
In right this moment’s world, the reliability of information options is every part. After we construct dashboards and stories, one expects that the numbers mirrored there are appropriate and up-to-date. Primarily based on these numbers, insights are drawn and actions are taken. For any unexpected cause, if the dashboards are damaged or if the numbers are incorrect — then it turns into a fire-fight to repair every part. If the problems usually are not fastened in time, then it damages the belief positioned on the information crew and their options.
However why would dashboards be damaged or have fallacious numbers? If the dashboard was constructed appropriately the primary time, then 99% of the time the difficulty comes from the information that feeds the dashboards — from the information warehouse. Some attainable situations are:
- Few ETL pipelines failed, so the brand new information isn’t but in
- A desk is changed with one other new one
- Some columns within the desk are dropped or renamed
- Schemas in information warehouse have modified
- And plenty of extra.
There may be nonetheless an opportunity that the difficulty is on the Tableau web site, however in my expertise, a lot of the occasions, it’s all the time as a consequence of some adjustments in information warehouse. Despite the fact that we all know the basis trigger, it’s not all the time simple to begin engaged on a repair. There may be no central place the place you may examine which Tableau information sources depend on particular tables. When you have the Tableau Information Administration add-on, it may assist, however from what I do know, its exhausting to seek out dependencies of customized sql queries utilized in information sources.
However, the add-on is just too costly and most firms don’t have it. The true ache begins when you must undergo all the information sources manually to begin fixing it. On prime of it, you will have a string of customers in your head impatiently ready for a quick-fix. The repair itself won’t be tough, it could simply be a time-consuming one.
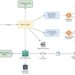
What if we may anticipate these points and establish impacted information sources earlier than anybody notices an issue? Wouldn’t that simply be nice? Nicely, there’s a means now with the Tableau Metadata API. The Metadata API makes use of GraphQL, a question language for APIs that returns solely the information that you just’re fascinated about. For more information on what’s attainable with GraphQL, do try GraphQL.org.
On this weblog publish, I’ll present you ways to connect with the Tableau Metadata API utilizing Python’s Tableau Server Shopper (TSC) library to proactively establish information sources utilizing particular tables, in an effort to act quick earlier than any points come up. As soon as you understand which Tableau information sources are affected by a selected desk, you may make some updates your self or alert the homeowners of these information sources in regards to the upcoming adjustments to allow them to be ready for it.
Connecting to the Tableau Metadata API
Lets connect with the Tableau Server utilizing TSC. We have to import in all of the libraries we would wish for the train!
### Import all required libraries
import tableauserverclient as t
import pandas as pd
import json
import ast
import reWith a purpose to connect with the Metadata API, you’ll have to first create a private entry token in your Tableau Account settings. Then replace the
### Connect with Tableau server utilizing private entry token
tableau_auth = t.PersonalAccessTokenAuth("", "",
site_id="")
server = t.Server("https://dub01.on-line.tableau.com/", use_server_version=True)
with server.auth.sign_in(tableau_auth):
print("Linked") Lets now get a listing of all information sources which might be printed in your web site. There are a lot of attributes you may fetch, however for the present use case, lets hold it easy and solely get the id, title and proprietor contact data for each information supply. This might be our grasp checklist to which we’ll add in all different data.
############### Get all of the checklist of information sources in your Website
all_datasources_query = """ {
publishedDatasources {
title
id
proprietor {
title
e mail
}
}
}"""
with server.auth.sign_in(tableau_auth):
end result = server.metadata.question(
all_datasources_query
)Since I need this weblog to be focussed on how one can proactively establish which information sources are affected by a selected desk, I’ll not be going into the nuances of Metadata API. To higher perceive how the question works, you may check with a really detailed Tableau’s personal Metadata API documentation.
One factor to notice is that the Metadata API returns information in a JSON format. Relying on what you’re querying, you’ll find yourself with a number of nested json lists and it may possibly get very difficult to transform this right into a pandas dataframe. For the above metadata question, you’ll find yourself with a end result which would love beneath (that is mock information simply to offer you an thought of what the output appears like):
{
"information": {
"publishedDatasources": [
{
"name": "Sales Performance DataSource",
"id": "f3b1a2c4-1234-5678-9abc-1234567890ab",
"owner": {
"name": "Alice Johnson",
"email": "[email protected]"
}
},
{
"title": "Buyer Orders DataSource",
"id": "a4d2b3c5-2345-6789-abcd-2345678901bc",
"proprietor": {
"title": "Bob Smith",
"e mail": "[email protected]"
}
},
{
"title": "Product Returns and Profitability",
"id": "c5e3d4f6-3456-789a-bcde-3456789012cd",
"proprietor": {
"title": "Alice Johnson",
"e mail": "[email protected]"
}
},
{
"title": "Buyer Segmentation Evaluation",
"id": "d6f4e5a7-4567-89ab-cdef-4567890123de",
"proprietor": {
"title": "Charlie Lee",
"e mail": "[email protected]"
}
},
{
"title": "Regional Gross sales Tendencies (Customized SQL)",
"id": "e7a5f6b8-5678-9abc-def0-5678901234ef",
"proprietor": {
"title": "Bob Smith",
"e mail": "[email protected]"
}
}
]
}
}We have to convert this JSON response right into a dataframe in order that its straightforward to work with. Discover that we have to extract the title and e mail of the proprietor from contained in the proprietor object.
### We have to convert the response into dataframe for straightforward information manipulation
col_names = end result['data']['publishedDatasources'][0].keys()
master_df = pd.DataFrame(columns=col_names)
for i in end result['data']['publishedDatasources']:
tmp_dt = {okay:v for okay,v in i.objects()}
master_df = pd.concat([master_df, pd.DataFrame.from_dict(tmp_dt, orient='index').T])
# Extract the proprietor title and e mail from the proprietor object
master_df['owner_name'] = master_df['owner'].apply(lambda x: x.get('title') if isinstance(x, dict) else None)
master_df['owner_email'] = master_df['owner'].apply(lambda x: x.get('e mail') if isinstance(x, dict) else None)
master_df.reset_index(inplace=True)
master_df.drop(['index','owner'], axis=1, inplace=True)
print('There are ', master_df.form[0] , ' datasources in your web site')That is how the construction of master_df would seem like:

As soon as we have now the primary checklist prepared, we are able to go forward and begin getting the names of the tables embedded within the information sources. In case you are an avid Tableau consumer, you understand that there are two methods to choosing tables in a Tableau information supply — one is to instantly select the tables and set up a relation between them and the opposite is to make use of a customized sql question with a number of tables to realize a brand new resultant desk. Subsequently, we have to tackle each the circumstances.
Processing of Customized SQL question tables
Under is the question to get the checklist of all customized SQLs used within the web site together with their information sources. Discover that I’ve filtered the checklist to get solely first 500 customized sql queries. In case there are extra in your org, you’ll have to use an offset to get the following set of customized sql queries. There may be additionally an possibility of utilizing cursor technique in Pagination if you need to fetch massive checklist of outcomes (refer right here). For the sake of simplicity, I simply use the offset technique as I do know, as there are lower than 500 customized sql queries used on the location.
# Get the information sources and the desk names from all of the customized sql queries used in your Website
custom_table_query = """ {
customSQLTablesConnection(first: 500){
nodes {
id
title
downstreamDatasources {
title
}
question
}
}
}
"""
with server.auth.sign_in(tableau_auth):
custom_table_query_result = server.metadata.question(
custom_table_query
)Primarily based on our mock information, that is how our output would seem like:
{
"information": {
"customSQLTablesConnection": {
"nodes": [
{
"id": "csql-1234",
"name": "RegionalSales_CustomSQL",
"downstreamDatasources": [
{
"name": "Regional Sales Trends (Custom SQL)"
}
],
"question": "SELECT r.region_name, SUM(s.sales_amount) AS total_sales FROM ecommerce.sales_data.Gross sales s JOIN ecommerce.sales_data.Areas r ON s.region_id = r.region_id GROUP BY r.region_name"
},
{
"id": "csql-5678",
"title": "ProfitabilityAnalysis_CustomSQL",
"downstreamDatasources": [
{
"name": "Product Returns and Profitability"
}
],
"question": "SELECT p.product_category, SUM(s.revenue) AS total_profit FROM ecommerce.sales_data.Gross sales s JOIN ecommerce.sales_data.Merchandise p ON s.product_id = p.product_id GROUP BY p.product_category"
},
{
"id": "csql-9101",
"title": "CustomerSegmentation_CustomSQL",
"downstreamDatasources": [
{
"name": "Customer Segmentation Analysis"
}
],
"question": "SELECT c.customer_id, c.location, COUNT(o.order_id) AS total_orders FROM ecommerce.sales_data.Prospects c JOIN ecommerce.sales_data.Orders o ON c.customer_id = o.customer_id GROUP BY c.customer_id, c.location"
},
{
"id": "csql-3141",
"title": "CustomerOrders_CustomSQL",
"downstreamDatasources": [
{
"name": "Customer Orders DataSource"
}
],
"question": "SELECT o.order_id, o.customer_id, o.order_date, o.sales_amount FROM ecommerce.sales_data.Orders o WHERE o.order_status = 'Accomplished'"
},
{
"id": "csql-3142",
"title": "CustomerProfiles_CustomSQL",
"downstreamDatasources": [
{
"name": "Customer Orders DataSource"
}
],
"question": "SELECT c.customer_id, c.customer_name, c.phase, c.location FROM ecommerce.sales_data.Prospects c WHERE c.active_flag = 1"
},
{
"id": "csql-3143",
"title": "CustomerReturns_CustomSQL",
"downstreamDatasources": [
{
"name": "Customer Orders DataSource"
}
],
"question": "SELECT r.return_id, r.order_id, r.return_reason FROM ecommerce.sales_data.Returns r"
}
]
}
}
}Identical to earlier than once we have been creating the grasp checklist of information sources, right here additionally we have now nested json for the downstream information sources the place we would wish to extract solely the “title” a part of it. Within the “question” column, the whole customized sql is dumped. If we use regex sample, we are able to simply seek for the names of the desk used within the question.
We all know that the desk names all the time come after FROM or a JOIN clause they usually typically observe the format
### Convert the customized sql response into dataframe
col_names = custom_table_query_result['data']['customSQLTablesConnection']['nodes'][0].keys()
cs_df = pd.DataFrame(columns=col_names)
for i in custom_table_query_result['data']['customSQLTablesConnection']['nodes']:
tmp_dt = {okay:v for okay,v in i.objects()}
cs_df = pd.concat([cs_df, pd.DataFrame.from_dict(tmp_dt, orient='index').T])
# Extract the information supply title the place the customized sql question was used
cs_df['data_source'] = cs_df.downstreamDatasources.apply(lambda x: x[0]['name'] if x and 'title' in x[0] else None)
cs_df.reset_index(inplace=True)
cs_df.drop(['index','downstreamDatasources'], axis=1,inplace=True)
### We have to extract the desk names from the sql question. We all know the desk title comes after FROM or JOIN clause
# Notice that the title of desk will be of the format ..
# Relying on the format of how desk is named, you'll have to modify the regex expression
def extract_tables(sql):
# Regex to match database.schema.desk or schema.desk, keep away from alias
sample = r'(?:FROM|JOIN)s+((?:[w+]|w+).(?:[w+]|w+)(?:.(?:[w+]|w+))?)b'
matches = re.findall(sample, sql, re.IGNORECASE)
return checklist(set(matches)) # Distinctive desk names
cs_df['customSQLTables'] = cs_df['query'].apply(extract_tables)
cs_df = cs_df[['data_source','customSQLTables']]
# We have to merge datasources as there will be a number of customized sqls utilized in the identical information supply
cs_df = cs_df.groupby('data_source', as_index=False).agg({
'customSQLTables': lambda x: checklist(set(merchandise for sublist in x for merchandise in sublist)) # Flatten & make distinctive
})
print('There are ', cs_df.form[0], 'datasources with customized sqls utilized in it') After we carry out all of the above operations, that is how the construction of cs_df would seem like:

Processing of standard Tables in Information Sources
Now we have to get the checklist of all of the common tables utilized in a datasource which aren’t part of customized SQL. There are two methods to go about it. Both use the publishedDatasources object and examine for upstreamTables or use DatabaseTable and examine for upstreamDatasources. I’ll go by the primary technique as a result of I need the outcomes at a knowledge supply degree (mainly, I need some code able to reuse after I need to examine a selected information supply in additional element). Right here once more, for the sake of simplicity, as an alternative of going for pagination, I’m looping by way of every datasource to make sure I’ve every part. We get the upstreamTables inside the sector object in order that needs to be cleaned out.
############### Get the information sources with the common desk names utilized in your web site
### Its finest to extract the tables data for each information supply after which merge the outcomes.
# Since we solely get the desk data nested underneath fields, in case there are lots of of fields
# utilized in a single information supply, we'll hit the response limits and won't be able to retrieve all the information.
data_source_list = master_df.title.tolist()
col_names = ['name', 'id', 'extractLastUpdateTime', 'fields']
ds_df = pd.DataFrame(columns=col_names)
with server.auth.sign_in(tableau_auth):
for ds_name in data_source_list:
question = """ {
publishedDatasources (filter: { title: """"+ ds_name + """" }) {
title
id
extractLastUpdateTime
fields {
title
upstreamTables {
title
}
}
}
} """
ds_name_result = server.metadata.question(
question
)
for i in ds_name_result['data']['publishedDatasources']:
tmp_dt = {okay:v for okay,v in i.objects() if okay != 'fields'}
tmp_dt['fields'] = json.dumps(i['fields'])
ds_df = pd.concat([ds_df, pd.DataFrame.from_dict(tmp_dt, orient='index').T])
ds_df.reset_index(inplace=True)That is how the construction of ds_df would look:

We will have to flatten out the fields object and extract the sector names in addition to the desk names. Because the desk names might be repeating a number of occasions, we must deduplicate to maintain solely the distinctive ones.
# Perform to extract the values of fields and upstream tables in json lists
def extract_values(json_list, key):
values = []
for merchandise in json_list:
values.append(merchandise[key])
return values
ds_df["fields"] = ds_df["fields"].apply(ast.literal_eval)
ds_df['field_names'] = ds_df.apply(lambda x: extract_values(x['fields'],'title'), axis=1)
ds_df['upstreamTables'] = ds_df.apply(lambda x: extract_values(x['fields'],'upstreamTables'), axis=1)
# Perform to extract the distinctive desk names
def extract_upstreamTable_values(table_list):
values = set()a
for inner_list in table_list:
for merchandise in inner_list:
if 'title' in merchandise:
values.add(merchandise['name'])
return checklist(values)
ds_df['upstreamTables'] = ds_df.apply(lambda x: extract_upstreamTable_values(x['upstreamTables']), axis=1)
ds_df.drop(["index","fields"], axis=1, inplace=True)As soon as we do the above operations, the ultimate construction of ds_df would look one thing like this:

We’ve all of the items and now we simply need to merge them collectively:
###### Be part of all the information collectively
master_data = pd.merge(master_df, ds_df, how="left", on=["name","id"])
master_data = pd.merge(master_data, cs_df, how="left", left_on="title", right_on="data_source")
# Save the outcomes to analyse additional
master_data.to_excel("Tableau Information Sources with Tables.xlsx", index=False)That is our ultimate master_data:

Desk-level Affect Evaluation
Let’s say there have been some schema adjustments on the “Gross sales” desk and also you need to know which information sources might be impacted. Then you may merely write a small operate which checks if a desk is current in both of the 2 columns — upstreamTables or customSQLTables like beneath.
def filter_rows_with_table(df, col1, col2, target_table):
"""
Filters rows in df the place target_table is a part of any worth in both col1 or col2 (helps partial match).
Returns full rows (all columns retained).
"""
return df[
df.apply(
lambda row:
(isinstance(row[col1], checklist) and any(target_table in merchandise for merchandise in row[col1])) or
(isinstance(row[col2], checklist) and any(target_table in merchandise for merchandise in row[col2])),
axis=1
)
]
# For example
filter_rows_with_table(master_data, 'upstreamTables', 'customSQLTables', 'Gross sales')Under is the output. You may see that 3 information sources might be impacted by this alteration. You may as well alert the information supply homeowners Alice and Bob prematurely about this to allow them to begin engaged on a repair earlier than one thing breaks on the Tableau dashboards.

You may try the whole model of the code in my Github repository right here.
That is simply one of many potential use-cases of the Tableau Metadata API. You may as well extract the sector names utilized in customized sql queries and add to the dataset to get a field-level influence evaluation. One also can monitor the stale information sources with the extractLastUpdateTime to see if these have any points or must be archived if they don’t seem to be used any extra. We will additionally use the dashboards object to fetch data at a dashboard degree.
Ultimate Ideas
When you have come this far, kudos. This is only one use case of automating Tableau information administration. It’s time to replicate by yourself work and suppose which of these different duties you would automate to make your life simpler. I hope this mini-project served as an fulfilling studying expertise to grasp the ability of Tableau Metadata API. In the event you appreciated studying this, you may also like one other one in all my weblog posts about Tableau, on among the challenges I confronted when coping with massive .
Additionally do try my earlier weblog the place I explored constructing an interactive, database-powered app with Python, Streamlit, and SQLite.
Earlier than you go…
Comply with me so that you don’t miss any new posts I write in future; you can find extra of my articles on my . You may as well join with me on LinkedIn or Twitter!


{kind=link}