transcribe the video's audio verbatim with voice diarization.
- Embrace the `begin` timecode ({timecode_spec}) for every speech section.
**Job 2 - Audio system**
- For every `voice` ID from Job 1, extract details about the corresponding speaker.
- Use visible and audio cues.
- If a chunk of knowledge can't be discovered, use a query mark (`?`) as the worth.
"""
NOT_FOUND = "?"
class Transcript(pydantic.BaseModel):
begin: str
textual content: str
voice: int
class Speaker(pydantic.BaseModel):
voice: int
identify: str
firm: str
place: str
role_in_video: str
class VideoTranscription(pydantic.BaseModel):
task1_transcripts: checklist[Transcript] = pydantic.Subject(default_factory=checklist)
task2_speakers: checklist[Speaker] = pydantic.Subject(default_factory=checklist)
def get_generate_content_config(mannequin: Mannequin, video: Video) -> GenerateContentConfig:
media_resolution = get_media_resolution_for_video(video)
thinking_config = get_thinking_config(mannequin)
return GenerateContentConfig(
temperature=DEFAULT_CONFIG.temperature,
top_p=DEFAULT_CONFIG.top_p,
seed=DEFAULT_CONFIG.seed,
response_mime_type="software/json",
response_schema=VideoTranscription,
media_resolution=media_resolution,
thinking_config=thinking_config,
)
def get_video_duration(video: Video) -> timedelta | None:
# For testing functions, video period is statically specified within the enum identify
# Suffix (ISO 8601 based mostly): _PT[H][M][S]
# For manufacturing,
# - fetch durations dynamically or retailer them individually
# - keep in mind video VideoMetadata.start_offset & VideoMetadata.end_offset
regex = r"_PT(?:(d+)H)?(?:(d+)M)?(?:(d+)S)?$"
if not (match := re.search(regex, video.identify)):
print(f"⚠️ No period information in {video.identify}. Will use defaults.")
return None
h_str, m_str, s_str = match.teams()
return timedelta(
hours=int(h_str) if h_str is just not None else 0,
minutes=int(m_str) if m_str is just not None else 0,
seconds=int(s_str) if s_str is just not None else 0,
)
def get_media_resolution_for_video(video: Video) -> MediaResolution | None:
if not (video_duration := get_video_duration(video)):
return None # Default
# For testing functions, that is based mostly on video period, as our brief movies are usually extra detailed
less_than_five_minutes = video_duration < timedelta(minutes=5)
if less_than_five_minutes:
media_resolution = MediaResolution.MEDIA_RESOLUTION_MEDIUM
else:
media_resolution = MediaResolution.MEDIA_RESOLUTION_LOW
return media_resolution
def get_sampling_frame_rate_for_video(video: Video) -> SamplingFrameRate | None:
sampling_frame_rate = None # Default (1 FPS for present fashions)
# [Optional] Outline a customized FPS: 0.0 < sampling_frame_rate <= 24.0
return sampling_frame_rate
def get_timecode_spec_for_model_and_video(mannequin: Mannequin, video: Video) -> str:
timecode_spec = "MM:SS" # Default
match mannequin:
case Mannequin.GEMINI_2_0_FLASH: # Helps MM:SS
move
case Mannequin.GEMINI_2_5_FLASH | Mannequin.GEMINI_2_5_PRO: # Help MM:SS and H:MM:SS
period = get_video_duration(video)
one_hour_or_more = period is just not None and timedelta(hours=1) <= period
if one_hour_or_more:
timecode_spec = "MM:SS or H:MM:SS"
case _:
assert False, "Add timecode format for brand new mannequin"
return timecode_spec
def get_thinking_config(mannequin: Mannequin) -> ThinkingConfig | None:
# Examples of considering configurations (Gemini 2.5 fashions)
match mannequin:
case Mannequin.GEMINI_2_5_FLASH: # Pondering disabled
return ThinkingConfig(thinking_budget=0, include_thoughts=False)
case Mannequin.GEMINI_2_5_PRO: # Minimal considering price range and no summarized ideas
return ThinkingConfig(thinking_budget=128, include_thoughts=False)
case _:
return None # Default
def get_video_transcription_from_response(
response: GenerateContentResponse,
) -> VideoTranscription:
if not isinstance(response.parsed, VideoTranscription):
print("❌ Couldn't parse the JSON response")
return VideoTranscription() # Empty transcription
return response.parsed
def get_video_transcription(
video: Video,
video_segment: VideoSegment | None = None,
fps: float | None = None,
immediate: str | None = None,
mannequin: Mannequin | None = None,
) -> VideoTranscription:
mannequin = mannequin or Mannequin.DEFAULT
model_id = mannequin.worth
fps = fps or get_sampling_frame_rate_for_video(video)
video_part = get_video_part(video, video_segment, fps)
if not video_part: # Unsupported supply, return an empty transcription
return VideoTranscription()
if immediate is None:
timecode_spec = get_timecode_spec_for_model_and_video(mannequin, video)
immediate = VIDEO_TRANSCRIPTION_PROMPT.format(timecode_spec=timecode_spec)
contents = [video_part, prompt.strip()]
config = get_generate_content_config(mannequin, video)
print(f" {video.identify} / {model_id} ".heart(80, "-"))
response = None
for try in get_retrier():
with try:
response = consumer.fashions.generate_content(
mannequin=model_id,
contents=contents,
config=config,
)
display_response_info(response)
assert isinstance(response, GenerateContentResponse)
return get_video_transcription_from_response(response) Check it:
def test_structured_video_transcription(video: Video) -> None:
transcription = get_video_transcription(video)
print("-" * 80)
print(f"Transcripts : {len(transcription.task1_transcripts):3d}")
print(f"Audio system : {len(transcription.task2_speakers):3d}")
for speaker in transcription.task2_speakers:
print(f"- {speaker}")
test_structured_video_transcription(TestVideo.GDM_PODCAST_TRAILER_PT59S)----------------- GDM_PODCAST_TRAILER_PT59S / gemini-2.0-flash -----------------
Enter tokens : 16,917
Output tokens : 989
--------------------------------------------------------------------------------
Transcripts : 13
Audio system : 6
- voice=1 identify='Professor Hannah Fry' firm='Google DeepMind' place='Host' role_in_video='Host'
- voice=2 identify='Demis Hassabis' firm='Google DeepMind' place='Co-Founder & CEO' role_in_video='Interviewee'
- voice=3 identify='Anca Dragan' firm='?' place='Director, AI Security & Alignment' role_in_video='Interviewee'
- voice=4 identify='Pushmeet Kohli' firm='?' place='VP Science & Strategic Initiatives' role_in_video='Interviewee'
- voice=5 identify='Jeff Dean' firm='?' place='Chief Scientist' role_in_video='Interviewee'
- voice=6 identify='Douglas Eck' firm='?' place='Senior Analysis Director' role_in_video='Interviewee'📊 Information visualization
We began prototyping in pure language, crafted a immediate, and generated a structured output. Since studying uncooked knowledge will be cumbersome, we are able to now current video transcriptions in a extra visually interesting method.
Right here’s a attainable orchestrator perform:
def transcribe_video(video: Video, …) -> None:
display_video(video)
transcription = get_video_transcription(video, …)
display_speakers(transcription)
display_transcripts(transcription)Let’s add some knowledge visualization capabilities 🔽
import itertools
from collections.abc import Callable, Iterator
from pandas import DataFrame, Sequence
from pandas.io.codecs.model import Styler
from pandas.io.codecs.style_render import CSSDict
BGCOLOR_COLUMN = "bg_color" # Hidden column to retailer row background colours
def yield_known_speaker_color() -> Iterator[str]:
PAL_40 = ("#669DF6", "#EE675C", "#FCC934", "#5BB974")
PAL_30 = ("#8AB4F8", "#F28B82", "#FDD663", "#81C995")
PAL_20 = ("#AECBFA", "#F6AEA9", "#FDE293", "#A8DAB5")
PAL_10 = ("#D2E3FC", "#FAD2CF", "#FEEFC3", "#CEEAD6")
PAL_05 = ("#E8F0FE", "#FCE8E6", "#FEF7E0", "#E6F4EA")
return itertools.cycle([*PAL_40, *PAL_30, *PAL_20, *PAL_10, *PAL_05])
def yield_unknown_speaker_color() -> Iterator[str]:
GRAYS = ["#80868B", "#9AA0A6", "#BDC1C6", "#DADCE0", "#E8EAED", "#F1F3F4"]
return itertools.cycle(GRAYS)
def get_color_for_voice_mapping(audio system: checklist[Speaker]) -> dict[int, str]:
known_speaker_color = yield_known_speaker_color()
unknown_speaker_color = yield_unknown_speaker_color()
mapping: dict[int, str] = {}
for speaker in audio system:
if speaker.identify != NOT_FOUND:
coloration = subsequent(known_speaker_color)
else:
coloration = subsequent(unknown_speaker_color)
mapping[speaker.voice] = coloration
return mapping
def get_table_styler(df: DataFrame) -> Styler:
def join_styles(types: checklist[str]) -> str:
return ";".be part of(types)
table_css = [
"color: #202124",
"background-color: #BDC1C6",
"border: 0",
"border-radius: 0.5rem",
"border-spacing: 0px",
"outline: 0.5rem solid #BDC1C6",
"margin: 1rem 0.5rem",
]
th_css = ["background-color: #E8EAED"]
th_td_css = ["text-align:left", "padding: 0.25rem 1rem"]
table_styles = [
CSSDict(selector="", props=join_styles(table_css)),
CSSDict(selector="th", props=join_styles(th_css)),
CSSDict(selector="th,td", props=join_styles(th_td_css)),
]
return df.model.set_table_styles(table_styles).conceal()
def change_row_bgcolor(row: Sequence) -> checklist[str]:
model = f"background-color:{row[BGCOLOR_COLUMN]}"
return [style] * len(row)
def display_table(yield_rows: Callable[[], Iterator[list[str]]]) -> None:
knowledge = yield_rows()
df = DataFrame(columns=subsequent(knowledge), knowledge=knowledge)
styler = get_table_styler(df)
styler.apply(change_row_bgcolor, axis=1)
styler.conceal([BGCOLOR_COLUMN], axis="columns")
html = styler.to_html()
IPython.show.show(IPython.show.HTML(html))
def display_speakers(transcription: VideoTranscription) -> None:
def sanitize_field(s: str, symbol_if_unknown: str) -> str:
return symbol_if_unknown if s == NOT_FOUND else s
def yield_rows() -> Iterator[list[str]]:
yield ["voice", "name", "company", "position", "role_in_video", BGCOLOR_COLUMN]
color_for_voice = get_color_for_voice_mapping(transcription.task2_speakers)
for speaker in transcription.task2_speakers:
yield [
str(speaker.voice),
sanitize_field(speaker.name, NOT_FOUND),
sanitize_field(speaker.company, NOT_FOUND),
sanitize_field(speaker.position, NOT_FOUND),
sanitize_field(speaker.role_in_video, NOT_FOUND),
color_for_voice.get(speaker.voice, "red"),
]
display_markdown(f"### Audio system ({len(transcription.task2_speakers)})")
display_table(yield_rows)
def display_transcripts(transcription: VideoTranscription) -> None:
def yield_rows() -> Iterator[list[str]]:
yield ["start", "speaker", "transcript", BGCOLOR_COLUMN]
color_for_voice = get_color_for_voice_mapping(transcription.task2_speakers)
speaker_for_voice = {
speaker.voice: speaker for speaker in transcription.task2_speakers
}
previous_voice = None
for transcript in transcription.task1_transcripts:
current_voice = transcript.voice
speaker_label = ""
if speaker := speaker_for_voice.get(current_voice, None):
if speaker.identify != NOT_FOUND:
speaker_label = speaker.identify
elif speaker.place != NOT_FOUND:
speaker_label = f"[voice {current_voice}][{speaker.position}]"
elif speaker.role_in_video != NOT_FOUND:
speaker_label = f"[voice {current_voice}][{speaker.role_in_video}]"
if not speaker_label:
speaker_label = f"[voice {current_voice}]"
yield [
transcript.start,
speaker_label if current_voice != previous_voice else '"',
transcript.text,
color_for_voice.get(current_voice, "red"),
]
previous_voice = current_voice
display_markdown(f"### Transcripts ({len(transcription.task1_transcripts)})")
display_table(yield_rows)
def transcribe_video(
video: Video,
video_segment: VideoSegment | None = None,
fps: float | None = None,
immediate: str | None = None,
mannequin: Mannequin | None = None,
) -> None:
display_video(video)
transcription = get_video_transcription(video, video_segment, fps, immediate, mannequin)
display_speakers(transcription)
display_transcripts(transcription)✅ Problem accomplished
🎬 Brief video
This video is a trailer for the Google DeepMind podcast. It incorporates a fast-paced montage of 6 interviews. The multimodal transcription is superb:
transcribe_video(TestVideo.GDM_PODCAST_TRAILER_PT59S)Video (supply)
----------------- GDM_PODCAST_TRAILER_PT59S / gemini-2.0-flash -----------------
Enter tokens : 16,917
Output tokens : 989Audio system (6)

Transcripts (13)

🎬 Narrator-only video
This video is a documentary that takes viewers on a digital tour of the Gombe Nationwide Park in Tanzania. There’s no seen speaker. Jane Goodall is appropriately detected because the narrator, her identify is extracted from the credit:
transcribe_video(TestVideo.JANE_GOODALL_PT2M42S)Video (supply)
------------------- JANE_GOODALL_PT2M42S / gemini-2.0-flash --------------------
Enter tokens : 46,324
Output tokens : 717Audio system (1)

Transcripts (14)

💡 Over the previous few years, I’ve commonly used this video to check specialised ML fashions and it constantly resulted in numerous kinds of errors. Gemini’s transcription, together with punctuation, is ideal.
🎬 French video
This French reportage combines on-the-ground footage of a specialised group that makes use of educated canines to detect leaks in underground ingesting water pipes. The recording takes place solely outside in a rural setting. The interviewed staff are launched with on-screen textual content overlays. The audio, captured dwell on location, contains ambient noise. There are additionally some off-screen or unidentified audio system. This video is slightly advanced. The multimodal transcription supplies wonderful outcomes with no false positives:
transcribe_video(TestVideo.BRUT_FR_DOGS_WATER_LEAK_PT8M28S)Video (supply)
-------------- BRUT_FR_DOGS_WATER_LEAK_PT8M28S / gemini-2.0-flash --------------
Enter tokens : 46,514
Output tokens : 4,924Audio system (14)

Transcripts (61)

💡 Our immediate was crafted and examined with English movies, however works with out modification with this French video. It also needs to work for movies in these 100+ completely different languages.
💡 In a multilingual answer, we would ask to translate our transcriptions into any of these 100+ languages and even carry out textual content cleanup. This may be finished in a second request, because the multimodal transcription is advanced sufficient by itself.
💡 Gemini’s audio tokenizer detects greater than speech. If you happen to attempt to checklist non-speech sounds on audio tracks solely (to make sure the response doesn’t profit from any visible cues), you’ll see it could detect sounds resembling “canine bark”, “music”, “sound impact”, “footsteps”, “laughter”, “applause”…
💡 In our knowledge visualization tables, coloured rows are inference positives (audio system recognized by the mannequin), whereas grey rows correspond to negatives (unidentified audio system). This makes it simpler to know the outcomes. Because the immediate we crafted favors accuracy over recall, coloured rows are typically appropriate, and grey rows correspond both to unnamed/unidentifiable audio system (true negatives) or to audio system that ought to have been recognized (false negatives).
🎬 Complicated video
This Google DeepMind video is sort of advanced:
- It’s extremely edited and really dynamic
- Audio system are sometimes off-screen and different individuals will be seen as an alternative
- The researchers are sometimes in teams and it’s not at all times apparent who’s talking
- Some video pictures have been taken 2 years aside: the identical audio system can sound and look completely different!
Gemini 2.0 Flash generates a superb transcription regardless of the complexity. Nevertheless, it’s prone to checklist duplicate audio system as a result of video sort. Gemini 2.5 Professional supplies a deeper inference and manages to consolidate the audio system:
transcribe_video(
TestVideo.GDM_ALPHAFOLD_PT7M54S,
mannequin=Mannequin.GEMINI_2_5_PRO,
)Video (supply)
-------------------- GDM_ALPHAFOLD_PT7M54S / gemini-2.5-pro --------------------
Enter tokens : 43,354
Output tokens : 4,861
Ideas tokens: 80Audio system (11)

Transcripts (81)

🎬 Lengthy transcription
The full size of the transcribed textual content can rapidly attain the utmost variety of output tokens. With our present JSON response schema, we are able to attain 8,192 output tokens (supported by Gemini 2.0) with transcriptions of ~25min movies. Gemini 2.5 fashions help as much as 65,536 output tokens (8x extra) and allow us to transcribe longer movies.
For this 54-minute panel dialogue, Gemini 2.5 Professional makes use of solely ~30-35% of the enter/output token limits:
transcribe_video(
TestVideo.GDM_AI_FOR_SCIENCE_FRONTIER_PT54M23S,
mannequin=Mannequin.GEMINI_2_5_PRO,
)Video (supply)
------------ GDM_AI_FOR_SCIENCE_FRONTIER_PT54M23S / gemini-2.5-pro -------------
Enter tokens : 297,153
Output tokens : 22,896
Ideas tokens: 65Audio system (14)

Transcripts (593)

💡 On this lengthy video, the 5 panelists are appropriately transcribed, diarized, and recognized. Within the second half of the video, unseen attendees ask inquiries to the panel. They’re appropriately recognized as viewers members and, although their names and firms are by no means written on the display, Gemini appropriately extracts and even consolidates the knowledge from the audio cues.
🎬 1h+ video
Within the newest Google I/O keynote video (1h 10min):
- ~30-35%% of the token restrict is used (383k/1M in, 20/64k out)
- The dozen audio system are properly recognized, together with the demo “AI Voices” (“Gemini” and “Casey”)
- Speaker names are extracted from slanted textual content on the background display for the dwell keynote audio system (e.g., Josh Woodward at 0:07) and from lower-third on-screen textual content within the DolphinGemma reportage (e.g., Dr. Denise Herzing at 1:05:28)
transcribe_video(
TestVideo.GOOGLE_IO_DEV_KEYNOTE_PT1H10M03S,
mannequin=Mannequin.GEMINI_2_5_PRO,
)Video (supply)
-------------- GOOGLE_IO_DEV_KEYNOTE_PT1H10M03S / gemini-2.5-pro ---------------
Enter tokens : 382,699
Output tokens : 19,772
Ideas tokens: 75Audio system (14)

Transcripts (201)

🎬 40 speaker video
On this 1h 40min Google Cloud Subsequent keynote video:
- ~50-70% of the token restrict is used (547k/1M in, 45/64k out)
- 40 distinct voices are diarized
- 29 audio system are recognized, related to their 21 respective firms or divisions
- The transcription takes as much as 8 minutes (roughly 4 minutes with video tokens cached), which is 13 to 23 occasions quicker than watching your entire video with out pauses.
transcribe_video(
TestVideo.GOOGLE_CLOUD_NEXT_PT1H40M03S,
mannequin=Mannequin.GEMINI_2_5_PRO,
)Video (supply)
---------------- GOOGLE_CLOUD_NEXT_PT1H40M03S / gemini-2.5-pro -----------------
Enter tokens : 546,590
Output tokens : 45,398
Ideas tokens: 74Audio system (40)

Transcripts (853)

⚖️ Strengths & weaknesses
👍 Strengths
Total, Gemini is able to producing wonderful transcriptions that surpass human-generated ones in these points:
- Consistency of the transcription
- Excellent grammar and punctuation
- Spectacular semantic understanding
- No typos or transcription system errors
- Exhaustivity (each audible phrase is transcribed)
💡 As you understand, a single incorrect/lacking phrase (and even letter) can utterly change the which means. These strengths assist guarantee high-quality transcriptions and cut back the chance of misunderstandings.
If we examine YouTube’s user-provided transcriptions (typically by skilled caption distributors) to our auto-generated ones, we are able to observe some vital variations. Listed below are some examples from the final check:
| timecode | ❌ user-provided | ✅ our transcription |
|---|---|---|
| 9:47 | analysis and fashions | analysis and mannequin |
| 13:32 | used by 100,000 companies | used by over 100,000 companies |
| 18:19 | infrastructure core layer | infrastructure core for AI |
| 20:21 | {hardware} system | {hardware} technology |
| 23:42 | I do deployed ML fashions | Toyota deployed ML fashions |
| 34:17 | Vertex video | Vertex Media |
| 41:11 | velocity up app improvement | velocity up software coding and improvement |
| 42:15 | efficiency and confirmed insights | efficiency enchancment insights |
| 50:20 | throughout the milt agent ecosystem | throughout the multi-agent ecosystem |
| 52:50 | Salesforce, and Dun | Salesforce, or Dun |
| 1:22:28 | please virtually | Please welcome |
| 1:31:07 | organizations, like I say Charles | organizations like Charles |
| 1:33:23 | a number of public LOMs | a number of public LLMs |
| 1:33:54 | Gemini’s Agent tech AI | Gemini’s agentic AI |
| 1:34:24 | mitigated outsider danger | mitigated insider danger |
| 1:35:58 | from finish level, viral, networks | from endpoint, firewall, networks |
| 1:38:45 | We at Google are | We at Google Cloud are |
👎 Weaknesses
The present immediate is just not good although. It focuses first on the audio for transcription after which on all cues for speaker knowledge extraction. Although Gemini natively ensures a really excessive consolidation from the context, the immediate can present these unwanted side effects:
- Sensitivity to audio system’ pronunciation or accent
- Misspellings for correct nouns
- Inconsistencies between transcription and completely recognized speaker identify
Listed below are examples from the identical check:
| timecode | ✅ user-provided | ❌ our transcription |
|---|---|---|
| 3:31 | Bosun | Boson |
| 3:52 | Imagen | Think about |
| 3:52 | Veo | VO |
| 11:15 | Berman | Burman |
| 25:06 | Huang | Wang |
| 38:58 | Allegiant Stadium | Allegiance Stadium |
| 1:29:07 | Snyk | Sneak |
We’ll cease our exploration right here and go away it as an train, however listed here are attainable methods to repair these errors, so as of simplicity/price:
- Replace the immediate to make use of visible cues for correct nouns, resembling “Guarantee all correct nouns (individuals, firms, merchandise, and many others.) are spelled appropriately and constantly. Prioritize on-screen textual content for reference.”
- Enrich the immediate with a further preliminary desk to extract the correct nouns and use them explicitly within the context
- Add accessible video context metadata within the immediate
- Break up the immediate into two successive requests
📈 Suggestions & optimizations
🔧 Mannequin choice
Every mannequin can differ when it comes to efficiency, velocity, and value.
Right here’s a sensible abstract based mostly on the mannequin specs, our video check suite, and the present immediate:
| Mannequin | Efficiency | Velocity | Value | Max. enter tokens | Max. output tokens | Video sort |
|---|---|---|---|---|---|---|
| Gemini 2.0 Flash | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | 1,048,576 = 1M |
8,192 = 8k |
Commonplace video, as much as 25min |
| Gemini 2.5 Flash | ⭐⭐ | ⭐⭐ | ⭐⭐ | 1,048,576 = 1M |
65,536 = 64k |
Commonplace video, 25min+ |
| Gemini 2.5 Professional | ⭐⭐⭐ | ⭐ | ⭐ | 1,048,576 = 1M |
65,536 = 64k |
Complicated video or 1h+ video |
🔧 Video section
You don’t at all times want to research movies from begin to end. You’ll be able to point out a video section with begin and/or finish offsets within the VideoMetadata construction.
On this instance, Gemini will solely analyze the 30:00-50:00 section of the video:
video_metadata = VideoMetadata(
start_offset="1800.0s",
end_offset="3000.0s",
…
)🔧 Media decision
In our check suite, the movies are pretty customary. We acquired wonderful outcomes through the use of a “low” media decision (“medium” being the default), specified with the GenerateContentConfig.media_resolution parameter.
💡 This supplies quicker and cheaper inferences, whereas additionally enabling the evaluation of 3x longer movies.
We used a easy heuristic based mostly on video period, however you may need to make it dynamic on a per-video foundation:
def get_media_resolution_for_video(video: Video) -> MediaResolution | None:
if not (video_duration := get_video_duration(video)):
return None # Default
# For testing functions, that is based mostly on video period, as our brief movies are usually extra detailed
less_than_five_minutes = video_duration < timedelta(minutes=5)
if less_than_five_minutes:
media_resolution = MediaResolution.MEDIA_RESOLUTION_MEDIUM
else:
media_resolution = MediaResolution.MEDIA_RESOLUTION_LOW
return media_resolution⚠️ If you choose a “low” media decision and expertise an obvious lack of understanding, you is likely to be dropping essential particulars within the sampled video frames. That is straightforward to repair: change again to the default media decision.
🔧 Sampling body fee
The default sampling body fee of 1 FPS labored wonderful in our exams. You may need to customise it for every video:
SamplingFrameRate = float
def get_sampling_frame_rate_for_video(video: Video) -> SamplingFrameRate | None:
sampling_frame_rate = None # Default (1 FPS for present fashions)
# [Optional] Outline a customized FPS: 0.0 < sampling_frame_rate <= 24.0
return sampling_frame_rate💡 You’ll be able to combine the parameters. On this excessive instance, assuming the enter video has a 24fps body fee, all frames will likely be sampled for a 10s section:
video_metadata = VideoMetadata(
start_offset="42.0s",
end_offset="52.0s",
fps=24.0,
)⚠️ If you happen to use the next sampling fee, this multiplies the variety of frames (and tokens) accordingly, rising latency and value. As
10s × 24fps = 240 frames = 4×60s × 1fps, this 10-second evaluation at 24 FPS is equal to a 4-minute default evaluation at 1 FPS.
🎯 Precision vs recall
The immediate can affect the precision and recall of our knowledge extractions, particularly when utilizing express versus implicit wording. In order for you extra qualitative outcomes, favor precision utilizing express wording; if you’d like extra quantitative outcomes, favor recall utilizing implicit wording:
| wording | favors | generates much less | LLM conduct |
|---|---|---|---|
| express | precision | false positives | depends extra (or solely) on the offered context |
| implicit | recall | false negatives | depends on the general context, infers extra, and might use its coaching data |
Listed below are examples that may result in subtly completely different outcomes:
| wording | verbs | qualifiers |
|---|---|---|
| express | “extract”, “quote” | “acknowledged”, “direct”, “precise”, “verbatim” |
| implicit | “establish”, “deduce” | “discovered”, “oblique”, “attainable”, “potential” |
💡 Totally different fashions can even behave otherwise for a similar immediate. Specifically, extra performant fashions might sound extra “assured” and make extra implicit inferences or consolidations.
💡 For instance, on this AlphaFold video, on the 04:57 timecode, “Spring 2020” is first displayed as context. Then, a brief declaration from “The Prime Minister” is heard within the background (“You need to keep at residence”) with out some other hints. When requested to “establish” (slightly than “extract”) the speaker, Gemini is prone to infer extra and attribute the voice to “Boris Johnson”. There’s completely no express point out of Boris Johnson; his id is appropriately inferred from the context (“UK”, “Spring 2020”, and “The Prime Minister”).
🏷️ Metadata
In our present exams, Gemini solely makes use of audio and body tokens, tokenized from sources on Google Cloud Storage or YouTube. When you’ve got further video metadata, this generally is a goldmine; attempt to add it to your immediate and enrich the video context for higher outcomes upfront.
Probably useful metadata:
- Video description: This could present a greater understanding of the place and when the video was shot.
- Speaker information: This can assist auto-correct names which are solely heard and never apparent to spell.
- Entity information: Total, this can assist get higher transcriptions for customized or personal knowledge.
💡 For YouTube movies, no further metadata or transcript is fetched. Gemini solely receives the uncooked audio and video streams. You’ll be able to examine this your self by evaluating your outcomes with YouTube’s computerized captioning (no punctuation, audio solely) or user-provided transcripts (cleaned up), when accessible.
💡 If you understand your video considerations a group or an organization, including inside knowledge within the context can assist appropriate or full the requested speaker names (offered there aren’t any homonyms in the identical context), firms, and job titles.
💡 On this French reportage, within the 06:16-06:31 video shot, there are two canines: Arnold and Rio. “Arnold” is clearly audible, repeated 3 times, and appropriately transcribed. “Rio” is known as solely as soon as, audible for a fraction of a second in a loud atmosphere, and the audio transcription can differ. Offering the names of the entire group (homeowners & canines, even when they don’t seem to be all within the video) can assist in transcribing this brief identify constantly.
💡 It also needs to be attainable to floor the outcomes with Google Search, Google Maps, or your individual RAG system. See Grounding overview.
🔬 Debugging & proof
Iterating by way of successive prompts and debugging LLM outputs will be difficult, particularly when making an attempt to know the explanations for the outcomes.
It’s attainable to ask Gemini to offer proof within the response. In our video transcription answer, we might request a timecoded “proof” for every speaker’s recognized identify, firm, or position. This allows linking outcomes to their sources, discovering and understanding sudden insights, checking potential false positives…
💡 Within the examined movies, when making an attempt to know the place the insights got here from, requesting proof yielded very insightful explanations, for instance:
- Individual names may very well be extracted from numerous sources (video convention captions, badges, unseen contributors introducing themselves when asking questions in a convention panel…)
- Firm names may very well be discovered from textual content on uniforms, backpacks, automobiles…
💡 In a doc knowledge extraction answer, we might request to offer an “excerpt” as proof, together with web page quantity, chapter quantity, or some other related location info.
🐘 Verbose JSON
The JSON format is at the moment the commonest strategy to generate structured outputs with LLMs. Nevertheless, JSON is a slightly verbose knowledge format, as subject names are repeated for every object. For instance, an output can appear to be the next, with many repeated underlying tokens:
{
"task1_transcripts": [
{ "start": "00:02", "text": "We've…", "voice": 1 },
{ "start": "00:07", "text": "But we…", "voice": 1 }
// …
],
"task2_speakers": [
{
"voice": 1,
"name": "John Moult",
"company": "University of Maryland",
"position": "Co-Founder, CASP",
"role_in_video": "Expert"
},
// …
{
"voice": 3,
"name": "Demis Hassabis",
"company": "DeepMind",
"position": "Founder and CEO",
"role_in_video": "Team Leader"
}
// …
]
}To optimize output measurement, an fascinating chance is to ask Gemini to generate an XML block containing a CSV for every of your tabular extractions. The sector names are specified as soon as within the header, and through the use of tab separators, for instance, we are able to obtain extra compact outputs like the next:
begin textual content voice
00:02 We have… 1
00:07 However we… 1
…
voice identify firm place role_in_video
1 John Moult College of Maryland Co-Founder, CASP Skilled
…
3 Demis Hassabis DeepMind Founder and CEO Staff Chief
…
💡 Gemini excels at patterns and codecs. Relying in your wants, be at liberty to experiment with JSON, XML, CSV, YAML, and any customized structured codecs. It’s probably that the business will evolve to permit much more elaborate structured outputs.
🐿️ Context caching
Context caching optimizes the fee and the latency of repeated requests utilizing the identical base inputs.
There are two methods requests can profit from context caching:
- Implicit caching: By default, upon the primary request, enter tokens are cached, to speed up responses for subsequent requests with the identical base inputs. That is absolutely automated and no code change is required.
- Specific caching: You place particular inputs into the cache and reuse this cached content material as a base on your requests. This supplies full management however requires managing the cache manually.
Instance of implicit caching 🔽
model_id = "gemini-2.0-flash"
video_file_data = FileData(
file_uri="gs://bucket/path/to/my-video.mp4",
mime_type="video/mp4",
)
video = Half(file_data=video_file_data)
prompt_1 = "Record the individuals seen within the video."
prompt_2 = "Summarize what occurs to John Smith."
# ✅ Request A1: static knowledge (video) positioned first
response = consumer.fashions.generate_content(
mannequin=model_id,
contents=,
)
# ✅ Request A2: probably cache hit for the video tokens
response = consumer.fashions.generate_content(
mannequin=model_id,
contents=,
)💡 Implicit caching will be disabled on the undertaking stage (see knowledge governance).
Implicit caching is prefix-based, so it solely works when you put static knowledge first and variable knowledge final.
Instance of requests stopping implicit caching 🔽
# ❌ Request B1: variable enter positioned first
response = consumer.fashions.generate_content(
mannequin=model_id,
contents=[prompt_1, video],
)
# ❌ Request B2: no cache hit
response = consumer.fashions.generate_content(
mannequin=model_id,
contents=[prompt_2, video],
)💡 This explains why the data-plus-instructions enter order is most popular, for efficiency (not LLM-related) causes.
Value-wise, the enter tokens retrieved with a cache hit profit from a 75% low cost within the following instances:
- Implicit caching: With all Gemini fashions, cache hits are robotically discounted (with none management on the cache).
- Specific caching: With all Gemini fashions and supported fashions in Mannequin Backyard, you management your cached inputs and their lifespans to make sure cache hits.
Instance of express caching 🔽
from google.genai.sorts import (
Content material,
CreateCachedContentConfig,
FileData,
GenerateContentConfig,
Half,
)
model_id = "gemini-2.0-flash-001"
# Enter video
video_file_data = FileData(
file_uri="gs://cloud-samples-data/video/JaneGoodall.mp4",
mime_type="video/mp4",
)
video_part = Half(file_data=video_file_data)
video_contents = [Content(role="user", parts=[video_part])]
# Video explicitly put in cache, with time-to-live (TTL) earlier than computerized deletion
cached_content = consumer.caches.create(
mannequin=model_id,
config=CreateCachedContentConfig(
ttl="1800s",
display_name="video-cache",
contents=video_contents,
),
)
if cached_content.usage_metadata:
print(f"Cached tokens: {cached_content.usage_metadata.total_token_count or 0:,}")
# Cached tokens: 46,171
# ✅ Video tokens are cached (customary tokenization fee + storage price for TTL period)
cache_config = GenerateContentConfig(cached_content=cached_content.identify)
# Request #1
response = consumer.fashions.generate_content(
mannequin=model_id,
contents="Record the individuals talked about within the video.",
config=cache_config,
)
if response.usage_metadata:
print(f"Enter tokens : {response.usage_metadata.prompt_token_count or 0:,}")
print(f"Cached tokens: {response.usage_metadata.cached_content_token_count or 0:,}")
# Enter tokens : 46,178
# Cached tokens: 46,171
# ✅ Cache hit (75% low cost)
# Request #i (throughout the TTL interval)
# …
# Request #n (throughout the TTL interval)
response = consumer.fashions.generate_content(
mannequin=model_id,
contents="Record all of the timecodes when Jane Goodall is talked about.",
config=cache_config,
)
if response.usage_metadata:
print(f"Enter tokens : {response.usage_metadata.prompt_token_count or 0:,}")
print(f"Cached tokens: {response.usage_metadata.cached_content_token_count or 0:,}")
# Enter tokens : 46,182
# Cached tokens: 46,171
# ✅ Cache hit (75% low cost)💡 Specific caching wants a particular mannequin model (like
…-001on this instance) to make sure the cache stays legitimate and isn’t affected by a mannequin replace.
ℹ️ Be taught extra about Context caching.
⏳ Batch prediction
If it is advisable course of a big quantity of movies and don’t want synchronous responses, you need to use a single batch request and cut back your price.
💡 Batch requests for Gemini fashions get a 50% low cost in comparison with customary requests.
ℹ️ Be taught extra about Batch prediction.
♾️ To manufacturing… and past
A couple of further notes:
- The present immediate is just not good and will be improved. It has been preserved in its present state for example its improvement beginning with Gemini 2.0 Flash and a easy video check suite.
- The Gemini 2.5 fashions are extra succesful and intrinsically present a greater video understanding. Nevertheless, the present immediate has not been optimized for them. Writing optimum prompts for various fashions is one other problem.
- If you happen to check transcribing your individual movies, particularly several types of movies, chances are you’ll run into new or particular points. They’ll in all probability be addressed by enriching the immediate.
- Future fashions will probably help extra output options. This could enable for richer structured outputs and for easier prompts.
- As fashions continue learning, it’s additionally attainable that multimodal video transcription will turn into a one-liner immediate.
- Gemini’s picture and audio tokenizers are really spectacular and allow many different use instances. To totally grasp the extent of the chances, you possibly can run unit exams on pictures or audio information.
- We constrained our problem to utilizing a single request, which might dilute the LLM’s consideration in such wealthy multimodal contexts. For optimum ends in a large-scale answer, splitting the processing into two steps (i.e., requests) ought to assist Gemini’s consideration focus even additional. In step one, we’d extract and diarize the audio stream solely, which ought to end in probably the most exact speech-to-text transcription (perhaps with extra voice identifiers than precise audio system, however with a minimal variety of false positives). Within the second step, we’d reinject the transcription to give attention to extracting and consolidating speaker knowledge from the video frames. This might even be an answer to course of very lengthy movies, even these a number of hours in period.
🏁 Conclusion
Multimodal video transcription, which requires the advanced synthesis of audio and visible knowledge, is a real problem for ML practitioners, with out mainstream options. A conventional strategy, involving an elaborate pipeline of specialised fashions, can be engineering-intensive with none assure of success. In distinction, Gemini proved to be a flexible toolbox for reaching a robust and easy answer based mostly on a single immediate:

We managed to handle this advanced drawback with the next methods:
- Prototyping with open prompts to develop instinct about Gemini’s pure strengths
- Making an allowance for how LLMs work below the hood
- Crafting more and more particular prompts utilizing a tabular extraction technique
- Producing structured outputs to maneuver in direction of production-ready code
- Including knowledge visualization for simpler interpretation of responses and smoother iterations
- Adapting default parameters to optimize the outcomes
- Conducting extra exams, iterating, and even enriching the extracted knowledge
These rules ought to apply to many different knowledge extraction domains and assist you to resolve your individual advanced issues. Have enjoyable and comfortable fixing!


{kind=link}