
This submit is co-written by Instituto de Ciência e Tecnologia Itaú (ICTi) and AWS.
Sentiment evaluation has grown more and more essential in fashionable enterprises, offering insights into buyer opinions, satisfaction ranges, and potential frustrations. As interactions happen largely by textual content (resembling social media, chat purposes, and ecommerce opinions) or voice (resembling name facilities and telephony), organizations want strong strategies to interpret these alerts at scale. By precisely figuring out and classifying a buyer’s emotional state, firms can ship extra proactive, personalized experiences, positively impacting buyer satisfaction and loyalty.
Regardless of its strategic worth, implementing complete sentiment evaluation options presents a number of challenges. Language ambiguity, cultural nuances, regional dialects, sarcastic expressions, and excessive volumes of real-time knowledge all demand scalable and versatile architectures. Moreover, in voice-based sentiment evaluation, vital options resembling intonation and prosody will be misplaced if the audio is transcribed and handled purely as textual content. Amazon Internet Providers (AWS) presents a set of instruments to handle these challenges. AWS supplies providers starting from audio seize and transcription (Amazon Transcribe) to textual content sentiment classification (Amazon Comprehend), in addition to clever contact heart options (Amazon Join) and real-time knowledge streaming (Amazon Kinesis).
This submit, developed by a strategic scientific partnership between AWS and the Instituto de Ciência e Tecnologia Itaú (ICTi), P&D hub maintained by Itaú Unibanco, the most important personal financial institution in Latin America, explores the technical points of sentiment evaluation for each textual content and audio. We current experiments evaluating a number of machine studying (ML) fashions and providers, talk about the trade-offs and pitfalls of every strategy, and spotlight how AWS providers will be orchestrated to construct strong, end-to-end options. We additionally provide insights into potential future instructions, together with extra superior immediate engineering for big language fashions (LLMs) and increasing the scope of audio-based evaluation to seize emotional cues that textual content knowledge alone may miss. We discover audio-based sentiment evaluation in two levels:
- Stage 1 – Transcribe audio into textual content and carry out sentiment evaluation utilizing LLMs
- Stage 2 – Analyze sentiment immediately from the audio sign utilizing audio fashions
Sentiment evaluation in textual content
On this part, we talk about the strategy of transcribing audio into textual content and performing sentiment evaluation utilizing LLMS.
Challenges and traits
This technique presents the next challenges:
- Number of knowledge sources – Textual interactions emerge from quite a few channels—social networks, ecommerce platforms, chatbots, and helpdesk tickets—every with distinctive codecs and constraints. As an example, social media textual content may comprise hashtags, emojis, or character limits, whereas chat messages may embody acronyms and domain-specific jargon. A sturdy text-processing pipeline should due to this fact embody applicable knowledge cleansing and preprocessing steps to normalize these variations.
- Ambiguity of pure language – Human language is commonly ambiguous and context-dependent. Sarcasm, irony, and figurative expressions complicate classification by superficial pure language processing (NLP) strategies. Though deep neural networks—resembling BERT, RoBERTa, and Transformers-based architectures—have confirmed more proficient at capturing nuanced semantics, it stays an ongoing problem to completely account for artistic or context-dependent language utilization.
- Multilingual and dialect issues – World enterprises like Itaú Unibanco encounter a number of languages and regional dialects, every requiring specialised fashions or extra coaching knowledge. A sentiment mannequin educated totally on one language or dialect may fail when confronted with slang, colloquialisms, or distinctive grammatical buildings from one other.
Examined fashions and rationale
In our experiments, we evaluated a number of LLMs with a deal with sentiment classification. Amongst them have been in style basis fashions (FMs) obtainable by Amazon Bedrock and Amazon SageMaker JumpStart, resembling Meta’s Llama 3 70B, Anthropic’s Claude 3.5 Sonnet, Mistral AI’s Mixtral 8x7B, and Amazon Nova Professional. Every service presents distinctive benefits primarily based on particular wants. For instance, Amazon Bedrock simplifies large-scale experimentation by offering a unified, serverless interface to a number of LLM suppliers by API-based entry. SageMaker AI supplies a serverful managed expertise for accessing in style FMs with a user-friendly UI or API-based deployment and administration. Each Amazon Bedrock and SageMaker AI streamline operational issues like mannequin internet hosting, scalability, safety, and value optimization—key advantages for enterprise adoption of generative AI.
We examined every mannequin in two configurations:
- Zero-shot or few-shot prompting – Utilizing generic prompts to categorise sentiment in textual content
- Positive-tuning – Adapting the mannequin on domain-specific sentiment knowledge to evaluate whether or not this specialised coaching improved efficiency or risked overfitting
AWS providers for textual content evaluation
Amazon presents a set of providers to assist streamline the method of textual content evaluation. For this submit, we used the next providers to construct a textual content evaluation service:
- Amazon Bedrock – Facilitates serverless entry to pre-trained FMs from completely different suppliers inside a single, safe interface—notably entry to closed weights fashions like Anthropic’s Claude. This permits speedy testing of a number of fashions with out managing underlying infrastructure.
- Amazon SageMaker AI – Offers entry to the newest open-source FMs like Llama, Mistral, DeepSeek, and extra. With SageMaker AI, you might have the choice to simplify deployment of FMs utilizing Amazon SageMaker JumpStart—an ML and generative AI managed hub that gives easy UI or API primarily based deployment of lots of of FMs or alternatively serving to you deploy your most popular FM and structure on managed NVIDIA GPU infrastructure with ease.
- Amazon Comprehend – An AI service with textual content analytics capabilities together with sentiment evaluation, entity recognition, and matter modeling. It might function a baseline or be built-in with superior LLM workflows for a extra complete pipeline.
- Amazon Kinesis – Handles real-time ingestion and streaming of textual content knowledge from numerous sources (resembling social media feeds, log streams, or real-time buyer chat periods).
A simplified structure may encompass the next elements:
- Information ingestion utilizing Kinesis to seize textual content from varied sources
- Information preprocessing utilizing AWS Lambda or Amazon EMR for normalization, tokenization, and filtering.
- Mannequin inference utilizing both an LLM accessed by Amazon Bedrock or SageMaker AI
- Storage and analytics in Amazon Easy Storage Service (Amazon S3) or Amazon Redshift for long-term evaluation, reporting, and visualization
Experimental outcomes for textual content
The next desk summarizes efficiency metrics (accuracy, precision, recall) throughout completely different fashions examined. Every was evaluated on the identical textual content dataset with the purpose of classifying sentences as constructive, destructive, or impartial.
| Mannequin | Accuracy | Precision | Recall |
| Amazon SageMaker JumpStart Llama 3 70B Instruct v1 | 0.189 | 0.527 | 0.189 |
| Amazon Bedrock Anthropic Claude 3.5 Sonnet 2024-06-20-v1 | 0.187 | 0.44 | 0.187 |
| Amazon SageMaker Mixtral 8x7B Instruct v0 | 0.164 | 0.545 | 0.164 |
| Amazon Bedrock Amazon Nova Professional v1 | 0.159 | 0.239 | 0.16 |
| Closed Supply state-of-the-art LLM 1 (>50B) | 0.159 | 0.025 | 0.159 |
| Closed Supply state-of-the-art LLM 2 (>50B) | 0.159 | 0.025 | 0.159 |
Evaluation of findings
We noticed the next from our outcomes:
- Total low efficiency – All fashions present comparatively low accuracy in detecting sentiment polarity. This means purely text-based inputs may not present sufficient contextual or emotional cues, particularly for extra delicate expressions like sarcasm or irony.
- Affect of fine-tuning – The 2 fine-tuned OpenAI fashions achieved increased metrics than most different configurations, although the soar in efficiency may point out overfitting. They constantly labeled sentences as non-neutral solely when a robust emotional indicator was current.
- Mannequin variation – Meta’s Llama 3 70B and Anthropic’s Claude 3.5 Sonnet carried out higher than another base fashions however nonetheless under the fine-tuned OpenAI options. This may replicate their pre-training aims and the area variations between their authentic coaching knowledge and our sentiment classification job.
Future instructions for text-based evaluation
You may contemplate increasing your text-based evaluation within the following methods:
- Superior immediate engineering – Present experiments employed simple chain-of-thought prompts. Future work might discover extra refined few-shot or zero-shot immediate designs, together with superior reasoning methods like “buffer of ideas,” or rigorously focused domain-specific prompting.
- Multimodal inputs – Incorporating paralinguistic info (resembling intonation or speaker emphasis) may enhance text-based classification. Such knowledge might be encoded as metadata or extracted by auxiliary fashions to complement the textual context.
- Language protection – Extending to non-English corpora and coaching domain-specific or multilingual fashions would possible enhance generalization in real-world deployments.
Sentiment evaluation in audio
On this part, we talk about the strategy of analyzing sentiment immediately from the audio sign utilizing audio fashions.
Challenges and traits
This technique presents the next challenges:
- Intonation and prosody – Spoken language carries acoustic cues (tone, pitch, quantity, tempo, and rhythm) that vastly affect perceived sentiment. A easy greeting resembling “Hello, how are you?” will be genuinely enthusiastic or passively sarcastic, relying on the intonation. Conventional speech-to-text pipelines discard these non-verbal cues, doubtlessly weakening the sentiment sign.
- Speech-to-text conversion – Many audio sentiment evaluation programs depend on ASR (Automated Speech Recognition) to generate transcripts, that are then fed into text-based sentiment fashions. Although helpful for content material understanding, purely textual evaluation ignores prosodic options—one purpose direct audio-based sentiment classification has garnered analysis curiosity.
- Noise and recording high quality – Actual-world audio usually incorporates background noise, overlapping dialogue, or low-fidelity recordings. Fashions should be strong to such situations to be viable in environments like name facilities or buyer assist traces.
Experimental datasets
We used two distinct forms of datasets, every specializing in completely different points of emotion in speech:
- Sort 1 – A curated assortment of quick utterances recorded with completely different emotional intonations. Initially labeled by arousal (resembling, pleased, indignant, disgusted), the information was then re-labeled by valence (constructive, destructive, impartial). Recordings labeled as “shock” have been eliminated as a result of it may well manifest as both constructive or destructive.
- Sort 2 – Incorporates extra diverse sentences, every labeled as constructive, destructive, or impartial. The variety and complexity of utterances make this dataset considerably tougher.
Examined fashions and rationale
We evaluated three outstanding speech-based fashions:
- HuBERT (Hidden Unit BERT) – Employs a self-supervised Transformer that learns hidden cluster assignments within the audio sign. HuBERT excels at capturing prosodic and acoustic patterns essential for emotion detection.
- Wav2Vec – Related in philosophy to HuBERT, Wav2Vec learns highly effective representations immediately from uncooked audio utilizing a Transformer-encoder spine. Its self-supervised coaching scheme is very efficient with restricted labeled knowledge.
- Whisper – A Transformer-based encoder-decoder initially designed for strong speech recognition. Though its emphasis is on transcription and translation, we examined its skill to extract embeddings for downstream sentiment classification duties.
AWS providers for audio evaluation
To streamline the coaching and inference pipeline, we used the next AWS providers:
- Amazon SageMaker Studio – Permits fast setup of coaching jobs on purpose-built situations (for instance, GPU-enabled) with out vital infrastructure overhead. Every mannequin (HuBERT, Wav2Vec, Whisper) was educated and validated in separate SageMaker periods.
- Amazon Transcribe – For these workflows requiring speech-to-text conversion, Amazon Transcribe supplies scalable and correct ASR. Although not the main focus of direct audio-based sentiment strategies, it’s generally built-in into contact heart architectures, the place textual content transcripts are additionally used for analytics or compliance checks.
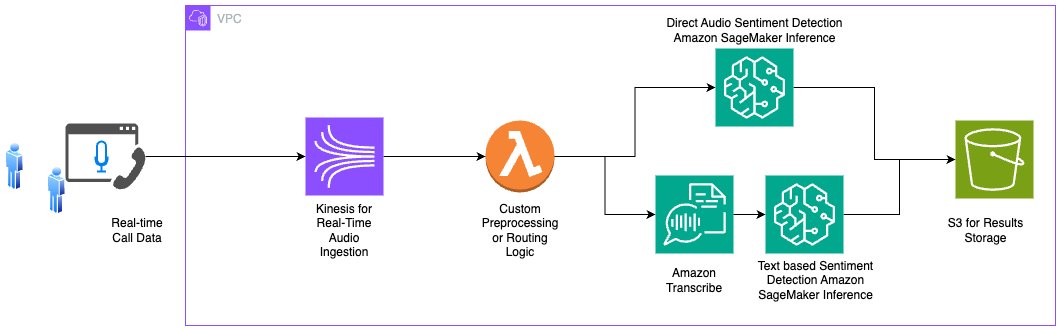
A consultant structure might contain Kinesis for audio ingestion, Lambda for orchestrating pre-processing or route choice (resembling direct audio-based sentiment vs. text-based after transcription), and Amazon S3 for storing remaining outcomes. The next diagram illustrates this instance structure.
Experimental outcomes for audio
Our analysis thought-about classification accuracy on separate check splits for Sort 1 and Sort 2 datasets. On the whole, all three fashions achieved increased efficiency on Sort 1 than on Sort 2. The next desk summarizes these outcomes.
| Dataset Sort | Sentiment | Wav2Vec | Hubert | Whisper | |||||||||
| Precision | Recall | F1 | Accuracy | Precision | Recall | F1 | Accuracy | Precision | Recall | F1 | Accuracy | ||
| Sort 1: Fastened Phrases | Adverse | 0.85 | 0.82 | 0.83 | 0.78 | 0.94 | 0.83 | 0.88 | 0.84 | 0.98 | 0.89 | 0.93 | 0.91 |
| Sort 1: Fastened Phrases | Impartial | 0.57 | 0.95 | 0.72 | 0.61 | 0.98 | 0.75 | 0.8 | 0.96 | 0.87 | |||
| Sort 1: Fastened Phrases | Optimistic | 0.86 | 0.49 | 0.63 | 0.84 | 0.74 | 0.79 | 0.82 | 0.92 | 0.86 | |||
| Sort 2: Variable Phrases | Adverse | 0.55 | 0.39 | 0.46 | 0.54 | 0.56 | 0.37 | 0.42 | 0.55 | 0.6 | 0.46 | 0.52 | 0.58 |
| Sort 2: Variable Phrases | Impartial | 0.59 | 0.73 | 0.65 | 0.6 | 0.74 | 0.66 | 0.63 | 0.71 | 0.67 | |||
| Sort 2: Variable Phrases | Optimistic | 0.35 | 0.31 | 0.33 | 0.38 | 0.35 | 0.36 | 0.44 | 0.47 | 0.46 | |||
Evaluation of findings
We noticed the next from our outcomes:
- Sort 1 – As a result of the identical phrases have been repeated with completely different emotional intonations, fashions centered extra on acoustic cues relatively than content material. This led to increased accuracy—particularly in distinguishing high-arousal (anger, pleasure) from low-arousal (disappointment, calm) states.
- Sort 2 – Efficiency dropped considerably when confronted with extra diverse sentences. Right here, the variations in lexical content material and context overshadowed purely prosodic options. The fashions struggled to generalize throughout numerous sentence buildings, speaker types, and emotional expressions.
Future instructions for audio-based evaluation
You may contemplate increasing your text-based evaluation within the following methods:
- Information variety – Increasing the datasets to incorporate extra languages, regional accents, and environmental situations may enhance the generalizability of those fashions.
- Multimodal fusion – Combining direct audio embeddings (prosody, intonation) with textual evaluation (lexical content material) may yield richer sentiment representations. That is particularly pertinent in customer support situations the place semantic content material and emotional tone each issues.
- Actual-time inference – For purposes like stay contact heart assist utilizing Amazon Join, real-time inference pipelines are essential. Researchers can examine strategies resembling streaming-based mannequin inference (for instance, chunk-by-chunk or frame-level processing) to get fast suggestions on buyer sentiment and adapt responses accordingly.
Conclusion
Sentiment evaluation—whether or not carried out on textual content or audio—presents highly effective insights into buyer perceptions, enabling extra proactive and empathetic engagement methods. Nonetheless, the technical hurdles are non-trivial:
- Textual content – Ambiguity, irony, and restricted context can hinder purely text-based classification. LLMs, even these fine-tuned, may underperform with out cautious knowledge curation, superior immediate engineering, or extra metadata.
- Audio – Instantly analyzing audio captures prosodic and acoustic cues usually misplaced in transcription. Nonetheless, environmental noise, overlapping speech, and speaker variety complicate coaching strong fashions.
AWS supplies an intensive suite of providers that cowl the end-to-end sentiment evaluation pipeline:
- Information ingestion – Kinesis for real-time textual content and audio streaming
- Preprocessing – Lambda and Amazon EMR for knowledge cleaning, characteristic extraction, and transformations
- Transcription (Optionally available) – Amazon Transcribe to transform audio to textual content if a mixed textual content and audio strategy is required
- Sentiment classification – AWS presents the next:
- Textual content – Amazon Comprehend or FMs accessed by Amazon Bedrock and SageMaker AI
- Audio – Customized fashions (resembling HuBERT, Wav2Vec, Whisper) educated in SageMaker AI
- Buyer Engagement – Amazon Join for clever contact facilities with potential for real-time sentiment suggestions loops
In the end, the selection between audio-based, text-based, or hybrid approaches relies on the use case and obtainable knowledge. Direct audio-based strategies may seize emotional subtleties essential in name heart interactions—notably throughout greetings or extremely charged conversations—whereas text-based strategies are sometimes extra simple to deploy at scale for chats, social media, and review-based evaluation. Through the use of AWS Cloud-based capabilities alongside rigorous ML methodologies, enterprises can tailor sentiment evaluation options that stability accuracy, scalability, and cost-effectiveness. Future explorations may additional combine multimodal streams, superior immediate engineering, and domain-specific fine-tuning, repeatedly refining our skill to interpret and act on the “voice of the shopper.”
Concerning the authors
 Caique de Almeida is a Workers Information Scientist at Itaú’s Institute of Science and Expertise (ICTI). He focuses on Pure Language Processing, Deep Studying, and Cloud Structure, bridging utilized analysis with production-grade AI programs. He holds 11 AWS certifications and applies that cloud experience to constructing scalable, dependable AI options. His present work facilities on constructing customer-facing brokers for monetary providers, making use of AI in finance, and investigating factuality and reasoning in generative AI. Outdoors of labor, he enjoys biking.
Caique de Almeida is a Workers Information Scientist at Itaú’s Institute of Science and Expertise (ICTI). He focuses on Pure Language Processing, Deep Studying, and Cloud Structure, bridging utilized analysis with production-grade AI programs. He holds 11 AWS certifications and applies that cloud experience to constructing scalable, dependable AI options. His present work facilities on constructing customer-facing brokers for monetary providers, making use of AI in finance, and investigating factuality and reasoning in generative AI. Outdoors of labor, he enjoys biking.
 Guilherme Rinaldo is a Workers AI Engineer and Researcher at Instituto de Ciência e Tecnologia Itaú (ICTI), the place he builds and evaluates Generative AI programs for textual content and voice, together with LLM primarily based brokers and deep studying fashions. With 8 years of expertise, he has led work from analysis prototypes to manufacturing pipelines, with an emphasis on reliability, safety, and rigorous analysis. His pursuits embody continuous studying, self evolving brokers, and mannequin monitoring at scale. Outdoors of labor, Guilherme enjoys writing, travelling, and enjoying technique video games. You’ll find Guilherme on LinkedIn.
Guilherme Rinaldo is a Workers AI Engineer and Researcher at Instituto de Ciência e Tecnologia Itaú (ICTI), the place he builds and evaluates Generative AI programs for textual content and voice, together with LLM primarily based brokers and deep studying fashions. With 8 years of expertise, he has led work from analysis prototypes to manufacturing pipelines, with an emphasis on reliability, safety, and rigorous analysis. His pursuits embody continuous studying, self evolving brokers, and mannequin monitoring at scale. Outdoors of labor, Guilherme enjoys writing, travelling, and enjoying technique video games. You’ll find Guilherme on LinkedIn.
 Paulo Finardi is a Principal Information Scientist at Itaú’s Institute of Science and Expertise (ICTI). He has over 10 years of expertise in Deep Studying and Pure Language Processing, with a deal with AI utilized to finance, simulations, and digital twins. His work spans large-scale utilized analysis, in addition to AI technique and innovation. Outdoors of labor, he enjoys biking. You’ll find Finardi on LinkedIn.
Paulo Finardi is a Principal Information Scientist at Itaú’s Institute of Science and Expertise (ICTI). He has over 10 years of expertise in Deep Studying and Pure Language Processing, with a deal with AI utilized to finance, simulations, and digital twins. His work spans large-scale utilized analysis, in addition to AI technique and innovation. Outdoors of labor, he enjoys biking. You’ll find Finardi on LinkedIn.
 Victor Costa Beraldo is a Lead Information Scientist at Itaú’s Institute of Science and Expertise (ICTi), working on the intersection of voice and AI. With a robust background in sign processing and deep studying, he focuses on speech-based options, together with ASR, ASV, emotion recognition, and real-time audio processing, bridging utilized analysis and manufacturing programs in monetary providers. Outdoors of labor, he enjoys watching soccer matches. You’ll find Victor on LinkedIn.
Victor Costa Beraldo is a Lead Information Scientist at Itaú’s Institute of Science and Expertise (ICTi), working on the intersection of voice and AI. With a robust background in sign processing and deep studying, he focuses on speech-based options, together with ASR, ASV, emotion recognition, and real-time audio processing, bridging utilized analysis and manufacturing programs in monetary providers. Outdoors of labor, he enjoys watching soccer matches. You’ll find Victor on LinkedIn.
 Vinicius Caridá is a Distinguished Information Scientist at Itaú Unibanco and a member of the scientific and technical committee at Itaú’s Institute of Science and Expertise (ICTI). He works throughout generative AI, pure language processing, digital assistants, advice programs, management programs, and the end-to-end MLOps lifecycle. Vinicius is honored to be acknowledged as an AWS AI Hero, proudly representing Latin America in this system. His present work focuses on constructing customer-facing AI brokers for monetary providers and advancing factuality and reasoning in generative fashions. Outdoors of labor, he loves instructing and studying with the tech group and spending time together with his spouse Jerusa and their daughter Olivia. You’ll find Vinicius on LinkedIn.
Vinicius Caridá is a Distinguished Information Scientist at Itaú Unibanco and a member of the scientific and technical committee at Itaú’s Institute of Science and Expertise (ICTI). He works throughout generative AI, pure language processing, digital assistants, advice programs, management programs, and the end-to-end MLOps lifecycle. Vinicius is honored to be acknowledged as an AWS AI Hero, proudly representing Latin America in this system. His present work focuses on constructing customer-facing AI brokers for monetary providers and advancing factuality and reasoning in generative fashions. Outdoors of labor, he loves instructing and studying with the tech group and spending time together with his spouse Jerusa and their daughter Olivia. You’ll find Vinicius on LinkedIn.
 Pranav Murthy is a Senior Generative AI Information Scientist at AWS, specializing in serving to organizations innovate with Generative AI, Deep Studying, and Machine Studying on Amazon SageMaker AI. Over the previous 10+ years, he has developed and scaled superior pc imaginative and prescient (CV) and pure language processing (NLP) fashions to deal with high-impact issues—from optimizing world provide chains to enabling real-time video analytics and multilingual search. You’ll find Pranav on LinkedIn.
Pranav Murthy is a Senior Generative AI Information Scientist at AWS, specializing in serving to organizations innovate with Generative AI, Deep Studying, and Machine Studying on Amazon SageMaker AI. Over the previous 10+ years, he has developed and scaled superior pc imaginative and prescient (CV) and pure language processing (NLP) fashions to deal with high-impact issues—from optimizing world provide chains to enabling real-time video analytics and multilingual search. You’ll find Pranav on LinkedIn.



{kind=link}