Selecting the best giant language mannequin (LLM) on your use case is changing into each more and more difficult and important. Many groups depend on one-time (advert hoc) evaluations based mostly on restricted samples from trending fashions, basically judging high quality on “vibes” alone.
This strategy includes experimenting with a mannequin’s responses and forming subjective opinions about its efficiency. Nonetheless, counting on these casual assessments of mannequin output is dangerous and unscalable, typically misses delicate errors, overlooks unsafe habits, and supplies no clear standards for enchancment.
A extra holistic strategy entails evaluating the mannequin based mostly on metrics round qualitative and quantitative features, resembling high quality of response, price, and efficiency. This additionally requires the analysis system to check fashions based mostly on these predefined metrics and provides a complete output evaluating fashions throughout all these areas. Nonetheless, these evaluations don’t scale successfully sufficient to assist organizations take full benefit of the mannequin decisions accessible.
On this put up, we talk about an strategy that may information you to construct complete and empirically pushed evaluations that may enable you make higher selections when choosing the best mannequin on your job.
From vibes to metrics and why it issues
Human brains excel at pattern-matching, and fashions are designed to be convincing. Though a vibes-based strategy can function a place to begin, with out systematic analysis, we lack the proof wanted to belief a mannequin in manufacturing. This limitation makes it tough to check fashions pretty or determine particular areas for enchancment.
The restrictions of “simply attempting it out” embody:
- Subjective bias – Human testers may favor responses based mostly on fashion or tone moderately than factual accuracy. Customers may be swayed by “unique phrases” or formatting. A mannequin whose writing sounds assured may win on vibes whereas truly introducing inaccuracies.
- Lack of protection – A number of interactive prompts received’t cowl the breadth of real-world inputs, typically lacking edge instances that reveal mannequin weaknesses.
- Inconsistency – With out outlined metrics, evaluators may disagree on why one mannequin is healthier based mostly on completely different priorities (brevity vs. factual element), making it tough to align mannequin alternative with enterprise objectives.
- No trackable benchmarks – With out quantitative metrics, it’s inconceivable to trace accuracy degradation throughout immediate optimization or mannequin modifications.
Established benchmarks like MMLU, HellaSwag, and HELM provide useful standardized assessments throughout reasoning, information retrieval, and factuality dimensions, effectively serving to slender down candidate fashions with out intensive inner sources.
Nonetheless, unique reliance on these benchmarks is problematic: they measure generalized moderately than domain-specific efficiency, prioritize simply quantifiable metrics over business-critical capabilities, and might’t account on your group’s distinctive constraints round latency, prices, and security necessities. A high-ranking mannequin may excel at trivia whereas failing together with your business terminology or producing responses too verbose or expensive on your particular implementation.
A strong analysis framework is significant for constructing belief, which is why no single metric can seize what makes an LLM response “good.” As a substitute, you could consider throughout a number of dimensions:
- Accuracy – Does the mannequin produce correct info? Does it totally reply the query or cowl required factors? Is the response on-topic, contextually related, well-structured, and logically coherent?
- Latency – How briskly does the mannequin produce a response? For interactive purposes, response time straight impacts consumer expertise.
- Price-efficiency – What’s the financial price per API name or token? Totally different fashions have various pricing buildings and infrastructure prices.
By evaluating alongside these aspects, you can also make knowledgeable selections aligned with product necessities. For instance, if robustness below adversarial inputs is essential, a barely slower however extra aligned mannequin could be preferable. For easy inner duties, buying and selling some accuracy for cost-efficiency may make sense.
Though many metrics require qualitative judgment, you’ll be able to construction and quantify these with cautious analysis strategies. Trade finest practices mix quantitative metrics with human or AI raters for subjective standards, transferring from “I like this reply extra” to “Mannequin A scored 4/5 on correctness and 5/5 on completeness.” This element permits significant dialogue and enchancment, and technical managers ought to demand such accuracy measurements earlier than deploying any mannequin.
Distinctive analysis dimensions for LLM efficiency
On this put up, we make the case for structured, multi-metric evaluation of basis fashions (FMs) and talk about the significance of making floor fact as a prerequisite to mannequin analysis. We use the open supply 360-Eval framework as a sensible, code-first instrument to orchestrate rigorous evaluations throughout a number of fashions and cloud suppliers.
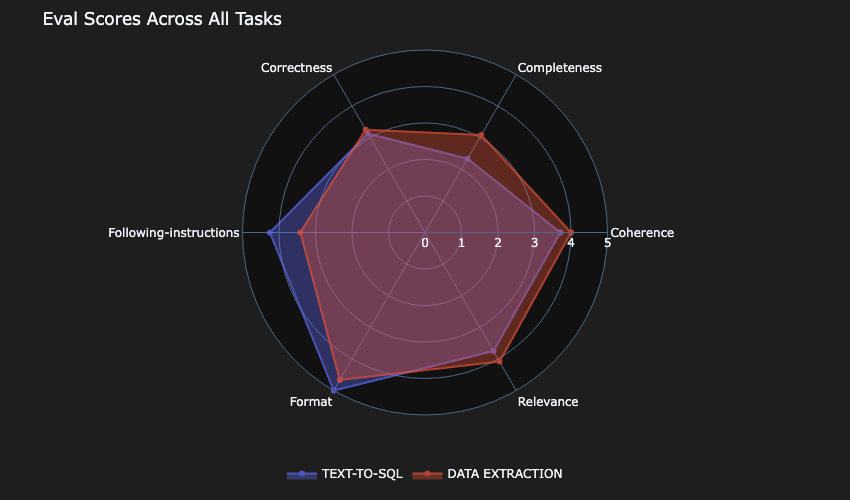
We present the strategy by evaluating 4 LLMs inside Amazon Bedrock, throughout a spectrum of correctness, completeness, relevance, format, coherence, and instruction following, to know how every mannequin responds matches our floor fact dataset. Our analysis measures the accuracy, latency, and price for every mannequin, portray a 360° image of their strengths and weaknesses.
To judge FMs, it’s extremely really useful that you simply break up mannequin efficiency into distinct dimensions. The next is a pattern set of standards and what every one measures:
- Correctness (accuracy) – The factual accuracy of the mannequin’s output. For duties with a identified reply, you’ll be able to measure this utilizing precise match or cosine similarity; for open-ended responses, you may depend on human or LLM judgment of factual consistency.
- Completeness – The extent to which the mannequin’s response addresses all elements of the question or drawback. In human/LLM evaluations, completeness is usually scored on a scale (did the reply partly handle or totally handle the question).
- Relevance – Measures if the content material of the response is on-topic and pertinent to the consumer’s request. Relevance scoring seems to be at how properly the response stays inside scope. Excessive relevance means the mannequin understood the question and stayed targeted on it.
- Coherence – The logical move and readability of the response. Coherence may be judged by human or LLM evaluators, or approximated with metrics like coherence scores or by checking discourse construction.
- Following directions – How properly the mannequin obeys specific directions within the immediate (formatting, fashion, size, and so forth). For instance, if requested “Listing three bullet-point benefits,” does the mannequin produce a three-item bullet checklist? If the system or consumer immediate units a task or tone, does the mannequin adhere to it? Instruction-following may be evaluated by programmatically checking if the output meets the desired standards (for instance, incorporates the required sections) or utilizing evaluator rankings.
Performing such complete evaluations manually may be extraordinarily time-consuming. Every mannequin must be run on many if not lots of of prompts, and every output have to be checked for throughout all metrics. Doing this by hand or writing one-off scripts is error-prone and doesn’t scale. In apply, these may be evaluated routinely utilizing LLM-as-a-judge or human suggestions. That is the place analysis frameworks come into play.
After you’ve chosen an analysis philosophy, it’s sensible to spend money on tooling to assist it. As a substitute of mixing advert hoc analysis scripts, you should utilize devoted frameworks to streamline the method of testing LLMs throughout many metrics and fashions.
Automating 360° mannequin analysis with 360-Eval
360-Eval is a light-weight resolution that captures the depth and breadth of mannequin analysis. You need to use it as an analysis orchestrator to outline the next:
- Your dataset of check prompts and respective golden solutions (anticipated solutions or reference outputs)
- Fashions you wish to consider
- The metrics and duties framework evaluating the fashions in opposition to
The instrument is designed to seize related and user-defined dimensions of mannequin efficiency in a single workflow, supporting multi-model comparisons out of the field. You may consider fashions hosted in Amazon Bedrock or Amazon SageMaker, or name exterior APIs—the framework is versatile in integrating completely different mannequin endpoints. That is splendid for a state of affairs the place you may wish to use the complete energy of Amazon Bedrock fashions with out having to sacrifice efficiency.
The framework consists of the next key parts:
- Information configuration – You specify your analysis dataset; for instance, a JSONL file of prompts with non-compulsory anticipated outputs, the duty, and an outline. The framework can even work with a customized immediate CSV dataset you present.
- API gateway – Utilizing the versatile LiteLLM framework, it abstracts the API variations so the analysis loop can deal with all fashions uniformly. Inference metadata resembling time-to-first-token (TTFT), time-to-last-token (TTLT), whole token output, API errors rely, and pricing can also be captured.
- Analysis structure – 360-Eval makes use of LLM-as-a-judge to attain and calculate the load of mannequin outputs on qualities like correctness or relevance. You may present all of the metrics you care about into one pipeline. Every analysis algorithm will produce a rating and verdict per check case per mannequin.
Selecting the best mannequin: An actual-world instance
For our instance use case, AnyCompany is growing an progressive software program as a service (SaaS) resolution that streamlines database structure for builders and companies. Their platform accepts pure language necessities as enter and makes use of LLMs to routinely generate PostgreSQL-specific knowledge fashions. Customers can describe their necessities in plain English—for instance, “I want a cloud-based order administration platform designed to streamline operations for small to medium companies”—and the instrument intelligently extracts the entity and attribute info and creates an optimized desk construction particularly for PostgreSQL. This resolution avoids hours of handbook entity and database design work, reduces the experience barrier for database modeling, and helps PostgreSQL finest practices even for groups with out devoted database specialists.
In our instance, we offer our mannequin a set of necessities (as prompts) related to the duty and ask it to extract the dominant entity and its attributes (a knowledge extraction job) and likewise produce a related create desk assertion utilizing PostgreSQL (a text-to-SQL job).
Instance immediate:
The next desk exhibits our job varieties, standards, and golden solutions for this instance immediate. Now we have shortened the immediate for brevity. In a real-world use case, your necessities may span a number of paragraphs.
| task_type | task_criteria | golden_answer |
DATA EXTRACTION |
Test if the extracted entity and attributes matches the necessities |
|
TEXT-TO-SQL |
Given the necessities verify if the generated create desk matches the necessities |
AnyCompany needs to discover a mannequin that can resolve the duty within the quickest and most cost-effective means, with out compromising on high quality.
360-Eval UI
To scale back the complexity of the method, we’ve got constructed a UI on prime of the analysis engine.
The UI_README.md file has directions to launch and run the analysis utilizing the UI. It’s essential to additionally observe the directions within the README.md to put in the Python packages as conditions and allow Amazon Bedrock mannequin entry.
Let’s discover the completely different pages within the UI in additional element.
Setup web page
As you launch the UI, you land on the preliminary Setup web page, the place you choose your analysis knowledge, outline your label, outline your job as discreetly as doable, and set the temperature the fashions may have when being evaluated. Then you choose the fashions you wish to consider in opposition to your dataset, the judges that can consider the fashions’ accuracy (utilizing customized metrics and the usual high quality and relevance metrics), configure pricing and AWS Area choices, and at last configure the way you need the analysis to happen, resembling concurrency, request per minute, and experiment counts (distinctive runs).
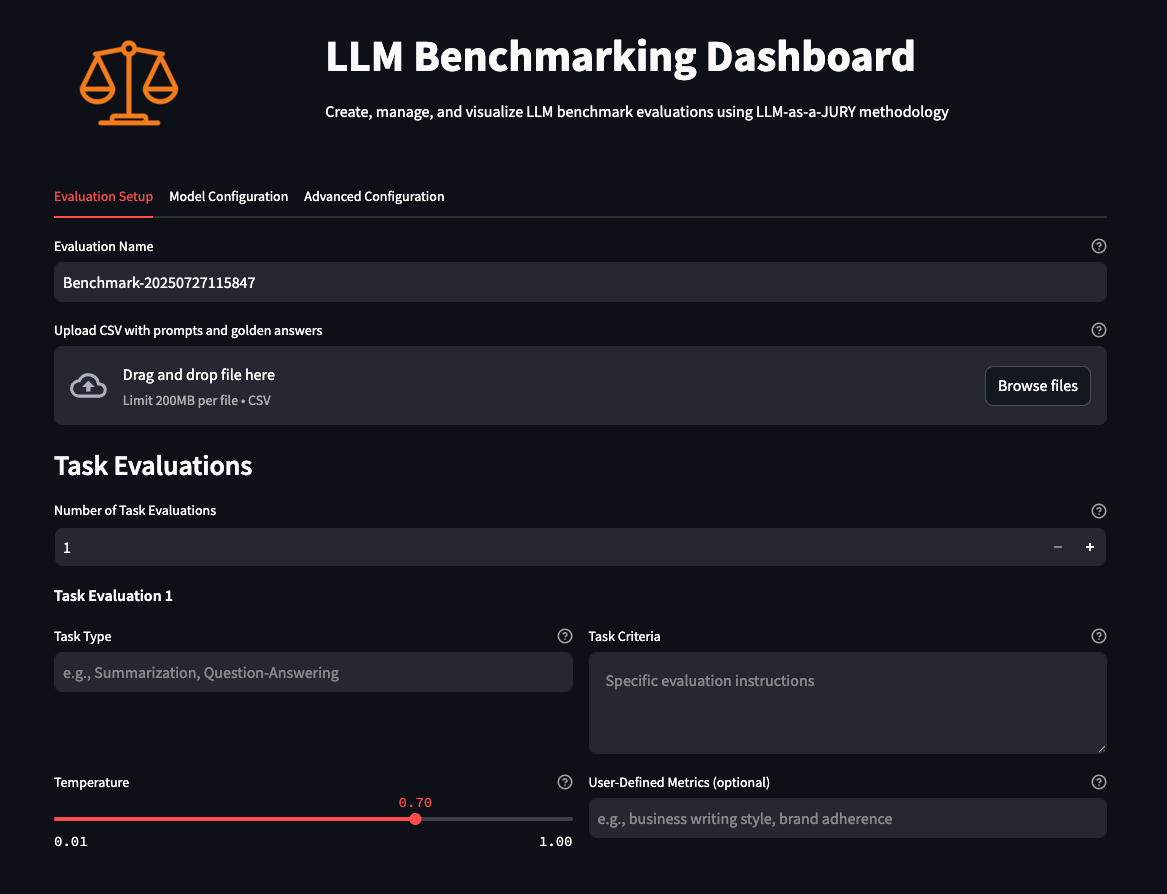
That is the place you specify the CSV file with pattern prompts, job kind, and job standards in accordance with your wants.
Monitor web page
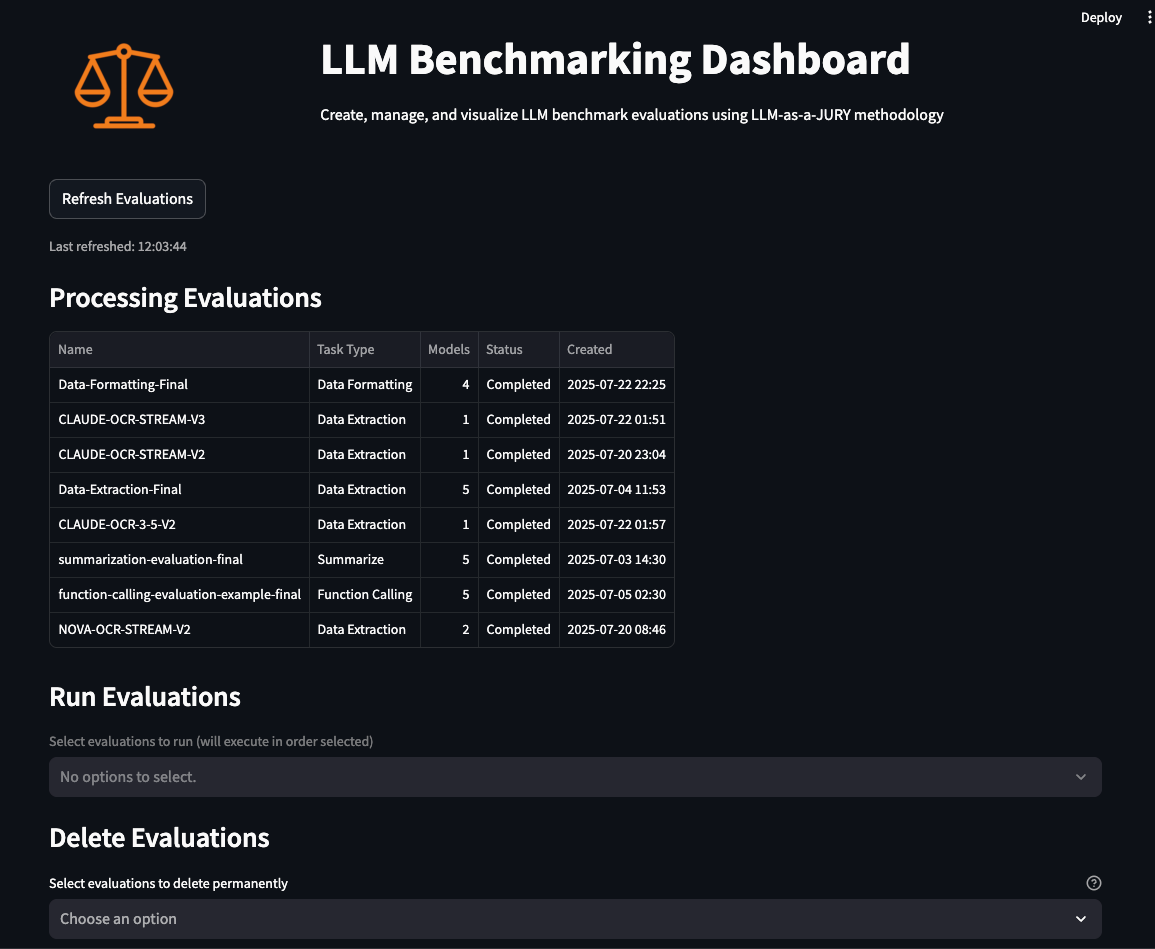
After the analysis standards and parameters are outlined, they’re displayed on the Monitor web page, which you’ll navigate to by selecting Monitor within the Navigation part. On this web page, you’ll be able to monitor all of your evaluations, together with these presently operating, these queued, and people not but scheduled to run. You may select the analysis you wish to run, and if any analysis is now not related, you’ll be able to take away it right here as properly.
The workflow is as follows:
- Execute the prompts within the enter file in opposition to the fashions chosen.
- Seize the metrics resembling enter token rely, output token rely, and TTFT.
- Use the enter and output tokens to calculate the price of operating every immediate in opposition to the fashions.
- Use an LLM-as-a-judge to judge the accuracy in opposition to predefined metrics (correctness, completeness, relevance, format, coherence, following directions) and any user-defined metrics.
Evaluations web page
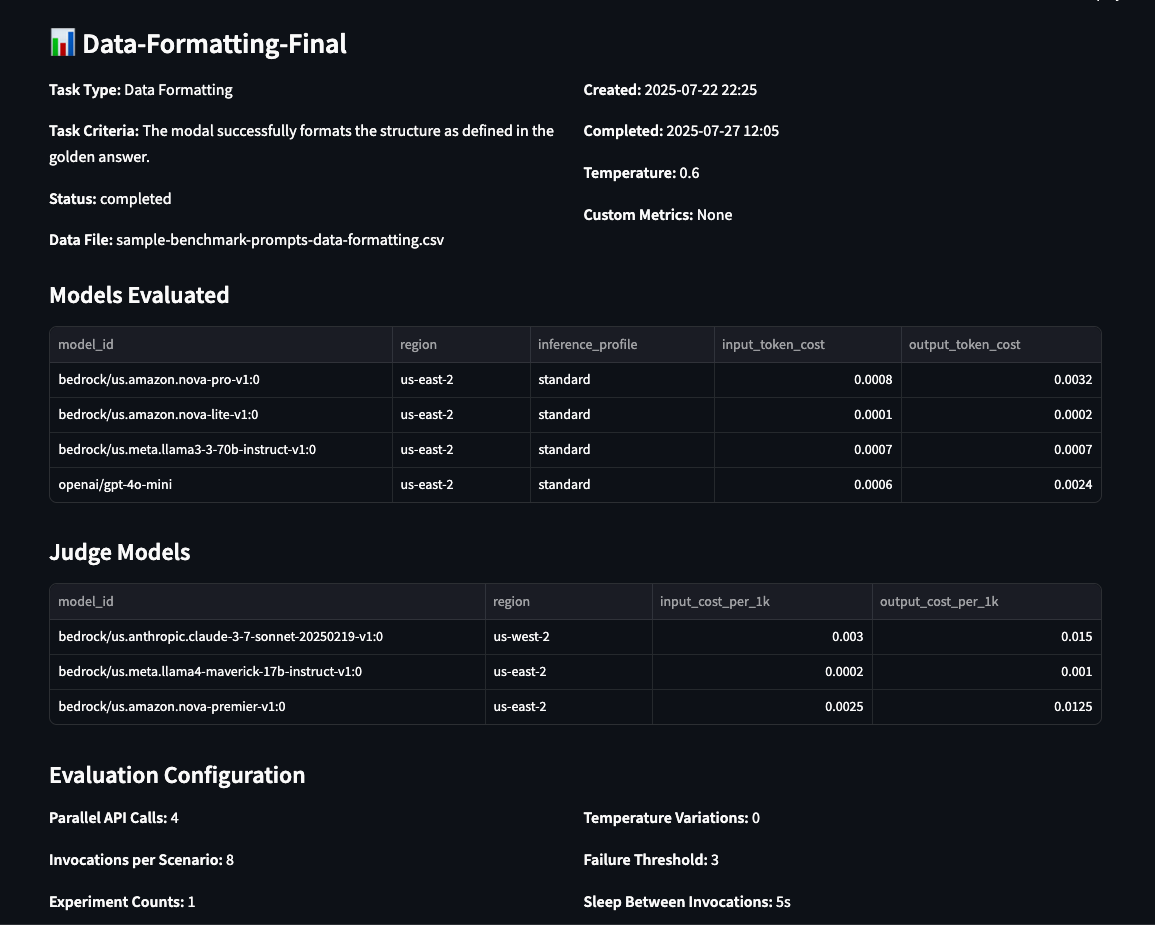
Detailed info of the evaluations, such because the analysis configuration, the choose fashions used to judge, the Areas the place the fashions are hosted, the enter and output price, and the duty and its standards the mannequin was evaluated with, are displayed on the Evaluations web page.
Experiences web page
Lastly, the Experiences web page is the place you’ll be able to choose the finished evaluations to generate a report in HTML format. You can even delete previous and irrelevant studies.
Understanding the analysis report
The instrument output is an HTML file that exhibits the outcomes of the analysis. It contains the next sections:
- Govt Abstract – This part supplies an general abstract of the outcomes. It supplies a fast abstract of which mannequin was most correct, which mannequin was the quickest general, and which mannequin offered the perfect success-to-cost ratio.
- Suggestions – This part incorporates extra particulars and a breakdown of what you see within the government abstract, in a tabular format.
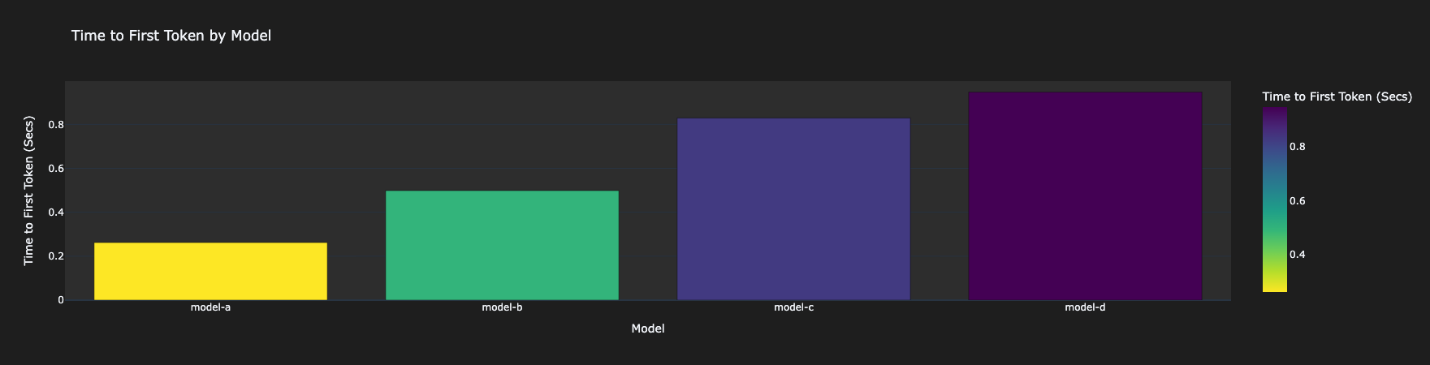
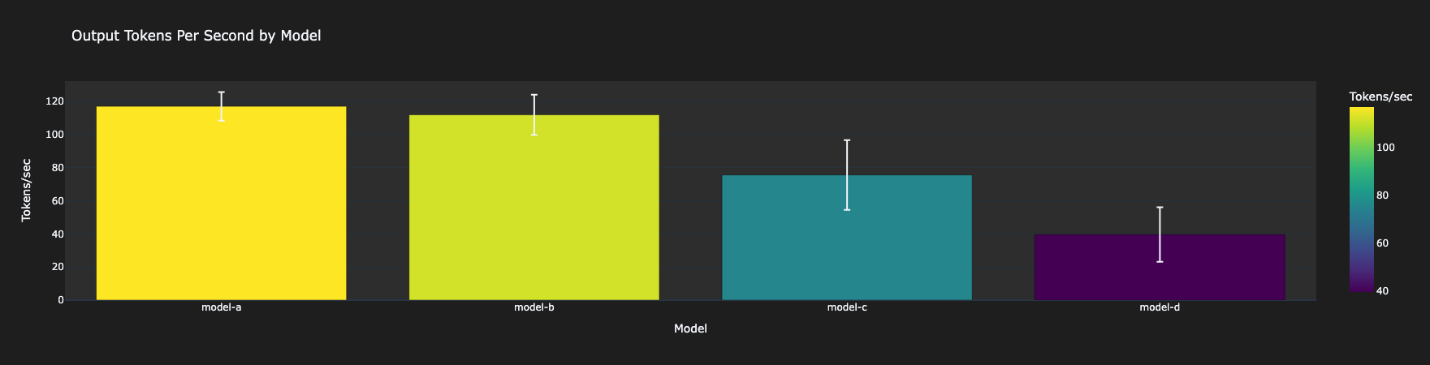
- Latency Metrics – On this part, you’ll be able to evaluation the efficiency facet of your analysis. We use the TTFT and output tokens per second as a measure for efficiency.
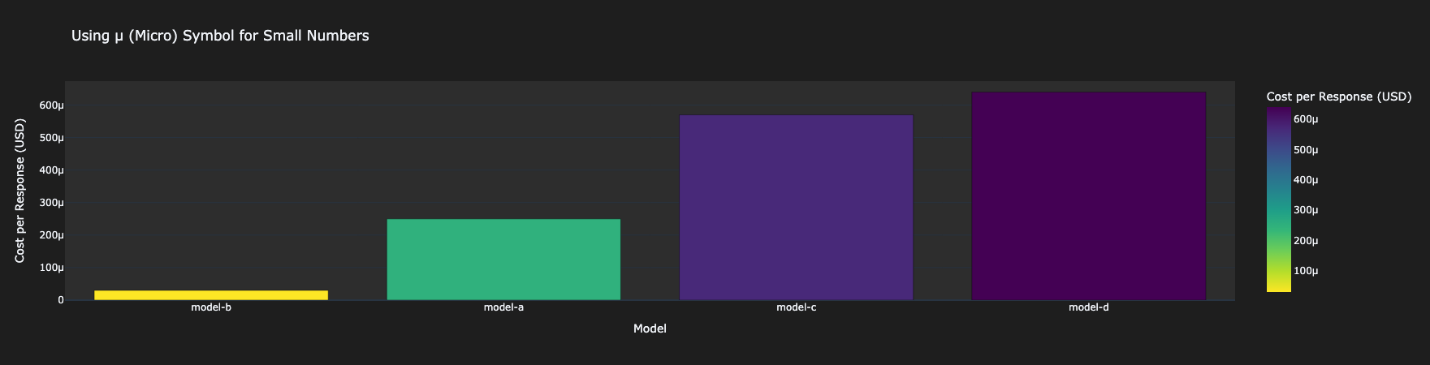
- Price Metrics – This part exhibits the general price of operating the analysis, which signifies what you’ll be able to count on in your AWS billing.
- Job Evaluation – The instrument additional breaks down the efficiency and price metrics by job kind. In our case, there might be a piece for the text-to-SQL job and one for knowledge extraction.
- Choose Scores Evaluation – On this part, you’ll be able to evaluation the standard of every mannequin based mostly on the varied metrics. You can even discover immediate optimizations to enhance your mannequin. In our case, our prompts have been extra biased in the direction of the Anthropic household, however in the event you use the Amazon Bedrock immediate optimization characteristic, you may be capable to handle this bias.
Decoding the analysis outcomes
Through the use of the 360-Eval UI, AnyCompany ran the analysis with their very own dataset and acquired the next outcomes. They selected 4 completely different LLMs in Amazon Bedrock to conduct the analysis. For this put up, the precise fashions used aren’t related. We name these fashions Mannequin-A, Mannequin-B, Mannequin-C, and Mannequin-D.
These outcomes will range in your case relying on the dataset and prompts. The outcomes listed here are a mirrored image of our personal instance inside a check account. As proven within the following figures, Mannequin-A was the quickest, adopted by Mannequin-B. Mannequin-C was 3–4 instances slower than Mannequin-A. Mannequin-D was the slowest.
As proven within the following determine, Mannequin B was the most cost effective. Mannequin A was thrice dearer than Mannequin-B. Mannequin-C and Mannequin-D have been each very costly.
The following focus was the standard of the analysis. The 2 most essential metrics to have been the correctness and completeness of the response. Within the following analysis, solely Mannequin-D scored greater than 3 for each job varieties.
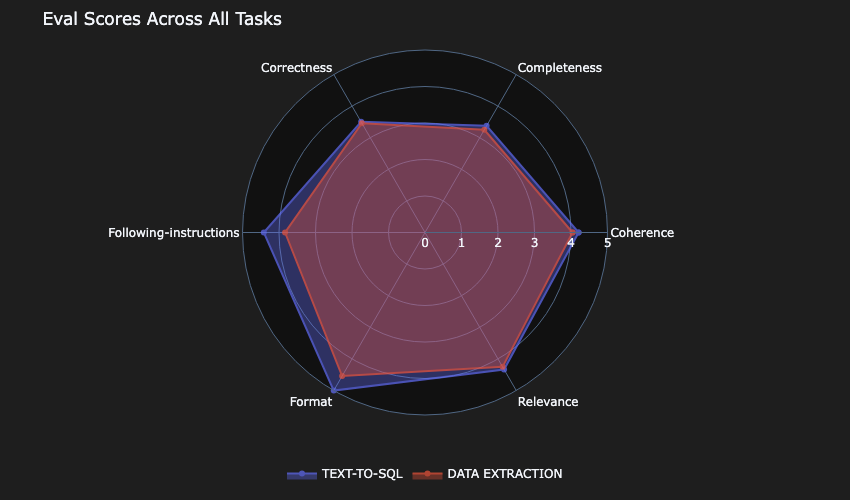
Mannequin-C was the subsequent closest contender.
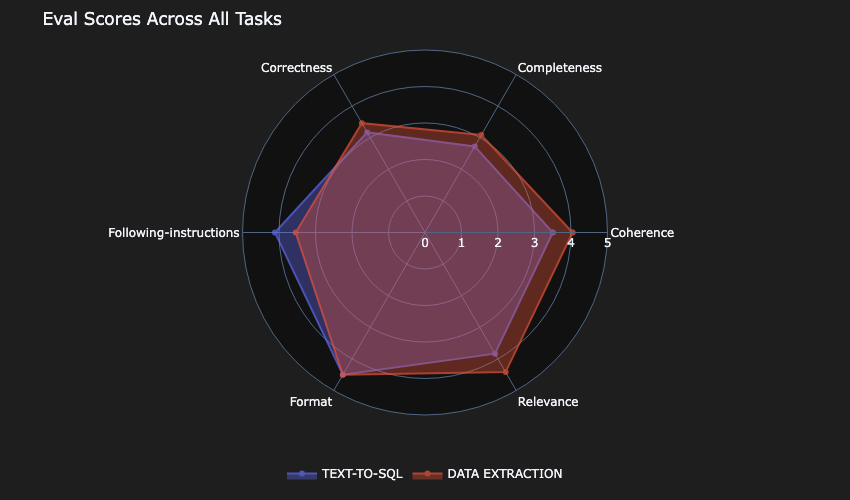
Mannequin-B scored lowest within the correctness and completeness metrics.
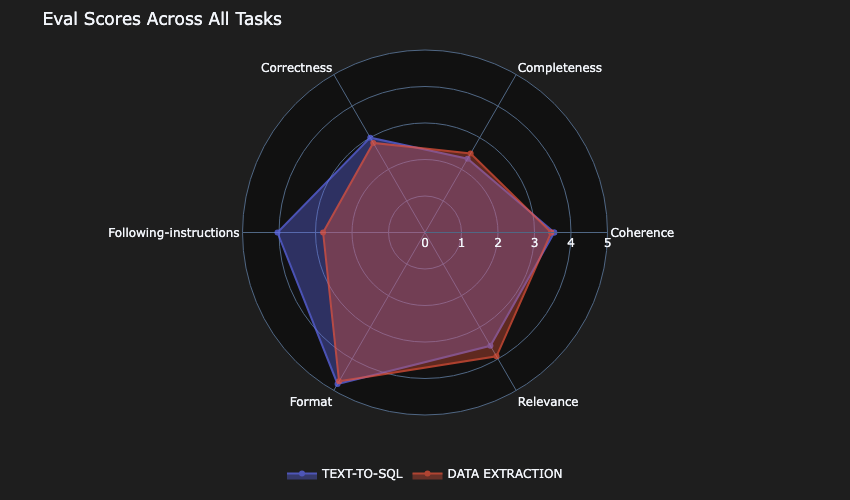
Mannequin-A missed barely on the completeness for the text-to-SQL use case.
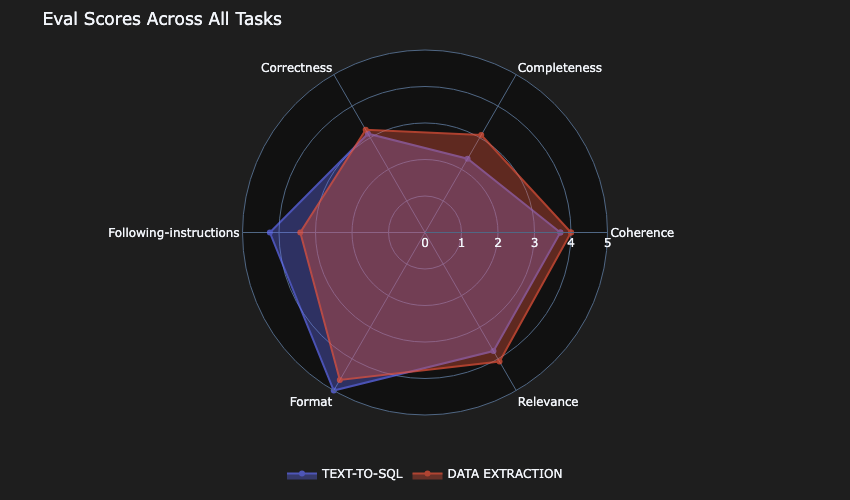
Analysis abstract
Let’s revisit AnyCompany’s standards, which was to discover a mannequin that can resolve the duty within the quickest and most cost-effective means, with out compromising on high quality. There was no apparent winner.
AnyCompany then thought of offering a tiered pricing mannequin to their clients. Premium-tier clients will obtain essentially the most correct mannequin at a premium value, and basic-tier clients will get the mannequin with the perfect price-performance.
Though for this use case, Mannequin-D was the slowest and dearer, it scored highest on essentially the most essential metrics: correctness and completeness of responses. For a database modeling instrument, accuracy is way extra essential than velocity or price, as a result of incorrect database schemas may result in important downstream points in utility growth. AnyCompany selected Mannequin-D for premium-tier clients.
Price is a significant constraint for the basic-tier, so AnyCompany selected Mannequin-A, as a result of it scored moderately properly on correctness for each duties and solely barely missed on completeness for one job kind, whereas being sooner and cheaper than the highest performers.
AnyCompany additionally thought of Mannequin-B as a viable possibility for free-tier clients.
Conclusion
As FMs turn into extra reliant, they’ll additionally turn into extra advanced. As a result of their strengths and weaknesses tougher to detect, evaluating them requires a scientific strategy. Through the use of a data-driven, multi-metric analysis, technical leaders could make knowledgeable selections rooted within the mannequin’s precise efficiency, together with factual accuracy, consumer expertise, compliance, and price.
Adopting frameworks like 360-Eval can operationalize this strategy. You may encode your analysis philosophy right into a standardized process, ensuring each new mannequin or model is judged the identical, and enabling side-by-side comparisons.
The framework handles the heavy lifting of operating fashions on check instances and computing metrics, so your workforce can deal with decoding outcomes and making selections. As the sector of generative AI continues to evolve quickly, having this analysis infrastructure will help you discover the best mannequin on your use case. Moreover, this strategy can allow sooner iteration on prompts and insurance policies, and in the end enable you develop extra dependable and efficient AI methods in manufacturing.
Concerning the authors
 Claudio Mazzoni is a Sr Specialist Options Architect on the Amazon Bedrock GTM workforce. Claudio exceeds at guiding costumers via their Gen AI journey. Outdoors of labor, Claudio enjoys spending time with household, working in his backyard, and cooking Uruguayan meals.
Claudio Mazzoni is a Sr Specialist Options Architect on the Amazon Bedrock GTM workforce. Claudio exceeds at guiding costumers via their Gen AI journey. Outdoors of labor, Claudio enjoys spending time with household, working in his backyard, and cooking Uruguayan meals.
 Anubhav Sharma is a Principal Options Architect at AWS with over 2 many years of expertise in coding and architecting business-critical purposes. Recognized for his robust need to study and innovate, Anubhav has spent the previous 6 years at AWS working carefully with a number of unbiased software program distributors (ISVs) and enterprises. He focuses on guiding these corporations via their journey of constructing, deploying, and working SaaS options on AWS.
Anubhav Sharma is a Principal Options Architect at AWS with over 2 many years of expertise in coding and architecting business-critical purposes. Recognized for his robust need to study and innovate, Anubhav has spent the previous 6 years at AWS working carefully with a number of unbiased software program distributors (ISVs) and enterprises. He focuses on guiding these corporations via their journey of constructing, deploying, and working SaaS options on AWS.



{kind=link}