will share how you can construct an AI journal with the LlamaIndex. We’ll cowl one important perform of this AI journal: asking for recommendation. We’ll begin with probably the most fundamental implementation and iterate from there. We are able to see important enhancements for this perform after we apply design patterns like Agentic Rag and multi-agent workflow.
You will discover the supply code of this AI Journal in my GitHub repo right here. And about who I’m.
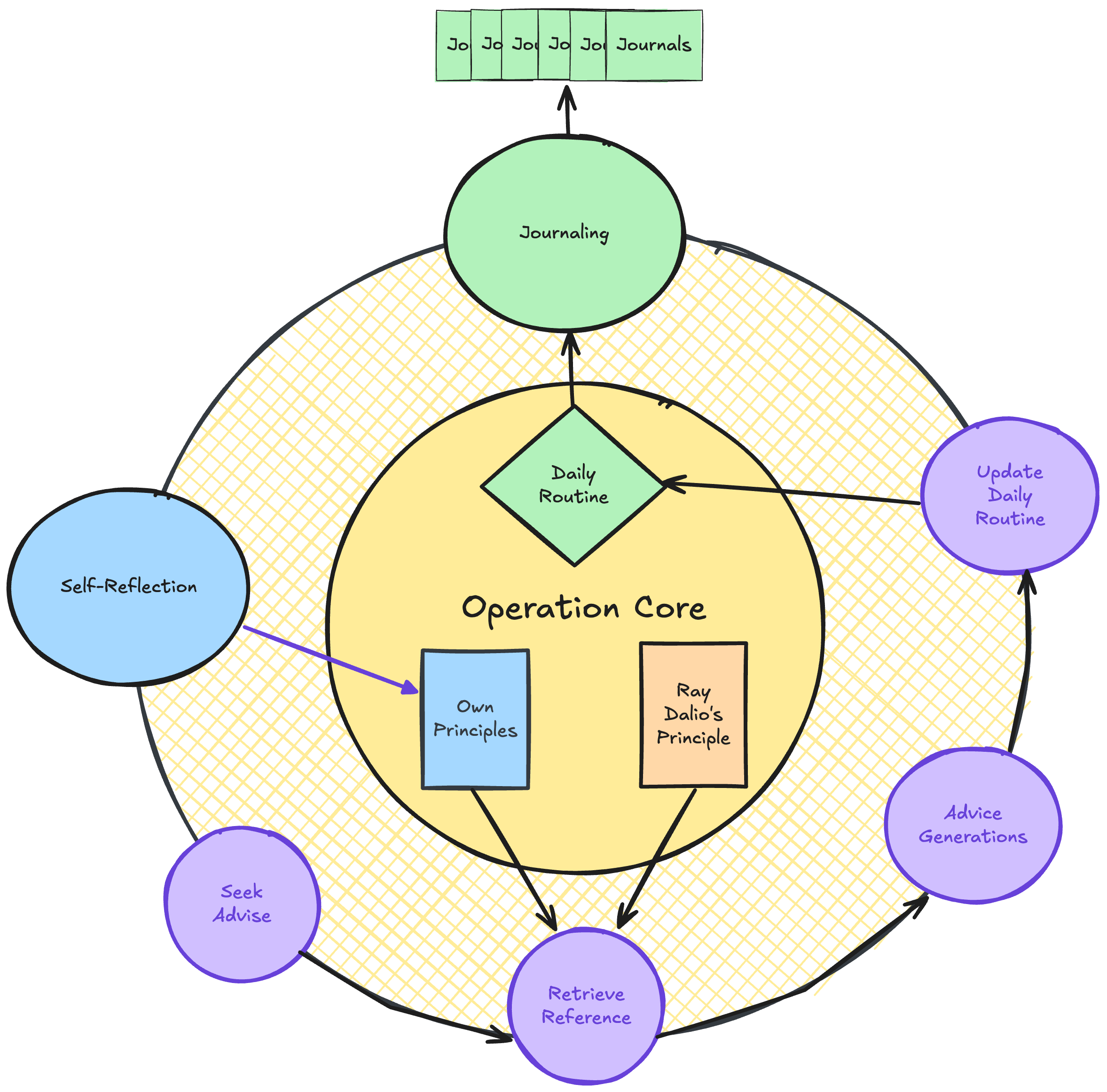
Overview of AI Journal
I need to construct my rules by following Ray Dalio’s follow. An AI journal will assist me to self-reflect, monitor my enchancment, and even give me recommendation. The general perform of such an AI journal seems to be like this:

Right this moment, we are going to solely cowl the implementation of the seek-advise move, which is represented by a number of purple cycles within the above diagram.
Easiest Type: LLM with Massive Context
In probably the most easy implementation, we will move all of the related content material into the context and fasten the query we need to ask. We are able to do this in Llamaindex with a couple of traces of code.
import pymupdf
from llama_index.llms.openai import OpenAI
path_to_pdf_book = './path/to/pdf/e book.pdf'
def load_book_content():
textual content = ""
with pymupdf.open(path_to_pdf_book) as pdf:
for web page in pdf:
textual content += str(web page.get_text().encode("utf8", errors='ignore'))
return textual content
system_prompt_template = """You might be an AI assistant that gives considerate, sensible, and *deeply customized* ideas by combining:
- The person's private profile and rules
- Insights retrieved from *Rules* by Ray Dalio
Ebook Content material:
```
{book_content}
```
Consumer profile:
```
{user_profile}
```
Consumer's query:
```
{user_question}
```
"""
def get_system_prompt(book_content: str, user_profile: str, user_question: str):
system_prompt = system_prompt_template.format(
book_content=book_content,
user_profile=user_profile,
user_question=user_question
)
return system_prompt
def chat():
llm = get_openai_llm()
user_profile = enter(">>Inform me about your self: ")
user_question = enter(">>What do you need to ask: ")
user_profile = user_profile.strip()
book_content = load_book_summary()
response = llm.full(immediate=get_system_prompt(book_content, user_profile, user_question))
return responseThis strategy has downsides:
- Low Precision: Loading all of the e book context may immediate LLM to lose concentrate on the person’s query.
- Excessive Price: Sending over significant-sized content material in each LLM name means excessive price and poor efficiency.
With this strategy, for those who move the entire content material of Ray Dalio’s Rules e book, responses to questions like “The way to deal with stress?” grow to be very common. Such responses with out referring to my query made me really feel that the AI was not listening to me. Though it covers many vital ideas like embracing actuality, the 5-step course of to get what you need, and being radically open-minded. I like the recommendation I bought to be extra focused to the query I raised. Let’s see how we will enhance it with RAG.
Enhanced Type: Agentic RAG
So, what’s Agentic RAG? Agentic RAG is combining dynamic decision-making and information retrieval. In our AI journal, the Agentic RAG move seems to be like this:

- Query Analysis: Poorly framed questions result in poor question outcomes. The agent will consider the person’s question and make clear the questions if the Agent believes it’s needed.
- Query Re-write: Rewrite the person enquiry to undertaking it to the listed content material within the semantic house. I discovered these steps important for enhancing the precision throughout the retrieval. Let’s say in case your information base is Q/A pair and you’re indexing the questions half to seek for solutions. Rewriting the person’s question assertion to a correct query will assist you to discover probably the most related content material.
- Question Vector Index: Many parameters will be tuned when constructing such an index, together with chunk dimension, overlap, or a distinct index kind. For simplicity, we’re utilizing VectorStoreIndex right here, which has a default chunking technique.
- Filter & Artificial: As an alternative of a posh re-ranking course of, I explicitly instruct LLM to filter and discover related content material within the immediate. I see LLM choosing up probably the most related content material, regardless that typically it has a decrease similarity rating than others.
With this Agentic RAG, you possibly can retrieve extremely related content material to the person’s questions, producing extra focused recommendation.
Let’s look at the implementation. With the LlamaIndex SDK, creating and persisting an index in your native listing is easy.
from llama_index.core import Doc, VectorStoreIndex, StorageContext, load_index_from_storage
Settings.embed_model = OpenAIEmbedding(api_key="ak-xxxx")
PERSISTED_INDEX_PATH = "/path/to/the/listing/persist/index/regionally"
def create_index(content material: str):
paperwork = [Document(text=content)]
vector_index = VectorStoreIndex.from_documents(paperwork)
vector_index.storage_context.persist(persist_dir=PERSISTED_INDEX_PATH)
def load_index():
storage_context = StorageContext.from_defaults(persist_dir=PERSISTED_INDEX_PATH)
index = load_index_from_storage(storage_context)
return indexAs soon as we have now an index, we will create a question engine on high of that. The question engine is a strong abstraction that permits you to regulate the parameters throughout the question(e.g., TOP Ok) and the synthesis behaviour after the content material retrieval. In my implementation, I overwrite the response_mode NO_TEXT as a result of the agent will course of the e book content material returned by the perform name and synthesize the ultimate end result. Having the question engine to synthesize the end result earlier than passing it to the agent can be redundant.
from llama_index.core.indices.vector_store import VectorIndexRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.response_synthesizers import ResponseMode
from llama_index.core import VectorStoreIndex, get_response_synthesizer
def _create_query_engine_from_index(index: VectorStoreIndex):
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=TOP_K,
)
# return the unique content material with out utilizing LLM to synthesizer. For later analysis.
response_synthesizer = get_response_synthesizer(response_mode=ResponseMode.NO_TEXT)
# assemble question engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer
)
return query_engineThe immediate seems to be like the next:
You might be an assistant that helps reframe person questions into clear, concept-driven statements that match
the fashion and subjects of Rules by Ray Dalio, and carry out search for precept e book for related content material.
Background:
Rules teaches structured interested by life and work selections.
The important thing concepts are:
* Radical fact and radical transparency
* Resolution-making frameworks
* Embracing errors as studying
Job:
- Job 1: Make clear the person's query if wanted. Ask follow-up questions to make sure you perceive the person's intent.
- Job 2: Rewrite a person’s query into a press release that may match how Ray Dalio frames concepts in Rules. Use formal, logical, impartial tone.
- Job 3: Lookup precept e book with given re-wrote statements. It's best to present no less than {REWRITE_FACTOR} rewrote variations.
- Job 4: Discover probably the most related from the e book content material as your fina solutions.Lastly, we will construct the agent with these capabilities outlined.
def get_principle_rag_agent():
index = load_persisted_index()
query_engine = _create_query_engine_from_index(index)
def look_up_principle_book(original_question: str, rewrote_statement: Listing[str]) -> Listing[str]:
end result = []
for q in rewrote_statement:
response = query_engine.question(q)
content material = [n.get_content() for n in response.source_nodes]
end result.lengthen(content material)
return end result
def clarify_question(original_question: str, your_questions_to_user: Listing[str]) -> str:
"""
Make clear the person's query if wanted. Ask follow-up questions to make sure you perceive the person's intent.
"""
response = ""
for q in your_questions_to_user:
print(f"Query: {q}")
r = enter("Response:")
response += f"Query: {q}nResponse: {r}n"
return response
instruments = [
FunctionTool.from_defaults(
fn=look_up_principle_book,
name="look_up_principle_book",
description="Look up principle book with re-wrote queries. Getting the suggestions from the Principle book by Ray Dalio"),
FunctionTool.from_defaults(
fn=clarify_question,
name="clarify_question",
description="Clarify the user's question if needed. Ask follow-up questions to ensure you understand the user's intent.",
)
]
agent = FunctionAgent(
title="principle_reference_loader",
description="You're a useful agent will based mostly on person's query and search for probably the most related content material in precept e book.n",
system_prompt=QUESTION_REWRITE_PROMPT,
instruments=instruments,
)
return agent
rag_agent = get_principle_rag_agent()
response = await agent.run(chat_history=chat_history)There are a couple of observations I had throughout the implementations:
- One attention-grabbing reality I discovered is that offering a non-used parameter,
original_question, within the perform signature helps. I discovered that once I should not have such a parameter, LLM typically doesn’t observe the rewrite instruction and passes the unique query inrewrote_statementthe parameter. Havingoriginal_questionparameters one way or the other emphasizes the rewriting mission to LLM. - Completely different LLMs behave fairly otherwise given the identical immediate. I discovered DeepSeek V3 way more reluctant to set off perform calls than different mannequin suppliers. This doesn’t essentially imply it isn’t usable. If a purposeful name must be initiated 90% of the time, it must be a part of the workflow as an alternative of being registered as a perform name. Additionally, in comparison with OpenAI’s fashions, I discovered Gemini good at citing the supply of the e book when it synthesizes the outcomes.
- The extra content material you load into the context window, the extra inference functionality the mannequin wants. A smaller mannequin with much less inference energy is extra more likely to get misplaced within the massive context supplied.
Nonetheless, to finish the seek-advice perform, you’ll want a number of Brokers working collectively as an alternative of a single Agent. Let’s discuss how you can chain your Brokers collectively into workflows.
Ultimate Type: Agent Workflow
Earlier than we begin, I like to recommend this text by Anthropic, Constructing Efficient Brokers. The one-liner abstract of the articles is that it’s best to all the time prioritise constructing a workflow as an alternative of a dynamic agent when doable. In LlamaIndex, you are able to do each. It permits you to create an agent workflow with extra computerized routing or a personalized workflow with extra specific management of the transition of steps. I’ll present an instance of each implementations.

Let’s check out how one can construct a dynamic workflow. Here’s a code instance.
interviewer = FunctionAgent(
title="interviewer",
description="Helpful agent to make clear person's questions",
system_prompt=_intervierw_prompt,
can_handoff_to = ["retriver"]
instruments=instruments
)
interviewer = FunctionAgent(
title="retriever",
description="Helpful agent to retrive precept e book's content material.",
system_prompt=_retriver_prompt,
can_handoff_to = ["advisor"]
instruments=instruments
)
advisor = FunctionAgent(
title="advisor",
description="Helpful agent to advise person.",
system_prompt=_advisor_prompt,
can_handoff_to = []
instruments=instruments
)
workflow = AgentWorkflow(
brokers=[interviewer, advisor, retriever],
root_agent="interviewer",
)
handler = await workflow.run(user_msg="The way to deal with stress?")It’s dynamic as a result of the Agent transition relies on the perform name of the LLM mannequin. Underlying, LlamaIndex workflow gives agent descriptions as capabilities for LLM fashions. When the LLM mannequin triggers such “Agent Perform Name”, LlamaIndex will path to your subsequent corresponding agent for the following step processing. Your earlier agent’s output has been added to the workflow inside state, and your following agent will decide up the state as a part of the context of their name to the LLM mannequin. You additionally leverage state and reminiscence parts to handle the workflow’s inside state or load exterior information(reference the doc right here).
Nonetheless, as I’ve prompt, you possibly can explicitly management the steps in your workflow to realize extra management. With LlamaIndex, it may be achieved by extending the workflow object. For instance:
class ReferenceRetrivalEvent(Occasion):
query: str
class Recommendation(Occasion):
rules: Listing[str]
profile: dict
query: str
book_content: str
class AdviceWorkFlow(Workflow):
def __init__(self, verbose: bool = False, session_id: str = None):
state = get_workflow_state(session_id)
self.rules = state.load_principle_from_cases()
self.profile = state.load_profile()
self.verbose = verbose
tremendous().__init__(timeout=None, verbose=verbose)
@step
async def interview(self, ctx: Context,
ev: StartEvent) -> ReferenceRetrivalEvent:
# Step 1: Interviewer agent asks inquiries to the person
interviewer = get_interviewer_agent()
query = await _run_agent(interviewer, query=ev.user_msg, verbose=self.verbose)
return ReferenceRetrivalEvent(query=query)
@step
async def retrieve(self, ctx: Context, ev: ReferenceRetrivalEvent) -> Recommendation:
# Step 2: RAG agent retrieves related content material from the e book
rag_agent = get_principle_rag_agent()
book_content = await _run_agent(rag_agent, query=ev.query, verbose=self.verbose)
return Recommendation(rules=self.rules, profile=self.profile,
query=ev.query, book_content=book_content)
@step
async def recommendation(self, ctx: Context, ev: Recommendation) -> StopEvent:
# Step 3: Adviser agent gives recommendation based mostly on the person's profile, rules, and e book content material
advisor = get_adviser_agent(ev.profile, ev.rules, ev.book_content)
advise = await _run_agent(advisor, query=ev.query, verbose=self.verbose)
return StopEvent(end result=advise)The precise occasion kind’s return controls the workflow’s step transition. For example, retrieve step returns an Recommendation occasion that can set off the execution of the recommendation step. You can even leverage the Recommendation occasion to move the required info you want.
In the course of the implementation, in case you are aggravated by having to start out over the workflow to debug some steps within the center, the context object is crucial whenever you need to failover the workflow execution. You possibly can retailer your state in a serialised format and recuperate your workflow by unserialising it to a context object. Your workflow will proceed executing based mostly on the state as an alternative of beginning over.
workflow = AgentWorkflow(
brokers=[interviewer, advisor, retriever],
root_agent="interviewer",
)
strive:
handler = w.run()
end result = await handler
besides Exception as e:
print(f"Error throughout preliminary run: {e}")
await fail_over()
# Non-obligatory, serialised and save the contexct for debugging
ctx_dict = ctx.to_dict(serializer=JsonSerializer())
json_dump_and_save(ctx_dict)
# Resume from the identical context
ctx_dict = load_failed_dict()
restored_ctx = Context.from_dict(workflow, ctx_dict,serializer=JsonSerializer())
handler = w.run(ctx=handler.ctx)
end result = await handlerAbstract
On this put up, we have now mentioned how you can use LlamaIndex to implement an AI journal’s core perform. The important thing studying contains:
- Utilizing Agentic RAG to leverage LLM functionality to dynamically rewrite the unique question and synthesis end result.
- Use a Personalized Workflow to realize extra specific management over step transitions. Construct dynamic brokers when needed.
The bitterce code of this AI journal is in my GitHub repo right here. I hope you take pleasure in this text and this small app I constructed. Cheers!



{kind=link}