Disentangle options in advanced Neural Community with superpositions
Complicated neural networks, corresponding to Giant Language Fashions (LLMs), endure very often from interpretability challenges. One of the vital essential causes for such problem is superposition — a phenomenon of the neural community having fewer dimensions than the variety of options it has to characterize. For instance, a toy LLM with 2 neurons has to current 6 completely different language options. In consequence, we observe typically {that a} single neuron must activate for a number of options. For a extra detailed rationalization and definition of superposition, please confer with my earlier weblog submit: “Superposition: What Makes it Tough to Clarify Neural Community”.
On this weblog submit, we take one step additional: let’s attempt to disentangle some fsuperposed options. I’ll introduce a strategy referred to as Sparse Autoencoder to decompose advanced neural community, particularly LLM into interpretable options, with a toy instance of language options.
A Sparse Autoencoder, by definition, is an Autoencoder with sparsity launched on objective within the activations of its hidden layers. With a reasonably easy construction and lightweight coaching course of, it goals to decompose a fancy neural community and uncover the options in a extra interpretable approach and extra comprehensible to people.
Allow us to think about that you’ve a educated neural community. The autoencoder is just not a part of the coaching means of the mannequin itself however is as a substitute a post-hoc evaluation software. The unique mannequin has its personal activations, and these activations are collected afterwards after which used as enter information for the sparse autoencoder.
For instance, we suppose that your unique mannequin is a neural community with one hidden layer of 5 neurons. In addition to, you’ve got a coaching dataset of 5000 samples. You must gather all of the values of the 5-dimensional activation of the hidden layer for all of your 5000 coaching samples, and they’re now the enter to your sparse autoencoder.

The autoencoder then learns a brand new, sparse illustration from these activations. The encoder maps the unique MLP activations into a brand new vector area with larger illustration dimensions. Trying again at my earlier 5-neuron easy instance, we would contemplate to map it right into a vector area with 20 options. Hopefully, we’ll get hold of a sparse autoencoder successfully decomposing the unique MLP activations right into a illustration, simpler to interpret and analyze.
Sparsity is a crucial within the autoencoder as a result of it’s vital for the autoencoder to “disentangle” options, with extra “freedom” than in a dense, overlapping area.. With out existence of sparsity, the autoencoder will most likely the autoencoder may simply be taught a trivial compression with none significant options’ formation.
Language mannequin
Allow us to now construct our toy mannequin. I encourage the readers to notice that this mannequin is just not practical and even a bit foolish in apply however it’s enough to showcase how we construct sparse autoencoder and seize some options.
Suppose now we have now constructed a language mannequin which has one specific hidden layer whose activation has three dimensions. Allow us to suppose additionally that we have now the next tokens: “cat,” “completely happy cat,” “canine,” “energetic canine,” “not cat,” “not canine,” “robotic,” and “AI assistant” within the coaching dataset and so they have the next activation values.
information = torch.tensor([
# Cat categories
[0.8, 0.3, 0.1, 0.05], # "cat"
[0.82, 0.32, 0.12, 0.06], # "completely happy cat" (just like "cat")
# Canine classes
[0.7, 0.2, 0.05, 0.2], # "canine"
[0.75, 0.3, 0.1, 0.25], # "loyal canine" (just like "canine")# "Not animal" classes
[0.05, 0.9, 0.4, 0.4], # "not cat"
[0.15, 0.85, 0.35, 0.5], # "not canine"
# Robotic and AI assistant (extra distinct in 4D area)
[0.0, 0.7, 0.9, 0.8], # "robotic"
[0.1, 0.6, 0.85, 0.75] # "AI assistant"
], dtype=torch.float32)
Building of autoencoder
We now construct the autoencoder with the next code:
class SparseAutoencoder(nn.Module):
def __init__(self, input_dim, hidden_dim):
tremendous(SparseAutoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(hidden_dim, input_dim)
)def ahead(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
In response to the code above, we see that the encoder has a just one absolutely related linear layer, mapping the enter to a hidden illustration with hidden_dim and it then passes to a ReLU activation. The decoder makes use of only one linear layer to reconstruct the enter. Observe that the absence of ReLU activation within the decoder is intentional for our particular reconstruction case, as a result of the reconstruction may comprise real-valued and doubtlessly damaging valued information. A ReLU would quite the opposite power the output to remain non-negative, which isn’t fascinating for our reconstruction.
We prepare mannequin utilizing the code beneath. Right here, the loss perform has two elements: the reconstruction loss, measuring the accuracy of the autoencoder’s reconstruction of the enter information, and a sparsity loss (with weight), which inspires sparsity formulation within the encoder.
# Coaching loop
for epoch in vary(num_epochs):
optimizer.zero_grad()# Ahead move
encoded, decoded = mannequin(information)
# Reconstruction loss
reconstruction_loss = criterion(decoded, information)
# Sparsity penalty (L1 regularization on the encoded options)
sparsity_loss = torch.imply(torch.abs(encoded))
# Complete loss
loss = reconstruction_loss + sparsity_weight * sparsity_loss
# Backward move and optimization
loss.backward()
optimizer.step()
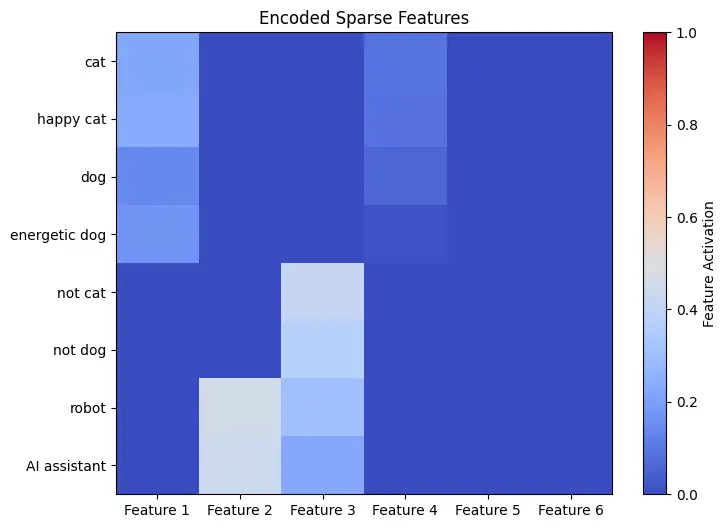
Now we are able to take a look of the consequence. We have now plotted the encoder’s output worth of every activation of the unique fashions. Recall that the enter tokens are “cat,” “completely happy cat,” “canine,” “energetic canine,” “not cat,” “not canine,” “robotic,” and “AI assistant”.

Regardless that the unique mannequin was designed with a quite simple structure with none deep consideration, the autoencoder has nonetheless captured significant options of this trivial mannequin. In response to the plot above, we are able to observe a minimum of 4 options that look like realized by the encoder.
Give first Characteristic 1 a consideration. This feautre has large activation values on the 4 following tokens: “cat”, “completely happy cat”, “canine”, and “energetic canine”. The consequence means that Characteristic 1 may be one thing associated to “animals” or “pets”. Characteristic 2 can be an fascinating instance, activating on two tokens “robotic” and “AI assistant”. We guess, due to this fact, this function has one thing to do with “synthetic and robotics”, indicating the mannequin’s understanding on technological contexts. Characteristic 3 has activation on 4 tokens: “not cat”, “not canine”, “robotic” and “AI assistant” and that is probably a function “not an animal”.
Sadly, unique mannequin is just not an actual mannequin educated on real-world textual content, however reasonably artificially designed with the belief that comparable tokens have some similarity within the activation vector area. Nonetheless, the outcomes nonetheless present fascinating insights: the sparse autoencoder succeeded in displaying some significant, human-friendly options or real-world ideas.
The straightforward consequence on this weblog submit suggests:, a sparse autoencoder can successfully assist to get high-level, interpretable options from advanced neural networks corresponding to LLM.
For readers involved in a real-world implementation of sparse autoencoders, I like to recommend this article, the place an autoencoder was educated to interpret an actual giant language mannequin with 512 neurons. This examine offers an actual software of sparse autoencoders within the context of LLM’s interpretability.
Lastly, I present right here this google colab pocket book for my detailed implementation talked about on this article.


{kind=link}