Clever doc processing (IDP) is a know-how to automate the extraction, evaluation, and interpretation of essential data from a variety of paperwork. By utilizing superior machine studying (ML) and pure language processing algorithms, IDP options can effectively extract and course of structured knowledge from unstructured textual content, streamlining document-centric workflows.
When enhanced with generative AI capabilities, IDP allows organizations to remodel doc workflows via superior understanding, structured knowledge extraction, and automatic classification. Generative AI-powered IDP options can higher deal with the number of paperwork that conventional ML fashions may not have seen earlier than. This know-how mixture is impactful throughout a number of industries, together with little one help companies, insurance coverage, healthcare, monetary companies, and the general public sector. Conventional guide processing creates bottlenecks and will increase error threat, however by implementing these superior options, organizations can dramatically improve their doc workflow effectivity and knowledge retrieval capabilities. AI-enhanced IDP options enhance service supply whereas decreasing administrative burden throughout various doc processing situations.
This method to doc processing gives scalable, environment friendly, and high-value doc processing that results in improved productiveness, decreased prices, and enhanced decision-making. Enterprises that embrace the ability of IDP augmented with generative AI can profit from elevated effectivity, enhanced buyer experiences, and accelerated development.
Within the weblog publish Scalable clever doc processing utilizing Amazon Bedrock, we demonstrated easy methods to construct a scalable IDP pipeline utilizing Anthropic basis fashions on Amazon Bedrock. Though that method delivered sturdy efficiency, the introduction of Amazon Bedrock Information Automation brings a brand new degree of effectivity and suppleness to IDP options. This publish explores how Amazon Bedrock Information Automation enhances doc processing capabilities and streamlines the automation journey.
Advantages of Amazon Bedrock Information Automation
Amazon Bedrock Information Automation introduces a number of options that considerably enhance the scalability and accuracy of IDP options:
- Confidence scores and bounding field knowledge – Amazon Bedrock Information Automation gives confidence scores and bounding field knowledge, enhancing knowledge explainability and transparency. With these options, you may assess the reliability of extracted data, leading to extra knowledgeable decision-making. For example, low confidence scores can sign the necessity for added human evaluate or verification of particular knowledge fields.
- Blueprints for speedy improvement – Amazon Bedrock Information Automation gives pre-built blueprints that simplify the creation of doc processing pipelines, serving to you develop and deploy options shortly. Amazon Bedrock Information Automation gives versatile output configurations to satisfy various doc processing necessities. For easy extraction use instances (OCR and format) or for a linearized output of the textual content in paperwork, you should use commonplace output. For personalized output, you can begin from scratch to design a novel extraction schema, or use preconfigured blueprints from our catalog as a place to begin. You’ll be able to customise your blueprint primarily based in your particular doc sorts and enterprise necessities for extra focused and correct data retrieval.
- Computerized classification help – Amazon Bedrock Information Automation splits and matches paperwork to acceptable blueprints, leading to exact doc categorization. This clever routing alleviates the necessity for guide doc sorting, drastically decreasing human intervention and accelerating processing time.
- Normalization – Amazon Bedrock Information Automation addresses a standard IDP problem via its complete normalization framework, which handles each key normalization (mapping numerous area labels to standardized names) and worth normalization (changing extracted knowledge into constant codecs, models, and knowledge sorts). This normalization method helps cut back knowledge processing complexities, so organizations can routinely remodel uncooked doc extractions into standardized knowledge that integrates extra easily with their present programs and workflows.
- Transformation – The Amazon Bedrock Information Automation transformation function converts complicated doc fields into structured, business-ready knowledge by routinely splitting mixed data (similar to addresses or names) into discrete, significant parts. This functionality simplifies how organizations deal with diverse doc codecs, serving to groups outline customized knowledge sorts and area relationships that match their present database schemas and enterprise functions.
- Validation – Amazon Bedrock Information Automation enhances doc processing accuracy by utilizing automated validation guidelines for extracted knowledge, supporting numeric ranges, date codecs, string patterns, and cross-field checks. This validation framework helps organizations routinely establish knowledge high quality points, set off human critiques when wanted, and ensure extracted data meets particular enterprise guidelines and compliance necessities earlier than coming into downstream programs.
Answer overview
The next diagram exhibits a totally serverless structure that makes use of Amazon Bedrock Information Automation together with AWS Step Capabilities and Amazon Augmented AI (Amazon A2I) to offer cost-effective scaling for doc processing workloads of various sizes.
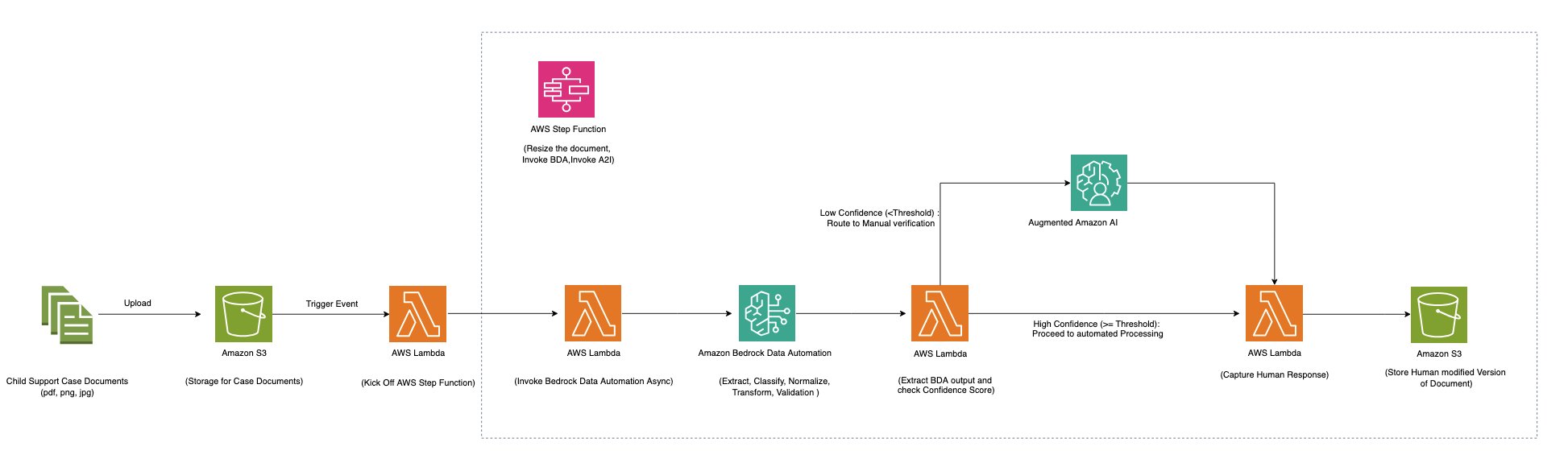
The Step Capabilities workflow processes a number of doc sorts together with multipage PDFs and pictures utilizing Amazon Bedrock Information Automation. It makes use of numerous Amazon Bedrock Information Automation blueprints (each commonplace and customized) inside a single mission to allow processing of various doc sorts similar to immunization paperwork, conveyance tax certificates, little one help companies enrollment types, and driver licenses.
The workflow processes a file (PDF, JPG, PNG, TIFF, DOC, DOCX) containing a single doc or a number of paperwork via the next steps:
- For multi-page paperwork, splits alongside logical doc boundaries
- Matches every doc to the suitable blueprint
- Applies the blueprint’s particular extraction directions to retrieve data from every doc
- Carry out normalization, Transformation and validation on extracted knowledge in keeping with the instruction laid out in blueprint
The Step Capabilities Map state is used to course of every doc. If a doc meets the arrogance threshold, the output is shipped to an Amazon Easy Storage Service (Amazon S3) bucket. If any extracted knowledge falls under the arrogance threshold, the doc is shipped to Amazon A2I for human evaluate. Reviewers use the Amazon A2I UI with bounding field highlighting for chosen fields to confirm the extraction outcomes. When the human evaluate is full, the callback activity token is used to renew the state machine and human-reviewed output is shipped to an S3 bucket.
To deploy this resolution in an AWS account, comply with the steps offered within the accompanying GitHub repository.
Within the following sections, we evaluate the precise Amazon Bedrock Information Automation options deployed utilizing this resolution, utilizing the instance of a kid help enrollment kind.
Automated Classification
In our implementation, we outline the doc class title for every customized blueprint created, as illustrated within the following screenshot. When processing a number of doc sorts, similar to driver’s licenses and little one help enrollment types, the system routinely applies the suitable blueprint primarily based on content material evaluation, ensuring the proper extraction logic is used for every doc kind.

Information Normalization
We use knowledge normalization to ensure downstream programs obtain uniformly formatted knowledge. We use each express extractions (for clearly said data seen within the doc) and implicit extractions (for data that wants transformation). For instance, as proven within the following screenshot, dates of delivery are standardized to YYYY-MM-DD format.

Equally, format of Social Safety Numbers is modified to XXX-XX-XXXX.
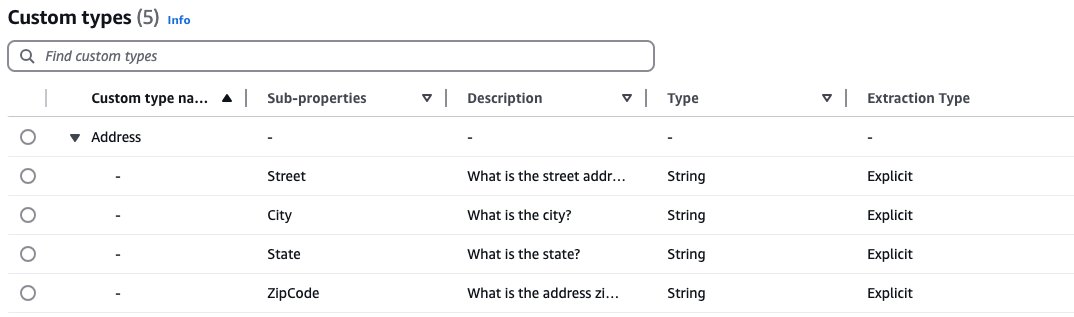
Information Transformation
For the kid help enrollment software, we’ve applied customized knowledge transformations to align extracted knowledge with particular necessities. One instance is our customized knowledge kind for addresses, which breaks down single-line addresses into structured fields (Road, Metropolis, State, ZipCode). These structured fields are reused throughout totally different handle fields within the enrollment kind (employer handle, house handle, different father or mother handle), leading to constant formatting and easy integration with present programs.
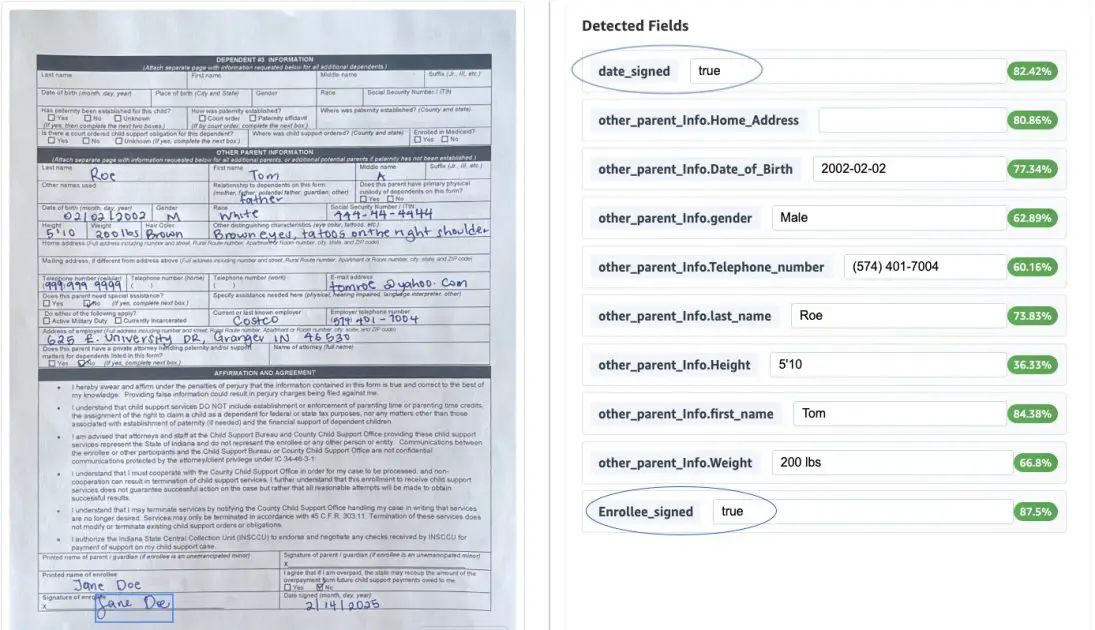
Information Validation
Our implementation contains validation guidelines for sustaining knowledge accuracy and compliance. For our instance use case, we’ve applied two validations: 1. confirm the presence of the enrollee’s signature and a couple of. confirm that the signed date isn’t sooner or later.

The next screenshot exhibits the results of the above validation guidelines utilized to the doc.
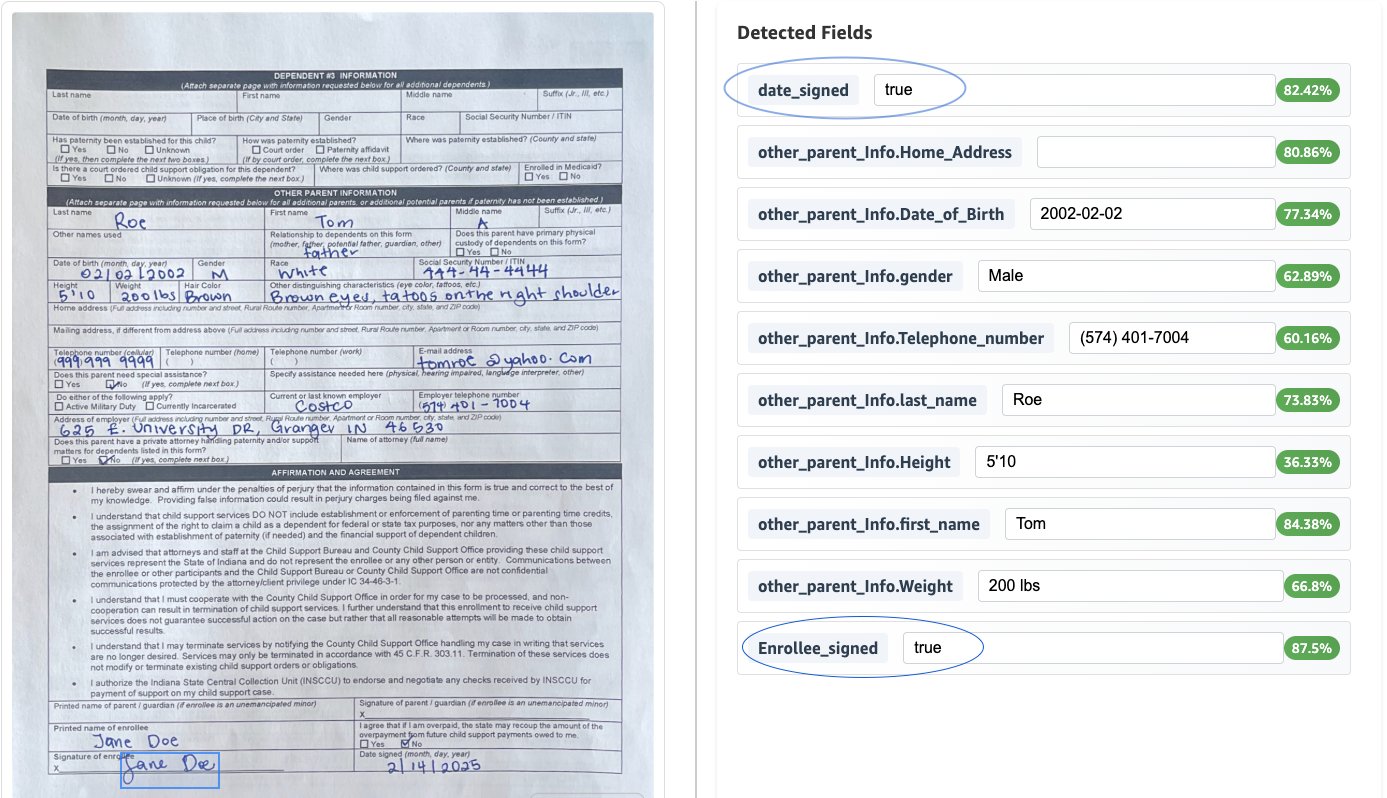
Human-in-the-loop validation
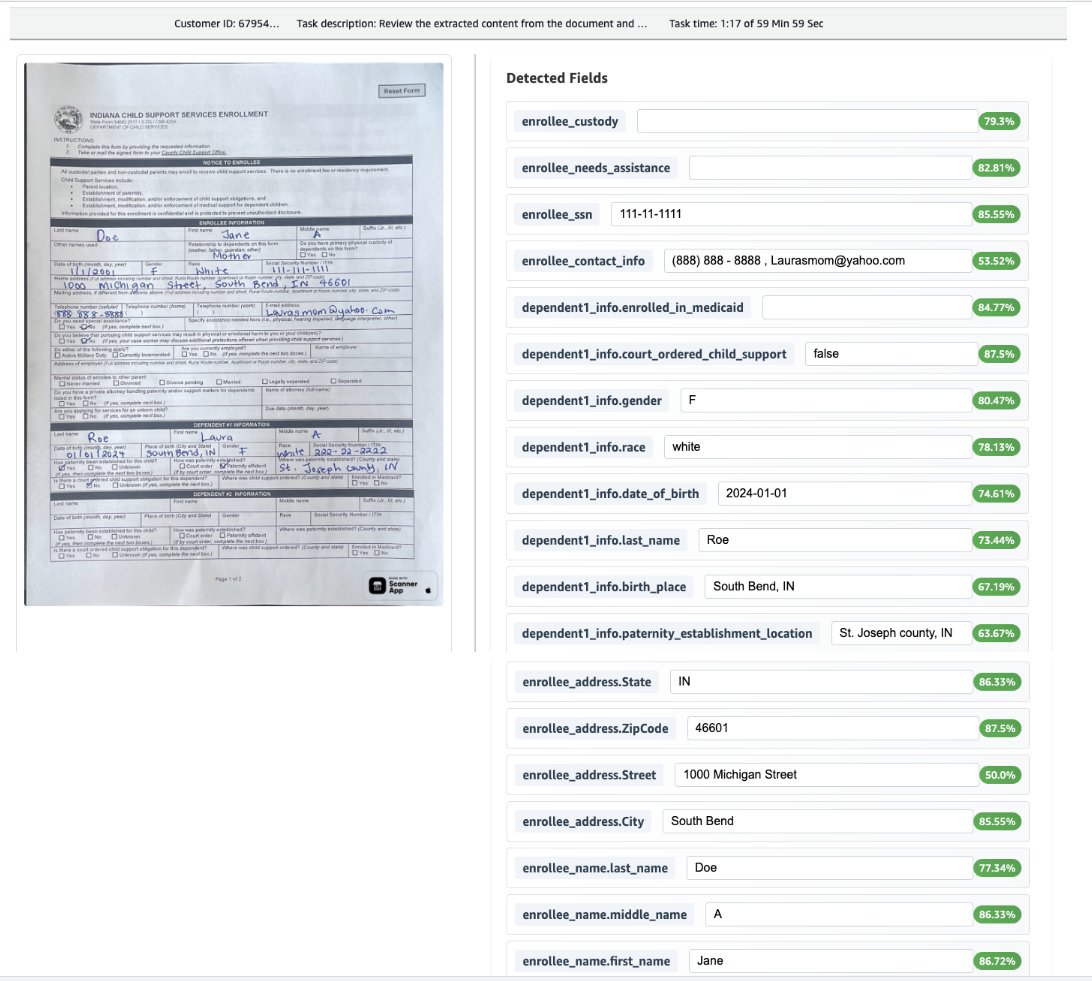
The next screenshot illustrates the extraction course of, which features a confidence rating and is built-in with a human-in-the-loop course of. It additionally exhibits normalization utilized to the date of delivery format.
Conclusion
Amazon Bedrock Information Automation considerably advances IDP by introducing confidence scoring, bounding field knowledge, automated classification, and speedy improvement via blueprints. On this publish, we demonstrated easy methods to make the most of its superior capabilities for knowledge normalization, transformation, and validation. By upgrading to Amazon Bedrock Information Automation, organizations can considerably cut back improvement time, enhance knowledge high quality, and create extra sturdy, scalable IDP options that combine with human evaluate processes.
Comply with the AWS Machine Studying Weblog to maintain updated with new capabilities and use instances for Amazon Bedrock.
Concerning the authors
 Abdul Navaz is a Senior Options Architect within the Amazon Net Providers (AWS) Well being and Human Providers crew, primarily based in Dallas, Texas. With over 10 years of expertise at AWS, he focuses on modernization options for little one help and little one welfare companies utilizing AWS companies. Previous to his function as a Options Architect, Navaz labored as a Senior Cloud Help Engineer, specializing in networking options.
Abdul Navaz is a Senior Options Architect within the Amazon Net Providers (AWS) Well being and Human Providers crew, primarily based in Dallas, Texas. With over 10 years of expertise at AWS, he focuses on modernization options for little one help and little one welfare companies utilizing AWS companies. Previous to his function as a Options Architect, Navaz labored as a Senior Cloud Help Engineer, specializing in networking options.
 Venkata Kampana is a senior options architect within the Amazon Net Providers (AWS) Well being and Human Providers crew and is predicated in Sacramento, Calif. On this function, he helps public sector prospects obtain their mission aims with well-architected options on AWS.
Venkata Kampana is a senior options architect within the Amazon Net Providers (AWS) Well being and Human Providers crew and is predicated in Sacramento, Calif. On this function, he helps public sector prospects obtain their mission aims with well-architected options on AWS.
 Sanjeev Pulapaka is principal options architect and AI lead for public sector. Sanjeev is a printed writer with a number of blogs and a e book on generative AI. He’s additionally a well known speaker at a number of occasions together with re:Invent and Summit. Sanjeev has an undergraduate diploma in engineering from the Indian Institute of Expertise and an MBA from the College of Notre Dame.
Sanjeev Pulapaka is principal options architect and AI lead for public sector. Sanjeev is a printed writer with a number of blogs and a e book on generative AI. He’s additionally a well known speaker at a number of occasions together with re:Invent and Summit. Sanjeev has an undergraduate diploma in engineering from the Indian Institute of Expertise and an MBA from the College of Notre Dame.



{kind=link}