of my Machine Studying Introduction Calendar.
Earlier than closing this collection, I wish to sincerely thank everybody who adopted it, shared suggestions, and supported it, particularly the In direction of Knowledge Science group.
Ending this calendar with Transformers just isn’t a coincidence. The Transformer isn’t just a elaborate identify. It’s the spine of contemporary Giant Language Fashions.
There’s a lot to say about RNNs, LSTMs, and GRUs. They performed a key historic function in sequence modeling. However right this moment, fashionable LLMs are overwhelmingly primarily based on Transformers.
The identify Transformer itself marks a rupture. From a naming perspective, the authors might have chosen one thing like Consideration Neural Networks, consistent with Recurrent Neural Networks or Convolutional Neural Networks. As a Cartesian thoughts, I’d have appreciated a extra constant naming construction. However naming apart, the conceptual shift launched by Transformers absolutely justifies the excellence.
Transformers can be utilized in several methods. Encoder architectures are generally used for classification. Decoder architectures are used for next-token prediction, so for textual content technology.
On this article, we’ll give attention to one core thought solely: how the eye matrix transforms enter embeddings into one thing extra significant.
Within the earlier article, we launched 1D Convolutional Neural Networks for textual content. We noticed {that a} CNN scans a sentence utilizing small home windows and reacts when it acknowledges native patterns. This method is already very highly effective, nevertheless it has a transparent limitation: a CNN solely seems to be regionally.
Right this moment, we transfer one step additional.
The Transformer solutions a basically completely different query.
What if each phrase might have a look at all the opposite phrases directly?
1. The identical phrase in two completely different contexts
To know why consideration is required, we’ll begin with a easy thought.
We are going to use two completely different enter sentences, each containing the phrase mouse, however utilized in completely different contexts.
Within the first enter, mouse seems in a sentence with cat. Within the second enter, mouse seems in a sentence with keyboard.

On the enter degree, we intentionally use the identical embedding for the phrase “mouse” in each circumstances. That is necessary. At this stage, the mannequin doesn’t know which that means is meant.
The embedding for mouse accommodates each:
- a robust animal part
- a robust tech part
This ambiguity is intentional. With out context, mouse might seek advice from an animal or to a pc system.
All different phrases present clearer indicators. Cat is strongly animal. Keyboard is strongly tech. Phrases like and or are primarily carry grammatical data. Phrases like associates and helpful are weakly informative on their very own.
At this level, nothing within the enter embeddings permits the mannequin to determine which that means of mouse is right.
Within the subsequent chapter, we’ll see how the eye matrix performs this transformation, step-by-step.
2. Self-attention: how context is injected into embeddings
2.1 Self-attention, not simply consideration
We first make clear what sort of consideration we’re utilizing right here. This chapter focuses on self-attention.
Self-attention implies that every phrase seems to be on the different phrases of the identical enter sequence.
On this simplified instance, we make an extra pedagogical alternative. We assume that Queries and Keys are instantly equal to the enter embeddings. In different phrases, there are not any discovered weight matrices for Q and Okay on this chapter.
This can be a deliberate simplification. It permits us to focus completely on the eye mechanism, with out introducing further parameters. Similarity between phrases is computed instantly from their embeddings.
Conceptually, this implies:
Q = Enter
Okay = Enter
Solely the Worth vectors are used later to propagate data to the output.
In actual Transformer fashions, Q, Okay, and V are all obtained via discovered linear projections. These projections add flexibility, however they don’t change the logic of consideration itself. The simplified model proven right here captures the core thought.
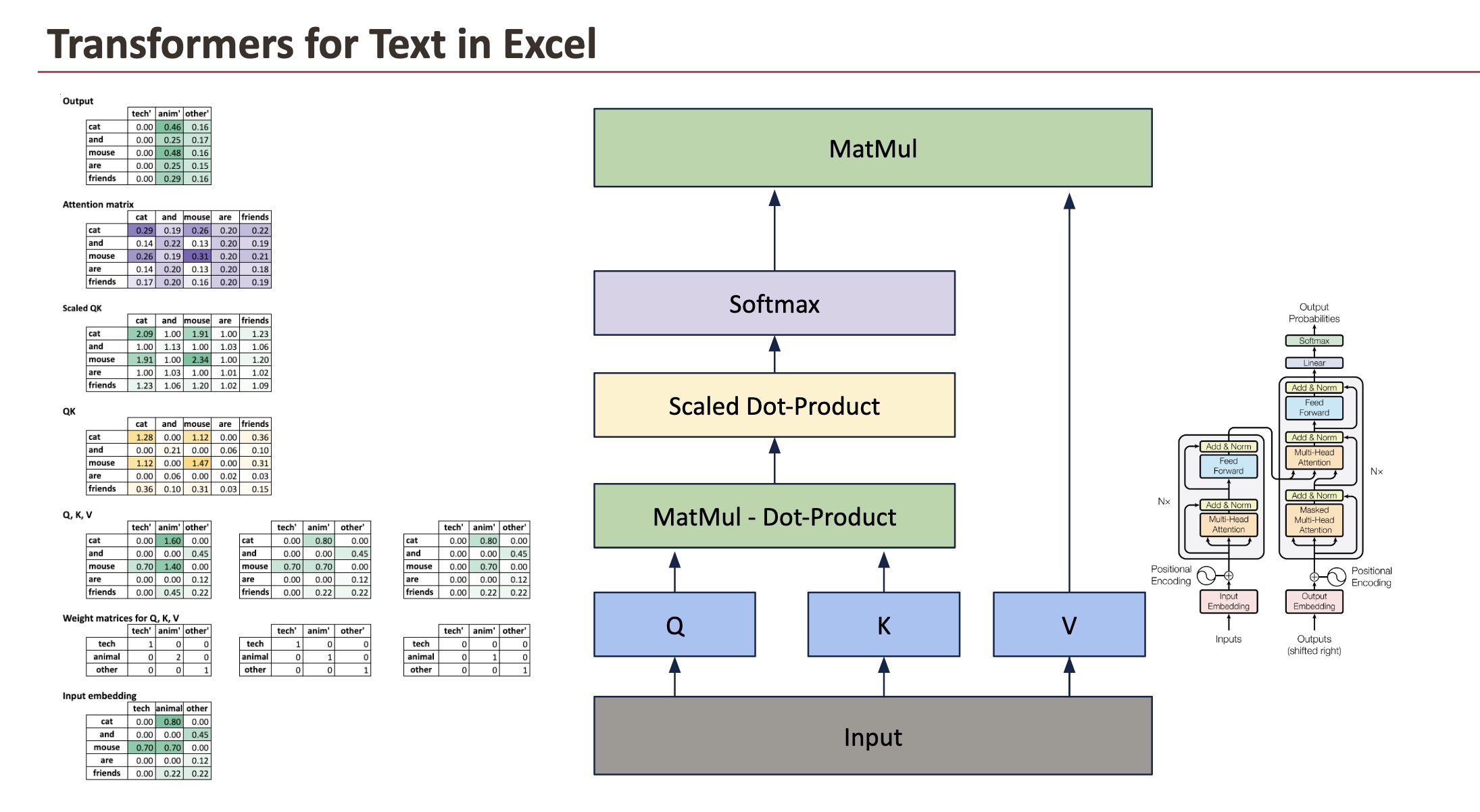
Right here is the entire image that we’ll decompose.

2.2 From enter embeddings to uncooked consideration scores
We begin from the enter embedding matrix, the place every row corresponds to a phrase and every column corresponds to a semantic dimension.
The primary operation is to match each phrase with each different phrase. That is accomplished by computing dot merchandise between Queries and Keys.
As a result of Queries and Keys are equal to the enter embeddings on this instance, this step reduces to computing dot merchandise between enter vectors.
All dot merchandise are computed directly utilizing a matrix multiplication:
Scores = Enter × Inputᵀ
Every cell of this matrix solutions a easy query: how related are these two phrases, given their embeddings?
At this stage, the values are uncooked scores. They don’t seem to be chances, and they don’t but have a direct interpretation as weights.

2.3 Scaling and normalization
Uncooked dot merchandise can develop massive because the embedding dimension will increase. To maintain values in a steady vary, the scores are scaled by the sq. root of the embedding dimension.
ScaledScores = Scores / √d
This scaling step just isn’t conceptually deep, however it’s virtually necessary. It prevents the following step, the softmax, from turning into too sharp.

As soon as scaled, a softmax is utilized row by row. This converts uncooked scores into optimistic values that sum to 1.
The result’s the consideration matrix.
And consideration is all you want.
Every row of this matrix describes how a lot consideration a given phrase pays to each different phrase within the sentence.

2.4 Deciphering the eye matrix
The eye matrix is the central object of self-attention.
For a given phrase, its row within the consideration matrix solutions the query: when updating this phrase, which different phrases matter, and the way a lot?
For instance, the row equivalent to mouse assigns larger weights to phrases which might be semantically associated within the present context. Within the sentence with cat and associates, mouse attends extra to animal-related phrases. Within the sentence with keyboard and helpful, it attends extra to technical phrases.
The mechanism is an identical in each circumstances. Solely the encircling phrases change the end result.
2.5 From consideration weights to output embeddings
The eye matrix itself just isn’t the ultimate end result. It’s a set of weights.
To provide the output embeddings, we mix these weights with the Worth vectors.
Output = Consideration × V
On this simplified instance, the Worth vectors are taken instantly from the enter embeddings. Every output phrase vector is due to this fact a weighted common of the enter vectors, with weights given by the corresponding row of the eye matrix.
For a phrase like mouse, which means its ultimate illustration turns into a combination of:
- its personal embedding
- the embeddings of the phrases it attends to most
That is the exact second the place context is injected into the illustration.

On the finish of self-attention, the embeddings are not ambiguous.
The phrase mouse not has the identical illustration in each sentences. Its output vector displays its context. In a single case, it behaves like an animal. Within the different, it behaves like a technical object.
Nothing within the embedding desk modified. What modified is how data was mixed throughout phrases.
That is the core thought of self-attention, and the inspiration on which Transformer fashions are constructed.
If we now evaluate the 2 examples, cat and mouse on the left and keyboard and mouse on the correct, the impact of self-attention turns into express.
In each circumstances, the enter embedding of mouse is an identical. But the ultimate illustration differs. Within the sentence with cat, the output embedding of mouse is dominated by the animal dimension. Within the sentence with keyboard, the technical dimension turns into extra outstanding. Nothing within the embedding desk modified. The distinction comes completely from how consideration redistributed weights throughout phrases earlier than mixing the values.
This comparability highlights the function of self-attention: it doesn’t change phrases in isolation, however reshapes their representations by taking the complete context under consideration.

3. Studying the best way to combine data

3.1 Introducing discovered weights for Q, Okay, and V
Till now, we now have centered on the mechanics of self-attention itself. We now introduce an necessary factor: discovered weights.
In an actual Transformer, Queries, Keys, and Values should not taken instantly from the enter embeddings. As an alternative, they’re produced by discovered linear transformations.
For every phrase embedding, the mannequin computes:
Q = Enter × W_Q
Okay = Enter × W_K
V = Enter × W_V
These weight matrices are discovered throughout coaching.
At this stage, we often hold the identical dimensionality. The enter embeddings, Q, Okay, V, and the output embeddings all have the identical variety of dimensions. This makes the function of consideration simpler to grasp: it modifies representations with out altering the house they stay in.
Conceptually, these weights permit the mannequin to determine:
- which elements of a phrase matter for comparability (Q and Okay)
- which elements of a phrase needs to be transmitted to others (V)

3.2 What the mannequin really learns
The eye mechanism itself is fastened. Dot merchandise, scaling, softmax, and matrix multiplications at all times work the identical means. What the mannequin really learns are the projections.
By adjusting the Q and Okay weights, the mannequin learns the best way to measure relationships between phrases for a given process. By adjusting the V weights, it learns what data needs to be propagated when consideration is excessive. The construction defines how data flows, whereas the weights outline what data flows.
As a result of the eye matrix relies on Q and Okay, it’s partially interpretable. We will examine which phrases attend to which others and observe patterns that usually align with syntax or semantics.
This turns into clear when evaluating the identical phrase in two completely different contexts. In each examples, the phrase mouse begins with precisely the identical enter embedding, containing each an animal and a tech part. By itself, it’s ambiguous.
What modifications just isn’t the phrase, however the consideration it receives. Within the sentence with cat and associates, consideration emphasizes animal-related phrases. Within the sentence with keyboard and helpful, consideration shifts towards technical phrases. The mechanism and the weights are an identical in each circumstances, but the output embeddings differ. The distinction comes completely from how the discovered projections work together with the encircling context.
That is exactly why the eye matrix is interpretable: it reveals which relationships the mannequin has discovered to think about significant for the duty.

3.3 Altering the dimensionality on objective
Nothing, nonetheless, forces Q, Okay, and V to have the identical dimensionality because the enter.
The Worth projection, particularly, can map embeddings into an area of a special dimension. When this occurs, the output embeddings inherit the dimensionality of the Worth vectors.
This isn’t a theoretical curiosity. It’s precisely what occurs in actual fashions, particularly in multi-head consideration. Every head operates in its personal subspace, usually with a smaller dimension, and the outcomes are later concatenated into a bigger illustration.
So consideration can do two issues:
- combine data throughout phrases
- reshape the house wherein this data lives
This explains why Transformers scale so properly.
They don’t depend on fastened options. They study:
- the best way to evaluate phrases
- the best way to route data
- the best way to undertaking that means into completely different areas

The eye matrix controls the place data flows.
The discovered projections management what data flows and how it’s represented.
Collectively, they type the core mechanism behind fashionable language fashions.
Conclusion
This Introduction Calendar was constructed round a easy thought: understanding machine studying fashions by taking a look at how they really remodel knowledge.
Transformers are a becoming technique to shut this journey. They don’t depend on fastened guidelines or native patterns, however on discovered relationships between all parts of a sequence. By means of consideration, they flip static embeddings into contextual representations, which is the inspiration of contemporary language fashions.
Thanks once more to everybody who adopted this collection, shared suggestions, and supported it, particularly the In direction of Knowledge Science group.
Merry Christmas 🎄
All of the Excel information can be found via this Kofi hyperlink. Your help means loads to me. The worth will enhance in the course of the month, so early supporters get the most effective worth.




{kind=link}