A deep dive into stochastic decoding with temperature, top_p, top_k, and min_p
18 hours in the past

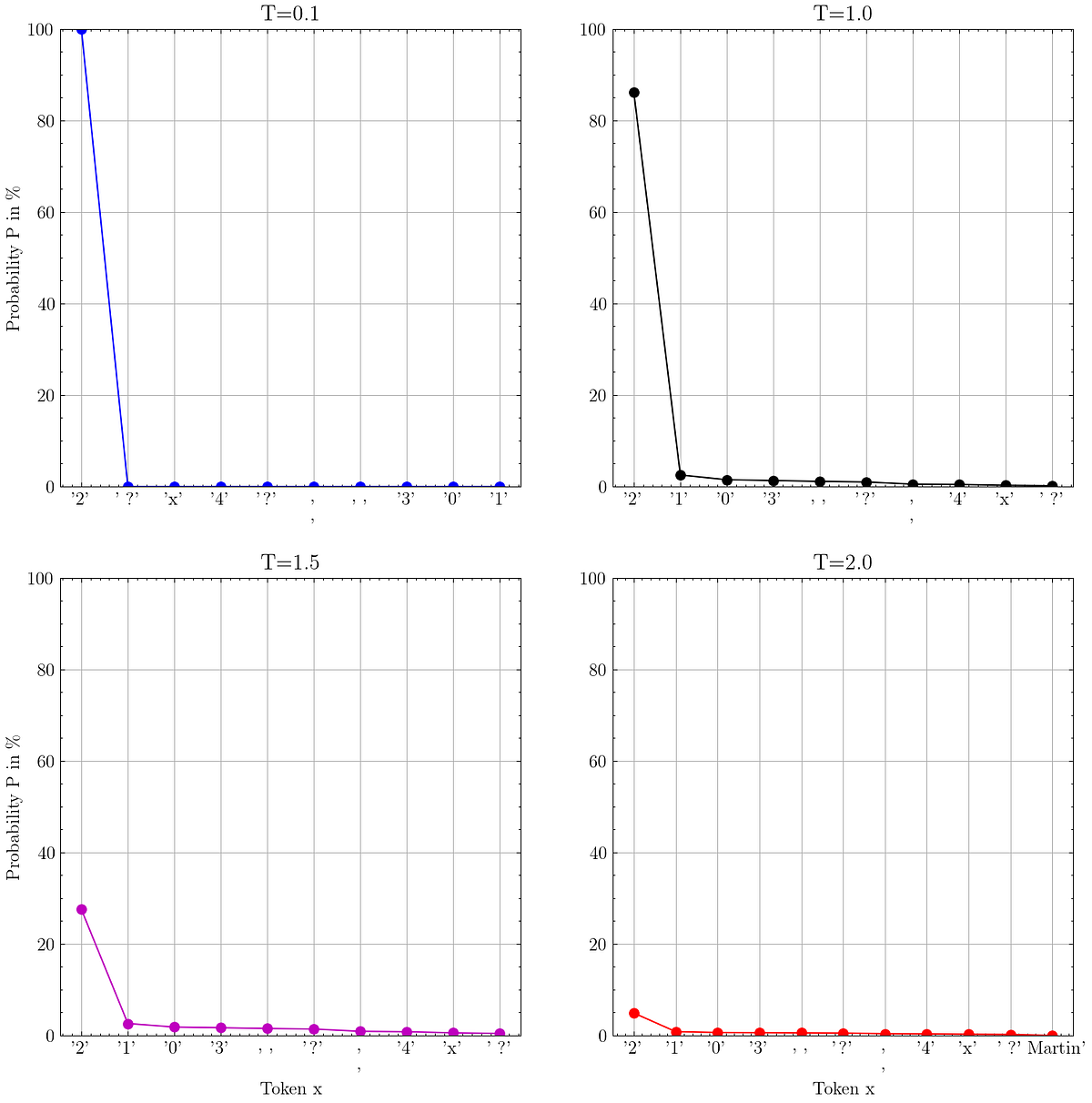
Once you ask a Massive Language Mannequin (LLM) a query, the mannequin outputs a likelihood for each potential token in its vocabulary.
After sampling a token from this likelihood distribution, we are able to append the chosen token to our enter immediate in order that the LLM can output the chances for the subsequent token.
This sampling course of might be managed by parameters such because the well-known temperature and top_p.
On this article, I’ll clarify and visualize the sampling methods that outline the output conduct of LLMs. By understanding what these parameters do and setting them based on our use case, we are able to enhance the output generated by LLMs.
For this text, I’ll use VLLM because the inference engine and Microsoft’s new Phi-3.5-mini-instruct mannequin with AWQ quantization. To run this mannequin regionally, I’m utilizing my laptop computer’s NVIDIA GeForce RTX 2060 GPU.
Desk Of Contents
· Understanding Sampling With Logprobs
∘ LLM Decoding Idea
∘ Retrieving Logprobs With the OpenAI Python SDK
· Grasping Decoding
· Temperature
· Prime-k Sampling
· Prime-p Sampling
· Combining Prime-p…



{kind=link}