LLM Themes Are Not Observations
themes from a name corpus to the client desk. Clients with out transcripts get NULL. NULL will get crammed with zero, or with “no challenge talked about,” or quietly omitted...
themes from a name corpus to the client desk. Clients with out transcripts get NULL. NULL will get crammed with zero, or with “no challenge talked about,” or quietly omitted...
At present, Amazon SageMaker AI introduces OpenAI-compatible API assist for real-time inference endpoints. Should you use the OpenAI SDK, LangChain, or Strands Brokers, now you can invoke fashions on SageMaker...
you ask an LLM to simulate 6,000 American households answering questions on inflation? Latest papers discover that giant language fashions can replicate the common responses of main family surveys to...
Should you’re constructing visible procuring, picture or doc understanding, or chart evaluation, you want a approach to confirm whether or not your mannequin’s response is definitely grounded within the supply...
as Claude Code and Codex have offered me the largest effectivity increase I’ve ever skilled whereas programming, far more of a lift in comparison with getting extra highly effective computer...
Design patterns for scalable voice brokers matter for organizations that must ship quick, pure, and dependable voice experiences. Many groups face challenges like excessive latency, managing real-time audio, and coordinating...
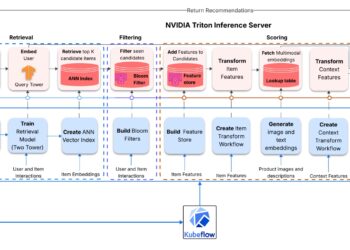
, multimodal recommender system will not be trivial particularly when it must scale, adapt in close to actual time, and run reliably on cloud. On this submit, I stroll by...
This visitor publish is co-written by Angela Mapes and Adam Walker of Aderant. Aderant, a number one international supplier of complete enterprise administration software program for the authorized business, reworked...
train you how one can make a mannequin correct. They not often train you the selections that come proper after. How are you aware when to completely automate one thing...
If you happen to average user-generated content material at scale, you want a system that catches coverage violations precisely with out over-flagging respectable posts. A moderation system that misses dangerous...