Retrieval Augmented Era (RAG) enhances AI responses by combining the generative AI mannequin’s capabilities with data from exterior information sources, quite than relying solely on the mannequin’s built-in information. On this publish, we showcase the customized information connector functionality in Amazon Bedrock Data Bases that makes it easy to construct RAG workflows with customized enter information. Via this functionality, Amazon Bedrock Data Bases helps the ingestion of streaming information, which suggests builders can add, replace, or delete information of their information base via direct API calls.
Consider the examples of clickstream information, bank card swipes, Web of Issues (IoT) sensor information, log evaluation and commodity costs—the place each present information and historic tendencies are essential to make a discovered determination. Beforehand, to feed such vital information inputs, you needed to first stage it in a supported information supply after which both provoke or schedule an information sync job. Based mostly on the standard and amount of the info, the time to finish this course of diversified. With customized information connectors, you’ll be able to shortly ingest particular paperwork from customized information sources with out requiring a full sync and ingest streaming information with out the necessity for middleman storage. By avoiding time-consuming full syncs and storage steps, you acquire sooner entry to information, lowered latency, and improved utility efficiency.
Nevertheless, with streaming ingestion utilizing customized connectors, Amazon Bedrock Data Bases processes such streaming information with out utilizing an middleman information supply, making it obtainable virtually instantly. This function chunks and converts enter information into embeddings utilizing your chosen Amazon Bedrock mannequin and shops every thing within the backend vector database. This automation applies to each newly created and present databases, streamlining your workflow so you’ll be able to concentrate on constructing AI functions with out worrying about orchestrating information chunking, embeddings era, or vector retailer provisioning and indexing. Moreover, this function offers the flexibility to ingest particular paperwork from customized information sources, all whereas lowering latency and assuaging operational prices for middleman storage.
Amazon Bedrock
Amazon Bedrock is a totally managed service that provides a selection of high-performing basis fashions (FMs) from main AI corporations corresponding to Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, together with a broad set of capabilities that you must construct generative AI functions with safety, privateness, and accountable AI. Utilizing Amazon Bedrock, you’ll be able to experiment with and consider prime FMs in your use case, privately customise them along with your information utilizing strategies corresponding to fine-tuning and RAG, and construct brokers that execute duties utilizing your enterprise methods and information sources.
Amazon Bedrock Data Bases
Amazon Bedrock Data Bases permits organizations to construct absolutely managed RAG pipelines by augmenting contextual data from non-public information sources to ship extra related, correct, and customised responses. With Amazon Bedrock Data Bases, you’ll be able to construct functions which are enriched by the context that’s acquired from querying a information base. It permits a sooner time to product launch by abstracting from the heavy lifting of constructing pipelines and offering you an out-of-the-box RAG resolution, thus lowering the construct time in your utility.
Amazon Bedrock Data Bases customized connector
Amazon Bedrock Data Bases helps customized connectors and the ingestion of streaming information, which suggests you’ll be able to add, replace, or delete information in your information base via direct API calls.
Resolution overview: Construct a generative AI inventory value analyzer with RAG
For this publish, we implement a RAG structure with Amazon Bedrock Data Bases utilizing a customized connector and matters constructed with Amazon Managed Streaming for Apache Kafka (Amazon MSK) for a person who could also be to grasp inventory value tendencies. Amazon MSK is a streaming information service that manages Apache Kafka infrastructure and operations, making it easy to run Apache Kafka functions on Amazon Net Providers (AWS). The answer permits real-time evaluation of buyer suggestions via vector embeddings and giant language fashions (LLMs).
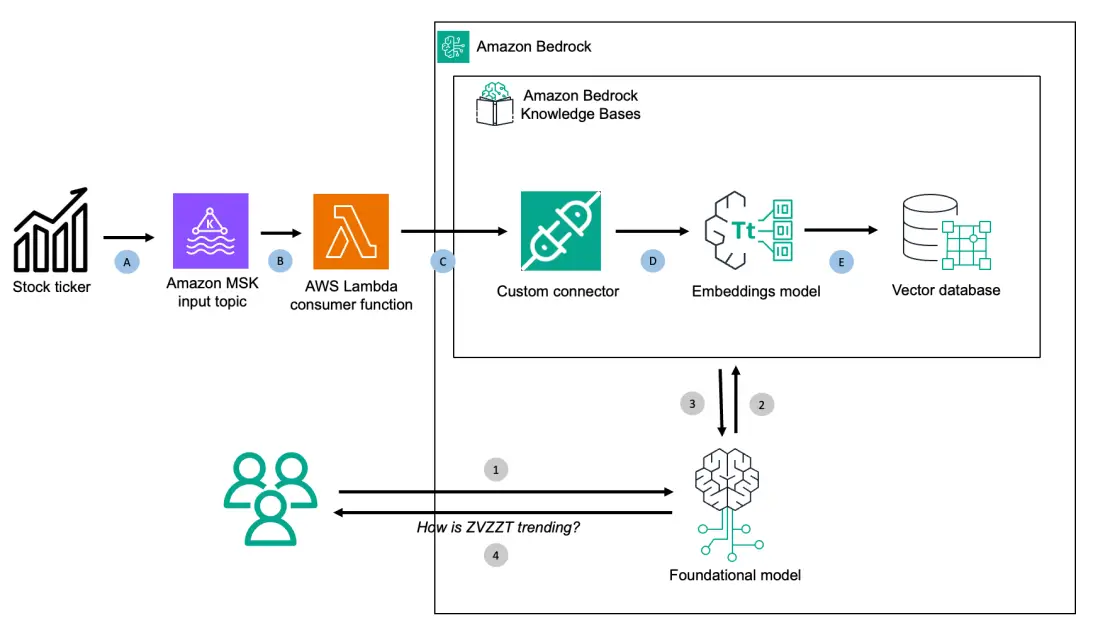
The next structure diagram has two parts:
Preprocessing streaming information workflow famous in letters on the highest of the diagram:
- Mimicking streaming enter, add a .csv file with inventory value information into MSK matter
- Robotically set off the patron AWS Lambda perform
- Ingest consumed information right into a information base
- Data base internally utilizing embeddings mannequin transforms into vector index
- Data base internally storing vector index into the vector database
Runtime execution throughout person queries famous in numerals on the backside of the diagram:
- Customers question on inventory costs
- Basis mannequin makes use of the information base to seek for a solution
- The information base returns with related paperwork
- Consumer answered with related reply

Implementation design
The implementation follows these high-level steps:
- Information supply setup – Configure an MSK matter that streams enter inventory costs
- Amazon Bedrock Data Bases setup – Create a information base in Amazon Bedrock utilizing the fast create a brand new vector retailer possibility, which routinely provisions and units up the vector retailer
- Information consumption and ingestion – As and when information lands within the MSK matter, set off a Lambda perform that extracts inventory indices, costs, and timestamp data and feeds into the customized connector for Amazon Bedrock Data Bases
- Check the information base – Consider buyer suggestions evaluation utilizing the information base
Resolution walkthrough
To construct a generative AI inventory evaluation device with Amazon Bedrock Data Bases customized connector, use directions within the following sections.
Configure the structure
To do this structure, deploy the AWS CloudFormation template from this GitHub repository in your AWS account. This template deploys the next parts:
- Useful digital non-public clouds (VPCs), subnets, safety teams and AWS Id and Entry Administration (IAM) roles
- An MSK cluster internet hosting Apache Kafka enter matter
- A Lambda perform to devour Apache Kafka matter information
- An Amazon SageMaker Studio pocket book for granular setup and enablement
Create an Apache Kafka matter
Within the precreated MSK cluster, the required brokers are deployed prepared to be used. The following step is to make use of a SageMaker Studio terminal occasion to hook up with the MSK cluster and create the take a look at stream matter. On this step, you observe the detailed directions which are talked about at Create a subject within the Amazon MSK cluster. The next are the overall steps concerned:
- Obtain and set up the newest Apache Kafka consumer
- Connect with the MSK cluster dealer occasion
- Create the take a look at stream matter on the dealer occasion
Create a information base in Amazon Bedrock
To create a information base in Amazon Bedrock, observe these steps:
- On the Amazon Bedrock console, within the left navigation web page underneath Builder instruments, select Data Bases.

- To provoke information base creation, on the Create dropdown menu, select Data Base with vector retailer, as proven within the following screenshot.

- Within the Present Data Base particulars pane, enter
BedrockStreamIngestKnowledgeBasebecause the Data Base identify. - Below IAM permissions, select the default possibility, Create and use a brand new service function, and (elective) present a Service function identify, as proven within the following screenshot.

- On the Select information supply pane, choose Customized as the info supply the place your dataset is saved
- Select Subsequent, as proven within the following screenshot

- On the Configure information supply pane, enter
BedrockStreamIngestKBCustomDSbecause the Information supply identify. - Below Parsing technique, choose Amazon Bedrock default parser and for Chunking technique, select Default chunking. Select Subsequent, as proven within the following screenshot.

- On the Choose embeddings mannequin and configure vector retailer pane, for Embeddings mannequin, select Titan Textual content Embeddings v2. For Embeddings sort, select Floating-point vector embeddings. For Vector dimensions, choose 1024, as proven within the following screenshot. Be sure you have requested and acquired entry to the chosen FM in Amazon Bedrock. To be taught extra, discuss with Add or take away entry to Amazon Bedrock basis fashions.

- On the Vector database pane, choose Fast create a brand new vector retailer and select the brand new Amazon OpenSearch Serverless possibility because the vector retailer.

- On the subsequent display, evaluate your alternatives. To finalize the setup, select Create.
- Inside a couple of minutes, the console will show your newly created information base.
Configure AWS Lambda Apache Kafka shopper
Now, utilizing API calls, you configure the patron Lambda perform so it will get triggered as quickly because the enter Apache Kafka matter receives information.
- Configure the manually created Amazon Bedrock Data Base ID and its customized Information Supply ID as surroundings variables throughout the Lambda perform. While you use the pattern pocket book, the referred perform names and IDs will probably be crammed in routinely.
- When it’s accomplished, you tie the Lambda shopper perform to pay attention for occasions within the supply Apache Kafka matter:
Evaluate AWS Lambda Apache Kafka shopper
The Apache Kafka shopper Lambda perform reads information from the Apache Kafka matter, decodes it, extracts inventory value data, and ingests it into the Amazon Bedrock information base utilizing the customized connector.
- Extract the information base ID and the info supply ID:
- Outline a Python perform to decode enter occasions:
- Decode and parse required information on the enter occasion acquired from the Apache Kafka matter. Utilizing them, create a payload to be ingested into the information base:
- Ingest the payload into Amazon Bedrock Data Bases utilizing the customized connector:
Testing
Now that the required setup is finished, you set off the workflow by ingesting take a look at information into your Apache Kafka matter hosted with the MSK cluster. For greatest outcomes, repeat this part by altering the .csv enter file to point out inventory value improve or lower.
- Put together the take a look at information. In my case, I had the next information enter as a .csv file with a header.
| ticker | value |
| OOOO | $44.50 |
| ZVZZT | $3,413.23 |
| ZNTRX | $22.34 |
| ZNRXX | $208.76 |
| NTEST | $0.45 |
| ZBZX | $36.23 |
| ZEXIT | $942.34 |
| ZIEXT | $870.23 |
| ZTEST | $23.75 |
| ZVV | $2,802.86 |
| ZXIET | $63.00 |
| ZAZZT | $18.86 |
| ZBZZT | $998.26 |
| ZCZZT | $72.34 |
| ZVZZC | $90.32 |
| ZWZZT | $698.24 |
| ZXZZT | $932.32 |
- Outline a Python perform to place information to the subject. Use pykafka consumer to ingest information:
- Learn the .csv file and push the information to the subject:
Verification
If the info ingestion and subsequent processing is profitable, navigate to the Amazon Bedrock Data Bases information supply web page to verify the uploaded data.

Querying the information base
Throughout the Amazon Bedrock Data Bases console, you could have entry to question the ingested information instantly, as proven within the following screenshot.

To do this, choose an Amazon Bedrock FM that you’ve got entry to. In my case, I selected Amazon Nova Lite 1.0, as proven within the following screenshot.

When it’s accomplished, the query, “How is ZVZZT trending?”, yields the outcomes primarily based on the ingested information. Notice how Amazon Bedrock Data Bases exhibits the way it derived the reply, even pointing to the granular information ingredient from its supply.

Cleanup
To be sure to’re not paying for assets, delete and clear up the assets created.
- Delete the Amazon Bedrock information base.
- Delete the routinely created Amazon OpenSearch Serverless cluster.
- Delete the routinely created Amazon Elastic File System (Amazon EFS) shares backing the SageMaker Studio surroundings.
- Delete the routinely created safety teams related to the Amazon EFS share. You may have to take away the inbound and outbound guidelines earlier than they are often deleted.
- Delete the routinely created elastic community interfaces hooked up to the Amazon MSK safety group for Lambda visitors.
- Delete the routinely created Amazon Bedrock Data Bases execution IAM function.
- Cease the kernel situations with Amazon SageMaker Studio.
- Delete the CloudFormation stack.
Conclusion
On this publish, we confirmed you ways Amazon Bedrock Data Bases helps customized connectors and the ingestion of streaming information, via which builders can add, replace, or delete information of their information base via direct API calls. Amazon Bedrock Data Bases presents absolutely managed, end-to-end RAG workflows to create extremely correct, low-latency, safe, and customized generative AI functions by incorporating contextual data out of your firm’s information sources. With this functionality, you’ll be able to shortly ingest particular paperwork from customized information sources with out requiring a full sync, and ingest streaming information with out the necessity for middleman storage.
Ship suggestions to AWS re:Put up for Amazon Bedrock or via your regular AWS contacts, and interact with the generative AI builder neighborhood at neighborhood.aws.
In regards to the Creator
 Prabhakar Chandrasekaran is a Senior Technical Account Supervisor with AWS Enterprise Assist. Prabhakar enjoys serving to prospects construct cutting-edge AI/ML options on the cloud. He additionally works with enterprise prospects offering proactive steerage and operational help, serving to them enhance the worth of their options when utilizing AWS. Prabhakar holds eight AWS and 7 different skilled certifications. With over 22 years {of professional} expertise, Prabhakar was an information engineer and a program chief within the monetary providers house previous to becoming a member of AWS.
Prabhakar Chandrasekaran is a Senior Technical Account Supervisor with AWS Enterprise Assist. Prabhakar enjoys serving to prospects construct cutting-edge AI/ML options on the cloud. He additionally works with enterprise prospects offering proactive steerage and operational help, serving to them enhance the worth of their options when utilizing AWS. Prabhakar holds eight AWS and 7 different skilled certifications. With over 22 years {of professional} expertise, Prabhakar was an information engineer and a program chief within the monetary providers house previous to becoming a member of AWS.



{kind=link}