Massive language fashions (LLMs) are very giant deep-learning fashions which might be pre-trained on huge quantities of information. LLMs are extremely versatile. One mannequin can carry out utterly completely different duties reminiscent of answering questions, summarizing paperwork, translating languages, and finishing sentences. LLMs have the potential to revolutionize content material creation and the best way folks use engines like google and digital assistants. Retrieval Augmented Era (RAG) is the method of optimizing the output of an LLM, so it references an authoritative information base exterior of its coaching knowledge sources earlier than producing a response. Whereas LLMs are educated on huge volumes of information and use billions of parameters to generate unique output, RAG extends the already highly effective capabilities of LLMs to particular domains or a corporation’s inner information base—with out having to retrain the LLMs. RAG is a quick and cost-effective method to enhance LLM output in order that it stays related, correct, and helpful in a selected context. RAG introduces an data retrieval part that makes use of the consumer enter to first pull data from a brand new knowledge supply. This new knowledge from exterior of the LLM’s unique coaching knowledge set known as exterior knowledge. The information would possibly exist in varied codecs reminiscent of recordsdata, database data, or long-form textual content. An AI method known as embedding language fashions converts this exterior knowledge into numerical representations and shops it in a vector database. This course of creates a information library that generative AI fashions can perceive.
RAG introduces extra knowledge engineering necessities:
- Scalable retrieval indexes should ingest large textual content corpora overlaying requisite information domains.
- Knowledge should be preprocessed to allow semantic search throughout inference. This consists of normalization, vectorization, and index optimization.
- These indexes repeatedly accumulate paperwork. Knowledge pipelines should seamlessly combine new knowledge at scale.
- Numerous knowledge amplifies the necessity for customizable cleansing and transformation logic to deal with the quirks of various sources.
On this submit, we’ll discover constructing a reusable RAG knowledge pipeline on LangChain—an open supply framework for constructing purposes primarily based on LLMs—and integrating it with AWS Glue and Amazon OpenSearch Serverless. The top answer is a reference structure for scalable RAG indexing and deployment. We offer pattern notebooks overlaying ingestion, transformation, vectorization, and index administration, enabling groups to eat disparate knowledge into high-performing RAG purposes.
Knowledge preprocessing for RAG
Knowledge pre-processing is essential for accountable retrieval out of your exterior knowledge with RAG. Clear, high-quality knowledge results in extra correct outcomes with RAG, whereas privateness and ethics issues necessitate cautious knowledge filtering. This lays the muse for LLMs with RAG to achieve their full potential in downstream purposes.
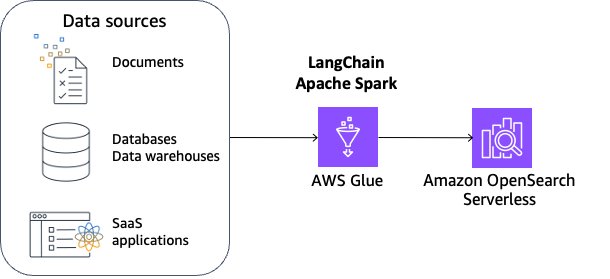
To facilitate efficient retrieval from exterior knowledge, a typical apply is to first clear up and sanitize the paperwork. You need to use Amazon Comprehend or AWS Glue delicate knowledge detection functionality to determine delicate knowledge after which use Spark to scrub up and sanitize the information. The subsequent step is to separate the paperwork into manageable chunks. The chunks are then transformed to embeddings and written to a vector index, whereas sustaining a mapping to the unique doc. This course of is proven within the determine that follows. These embeddings are used to find out semantic similarity between queries and textual content from the information sources

Resolution overview
On this answer, we use LangChain built-in with AWS Glue for Apache Spark and Amazon OpenSearch Serverless. To make this answer scalable and customizable, we use Apache Spark’s distributed capabilities and PySpark’s versatile scripting capabilities. We use OpenSearch Serverless as a pattern vector retailer and use the Llama 3.1 mannequin.

The advantages of this answer are:
- You possibly can flexibly obtain knowledge cleansing, sanitizing, and knowledge high quality administration along with chunking and embedding.
- You possibly can construct and handle an incremental knowledge pipeline to replace embeddings on Vectorstore at scale.
- You possibly can select all kinds of embedding fashions.
- You possibly can select all kinds of information sources together with databases, knowledge warehouses, and SaaS purposes supported in AWS Glue.
This answer covers the next areas:
- Processing unstructured knowledge reminiscent of HTML, Markdown, and textual content recordsdata utilizing Apache Spark. This consists of distributed knowledge cleansing, sanitizing, chunking, and embedding vectors for downstream consumption.
- Bringing all of it collectively right into a Spark pipeline that incrementally processes sources and publishes vectors to an OpenSearch Serverless
- Querying the listed content material utilizing the LLM mannequin of your alternative to supply pure language solutions.
Conditions
To proceed this tutorial, you could create the next AWS sources upfront:
- An Amazon Easy Storage Service (Amazon S3) bucket for storing knowledge
- An AWS Identification and Entry Administration (IAM) function on your AWS Glue pocket book as instructed in Arrange IAM permissions for AWS Glue Studio. It requires IAM permission for OpenSearch Service Serverless. Right here’s an instance coverage:
Full the next steps to launch an AWS Glue Studio pocket book:
- Obtain the Jupyter Pocket book file.
- On the AWS Glue console, selectNotebooks within the navigation pane.
- Below Create job, choose Pocket book.
- For Choices, select Add Pocket book.
- Select Create pocket book. The pocket book will begin up in a minute.

- Run the primary two cells to configure an AWS Glue interactive session.

Now you might have configured the required settings on your AWS Glue pocket book.
Vector retailer setup
First, create a vector retailer. A vector retailer supplies environment friendly vector similarity search by offering specialised indexes. RAG enhances LLMs with an exterior information base that’s usually constructed utilizing a vector database hydrated with vector-encoded information articles.
On this instance, you’ll use Amazon OpenSearch Serverless for its simplicity and scalability to assist a vector search at low latency and as much as billions of vectors. Study extra in Amazon OpenSearch Service’s vector database capabilities defined.
Full the next steps to arrange OpenSearch Serverless:
- For the cell underneath Vectorestore Setup, change
together with your IAM function Amazon Useful resource Identify (ARN), change together with your AWS Area, and run the cell. - Run the following cell to create the OpenSearch Serverless assortment, safety insurance policies, and entry insurance policies.

You may have provisioned OpenSearch Serverless efficiently. Now you’re able to inject paperwork into the vector retailer.
Doc preparation
On this instance, you’ll use a pattern HTML file because the HTML enter. It’s an article with specialised content material that LLMs can’t reply with out utilizing RAG.
- Run the cell underneath Pattern doc obtain to obtain the HTML file, create a brand new S3 bucket, and add the HTML file to the bucket.

- Run the cell underneath Doc preparation. It masses the HTML file into Spark DataFrame df_html.

- Run the 2 cells underneath Parse and clear up HTMLto outline capabilities
parse_htmlandformat_md. We use Lovely Soup to parse HTML, and convert it to Markdown utilizing markdownify with a view to use MarkdownTextSplitter for chunking. These capabilities shall be used inside a Spark Python user-defined operate (UDF) in later cells.

- Run the cell underneath Chunking HTML. The instance makes use of LangChain’s
MarkdownTextSplitterto separate the textual content alongside markdown-formatted headings into manageable chunks. Adjusting chunk dimension and overlap is essential to assist forestall the interruption of contextual which means, which might have an effect on the accuracy of subsequent vector retailer searches. The instance makes use of a bit dimension of 1,000 and a bit overlap of 100 to protect data continuity, however these settings might be fine-tuned to swimsuit completely different use instances.

- Run the three cells underneath Embedding. The primary two cells configure LLMs and deploy them by Amazon SageMaker Within the third cell, the operate
process_batchinjectsthe paperwork into the vector retailer by OpenSearch implementation inside LangChain, which inputs the embeddings mannequin and the paperwork to create all the vector retailer.



- Run the 2 cells underneath Pre-process HTML doc. The primary cell defines the Spark UDF, and the second cell triggers the Spark motion to run the UDF per report containing all the HTML content material.

You may have efficiently ingested an embedding into the OpenSearch Serverless assortment.
Query answering
On this part, we’re going to show the question-answering functionality utilizing the embedding ingested within the earlier part.
- Run the 2 cells underneath Query Answering to create the
OpenSearchVectorSearchshopper, the LLM utilizing Llama 3.1, and outline RetrievalQA the place you may customise how the paperwork fetched ought to be added to the immediate utilizing thechain_typeOptionally, you may select different basis fashions (FMs). For such instances, consult with the mannequin card to regulate the chunking size.


- Run the following cell to do a similarity search utilizing the question “What’s Activity Decomposition?” towards the vector retailer offering essentially the most related data. It takes a number of seconds to make paperwork accessible within the index. When you get an empty output within the subsequent cell, wait 1-3 minutes and retry.

Now that you’ve got the related paperwork, it’s time to make use of the LLM to generate a solution primarily based on the embeddings.
- Run the following cell to invoke the LLM to generate a solution primarily based on the embeddings.

As you anticipate, the LLM answered with an in depth rationalization about job decomposition. For manufacturing workloads, balancing latency and value effectivity is essential in semantic searches by vector shops. It’s vital to pick essentially the most appropriate k-NN algorithm and parameters on your particular wants, as detailed on this submit. Moreover, think about using product quantization (PQ) to cut back the dimensionality of embeddings saved within the vector database. This method might be advantageous for latency-sensitive duties, although it’d contain some trade-offs in accuracy. For extra particulars, see Select the k-NN algorithm on your billion-scale use case with OpenSearch.
Clear up
Now to the ultimate step, cleansing up the sources:
- Run the cell underneath Clear up to delete S3, OpenSearch Serverless, and SageMaker sources.

- Delete the AWS Glue pocket book job.
Conclusion
This submit explored a reusable RAG knowledge pipeline utilizing LangChain, AWS Glue, Apache Spark, Amazon SageMaker JumpStart, and Amazon OpenSearch Serverless. The answer supplies a reference structure for ingesting, reworking, vectorizing, and managing indexes for RAG at scale through the use of Apache Spark’s distributed capabilities and PySpark’s versatile scripting capabilities. This lets you preprocess your exterior knowledge within the phases together with cleansing, sanitization, chunking paperwork, producing vector embeddings for every chunk, and loading right into a vector retailer.
Concerning the Authors
 Noritaka Sekiyama is a Principal Massive Knowledge Architect on the AWS Glue crew. He’s answerable for constructing software program artifacts to assist clients. In his spare time, he enjoys biking along with his street bike.
Noritaka Sekiyama is a Principal Massive Knowledge Architect on the AWS Glue crew. He’s answerable for constructing software program artifacts to assist clients. In his spare time, he enjoys biking along with his street bike.
 Akito Takeki is a Cloud Help Engineer at Amazon Net Companies. He focuses on Amazon Bedrock and Amazon SageMaker. In his spare time, he enjoys travelling and spending time along with his household.
Akito Takeki is a Cloud Help Engineer at Amazon Net Companies. He focuses on Amazon Bedrock and Amazon SageMaker. In his spare time, he enjoys travelling and spending time along with his household.
 Ray Wang is a Senior Options Architect at Amazon Net Companies. Ray is devoted to constructing trendy options on the Cloud, particularly in NoSQL, huge knowledge, and machine studying. As a hungry go-getter, he handed all 12 AWS certificates to make his technical discipline not solely deep however huge. He likes to learn and watch sci-fi films in his spare time.
Ray Wang is a Senior Options Architect at Amazon Net Companies. Ray is devoted to constructing trendy options on the Cloud, particularly in NoSQL, huge knowledge, and machine studying. As a hungry go-getter, he handed all 12 AWS certificates to make his technical discipline not solely deep however huge. He likes to learn and watch sci-fi films in his spare time.
 Vishal Kajjam is a Software program Improvement Engineer on the AWS Glue crew. He’s obsessed with distributed computing and utilizing ML/AI for designing and constructing end-to-end options to handle clients’ Knowledge Integration wants. In his spare time, he enjoys spending time with household and pals.
Vishal Kajjam is a Software program Improvement Engineer on the AWS Glue crew. He’s obsessed with distributed computing and utilizing ML/AI for designing and constructing end-to-end options to handle clients’ Knowledge Integration wants. In his spare time, he enjoys spending time with household and pals.
 Savio Dsouza is a Software program Improvement Supervisor on the AWS Glue crew. His crew works on generative AI purposes for the Knowledge Integration area and distributed programs for effectively managing knowledge lakes on AWS and optimizing Apache Spark for efficiency and reliability.
Savio Dsouza is a Software program Improvement Supervisor on the AWS Glue crew. His crew works on generative AI purposes for the Knowledge Integration area and distributed programs for effectively managing knowledge lakes on AWS and optimizing Apache Spark for efficiency and reliability.
 Kinshuk Pahare is a Principal Product Supervisor on AWS Glue. He leads a crew of Product Managers who give attention to AWS Glue platform, developer expertise, knowledge processing engines, and generative AI. He had been with AWS for 4.5 years. Earlier than that he did product administration at Proofpoint and Cisco.
Kinshuk Pahare is a Principal Product Supervisor on AWS Glue. He leads a crew of Product Managers who give attention to AWS Glue platform, developer expertise, knowledge processing engines, and generative AI. He had been with AWS for 4.5 years. Earlier than that he did product administration at Proofpoint and Cisco.



{kind=link}