
, a bit of optimisation goes a great distance. Fashions like GPT4 value greater than $100 tens of millions to coach, which makes a 1% effectivity achieve price over 1,000,000 {dollars}. A robust option to optimise the effectivity of machine studying fashions is by writing a few of their parts straight on the GPU. Now if you happen to’re something like me, the easy point out of CUDA kernels is sufficient to ship chills down your backbone, as they’re notoriously advanced to put in writing and debug.
Luckily, OpenAI launched Triton in 2021, a brand new language and compiler abstracting away a lot of CUDA’s complexity and permitting much less skilled practitioners to put in writing performant kernels. A notable instance is Unsloth, an LLM-training service that guarantees 30x quicker coaching with 60% much less reminiscence utilization, all because of changing layers written in PyTorch with Triton kernels.
On this tutorial collection, we’ll be taught the fundamentals of GPU structure and implement high-performance Triton kernels! All of the code offered on this collection might be out there at https://github.com/RPegoud/Triton-Kernels.
GPU Structure Fundamentals
On this part, we’ll undergo the very fundamentals of (Nvidia) GPUs to get us began and write our first Triton kernel by the top of this text.
Ranging from the smallest software program unit, we will describe the hierarchy of execution models as follows:
- Threads: The smallest unit of labor, they run the user-defined kernel code.
- Warps: The smallest scheduling unit, they’re all the time composed of 32 parallel threads, every with their very own instruction handle counter and register state. Threads in a warp begin collectively however are free to department and execute independently.
- Thread Blocks: Group of warps, the place all threads can cooperate by way of shared reminiscence and sync limitations. It’s required that thread blocks can execute independently and in any order, in parallel or sequentially. This independence permits thread blocks to be scheduled in any order throughout any variety of cores, in order that GPU applications scale effectively with the variety of cores. We are able to synchronise the threads inside a block at particular factors within the kernel if wanted, for instance to synchronise reminiscence entry.
- Streaming Multiprocessor (SM): A unit accountable for executing many warps in parallel, it owns shared reminiscence and an L1 cache (holds the newest global-memory traces that the SM has accessed). An SM has a devoted warp scheduler that pull warps from the thread blocks which might be able to run.
On the {hardware} facet, the smallest unit of labor is a CUDA core, the bodily Arithmetic Logic Unit (ALU) which performs arithmetic operations for a thread (or components of it).
To summarise this part with an analogy, we may see CUDA cores as particular person staff, whereas a warp is a squad of 32 staff given the identical instruction directly. They could or could not execute this process the identical means (branching) and may probably full it at a distinct time limit (independence). A thread block consists of a number of squads sharing a standard workspace (i.e. have shared reminiscence), staff from all squads within the workspace can look forward to one another to get lunch on the similar time. A streaming multiprocessor is a manufacturing facility flooring with many squads working collectively and sharing instruments and storage. Lastly, the GPU is a entire plant, with many flooring.

Optimisation Fundamentals
When optimising deep studying fashions, we’re juggling with three major parts:
- Compute: Time spent by the GPU computing floating level operations (FLOPS).
- Reminiscence: Time spent transferring tensors inside a GPU.
- Overhead: All different operations (Python interpreter, PyTorch dispatch, …).
Preserving these parts in thoughts helps determining the fitting option to resolve a bottleneck. As an example, rising compute (e.g. utilizing a extra highly effective GPU) doesn’t assist if more often than not is spent doing reminiscence transfers. Ideally although, more often than not needs to be spent on compute, extra exactly on matrix multiplications, the exact operation GPUs are optimised for.
This suggests minimising the price paid to maneuver knowledge round, both from the CPU to the GPU (”knowledge switch value”), from one node to the opposite (”community value”) or from CUDA world reminiscence (DRAM, low cost however sluggish) to CUDA shared reminiscence (SRAM, costly however quickest on-device reminiscence). The later known as bandwidth prices and goes to be our major focus for now. Widespread methods to cut back bandwidth prices embody:
- Reusing knowledge loaded in shared reminiscence for a number of steps. A primary instance of that is tiled matrix multiplication, which we’ll cowl in a future publish.
- Fusing a number of operations in a single kernel (since each kernel launch implies shifting knowledge from DRAM to SRAM), as an illustration we will fuse a matrix multiplication with an activation operate. Usually, operator fusion can present huge efficiency enhance because it prevents plenty of world reminiscence reads/writes and any two operators current a chance for fusion.

On this instance, we carry out a matrix multiplication x@W and retailer the end in an intermediate variable a. We then apply a relu to a and retailer the end in a variable y. This requires the GPU to learn from x and W in world reminiscence, write the end in a, learn from a once more and at last write in y. As an alternative, operator fusion would enable us to halve the quantity of reads and writes to world reminiscence by performing the matrix multiplication and making use of the ReLU in a single kernel.

Triton
We’ll now write our first Triton kernel, a easy vector addition. First, let’s stroll by way of how this operation is damaged down and executed on a GPU.
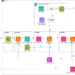
Contemplate eager to sum the entries of two vectors X and Y, every with 7 components (n_elements=7).
We’ll instruct the GPU to deal with this downside in chunks of three components at a time (BLOCK_SIZE=3). Due to this fact, to cowl all 7 components of the enter vectors, the GPU will launch 3 parallel “applications”, unbiased occasion of our kernel, every with a singular program ID, pid:
- Program 0 is assigned components
0, 1, 2. - Program 1 is assigned components
3, 4, 5. - Program 2 is assigned component
6.
Then, these applications will write again the leads to a vector Z saved in world reminiscence.
An necessary element is {that a} kernel doesn’t obtain a whole vector X, as a substitute it receives a pointer to the reminiscence handle of the primary component, X[0]. So as to entry the precise values of X, we have to load them from world reminiscence manually.
We are able to entry the info for every block through the use of this system ID: block_start = pid * BLOCK_SIZE. From there, we will get the remaining component addresses for that block by computing offsets = block_start + vary(0, BLOCK_SIZE) and cargo them into reminiscence.
Nonetheless, keep in mind that program 2 is just assigned component 6, however its offsets are [6, 7, 8]. To keep away from any indexing error, Triton lets us outline a masks to determine legitimate goal components, right here masks = offsets < n_elements.
We are able to now safely load X and Y and add them collectively earlier than writing the outcome again to an output variable Z in world reminiscence in the same means.

Let’s take a better take a look at the code, right here’s the Triton kernel:
import triton
import triton.language as tl
@triton.jit
def add_kernel(
x_ptr, # pointer to the primary reminiscence entry of x
y_ptr, # pointer to the primary reminiscence entry of y
output_ptr, # pointer to the primary reminiscence entry of the output
n_elements, # dimension of x and y
BLOCK_SIZE: tl.constexpr, # measurement of a single block
):
# --- Compute offsets and masks ---
pid = tl.program_id(axis=0) # block index
block_start = pid * BLOCK_SIZE # begin index for present block
offsets = block_start + tl.arange(0, BLOCK_SIZE) # index vary
masks = offsets < n_elements # masks out-of-bound components
# --- Load variables from world reminiscence ---
x = tl.load(x_ptr + offsets, masks=masks)
y = tl.load(y_ptr + offsets, masks=masks)
# --- Operation ---
output = x + y
# --- Save outcomes to world reminiscence ---
tl.retailer(pointer=output_ptr + offsets, worth=output, masks=masks)Let’s break down a few of the Triton-specific syntax:
- First, a Triton kernel is all the time adorned by
@triton.jit. - Second, some arguments must be declared as static, that means that they’re recognized at compute-time. That is required for
BLOCK_SIZEand is achieved by add thetl.constexprsort annotation. Additionally be aware that we don’t annotate different variables, since they aren’t correct Python variables. - We use
tl.program_idto entry the ID of the present block,tl.arangebehaves equally to Numpy’snp.arange. - Loading and storing variables is achieved by calling
tl.loadandtl.retailerwith arrays of pointers. Discover that there is no such thing as areturnassertion, this function is delegated totl.retailer.
To make use of our kernel, we now want to put in writing a PyTorch-level wrapper that gives reminiscence pointers and defines a kernel grid. Usually, the kernel grid is a 1D, 2D or 3D tuple containing the variety of thread blocks allotted to the kernel alongside every axis. In our earlier instance, we used a 1D grid of three thread blocks: grid = (3, ).
To deal with various array sizes, we default to grid = (ceil(n_elements / BLOCK_SIZE), ).
def add(X: torch.Tensor, Y: torch.Tensor) -> torch.Tensor:
"""PyTorch wrapper for `add_kernel`."""
output = torch.zeros_like(x) # allocate reminiscence for the output
n_elements = output.numel() # dimension of X and Y
# cdiv = ceil div, computes the variety of blocks to make use of
grid = lambda meta: (triton.cdiv(n_elements, meta["BLOCK_SIZE"]),)
# calling the kernel will robotically retailer `BLOCK_SIZE` in `meta`
# and replace `output`
add_kernel[grid](X, Y, output, n_elements, BLOCK_SIZE=1024)
return outputListed below are two ultimate notes concerning the wrapper:
You might need seen that grid is outlined as a lambda operate. This permits Triton to compute the variety of thread blocks to launch at launch time. Due to this fact, we compute the grid measurement based mostly on the block measurement which is saved in meta, a dictionary of compile-time constants which might be uncovered to the kernel.
When calling the kernel, the worth of output might be modified in-place, so we don’t must reassign output = add_kernel[…].
We are able to conclude this tutorial by verifying that our kernel works correctly:
x, y = torch.randn((2, 2048), system="cuda")
print(add(x, y))
>> tensor([ 1.8022, 0.6780, 2.8261, ..., 1.5445, 0.2563, -0.1846], system='cuda:0')
abs_difference = torch.abs((x + y) - add(x, y))
print(f"Max absolute distinction: {torch.max(abs_difference)}")
>> Max absolute distinction: 0.0That’s it for this introduction, in following posts we’ll be taught to implement extra fascinating kernels comparable to tiled matrix multiplication and see combine Triton kernels in PyTorch fashions utilizing autograd.
Till subsequent time! 👋
References and Helpful Assets


{kind=link}