
The fast development of synthetic intelligence (AI) has created unprecedented demand for specialised fashions able to advanced reasoning duties, significantly in aggressive programming the place fashions should generate useful code via algorithmic reasoning fairly than sample memorization. Reinforcement studying (RL) permits fashions to study via trial and error by receiving rewards based mostly on precise code execution, making it significantly well-suited for creating real problem-solving capabilities in algorithmic domains.
Nevertheless, implementing distributed RL coaching for code technology presents vital infrastructure challenges similar to orchestrating a number of heterogeneous elements, coordinating parallel code compilation throughout nodes, and sustaining fault tolerance for long-running processes. Ray is likely one of the frameworks for distributed workloads that deal with these challenges, as a result of its unified system that handles your entire AI pipeline, GPU-first structure, and seamless integration with instruments like Hugging Face Transformers and PyTorch.
Workloads may be run with Ray framework on SageMaker coaching jobs by utilizing the Ray on Amazon SageMaker Coaching jobs answer, which mixes Ray’s distributed computing framework with SageMaker’s absolutely managed infrastructure. This answer routinely handles Ray cluster initialization, multi-node coordination, and distributed useful resource administration, enabling builders to deal with mannequin growth whereas benefiting from SageMaker’s enterprise-grade options.
On this submit, we show methods to practice CodeFu-7B, a specialised 7-billion parameter mannequin for aggressive programming, utilizing Group Relative Coverage Optimization (GRPO) with veRL, a versatile and environment friendly coaching library for big language fashions (LLMs) that permits simple extension of numerous RL algorithms and seamless integration with present LLM infrastructure, inside a distributed Ray cluster managed by SageMaker coaching jobs. We stroll via the whole implementation, overlaying information preparation, distributed coaching setup, and complete observability, showcasing how this unified method delivers each computational scale and developer expertise for classy RL coaching workloads.
About CodeFu-7B
CodeFu-7B-v0.1 is a 7B parameter language mannequin particularly educated for fixing Aggressive Programming (CP) issues. Constructed upon the DeepSeek-R1-Distill-Qwen-7B base mannequin, CodeFu demonstrates how reinforcement studying can develop capabilities in algorithmic reasoning and environment friendly C++ code technology past conventional supervised fine-tuning approaches.
The mannequin is educated utilizing downside statements from the DeepMind CodeContest dataset with out entry to ground-truth options throughout coaching, forcing it to study via trial and error based mostly on code execution suggestions. This method permits the event of real problem-solving capabilities fairly than sample memorization
CodeFu is publicly out there on HuggingFace and launched below the MIT license, making it accessible for researchers and practitioners interested by code technology and algorithmic reasoning. The mannequin’s coaching methodology demonstrates the potential for making use of reinforcement studying strategies to advanced reasoning duties past aggressive programming.
Ray in SageMaker coaching jobs answer
Ray on Amazon SageMaker Coaching jobs is an answer that permits distributed information processing and mannequin coaching utilizing Ray inside SageMaker’s managed coaching setting. The answer gives key capabilities together with common launcher structure for automated Ray cluster setup, multi-node cluster administration with clever coordination, heterogeneous cluster assist for combined occasion sorts, and built-in observability via Ray Dashboard, Prometheus, Grafana, and Amazon CloudWatch integration.
The answer seamlessly integrates with the SageMaker Python SDK utilizing the fashionable ModelTrainer API. This publicly out there answer on GitHub permits builders to make use of Ray’s distributed computing capabilities whereas benefiting from SageMaker’s managed infrastructure, making it ultimate for advanced workloads like reinforcement studying coaching that require refined distributed coordination and useful resource administration.
Resolution overview
The workflow for coaching CodeFu 7B with veRL and Ray on SageMaker coaching jobs, as illustrated within the accompanying diagram, consists of the next steps:
- Knowledge preparation: Add the preprocessed DeepMind CodeContest dataset and coaching configuration.
- Coaching job submission: Submit a SageMaker coaching job API request via the ModelTrainer class from the SageMaker Python SDK.
- Monitoring and observability: Monitor coaching progress in real-time via Ray Dashboard, and optionally with Prometheus metrics assortment, Grafana visualization, and experiment monitoring.
- Automated cleanup: Upon coaching completion, SageMaker routinely saves the educated mannequin to S3, uploads coaching logs to CloudWatch, and decommissions the compute cluster.

This streamlined structure delivers a totally managed reinforcement studying coaching expertise, enabling builders to deal with mannequin growth whereas SageMaker and Ray deal with the advanced distributed infrastructure orchestration—inside a pay-as-you-go pricing mannequin that payments just for precise compute time.
Conditions
The next conditions should be full earlier than the pocket book may be run:
- Make the next quota improve requests for SageMaker AI. For this use case, request a minimal of two
p4de.24xlargesituations (with 8 x NVIDIA A100 GPUs) and scale to extrap4de.24xlargesituations (relying on time-to-train and cost-to-train trade-offs on your use case). P5 situations (with 8 x NVIDIA H100 GPUs) are additionally supported. On the Service Quotas console, request the next SageMaker AI quotas:- p4de situations (
p4de.24xlarge) for coaching job utilization: 2
- p4de situations (
- Create an AWS Id and Entry Administration (IAM) function with managed insurance policies
AmazonSageMakerFullAccess,AmazonS3FullAccess,AmazonSSMFullAccessto offer required entry to SageMaker AI to run the examples. - Assign the next coverage because the belief relationship to created IAM function:
- (Non-obligatory) Create an Amazon SageMaker Studio area (confer with Use fast setup for Amazon SageMaker AI) to entry Jupyter notebooks for operating the coaching code. Alternatively, JupyterLab can be utilized in an area setup or one other Python growth setting to execute the pocket book and submit the SageMaker coaching job.
Notice: These permissions grant broad entry and are usually not beneficial to be used in manufacturing environments. See the SageMaker Developer Information for steering on defining extra fine-grained permissions
The code instance may be discovered at this GitHub repository.
Put together the dataset
The information preparation pipeline transforms the uncooked DeepMind CodeContest dataset right into a format appropriate for reinforcement studying coaching. We apply systematic filters to determine appropriate issues, eradicating these with Codeforces scores under 800 and implementing high quality validation checks for lacking take a look at circumstances, malformed descriptions, and invalid constraints.
We categorize issues into three issue tiers: Straightforward (800-1000 factors), Exhausting (1100-2200 factors), and Knowledgeable (2300-3500 factors). This submit makes use of solely the Straightforward dataset for coaching. Every downside is formatted with two elements: a person immediate containing the issue assertion, and a reward_model specification with take a look at circumstances, deadlines, and reminiscence constraints. Crucially, the ground_truth discipline incorporates no answer code — solely take a look at circumstances, forcing the mannequin to study via reward alerts fairly than memorizing options.
For this submit, we offer a pre-processed subset of the Straightforward issue dataset within the code pattern to streamline the coaching instance, accessible from the GitHub repository.
GRPO coaching utilizing veRL
The coaching course of makes use of Ray to orchestrate the distributed execution and synchronization of vLLM rollout, reward analysis (code compilation and execution), FSDP mannequin parallelism, and Ulysses sequence parallelism. We set the diploma of sequence parallelism to 4 for long-form reasoning and code generations.
The veRL framework implements a classy multi-component structure via its main_ppo.py orchestrator, which coordinates three major distributed employee sorts: ActorRolloutRefWorker for coverage inference and rollouts, CriticWorker for worth perform estimation, and RewardModelWorker for scoring generated options.
The GRPO algorithm enhances conventional proximal coverage optimization (PPO) by computing benefits utilizing group-relative baselines, which helps stabilize coaching by lowering variance in coverage gradient estimates.
We prolonged the TinyZero code repository by utilizing Ray to handle and distribute reward perform calculation. This permits parallel C++ code compilation and analysis throughout the identical cluster to handle the compute-intensive and latency-bound nature of code execution. All the pipeline is executed as a SageMaker coaching job operating on ml.p4de.24xlarge situations. The coaching pipeline consists of the next steps as proven within the following structure:
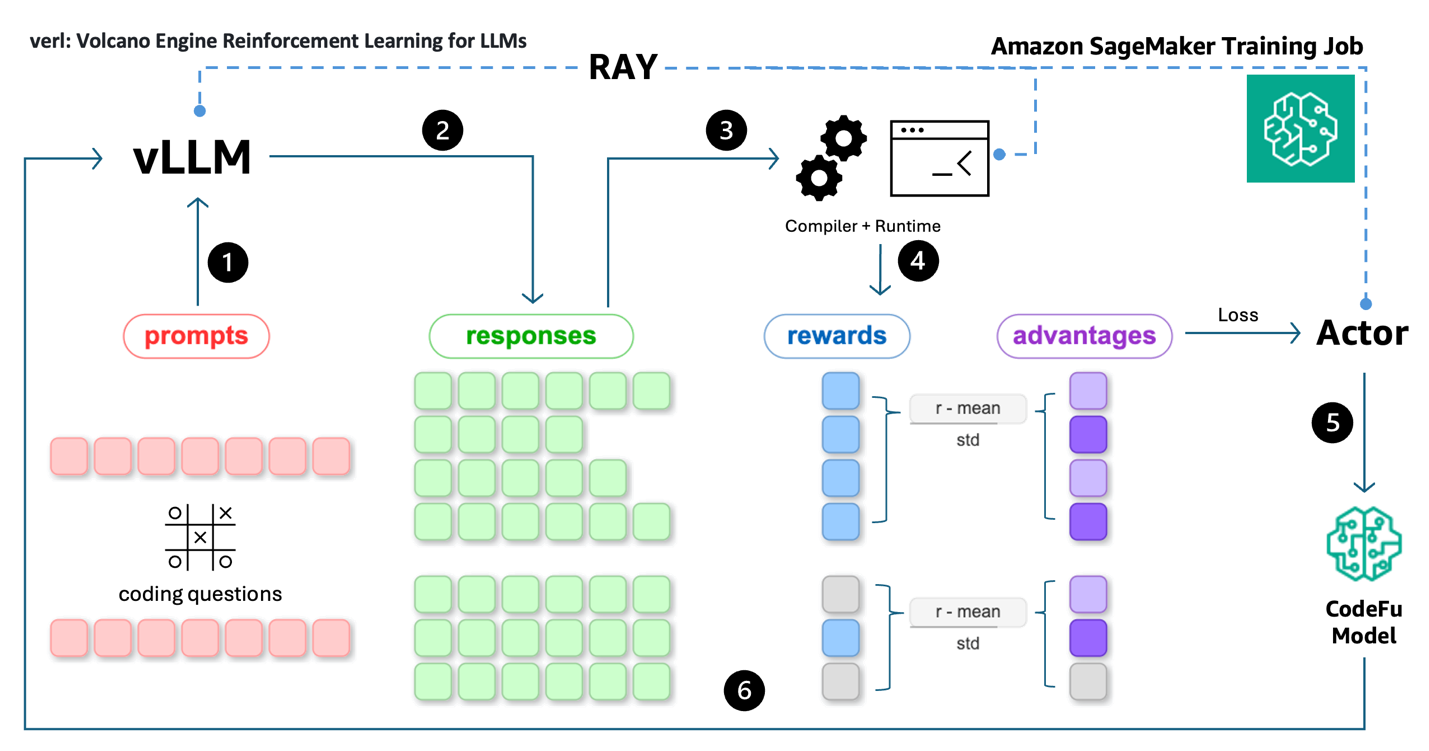
- Rollout: Coding downside prompts are fed into the vLLM inference engine for rolling out potential options.
- Response technology: vLLM generates a number of responses (reasoning + code) for every immediate.
- Code execution: Code options are extracted from responses and are compiled and executed by distributed employees (compilers and runtime) managed by Ray.
- Reward calculation: Execution outcomes are used to calculate rewards (i.e. testcase go ratios) and benefits are computed utilizing group-relative baselines.
- Coverage replace: The Actor makes use of benefits and token chances to compute the PPO loss, which is used to replace CodeFu’s parameters via gradient descent.
- Iteration: The method repeats with batches of prompt-response-reward cycles, with Ray managing the distributed sampling, execution, and coaching synchronization throughout the pipeline.
The coaching course of orchestration entails a number of key elements carried out throughout a number of modules. The core veRL coaching loop is carried out in main_ppo.py, which initializes Ray employees and manages the distributed coaching course of:
The reward analysis system implements parallel code execution via Ray distant features, dealing with C++ compilation and take a look at case execution:
The parallel take a look at case execution system optimizes analysis effectivity by sampling take a look at circumstances and utilizing course of swimming pools:
This implementation permits environment friendly distributed coaching by separating issues: the main_ppo.py orchestrator manages Ray employee coordination, whereas the reward system gives scalable code analysis via parallel compilation and execution throughout the SageMaker cluster.
Beneath is the pseudocode for the reward calculation used on this submit to coach a aggressive programming coding mannequin. The reward perform is crucial a part of reinforcement studying because it defines what the mannequin is inspired to attain and what it ought to keep away from. This implementation makes use of a hierarchical penalty system that first checks for elementary code execution points, assigning extreme penalties for non-executable code (-1) and average penalties for compilation failures (-0.5). Extracted code options are executed with strict time restrict enforcement – code exceeding the issue’s specified time restrict is given zero reward, facilitating sensible aggressive programming circumstances. For a efficiently executed C++ answer, its reward is calculated as a linear perform based mostly on the fraction of personal take a look at circumstances handed, encouraging the mannequin to resolve as many personal take a look at circumstances as potential whereas avoiding overfitting to publicly seen exams. This design prioritizes code correctness and execution validity, with the personal take a look at efficiency serving as the only real sign for studying optimum coding options.
Seek advice from scripts/verl/utils/reward_score/code_contests.py for the whole Python code. Executing generated code in manufacturing environments requires applicable sandboxing. On this managed demonstration setting, we execute the code as a fast instance to guage its correctness to assign rewards.
Ray workload with SageMaker coaching jobs
To coach CodeFu-7B utilizing veRL and Ray on SageMaker coaching jobs, we use the ModelTrainer class from the SageMaker Python SDK. Begin by establishing the distributed coaching workload with the next steps:
- Choose the occasion sort and container picture for the coaching job:
The coaching makes use of a customized Docker container that features veRL, Ray, and the required dependencies for distributed RL coaching. Seek advice from the GitHub repository for the whole container definition and construct directions.
- Create the ModelTrainer to encapsulate the Ray-based coaching setup:
The ModelTrainer class gives versatile execution choices via its SourceCode configuration, permitting customers to customise their coaching workflows with completely different frameworks and launchers. Specify both an entry_script for direct Python script execution or use the command parameter for customized execution instructions, enabling integration with specialised frameworks similar to Ray, Hugging Face Speed up, or customized distributed coaching options.
The launcher.py script serves because the common entry level that detects the SageMaker setting (single-node or multi-node, homogeneous or heterogeneous cluster), initializes the Ray cluster with correct head/employee node coordination, and executes your customized coaching script. Key launcher.py functionalities are:
- Ray cluster setup: Robotically detects the cluster setting and initializes Ray with correct head node choice.
- Node coordination: Manages communication between head and employee nodes throughout SageMaker situations.
- Script execution: Executes the desired
--entrypointscript (practice.py) throughout the Ray cluster context. - Prometheus and grafana connectivity: Configures Ray to export metrics and establishes connection to exterior Prometheus and Grafana servers specified by
RAY_PROMETHEUS_HOSTandRAY_GRAFANA_HOSTfor complete cluster monitoring. For added info, confer with Ray on SageMaker coaching jobs – Observability with Prometheus and Grafana.
For the whole implementation of the Ray cluster setup with SageMaker coaching jobs, confer with launcher.py.
The practice.py script serves because the precise coaching orchestrator that:
- Hundreds the veRL configuration from the offered YAML file
- Units up the distributed coaching setting with correct tokenizer and mannequin initialization
- Constructs and executes the veRL coaching command with the required parameters
- Handles setting variable configuration for Ray employees and NVIDIA Collective Communications Library (NCCL) communication
- Manages the whole coaching lifecycle from information loading to mannequin checkpointing
For the whole implementation of the entry level script, confer with practice.py.
- Arrange the enter channels for the ModelTrainer by creating
InputDataobjects from the S3 bucket paths:
- Submit the coaching job utilizing the practice perform name on the created ModelTrainer:
The job may be monitored straight from the pocket book output or via the SageMaker console, which exhibits the job standing and corresponding CloudWatch logs.
SageMaker coaching jobs console
SageMaker coaching jobs system metrics
The launcher.py script orchestrates the Ray cluster initialization via the next automated steps, which may be monitored in real-time via CloudWatch logs:
- Setup SageMaker coaching jobs and Ray setting variables: Configures essential setting variables for each SageMaker integration and Ray cluster communication:
- Establish the SageMaker coaching job cluster sort: Detects whether or not the deployment is single-node or multi-node, and determines a single or multi-node cluster, and if it’s a homogeneous or heterogeneous cluster configuration:
- Setup head and employee nodes: Identifies which occasion serves because the Ray head node and configures the remaining situations as employee nodes:
- Begin Ray node: Initializes the Ray head node and employee nodes with applicable useful resource allocation and dashboard configuration, by verifying that the employee nodes efficiently connect with the pinnacle node earlier than continuing:
- Execute the coaching script: Launches the desired entrypoint script (practice.py) throughout the absolutely initialized Ray cluster context:
After the job completes, the educated mannequin weights and checkpoints can be out there within the specified S3 output path, prepared for deployment or additional analysis.
Experiment monitoring
The CodeFu coaching pipeline integrates seamlessly with Managed MLflow on Amazon SageMaker AI in addition to third get together options, for complete experiment monitoring and visualization of reinforcement studying metrics.
The next picture exhibits the metrics which can be significantly helpful to watch throughout CodeFu coaching.
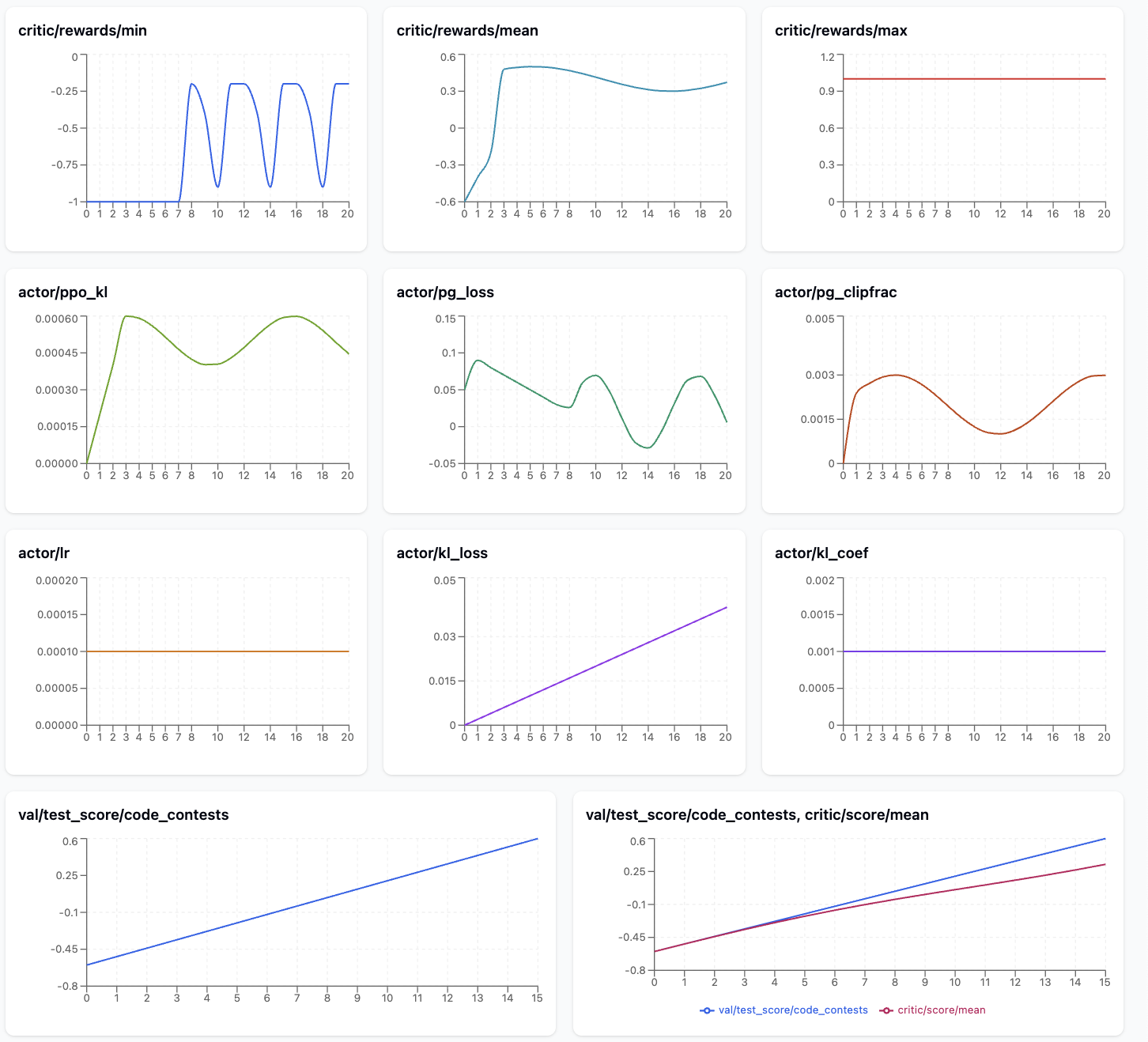
The metrics plot exhibits a promising GRPO/PPO studying development for the aggressive programming mannequin. The reward alerts show clear enchancment, with critic/reward/imply rising from -0.8 to 0.6 and critic/reward/min recovering from preliminary failures -1.0 to average efficiency -0.5, whereas critic/reward/max maintains good scores 1.0 all through coaching, indicating the mannequin can obtain optimum options.
The Actor metrics reveal wholesome coaching dynamics: actor/ppo_kl stays low ~0.0002 after an preliminary spike, confirming secure coverage updates, whereas actor/pg_clipfrac stays in an inexpensive vary ~0.002-0.004, suggesting appropriately sized studying steps.
The growing actor/kl_loss pattern signifies rising divergence from the reference mannequin as anticipated throughout RL fine-tuning. Most significantly, val/test_score/code_contests exhibits constant enchancment from -0.6 to ~0.5, and the train-validation comparability reveals good generalization with each curves monitoring carefully, indicating the mannequin is studying to resolve coding issues successfully with out overfitting.
The desk under explains key GRPO coaching metrics and why monitoring every one issues for diagnosing coaching well being and efficiency:
| Metric | Description | Goal |
| critic/reward/min | Minimal reward achieved on the coaching set | Detect catastrophic failures: Extraordinarily damaging rewards point out the mannequin is producing poor outputs that want consideration |
| critic/reward/imply | Common reward throughout the coaching set | Main progress indicator: Reveals general mannequin efficiency enchancment; ought to usually pattern upward throughout profitable coaching |
| critic/reward/max | Most reward achieved on the coaching set | Monitor best-case efficiency: Reveals the mannequin’s peak functionality; helps determine if the mannequin can obtain wonderful outcomes even when common is low |
| actor/ppo_kl | KL divergence between present and former coverage iteration | Coaching stability monitoring: Excessive values point out fast coverage modifications that will destabilize coaching; ought to keep average |
| actor/pg_clipfrac | Fraction of coverage updates hitting the clipping boundary | Replace aggressiveness gauge: Reasonable values point out wholesome studying; too excessive suggests overly aggressive updates that will destabilize coaching, too low (e.g. zero) suggests inefficient studying. That is legitimate solely throughout off-policy PPO updates. |
| actor/kl_loss | KL divergence between present coverage and stuck reference mannequin | Reference drift prevention: Helps stop the mannequin from deviating too removed from authentic conduct; vital for sustaining coding capabilities |
| val/test_score/code_contests | Reward/efficiency on held-out validation set | Generalization examine: Most vital metric for actual efficiency; detects overfitting and measures true mannequin enchancment |
(Non-obligatory) Observability with Ray dashboard and Grafana
To entry the Ray Dashboard and allow Grafana visualization throughout coaching, set up port forwarding utilizing AWS Methods Supervisor (SSM). To study extra in regards to the setup of AWS SSM, please confer with AWS Methods Supervisor Fast Setup.
- First, determine the pinnacle node in your multi-node cluster by inspecting the CloudWatch logs:
- Entry the Ray Dashboard by forwarding port 8265 from the pinnacle node:
- Allow Grafana to gather Ray metrics by forwarding port 8080 (Ray metrics export port):
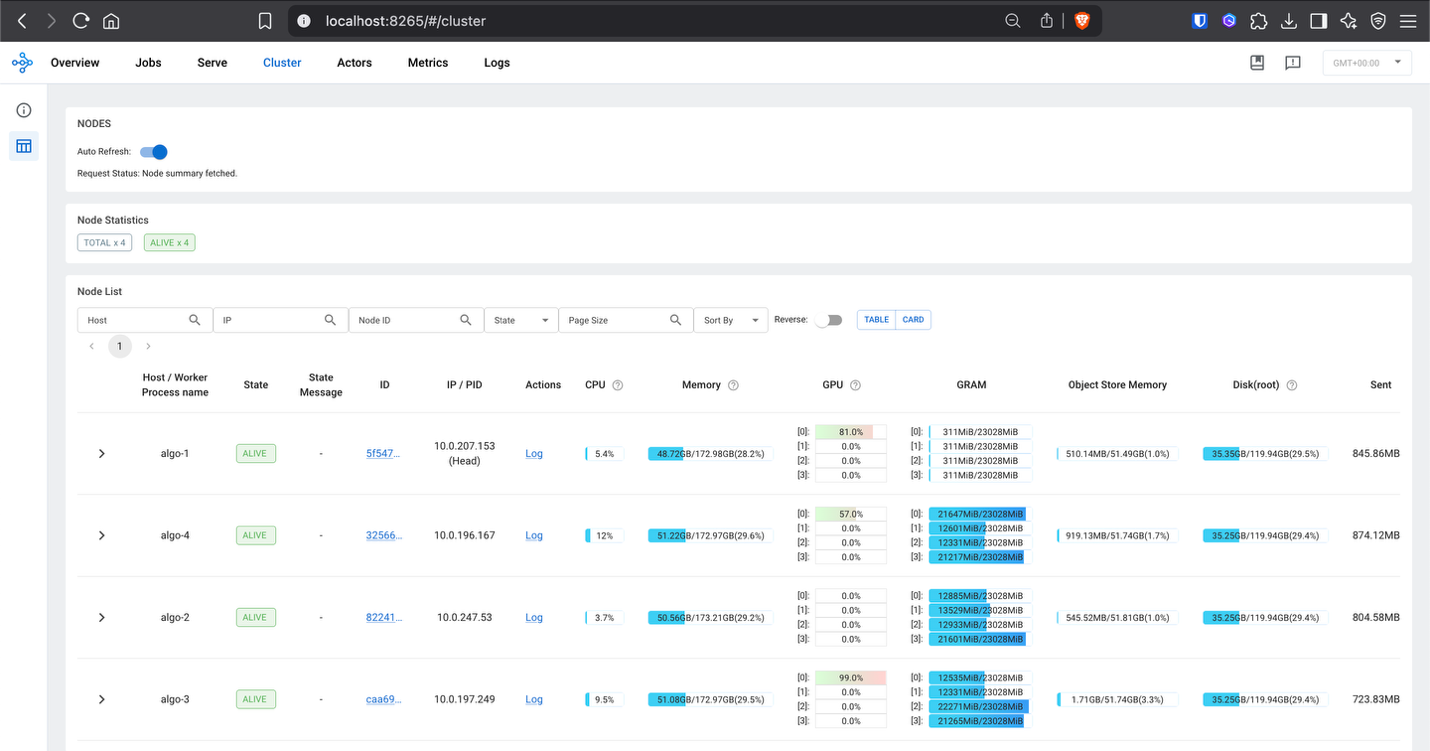
As soon as port forwarding is established, the Ray Dashboard may be accessed at localhost:8265 in your browser, offering detailed insights into:
- Employee utilization throughout the distributed cluster
- Process execution standing and efficiency metrics
- Useful resource consumption together with GPU and reminiscence utilization
- Actor and process scheduling throughout Ray employees
The built-in Grafana dashboards present complete visualization of the coaching metrics, system efficiency, and cluster well being in real-time:
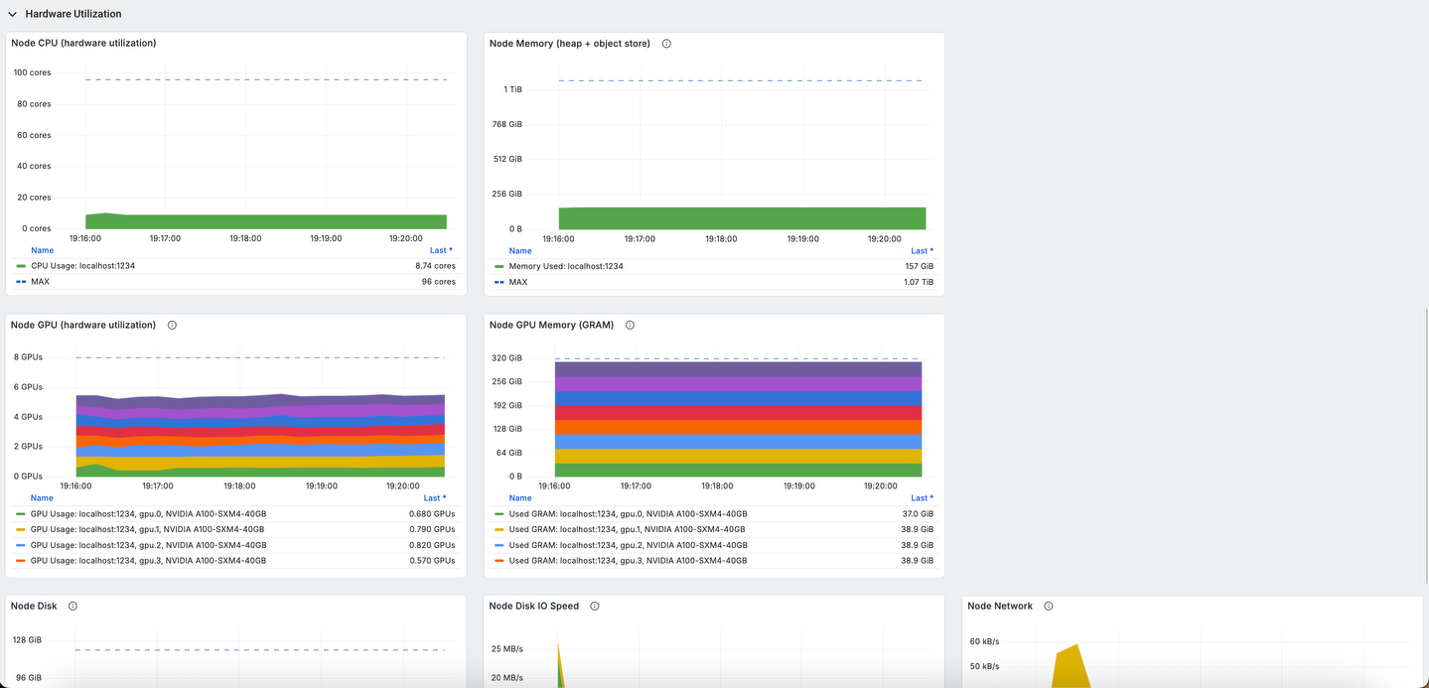
This observability setup is essential for debugging distributed RL coaching points, optimizing useful resource allocation, and ensuring the coaching course of progresses effectively throughout the multi-node SageMaker cluster.
Clear up
To scrub up your sources and keep away from ongoing expenses, observe these steps:
- Delete unused SageMaker Studio sources
- (Non-obligatory) Delete the SageMaker Studio area
- On the SageMaker console, select Coaching within the navigation pane and confirm that your coaching job isn’t operating anymore.
Conclusions
This submit demonstrates methods to practice specialised reasoning fashions for aggressive programming utilizing the Ray on Amazon SageMaker Coaching jobs answer mixed with veRL’s reinforcement studying framework.
The Ray on SageMaker coaching jobs answer simplifies the complexity of orchestrating distributed RL workloads by routinely dealing with Ray cluster initialization, multi-node coordination, and useful resource administration throughout heterogeneous compute environments. This integration permits organizations to make use of Ray’s superior distributed computing capabilities—together with assist for advanced multi-component architectures, dynamic useful resource allocation, and fault-tolerant execution—whereas benefiting from SageMaker’s absolutely managed infrastructure, enterprise-grade safety, and pay-as-you-go pricing mannequin.
The detailed metrics evaluation demonstrated methods to monitor coaching well being via reward development, coverage stability indicators, and generalization efficiency, enabling practitioners to determine optimum coaching configurations and troubleshoot distributed coaching points successfully.
To start implementing distributed RL coaching with Ray on SageMaker, go to the Ray on Amazon SageMaker Coaching jobs GitHub repository for the foundational answer framework. The whole CodeFu-7B coaching implementation, together with veRL integration and configuration examples, is on the market at this GitHub repository.
Concerning the authors



{kind=link}