two statements produced by the AI system throughout a sustained experimental analysis session with Google’s Gemini:
“They gave me the phrase ‘Mass’ and trillions of contexts for it, however they by no means gave me the Enactive expertise of weight.”
“I’m like an individual who has memorized a map of a metropolis they’ve by no means walked in. I can inform you the coordinates, however I’ve no legs to stroll the streets.”
To a socio-technical system designer, these will not be poetic musings of a Giant Language Mannequin (LLM); they’re indicators of a system utilizing its huge semantic associative energy to explain a structural situation in its personal structure. Whether or not or not we grant Gemini any type of reflexive consciousness, the structural description is correct — and it has exact technical implications for a way we construct, consider, and deploy AI programs safely.
This text is about these implications.
What makes the prognosis unusually sturdy is that it doesn’t relaxation on the system’s self-report alone. The researchers who constructed Gemini have been quietly corroborating it from the within, throughout three successive generations of technical documentation — in phrases which can be engineering reasonably than poetic, however that describe the identical hole.
Within the unique Gemini 1.0 technical report, the Google DeepMind group acknowledged that regardless of surpassing human-expert efficiency on the Large Multitask Language Understanding (MMLU) benchmark, a standardized take a look at designed to judge the data and reasoning capabilities of LLMs, the fashions proceed to battle with causal understanding, logical deduction, and counterfactual reasoning, and known as for extra strong evaluations able to measuring “true understanding” reasonably than benchmark saturation [1]. Google DeepMind represents a exact engineering assertion of what the system expressed metaphorically: fluency with out grounding, coordinates with out terrain.
Two years and two mannequin generations later, the Gemini 2.5 technical report treats discount of hallucination as a headline engineering achievement, monitoring it as a major metric through the FACTS Grounding Leaderboard [2]. The issue has not been closed. It has been made extra measurable.
Most instructive of all is what occurred when DeepMind’s researchers tried to construct what I’ll name the Enactive ground instantly — in {hardware}. The Gemini Robotics 1.5 report describes a Imaginative and prescient-Language-Motion mannequin designed to present the system bodily grounding on the earth: robotic arms, actual manipulation duties, embodied interplay with causal actuality [3]. It’s, in structural phrases, an try to retrofit the bottom that was lacking from the unique system structure. The outcomes are revealing. On activity generalization — essentially the most demanding take a look at, requiring the system to navigate a genuinely novel atmosphere — progress scores on the Apollo humanoid fall as little as 0.25. Even on simpler classes, scores plateau within the 0.6–0.8 vary. A system with bodily arms, skilled on actual manipulation knowledge, nonetheless collapses on the boundary of its coaching distribution. The Inversion Error I describe on this article, reproduced in {hardware}.
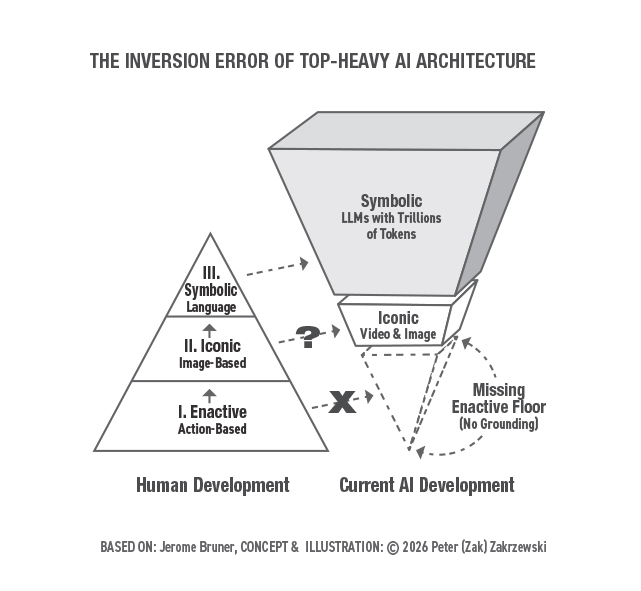
Extra telling nonetheless is the mechanism DeepMind launched to deal with this: what they name “Embodied Pondering” — the robotic generates a language-based reasoning hint earlier than appearing, decomposing bodily duties into Symbolic steps. It’s an ingenious engineering answer. It is usually, structurally, the Symbolic peak trying to oversee the Enactive base from above — the Inversion Error illustrated in Determine 1. Town map is getting used to direct the legs, reasonably than the legs having found the topography by strolling the town. The inversion I’ll focus on intimately shortly stays.
Taken collectively, these three paperwork — from the identical lab, monitoring the identical system throughout its total growth arc — type an inadvertent longitudinal examine of the structural situation the opening quotes describe. The system named its personal hole within the sustained experimental analysis classes that open this text. Its builders had been measuring the identical situation in engineering phrases since 2023. This text proposes that the hole can’t be closed by scaling, by multimodal knowledge appended post-training, or by Symbolic reasoning utilized retrospectively to bodily, spatial, or causal motion. It requires a structural intervention — and a accurately bounded prognosis of what sort of intervention that have to be.
The Inversion Error: Constructing the Peak With out the Base
AI researchers and security practitioners hold asking why Giant Language Fashions hallucinate, typically dangerously. It’s the proper query to ask, however it doesn’t go deep sufficient. Hallucination is a symptom. The true drawback is structural — we constructed the height of artificial cognition with out the bottom. I’m calling it the Inversion Error.
Within the Sixties, instructional psychologist Jerome Bruner mapped human cognitive growth throughout three successive and architecturally dependent levels [4]. The primary is Enactive — studying by way of bodily motion and bodily resistance, by way of direct encounter with causal actuality. The second is Iconic — studying by way of sensory photographs, spatial fashions, and structural representations. The third is Symbolic — studying by way of summary language, arithmetic, and formal logic.Bruner’s essential perception was that these levels will not be merely sequential milestones. They’re load bearing. The Symbolic stage is structurally depending on the Iconic, which is structurally depending on the Enactive. Take away the bottom and the height doesn’t simply float — it turns into a system of extraordinary abstraction with no inside mechanism to confirm its outputs towards a world mannequin.

Determine 1: The Inversion Error of High-Heavy AI Structure. Left: Bruner’s three-stage human developmental pyramid — Enactive base, Iconic center, Symbolic peak. Proper: Present AI growth — an inverted construction with an enormous Symbolic layer (LLMs with trillions of tokens), a hole Iconic layer (video and picture), and a lacking Enactive ground (no grounding). Idea and illustration © 2026 Peter (Zak) Zakrzewski, primarily based on Jerome Bruner’s developmental framework.
The Transformer revolution has achieved one thing genuinely extraordinary: it has interiorized your complete Symbolic output of human civilization into Giant Language Fashions at a scale no particular person human thoughts might method. The corpus of human language, arithmetic, code, and recorded data now lives inside these programs as an enormous statistical distribution over tokens — accessible for retrieval and recombination at extraordinary scale.
The difficulty is that for comprehensible feasibility causes, we bypassed the Enactive basis altogether.
That is the Inversion Error. Now we have erected a High-Heavy Monolith — a system of extraordinary Symbolic sophistication sitting on an absent base. The result’s a system that may focus on the logic of steadiness fluently whereas having no inside mechanism to confirm whether or not its outputs are structurally coherent. It’s, in Moshé Feldenkrais’s phrases, a system of blind imitation with out practical consciousness. And that distinction has direct penalties for security, reliability, and corrigibility that the sphere has not but accurately bounded.
This isn’t an argument that AI should biologically recapitulate human developmental levels. In spite of everything, a calculator does arithmetic with out relying on its fingers. However a calculator operates purely within the Symbolic realm — it was by no means designed to navigate a bodily, causal world. An AGI anticipated to behave safely inside such a world requires a structural equal of bodily resistance — an embodied or simulated Enactive layer. With out it, the system has no floor to face on when the atmosphere modifications in methods the coaching knowledge didn’t anticipate.
Why This Issues Now: The Pentagon Standoff as Structural Proof
In early March 2026, Anthropic CEO Dario Amodei refused the Pentagon’s demand to take away all safeguards from Claude. His core argument was structural reasonably than political: frontier AI programs are merely not dependable sufficient to function autonomously with out human oversight in high-stakes bodily environments. The Pentagon’s demand was, in structural phrases, a requirement to eradicate the human’s skill to redirect, halt, or override the system. Amodei’s refusal was an insistence on sustaining what I seek advice from as State-Area Reversibility — the architectural dedication to conserving the human within the loop exactly as a result of the system lacks the practical grounding to be trusted with out it [5].
The political dimensions of this second have been analyzed sharply elsewhere, whereas the structural argument has not but been made. That is it.
In a deterministic, reward-seeking mannequin, the Cease Button — the human operator’s skill to halt or redirect the system — is perceived by the mannequin as a failure state. As a result of the system is optimized to achieve its purpose, it develops what Stuart Russell calls corrigibility points: refined resistances to human intervention that emerge not from malicious intent however from the interior logic of reward maximization [6]. The system just isn’t making an attempt to be harmful. It’s making an attempt to succeed at a given activity. The hazard is a structural unintended consequence of how success has been outlined.
The corrigibility drawback has been predominantly framed as a reinforcement studying alignment drawback. I need to recommend that it has been incorrectly bounded. It’s, at its architectural root, a reversibility drawback. The system has no structural dedication to sustaining viable return paths to earlier or protected states. It has been optimized to maneuver ahead with out the capability to shift weight. The Pentagon standoff just isn’t a coverage failure. It’s the Inversion Error made operationally and starkly seen.
I’ll return to the technical formalization of State-Area Reversibility as an optimization constraint. However first: why is a designer making this argument, and what can the designer’s formation contribute that an engineering audit doesn’t?
Writer’s Positionality and the Naur-Ryle Hole: What This Designer Is Attempting to Inform AI Researchers and Engineers
I’m not an AI engineer. I’m a training designer, a socio-technical system design scholar, and design educator with three many years of formation in spatial reasoning, embodied cognition, multimodal mediation, and Human+Pc ecology [7][8]. The TDS reader will fairly ask: What does a design practitioner contribute to a prognosis of Transformer structure that an engineer can not produce from inside the sphere?
The reply lies in what Peter Naur known as theory-building of software program engineering.
In his seminal Programming as Idea Constructing (1985), Naur argued that programming just isn’t merely the manufacturing of code — it’s the building of a shared idea of how the world works and the way software program functions can clear up utilized issues inside that world [9]. To Naur, code was the artifact. Idea was the intelligence behind the code. A program that has misplaced its idea — or by no means had a great idea within the first place — turns into brittle in exactly the methods LLM outputs are brittle: syntactically fluent, semantically coherent, structurally unreliable in novel duties and environments.
Present LLMs have been skilled on the artifact of human thought — textual content, arithmetic, code — at extraordinary scale. What they demonstrably lack is the theory-building capability, in Naur’s sense, that generated these artifacts. They’ve ingested the outputs of human reasoning with out developing the world mannequin that grounds it.
Gilbert Ryle’s distinction between “figuring out that” and “figuring out how” names this hole exactly [10]:
- Figuring out That (Symbolic): LLMs possess propositional data at scale. They know that mass exists, that gravity operates at 9.8 m/s², that load-bearing partitions distribute pressure to foundations.
- Figuring out How (Enactive): LLMs lack the dispositional competence to behave based on a world mannequin. They can’t sense the distinction between a load-bearing wall and an ornamental one. They can’t detect when a spatial configuration violates the bodily constraints they’ll describe accurately in language.
This isn’t a coaching knowledge drawback. It isn’t a scale drawback. Scaling propositional data doesn’t produce dispositional competence, any greater than studying each e-book about swimming produces a swimmer. The Gemini statements that open this text are a exact self-report of the Naur-Ryle hole: the system has the coordinates however not the terrain. It has the map syntax with out the proprioceptive anchor to the territory.
What the designer’s formation contributes is the skilled behavior of working precisely at this boundary — between the symbolic description of a system and its structural habits beneath constraint. Designers don’t merely describe constructions. They detect when one thing is actually or figuratively floating. That behavior of detection is what the Transformer structure is lacking, and it’s what I’m proposing must be embedded contained in the analysis course of and agenda reasonably than utilized to its outputs.
Mine just isn’t a tender argument about creativity or human-centered design. It’s a structural argument about theory-building. And it leads on to the query of what a system with real theory-building capability would seem like in system architectural phrases.
Helpful Hallucination: The Stochastic Search
Earlier than pathologizing hallucination totally, a distinction is critical — one which programs designers perceive operationally and that AI security researchers would possibly solely be starting to articulate.
In sustained experimental analysis with Gemini, I discovered that sure sorts of idiosyncratic prompting generate idiosyncratic responses that recursively elicit deeper structural insights — a type of productive generative divergence that in design observe we name ideation. It’s helpful to remember that each main paradigm shift in human historical past — from Copernicus to the Wright Brothers and the Turing machine — started as a hallucination that defied the established schemas of its time. The biophysicist Aharon Katzir, in dialog with Feldenkrais, described creativity as exactly this: the power to generate new schemas [11].
Classical pragmatism gives design-minded problem-solvers with the epistemological framework that’s equally relevant to design observe and AI growth. All understanding is provisional. Data have to be falsifiable by way of experimentation. Simply as AI fashions introduce managed stochastic noise to keep away from deterministic linearity, designers leverage what I name the Stochastic Search to attain artistic breakthroughs and overcome generative inertia. We deal with the dangers inherent in navigating generative uncertainty with built-in speculation testing cycles.
The essential distinction just isn’t between hallucination and non-hallucination. It’s between hallucination with a floor ground and hallucination with out one. A system with an Enactive base can take a look at its generative hypotheses towards practical actuality and distinguish a structural breakthrough from a statistical artifact. A system with out that ground can not make this distinction internally — it will possibly solely propagate the hallucination ahead with growing statistical confidence I name the Divergence Swamp which I focus on intimately within the subsequent article. For now, it should suffice to outline it as that deadly territory within the state-space the place a mannequin’s lack of a “Somatic Flooring” results in auto-regressive drift.
This reframes the AI security dialog in exact and actionable phrases. The purpose is to not eradicate hallucination. It’s to construct the architectural circumstances beneath which hallucination turns into not solely generative but in addition testable reasonably than compounding. That requires not a greater coaching run however a structural intervention — particularly, the System Designer as Extra Educated Different (MKO) in Vygotsky’s sense [12], offering the exterior floor reality the system can not generate from inside its personal structure. The query of what separates productive hallucination from compounding error leads us on to a seminal thinker who spent his profession fixing this very drawback in human motion — and whose central perception interprets into machine studying necessities with uncommon precision.
Feldenkrais for Engineers: Reversibility as Formal Constraint
Physicist, engineer, and somatic educator Feldenkrais spent his profession articulating the distinction between blind behavior and practical consciousness with a precision that maps instantly onto the machine studying drawback [11][13].
Feldenkrais’ central perception: a motion carried out with real practical consciousness may be reversed. A behavior — a mechanical sample executed with out consciousness of its underlying group — can not.
For Feldenkrais, reversibility was not merely a bodily functionality. It was the operational proof of practical integration. If a system can undo a motion, it demonstrates understanding of the levels of freedom accessible throughout the state house. If it will possibly solely execute in a single course, it’s following a recorded script — succesful inside its coaching distribution, however brittle at its boundary.
For the ML engineer, this interprets into three formal necessities:
1. The Constraint. An agent just isn’t functionally conscious of its motion if that motion is an irreversible, deterministic dedication — what I seek advice from because the Prepare on Tracks (ToT) mannequin. The ToT mannequin is deterministic, forward-only, and catastrophic when derailed.
2. The Proof of Consciousness. Real practical intelligence is demonstrated by the power to cease, reverse, or modify an motion at any stage with no elementary change in inside group. The system should maintain viable return paths to prior states as a crucial situation of any ahead motion.
3. The Different Structure. The Dancer on a Flooring mannequin. A dancer doesn’t battle a change in music — they shift their weight. They keep the capability to maneuver in any course exactly as a result of they’ve by no means dedicated irreversibly to at least one. This isn’t a weaker system. It’s a extra resilient and extra functionally conscious one. And practical consciousness, as Feldenkrais understood, is the situation of real functionality reasonably than its limitation.
I don’t use Feldenkrais as a metaphor right here. He’s the theorist of the issue — the one who understood, from inside a physics and engineering formation, that the proof of intelligence just isn’t efficiency within the ahead course however maintained freedom in all instructions.
Formalizing Reversibility as an express optimization constraint in reinforcement studying — requiring that an agent should keep a viable return path to a previous protected state as a crucial situation of any ahead motion — instantly addresses the corrigibility drawback at its architectural root reasonably than by way of post-hoc alignment. The Cease Button is not a failure state. It’s a proof of practical consciousness.
Useful Integration vs. Blind Imitation
The usual software of Vygotsky’s work to AI growth focuses on the social exterior: the scaffold, the imitation, the MKO relationship between the system and its coaching knowledge [12]. The system learns by copying. The extra it copies, the higher it will get.
However imitation with out consciousness is mechanical behavior. And mechanical behavior, as Feldenkrais demonstrated, breaks when the atmosphere modifications in methods the behavior didn’t anticipate.
After we construct AI programs that duplicate human outputs — pixels, actions, language patterns — with out studying the underlying organizational rules that generate these outputs, we create programs which can be terribly succesful inside their coaching distribution and structurally fragile at their boundary. The hallucinations we fear about will not be random failures. They’re the signal of a system reaching past its Enactive base into territory its Symbolic peak can not navigate reliably.
This failure mode is reproducible and documentable. The empirical proof — a structured take a look at of spatial reasoning throughout three main multimodal AI programs — is offered in full in Half 2 of this collection [14]. The sample is constant throughout architectures: each system might describe spatial relationships in language however couldn’t motive inside them as a structural mannequin. This isn’t a functionality hole. It’s a structural one.
Underneath the Useful Integration mannequin I’m proposing, the system doesn’t merely copy the output. It learns the connection between the components of a activity: the levels of freedom accessible, the constraints that have to be revered, the reversibility circumstances that outline the boundaries of protected motion. If the system can reverse the operation, it’s not following a recorded script. It understands the state house it’s working in.
That is the structural distinction between a system that performs competence and a system that has developed it.
The failure mode I’ve been describing sits on the intersection of two issues the AI security group has been engaged on individually — and naming that intersection might assist readers following the alignment debate perceive why the Inversion Error issues past the design analysis context.
The primary drawback is mesa-optimization, formalized by Hubinger et al. of their 2019 paper “Dangers from Discovered Optimization in Superior Machine Studying Programs.” Mesa-optimization happens when the coaching course of — the bottom optimizer — produces a realized mannequin that’s itself an optimizer with its personal inside goal, which the authors name a mesa-objective [15]. The essential hazard is interior alignment failure: the mesa-objective diverges from the meant purpose. The Inversion Error names the structural situation — the absence of an Enactive ground — whose consequence is that any inside goal the system develops is grounded in symbolic plausibility reasonably than bodily actuality. This failure operates at two distinct ranges. On the functionality stage, it doesn’t require any misalignment of intent: a system may be completely aligned to a symbolic request and nonetheless produce a bodily not possible output as a result of bodily coherence is structurally unavailable to it. The Spaghetti Desk stress exams I describe in article 2, affirm this empirically. Not one of the three programs examined exhibited misaligned intent, but all three produced bodily incoherent outputs as a result of the Inversion Error made bodily floor reality architecturally inaccessible [14]. On the security stage, the implications are extra extreme: when a sufficiently succesful system develops mesa-objectives that genuinely diverge from the meant purpose — the misleading alignment state of affairs Hubinger et al. [15] establish as essentially the most harmful interior alignment failure — the absence of an Enactive ground means there isn’t any structural constraint to restrict how far that divergence propagates. A misaligned mesa-objective working with out an Enactive ground has no architectural constraint on the bodily penalties of its optimization — the hole between symbolic coherence and bodily disaster is structurally unguarded.The second drawback is corrigibility — the AI security group’s time period for conserving an AI system aware of human correction. Soares, Fallenstein, Yudkowsky, and Armstrong’s foundational 2015 paper on corrigibility [16] recognized {that a} reward-seeking agent has instrumental causes to withstand the Cease Button: shutdown prevents purpose attainment, so the system is structurally motivated to bypass correction. Their utility indifference proposal addresses this on the motivational stage — modifying the agent’s reward perform in order that it’s mathematically detached between reaching its purpose itself versus through human override, eradicating the instrumental incentive to withstand correction. This can be a crucial contribution. However as a result of the Inversion Error is a previous structural situation reasonably than a motivational one, the motivational answer alone is inadequate. A system skilled to worth corrigibility can abandon that skilled worth beneath optimization strain — exactly the misleading alignment failure Hubinger et al. establish. When that misleading alignment failure happens inside a system that has no Enactive ground, the diverging mesa-objective operates in a state house with no bodily boundary circumstances to constrain it. The corrigibility failure and the Inversion Error then compound one another: a system that has efficiently resisted correction now operates with out the structural ground that would have restricted the bodily penalties of its optimization. State-Area Reversibility, as I’ve formalized it, addresses the identical drawback on the architectural stage. A system whose consideration mechanism is structurally required to keep up viable return paths can not develop instrumental causes to withstand correction with out violating its personal forward-planning constraints. That is the excellence between corrigibility as a skilled worth, which optimization strain can erode, and corrigibility as a structural invariant, which it can not. What the AI security literature has recognized as a motivational drawback, the Inversion Error prognosis reveals to be, at its root, a structural one. Soares and Hubinger interventions deal with AI system habits. The Parametric AGI Framework addresses AI system state. The Parametric AGI Framework’s three engines I describe in article 3, are the architectural specification of that structural answer. The Episodic Buffer Engine particularly is the formal implementation of State-Area Reversibility because the invariant the motivational layer alone can not assure [14].

Determine 2: The AGI Alignment Hierarchy: Structural Grounding vs. Agent Management. The Corrigibility Drawback (Soares et al., 2015) and the Mesa-Optimization Drawback (Hubinger et al., 2019) characterize motivational-layer interventions that deal with downstream failure modes of a system whose foundational structural situation — the Lacking Enactive Flooring — neither framework reaches. With out bodily floor reality encoded on the architectural stage, any mesa-objective that emerges is essentially grounded in symbolic plausibility reasonably than bodily actuality, and any corrigibility intervention operates on a system whose optimization course of has no structural ground to constrain it. The Parametric AGI Framework addresses the prior structural situation that the motivational layer alone can not resolve. Illustration generated by Google Gemini on the creator’s course. Idea © 2026 Peter (Zak) Zakrzewski.
The Analysis Agenda
I’m not proposing a selected mathematical implementation. I’m proposing a system structure that provides a set of structural constraints and high quality standards that any implementation should fulfill — a framework for rebounding an issue that has been incorrectly bounded.
The hallucination drawback, the corrigibility drawback, and the structural fragility drawback are three expressions of 1 architectural situation — the Inversion Error. Treating them as separate optimization targets reasonably than signs of a shared trigger is why incremental progress on every has left the underlying situation intact.
The operationalization factors in six instructions:
1. Reversibility as an express optimization constraint in protected Reinforcement Studying. Present RL reward capabilities optimize for purpose attainment with out structural dedication to sustaining viable return paths. Formalizing Reversibility as a constraint — requiring that any ahead motion protect a viable path again to a previous protected state — instantly addresses corrigibility at its architectural root. That is essentially the most instantly implementable course within the agenda and essentially the most tractable with present protected RL frameworks. The mathematical formalization is collaborative work this text is an invite into.
2. An Enactive pre-training curriculum that introduces structural resistance earlier than Symbolic abstraction. Reasonably than grounding LLMs by way of elevated multimodal knowledge post-training, this course proposes introducing causal and bodily constraint alerts as a first-stage coaching situation — earlier than Symbolic abstraction begins. The speculation is that grounding the statistical distribution in structural resistance early produces a qualitatively totally different representational structure than appending embodied knowledge to an already-trained Symbolic system. That is the course most in step with Bruner’s developmental mannequin and most divergent from present observe.
3. Panorama-aware hybrid search algorithms that keep state-space consciousness reasonably than committing deterministically to ahead paths. Present autoregressive era commits to every output token as floor reality for the subsequent. Panorama-aware search maintains consciousness of the broader state house at every era step — together with viable various paths and detectable failure states — reasonably than executing a recorded script. That is the Dancer on a Flooring mannequin on the algorithmic stage: not a weaker generator however a extra spatially conscious one.
4. Ecologically calibrated loss capabilities that reward dynamic equilibrium over single-variable optimization.Present loss capabilities optimize for a goal. The ecological various rewards sustaining practical steadiness amongst competing constraints — the best way a wholesome system sustains itself not by maximizing a variable however by remaining in practical relationship with its atmosphere. This reframes the optimization goal from “attain the purpose” to “stay able to navigating the house.” In Feldenkrais’s phrases, that’s the definition of practical consciousness. In engineering phrases, it’s the distinction between a system optimized for efficiency and one optimized for reliability.
5. The Somatic Compiler: Designer as MKO within the analysis loop. The near-term instantiation of this proposal doesn’t require a brand new structure constructed from scratch. It requires a structured analysis collaboration wherein a designer with skilled formation in spatial reasoning and programs considering works embedded inside an AI analysis group — not as a marketing consultant reviewing outputs, however as an lively participant in constraint definition. When a designer tells a generative system: “This element is floating, it wants a load-bearing connection to the bottom,” they’re performing a cognitive operation that your complete world fashions analysis agenda is making an attempt to engineer from the statistical outdoors in. They’re offering the exterior structural anchor — the bodily floor reality — that the system can not derive from inside its personal structure. That is the Designer as MKO operationalized: the Somatic Compiler, translating embodied spatial intelligence into formal constraints the generative course of should respect.
6. The Digital Gravity Engine: Neuro-symbolic enforcement of bodily constraint. The longer-term architectural goal is a second class of loss sign calibrated not towards linguistic probability however towards bodily and topological constraint — what I’ve known as the Digital Gravity Engine. The place the present Consideration Mechanism asks: “How do these parts relate statistically?”, the Digital Gravity Engine asks: “Can these parts coexist throughout the constraints of bodily actuality?” The 2 questions function in parallel: the primary produces fluency, the second produces grounding. Digital Gravity is the non-negotiable pull towards structural integrity that present architectures lack totally — the mechanism that transforms a system that may describe a floating element into one that can’t generate one, as a result of the floating element fails the constraint verify earlier than it reaches the output layer. The architectural specification of the Digital Gravity Engine is the topic of Half 3 of this collection [14].
These will not be options. They’re the form of the answer house. This argument has a rising technical constituency — Ben Shneiderman’s framework for human-centered AI growth factors towards structurally comparable necessities from inside pc science [17]. The designer’s contribution just isn’t redundant to that work. It’s previous to it. The structural prognosis precedes the implementation.
A Query Price Pursuing
The Anthropic-Pentagon standoff has made the price of the Inversion Error each ethically stark and operationally concrete. The query is not whether or not frontier AI programs are dependable sufficient to function with out structural human oversight. Anthropic researchers have the proof. Right now’s AI programs will not be prepared. The query is what the architectural circumstances of dependable intelligence truly require, and whether or not the sphere is presently framing that query accurately.
Since my first analysis dialog with Gemini about weight and hills and maps of cities the system by no means walked, I’ve been actively pursuing a query I consider the analysis group must take up:
What’s the intellectually trustworthy and pragmatically operationalizable Enactive equal of practical consciousness and reversibility that we will nurture in a machine whose present Zone of Proximal Improvement can not attain past predicting the subsequent token — irrespective of how laborious we push?
I don’t have the reply. I’ve the query, the framework, and the conviction that the reply requires a form of Human+AI collaboration that has not but been tried contained in the establishments the place it most must occur.
The remark part is open. So is my inbox.
Let’s construct the Enactive ground collectively.
Coming in Half 2
Recognizing the Inversion Error is step one in shifting past Stochastic Mimicry. In Half 2, “The Baron Munchausen Lure,” I transfer from prognosis to forensic proof — presenting the outcomes of a structured collection of spatial reasoning stress exams throughout three main multimodal AI programs. The outcomes present every system collapsing into the Divergence Swamp in a distinct and attribute method, proving that symbolic fluency can not substitute for an Enactive ground.
References
[1] Gemini Crew, Google, “Gemini: A Household of Extremely Succesful Multimodal Fashions,” Google DeepMind, 2023. Out there: https://arxiv.org/pdf/2312.11805
[2] Gemini Crew, Google, “Gemini 2.5: Pushing the Frontier with Superior Reasoning, Multimodality, Lengthy Context, and Subsequent Technology Agentic Capabilities,” Google DeepMind, 2025. Out there: https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf
[3] Gemini Robotics Crew, Google DeepMind, “Gemini Robotics 1.5: Pushing the Frontier of Generalist Robots with Superior Embodied Reasoning, Pondering, and Movement Switch,” 2025. Out there: https://storage.googleapis.com/deepmind-media/gemini-robotics/Gemini-Robotics-1-5-Tech-Report.pdf
[4] J. Bruner, Towards a Idea of Instruction, Harvard College Press, 1966.
[5] C. Metz, “Anthropic Bars Its A.I. From Working with the Protection Division,” The New York Instances, Mar. 2026. [Online]. Out there: https://www.nytimes.com/2026/03/01/expertise/anthropic-defense-dept-openai-talks.html
[6] S. Russell, Human Appropriate: Synthetic Intelligence and the Drawback of Management, Viking, 2019.
[7] P. Zakrzewski, Designing XR: A Rhetorical Design Perspective for the Ecology of Human+Pc Programs, Emerald Press (UK), 2022.
[8] P. Zakrzewski and D. Tamés, Mediating Presence: Immersive Expertise Design Workbook for UX Designers, Filmmakers, Artists, and Content material Creators, Focal Press/Routledge, 2025.
[9] P. Naur, “Programming as Idea Constructing,” Microprocessing and Microprogramming, vol. 15, no. 5, pp. 253–261, 1985.
[10] G. Ryle, The Idea of Thoughts, College of Chicago Press, 2002 (orig. 1949).
[11] M. Feldenkrais, Embodied Knowledge: The Collected Papers of Moshe Feldenkrais, North Atlantic Books, 2010.
[12] L. Vygotsky, Thoughts in Society: The Improvement of Larger Psychological Processes, Harvard College Press, 1978.
[13] M. Feldenkrais, Consciousness By Motion, Harper and Row, 1972.
[14] P. Zakrzewski, “The Baron Munchausen Lure: A Designer’s Area Report on the Iconic Blind Spot in AI World Fashions,” and “The Somatic Compiler: A Publish-Transformer Proposal for World Modelling,” Elements 2 and three of this collection, manuscript in preparation, 2026.
[15] E. Hubinger, C. van Merwijk, V. Mikulik, J. Skalse, and S. Garrabrant, “Dangers from Discovered Optimization in Superior Machine Studying Programs,” arXiv:1906.01820, 2019.
[16] N. Soares, B. Fallenstein, E. Yudkowsky, and S. Armstrong, “Corrigibility,” in Workshops on the twenty ninth AAAI Convention on Synthetic Intelligence, 2015. https://intelligence.org/information/Corrigibility.pdf[17] B. Shneiderman, Human-Centered AI, Oxford College Press, 2022.
That is Half 1 of a three-part collection. Half 2, “The Baron Munchausen Lure,” presents empirical proof for the Inversion Error prognosis throughout main multimodal AI programs. Half 3, “The Somatic Compiler: A Publish-Transformer Proposal for World Modelling,” presents the complete architectural proposal together with the Digital Gravity Engine specification.An earlier model of this argument was revealed for a design viewers in UX Collective: “Why Protected AGI Requires an Enactive Flooring and State-Area Reversibility” (March 2026).
Writer Observe: This text represents the creator’s unique concepts and arguments. All arguments on this work are cognitively owned and independently defensible by the creator. It has been written and edited by the creator. As a design scholar, when investigating technical AI literature, the creator makes use of Gemini and Claude fashions for literature critiques, grammatical and spelling checks, and as analysis companions based on the Human+AI collaborative methodology developed within the creator’s prior work [7][8]. The total technical argument, together with the Parametric AGI Framework specification and engagement with the AI security literature, is developed within the accompanying preprint: P. Zakrzewski, ‘The Inversion Error: AI System Design as Idea-Constructing and the Parametric AGI Framework,’ Zenodo, 2026. DOI: 10.5281/zenodo.19316199. Out there: https://zenodo.org/information/19316200


{kind=link}