There’s a rising demand from prospects to include generative AI into their companies. Many use instances contain utilizing pre-trained massive language fashions (LLMs) by approaches like Retrieval Augmented Era (RAG). Nevertheless, for superior, domain-specific duties or these requiring particular codecs, mannequin customization methods resembling fine-tuning are typically crucial. Amazon Bedrock gives you with the flexibility to customise main basis fashions (FMs) resembling Anthropic’s Claude 3 Haiku and Meta’s Llama 3.1.
Amazon Bedrock is a completely managed service that makes FMs from main AI startups and Amazon out there by an API, so you may select from a variety of FMs to search out the mannequin that’s greatest suited on your use case. Amazon Bedrock affords a serverless expertise, so you may get began shortly, privately customise FMs with your personal knowledge, and combine and deploy them into your purposes utilizing AWS instruments with out having to handle any infrastructure.
Tremendous-tuning is a supervised coaching course of the place labeled immediate and response pairs are used to additional prepare a pre-trained mannequin to enhance its efficiency for a specific use case. One constant ache level of fine-tuning is the shortage of information to successfully customise these fashions. Gathering related knowledge is tough, and sustaining its high quality is one other hurdle. Moreover, fine-tuning LLMs requires substantial useful resource dedication. In such situations, artificial knowledge era affords a promising answer. You’ll be able to create artificial coaching knowledge utilizing a bigger language mannequin and use it to fine-tune a smaller mannequin, which has the advantage of a faster turnaround time.
On this publish, we discover the best way to use Amazon Bedrock to generate artificial coaching knowledge to fine-tune an LLM. Moreover, we offer concrete analysis outcomes that showcase the facility of artificial knowledge in fine-tuning when knowledge is scarce.
Resolution overview
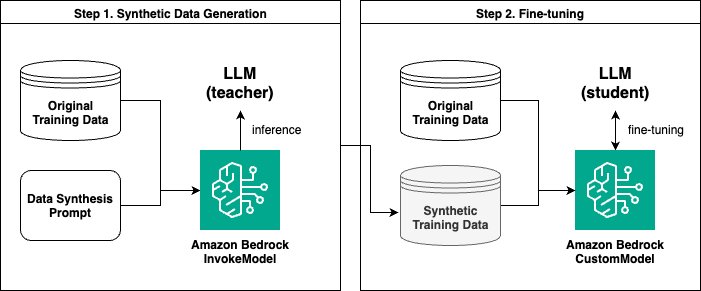
The answer contains two essential steps:
- Generate artificial knowledge utilizing the Amazon Bedrock InvokeModel API.
- Tremendous-tune utilizing an Amazon Bedrock customized mannequin.
For artificial knowledge era, we use a bigger language mannequin (resembling Anthropic’s Claude 3 Sonnet on Amazon Bedrock) because the trainer mannequin, and a smaller language mannequin (resembling Anthropic’s Claude Instantaneous 1.2 or Claude 3 Haiku on Amazon Bedrock) as the coed mannequin for fine-tuning. We use the bigger trainer mannequin to generate new knowledge primarily based on its data, which is then used to coach the smaller scholar mannequin. This idea is much like data distillation utilized in deep studying, besides that we’re utilizing the trainer mannequin to generate a brand new dataset from its data somewhat than instantly modifying the structure of the coed mannequin.
The next diagram illustrates the general move of the answer.

Lastly, we share our experiment outcomes, the place we examine the efficiency of the mannequin fine-tuned with artificial knowledge to the baseline (not fine-tuned) mannequin and to a mannequin fine-tuned with an equal quantity of unique coaching knowledge.
Stipulations
To generate artificial knowledge and fine-tune fashions utilizing Amazon Bedrock, you first have to create an AWS Identification and Entry Administration (IAM) service position with the suitable permissions. This position is utilized by Amazon Bedrock to entry the mandatory sources in your behalf.
For directions on creating the service position, discuss with Create a service position for mannequin customization. Additionally, ensure that the position has the permission for the bedrock:InvokeModel motion.
If you happen to’re operating this code utilizing an Amazon SageMaker pocket book occasion, edit the IAM position that’s hooked up to the pocket book (for instance, AmazonSageMaker-ExecutionRole-XXX) as a substitute of making a brand new position. Observe Create a service position for mannequin customization to change the belief relationship and add the S3 bucket permission. Moreover, on the position’s Permissions tab, create the next inline insurance policies:
- Coverage identify: bedrock-customization
- Coverage identify: iam-pass-role
The ultimate permission insurance policies for the SageMaker execution position ought to appear to be the next, which embrace AmazonSageMaker-ExecutionPolicy, AmazonSageMakerFullAccess, bedrock-customization, and iam-pass-role.

Generate artificial knowledge utilizing the Amazon Bedrock InvokeModel API
We use the Amazon Bedrock InvokeModel API to generate artificial knowledge for fine-tuning. You should use the API to programmatically ship an inference (textual content era) request to the mannequin of your alternative. All you want is a well-crafted immediate tailor-made for knowledge synthesis. We used the next pattern immediate for our use case:
The objective of our use case was to fine-tune a mannequin to generate a related and coherent reply primarily based on a given reference doc and a query. RAG is a well-liked approach used for such Q&A duties; nonetheless, one important problem with RAG is the potential for retrieving unrelated or irrelevant paperwork, which might result in inaccurate responses. You’ll be able to apply fine-tuning to information the mannequin to raised concentrate on the relevance of the paperwork to the query as a substitute of utilizing the offered paperwork with out context to reply the query.
Our dataset contains Q&A pairs with reference paperwork concerning AWS companies. Every pattern has as much as 5 reference paperwork as context, and a single-line query follows. The next desk reveals an instance.
| doc |
Context: Doc 1: Step 1: Put together to work with AWS CodeStar tasks On this step, you create an AWS CodeStar service position and an Amazon EC2 key pair, in an effort to start creating and dealing with AWS CodeStar tasks. You probably have used AWS CodeStar earlier than, skip forward to Step 2 Step 2: Create a Challenge in AWS CodeStar. For this step, comply with the directions in Setting Up AWS CodeStar within the AWS CodeStar Person Information. Don’t create a brand new AWS account, IAM person, or IAM group as a part of these directions. Use those you created or recognized in Group Setup for AWS Cloud9. While you end following these directions, return to this subject. Doc 2: Setting Up AWS CodeStar Earlier than you can begin utilizing AWS CodeStar, it’s essential to full the next steps. Subjects: Step 1: Create an account Step 2: Create the AWS CodeStar Service Position Step 3: Configure the Person’s IAM Permissions Step 4: Create an Amazon EC2 Key Pair for AWS CodeStar Initiatives Step 5: Open the AWS CodeStar Console Subsequent Steps Doc 3: How Do I Get Began with AWS CodeStar? To get began with AWS CodeStar: Put together to make use of AWS CodeStar by following the steps in Setting Up AWS CodeStar. Experiment with AWS CodeStar by following the steps within the Getting Began with AWS CodeStar tutorial. Share your mission with different builders by following the steps in Add Group Members to an AWS CodeStar Challenge. Combine your favourite IDE by following the steps in Use an IDE with AWS CodeStar. Doc 4: Step 2: Create a mission in AWS CodeStar On this step, you create a mission in AWS CodeStar. If you have already got a mission in AWS CodeStar you wish to use, skip forward to Step 3: Create an AWS Cloud9 Growth Atmosphere and Join It to the Challenge. For this step, comply with the directions in Create a Challenge in AWS CodeStar within the AWS CodeStar Person Information. Within the AWS CodeStar create mission wizard, while you get to the Setup instruments web page or Connect with your supply repository web page, select Skip, after which return to this subject. Doc 5: Create a Challenge in AWS CodeStar You employ the AWS CodeStar console to create a mission. If you happen to use a mission template, it units up the required sources for you. The template additionally contains pattern code that you should use to start out coding. To create a mission, check in to the AWS Administration Console with an IAM person that has the AWSCodeStarFullAccess coverage or equal permissions. For extra data, see Setting Up AWS CodeStar. Observe: You will need to full the steps in Setting Up AWS CodeStar earlier than you may full the procedures on this subject. Subjects Create a Challenge in AWS CodeStar (Console) Create a Challenge in AWS CodeStar (AWS CLI) Reply the next query to the very best of your means. Use and paraphrase the data within the context, if it solutions the query. In any other case, depend on your data and reminiscence. |
| query | How do I get began with AWS CodeStar? |
| reply |
To get began with AWS CodeStar, comply with these steps: 1. Put together to work with AWS CodeStar tasks: a. Create an AWS CodeStar service position by following the directions in “Setting Up AWS CodeStar” (Doc 2) within the AWS CodeStar Person Information [1]. b. Create an Amazon EC2 key pair for AWS CodeStar tasks, as described in the identical information [1]. 2. Create a mission in AWS CodeStar: a. Check in to the AWS Administration Console with an IAM person that has the AWSCodeStarFullAccess coverage or equal permissions [2]. b. Within the AWS CodeStar console, choose one of many out there mission templates, which is able to mechanically provision all of the required sources on your mission [3]. c. As soon as your mission is provisioned, you may see your operating utility from the Software endpoints tile [3]. 3. Connect with the AWS CodeCommit supply repository on your mission: a. Use the steps offered within the CodeStar console to hook up with the AWS CodeCommit supply repository on your mission [3]. b. Start coding and making adjustments to your mission’s supply code. 4. Monitor and handle adjustments within the launch course of: a. Use the mission dashboard to trace and handle adjustments within the launch course of [3]. b. View the newest mission exercise on the dashboard. 5. Share your mission with different builders: a. Observe the steps in “Add Group Members to an AWS CodeStar Challenge” to share your mission with different builders [3]. 6. Combine your favourite IDE: a. Observe the steps in “Use an IDE with AWS CodeStar” to combine your most well-liked Built-in Growth Atmosphere (IDE) with AWS CodeStar [3]. [1] https://docs.aws.amazon.com/codestar/newest/userguide/setting-up.html [2] https://docs.aws.amazon.com/codestar/newest/userguide/create-project.html [3] https://docs.aws.amazon.com/codestar/newest/userguide/getting-started.html |
For knowledge synthesis, we requested the mannequin to generate three new Q&A pairs per reference doc. Nevertheless, you may modify the quantity as wanted. The essential half is to make the mannequin assume deeply about a wide range of matters. As a result of the aim of producing artificial knowledge is to complement the coaching dataset, it’s extra helpful to have the mannequin take a look at totally different elements of the paperwork and create Q&A pairs with totally different matters than the unique.
The next instance reveals the best way to generate artificial knowledge with the Amazon Bedrock InvokeModel API. We examined the previous immediate with Anthropic’s Claude 3 Sonnet. If you wish to check a distinct mannequin, retrieve the corresponding mannequin ID from Amazon Bedrock mannequin IDs, and change the modelId variable within the operate.
The previous operate returns three JSONL information in strings with query, reply, and subject as keys. The next parse_llm_output operate hundreds the strings and makes use of common expressions to retrieve the generated questions and solutions. Then, the create_synthetic_samples operate combines these two functionalities to provide the ultimate artificial coaching samples.
The next script combines the entire previous features and provides you the ultimate coaching set with each unique and artificial samples. We convert the samples into the format required by the customization job utilizing the to_customization_format operate and save them as prepare.jsonl. Assume the enter knowledge is a CSV file with three columns: doc, query, and reply.
Tremendous-tune utilizing an Amazon Bedrock customized mannequin
Now that you’ve got the artificial knowledge generated by the trainer mannequin alongside along with your unique knowledge, it’s time to coach the coed mannequin. We fine-tune the coed mannequin utilizing the Amazon Bedrock customized mannequin performance.
Mannequin customization is the method of offering coaching knowledge to an FM to enhance its efficiency for particular use instances. Amazon Bedrock affords three mannequin customization strategies as of this writing:
- Tremendous-tuning
- Continued pre-training
- Distillation (preview).
You’ll be able to create your personal customized mannequin utilizing any of those strategies by the Amazon Bedrock console or API. For extra data on supported fashions and AWS Areas with numerous customization strategies, please see Person information for mannequin customization. On this part, we concentrate on the best way to fine-tune a mannequin utilizing the API.
To create a fine-tuning job in Amazon Bedrock, full the next prerequisite steps:
- Create an Amazon Easy Storage Service (Amazon S3) bucket on your coaching knowledge and one other one on your output knowledge (the names should be distinctive).
- Add the jsonl file to the coaching knowledge bucket.
- Just remember to have created an IAM position, as described within the Stipulations
When these steps are full, run the next code to submit a brand new fine-tuning job. In our use case, the coed mannequin was Anthropic’s Claude Instantaneous 1.2. On the time of writing, Anthropic’s Claude 3 Haiku is usually out there, and we advocate following the remainder of the code utilizing Anthropic’s Claude 3 Haiku. For the discharge announcement, see Tremendous-tuning for Anthropic’s Claude 3 Haiku in Amazon Bedrock is now usually out there.
If you wish to strive totally different fashions, it’s essential to test the mannequin supplier’s phrases of service your self. Many suppliers prohibit utilizing their fashions to coach competing fashions. For the most recent mannequin help data, see Supported Areas and fashions for mannequin customization, and change baseModelIdentifier accordingly. Totally different fashions have totally different hyperparameters. For extra data, see Customized mannequin hyperparameters.
When the standing adjustments to Accomplished, your fine-tuned scholar mannequin is prepared to be used. To run an inference with this practice mannequin, that you must buy provisioned throughput. A versatile No dedication possibility is offered for customized fashions, which will be turned off when not in use and billed by the hour. A value estimate is offered on the console prior to buying provisioned throughput.
On the Amazon Bedrock console, select Customized fashions within the navigation pane. Choose the mannequin you fine-tuned and select Buy provisioned throughput.

The mannequin identify and sort are mechanically chosen for you. Choose No dedication for Dedication time period. After you make this choice, the estimated value is proven. If you happen to’re okay with the pricing, select Affirm buy.

When the Provisioned Throughput turns into out there, retrieve the ARN of the provisioned customized mannequin and run the inference:
Consider
On this part, we share our experiment outcomes to supply knowledge factors on how the artificial knowledge generated by a trainer mannequin can enhance the efficiency of a scholar mannequin. For analysis strategies, we used an LLM-as-a-judge method, the place a decide mannequin compares responses from two totally different fashions and picks a greater response. Moreover, we performed a guide analysis on a small subset to evaluate whether or not the LLM-as-a-judge and human judges have aligned preferences.
We carried out managed experiments the place we in contrast 4 totally different fashions as follows: 1,500 artificial coaching samples for the 4th mannequin had been generated by Anthropic’s Claude 3 Sonnet, and we created three artificial samples per one unique reference doc (3 samples * 500 unique reference paperwork = 1,500 artificial samples).
| Instantaneous base mannequin | Anthropic’s Claude Instantaneous with none customization |
| Tremendous-tuned 500 unique | Anthropic’s Claude Instantaneous fine-tuned with 500 unique coaching samples |
| Tremendous-tuned 2,000 unique | Anthropic’s Claude Instantaneous fine-tuned with 2,000 unique coaching samples |
| Tremendous-tuned with artificial | Anthropic’s Claude Instantaneous fine-tuned with 500 unique coaching samples plus 1,500 artificial coaching samples |
LLM-as-a-judge outcomes
LLM output analysis is a vital step in creating generative AI purposes, however it’s costly and takes appreciable time if accomplished manually. Another answer to systematically consider output high quality in massive quantity is the LLM-as-a-judge method, the place an LLM is used to judge one other LLM’s responses.
For our use case, we used Anthropic’s Claude 3 Sonnet and Meta Llama 3 70B because the judges. We requested the LLM judges to match outputs from two totally different fashions and select one over the opposite or state a tie. The next chart summarizes the judges’ selections. Every quantity represents the share of occasions when the respective mannequin was chosen as offering a greater reply, excluding tie instances. The check set contained 343 samples.

As proven within the previous chart, the Anthropic’s Claude 3 Sonnet decide most well-liked the response from the fine-tuned mannequin with artificial examples over the Anthropic’s Claude Instantaneous base mannequin (84.8% choice) and the fine-tuned mannequin with unique 500 samples (72.3% choice). Nevertheless, the decide concluded that the fine-tuned mannequin with 2,000 unique examples was most well-liked over the fine-tuned mannequin with artificial examples (32.3% choice). This aligns with the expectation that when massive, high-quality unique knowledge is offered, it’s higher to make use of the massive coaching knowledge that precisely displays the goal knowledge distribution.

The Meta Llama decide reached the same conclusion. As proven within the previous chart, it most well-liked the response from the fine-tuned mannequin with artificial samples over the Anthropic’s Claude Instantaneous base mannequin (75.6% choice) and the fine-tuned mannequin with unique 500 examples (76.4% choice), however the fine-tuned mannequin with 2,000 unique examples was the last word winner.
Human analysis outcomes
To enrich the LLM-as-a-judge end result, we performed guide analysis with two human judges. We requested the 2 human evaluators to carry out the identical pairwise comparability activity because the LLM decide, however for 20 examples. The next chart summarizes the outcomes.

As proven within the previous chart, the 2 human evaluators reached the same conclusion, reinforcing the LLM-as-a-judge end result. The fine-tuned mannequin with artificial examples produced outputs that had been extra preferable than the Anthropic’s Claude Instantaneous base mannequin and the fine-tuned mannequin with the unique 500 examples; nonetheless, it didn’t outperform the fine-tuned mannequin with the two,000 unique examples.
These comparative analysis outcomes from each the LLM judges and human judges strongly reveal the facility and potential of utilizing knowledge synthesis when coaching knowledge is scarce. Furthermore, through the use of high-quality knowledge from the trainer mannequin, we will successfully prepare the coed mannequin, which is light-weight and cost-effective for deployment in a manufacturing surroundings.
Amazon Bedrock evaluations
Working LLM-as-a-judge and human analysis has grow to be a lot simpler with Amazon Bedrock. Mannequin analysis on Amazon Bedrock lets you consider, examine, and choose the very best FMs on your use case. Human analysis workflows can use your personal staff or an AWS-managed group as reviewers. For extra data on the best way to arrange a human analysis workflow, see Creating your first mannequin analysis that makes use of human employees. The most recent characteristic, LLM-as-a-judge, is now in preview and lets you assess a number of high quality dimensions together with correctness, helpfulness, and accountable AI standards resembling reply refusal and harmfulness. For step-by-step directions, see New RAG analysis and LLM-as-a-judge capabilities in Amazon Bedrock.
Clear up
Ensure that to delete the next sources to keep away from incurring value:
- Provisioned throughput for the customized mannequin
- The training_bucket and output_bucket S3 buckets
Conclusion
On this publish, we explored the best way to use Amazon Bedrock to generate artificial coaching knowledge utilizing a big trainer language mannequin and fine-tune a smaller scholar mannequin with artificial knowledge. We offered directions on producing artificial knowledge utilizing the Amazon Bedrock InvokeModel API and fine-tuning the coed mannequin utilizing an Amazon Bedrock customized mannequin. Our analysis outcomes, primarily based on each an LLM-as-a-judge method and human analysis, demonstrated the effectiveness of artificial knowledge in bettering the coed mannequin’s efficiency when unique coaching knowledge is proscribed.
Though fine-tuning with a considerable amount of high-quality unique knowledge stays the best method, our findings spotlight the promising potential of artificial knowledge era as a viable answer when coping with knowledge shortage. This system can allow extra environment friendly and cost-effective mannequin customization for domain-specific or specialised use instances.
If you happen to’re excited about working with the AWS Generative AI Innovation Heart and studying extra about LLM customization and different generative AI use instances, go to Generative AI Innovation Heart.
In regards to the Writer
 Sujeong Cha is a Deep Studying Architect on the AWS Generative AI Innovation Heart, the place she makes a speciality of mannequin customization and optimization. She has intensive hands-on expertise in fixing prospects’ enterprise use instances by using generative AI in addition to conventional AI/ML options. Sujeong holds a M.S. diploma in Knowledge Science from New York College.
Sujeong Cha is a Deep Studying Architect on the AWS Generative AI Innovation Heart, the place she makes a speciality of mannequin customization and optimization. She has intensive hands-on expertise in fixing prospects’ enterprise use instances by using generative AI in addition to conventional AI/ML options. Sujeong holds a M.S. diploma in Knowledge Science from New York College.
 Arijit Ghosh Chowdhury is a Scientist with the AWS Generative AI Innovation Heart, the place he works on mannequin customization and optimization. In his position, he works on utilized analysis in fine-tuning and mannequin evaluations to allow GenAI for numerous industries. He has a Grasp’s diploma in Pc Science from the College of Illinois at Urbana Champaign, the place his analysis centered on query answering, search and area adaptation.
Arijit Ghosh Chowdhury is a Scientist with the AWS Generative AI Innovation Heart, the place he works on mannequin customization and optimization. In his position, he works on utilized analysis in fine-tuning and mannequin evaluations to allow GenAI for numerous industries. He has a Grasp’s diploma in Pc Science from the College of Illinois at Urbana Champaign, the place his analysis centered on query answering, search and area adaptation.
 Sungmin Hong is a Senior Utilized Scientist at Amazon Generative AI Innovation Heart the place he helps expedite the number of use instances of AWS prospects. Earlier than becoming a member of Amazon, Sungmin was a postdoctoral analysis fellow at Harvard Medical Faculty. He holds Ph.D. in Pc Science from New York College. Outdoors of labor, Sungmin enjoys mountain climbing, studying and cooking.
Sungmin Hong is a Senior Utilized Scientist at Amazon Generative AI Innovation Heart the place he helps expedite the number of use instances of AWS prospects. Earlier than becoming a member of Amazon, Sungmin was a postdoctoral analysis fellow at Harvard Medical Faculty. He holds Ph.D. in Pc Science from New York College. Outdoors of labor, Sungmin enjoys mountain climbing, studying and cooking.
 Yiyue Qian is an Utilized Scientist II on the AWS Generative AI Innovation Heart, the place she develops generative AI options for AWS prospects. Her experience encompasses designing and implementing modern AI-driven and deep studying methods, specializing in pure language processing, pc imaginative and prescient, multi-modal studying, and graph studying. Yiyue holds a Ph.D. in Pc Science from the College of Notre Dame, the place her analysis centered on superior machine studying and deep studying methodologies. Outdoors of labor, she enjoys sports activities, mountain climbing, and touring.
Yiyue Qian is an Utilized Scientist II on the AWS Generative AI Innovation Heart, the place she develops generative AI options for AWS prospects. Her experience encompasses designing and implementing modern AI-driven and deep studying methods, specializing in pure language processing, pc imaginative and prescient, multi-modal studying, and graph studying. Yiyue holds a Ph.D. in Pc Science from the College of Notre Dame, the place her analysis centered on superior machine studying and deep studying methodologies. Outdoors of labor, she enjoys sports activities, mountain climbing, and touring.
 Wei-Chih Chen is a Machine Studying Engineer on the AWS Generative AI Innovation Heart, the place he works on mannequin customization and optimization for LLMs. He additionally builds instruments to assist his group deal with numerous features of the LLM improvement life cycle—together with fine-tuning, benchmarking, and load-testing—that accelerating the adoption of numerous use instances for AWS prospects. He holds an M.S. diploma in Pc Science from UC Davis.
Wei-Chih Chen is a Machine Studying Engineer on the AWS Generative AI Innovation Heart, the place he works on mannequin customization and optimization for LLMs. He additionally builds instruments to assist his group deal with numerous features of the LLM improvement life cycle—together with fine-tuning, benchmarking, and load-testing—that accelerating the adoption of numerous use instances for AWS prospects. He holds an M.S. diploma in Pc Science from UC Davis.
 Hannah Marlowe is a Senior Supervisor of Mannequin Customization on the AWS Generative AI Innovation Heart. Her group makes a speciality of serving to prospects develop differentiating Generative AI options utilizing their distinctive and proprietary knowledge to attain key enterprise outcomes. She holds a Ph.D in Physics from the College of Iowa, with a concentrate on astronomical X-ray evaluation and instrumentation improvement. Outdoors of labor, she will be discovered mountain climbing, mountain biking, and snowboarding across the mountains in Colorado.
Hannah Marlowe is a Senior Supervisor of Mannequin Customization on the AWS Generative AI Innovation Heart. Her group makes a speciality of serving to prospects develop differentiating Generative AI options utilizing their distinctive and proprietary knowledge to attain key enterprise outcomes. She holds a Ph.D in Physics from the College of Iowa, with a concentrate on astronomical X-ray evaluation and instrumentation improvement. Outdoors of labor, she will be discovered mountain climbing, mountain biking, and snowboarding across the mountains in Colorado.


{kind=link}