In recent times, the emergence of enormous language fashions (LLMs) has accelerated AI adoption throughout numerous industries. Nevertheless, to additional increase LLMs’ capabilities and successfully use up-to-date data and domain-specific information, integration with exterior knowledge sources is important. Retrieval Augmented Technology (RAG) has gained consideration as an efficient method to deal with this problem.
RAG is a method that searches related data from present information bases or paperwork primarily based on consumer enter, and incorporates this data into the LLM enter to generate extra correct and contextually applicable responses. This method is being applied throughout a variety of purposes, from utilizing technical documentation in product growth to answering FAQs in buyer help, and even supporting decision-making programs primarily based on the most recent knowledge.
The implementation of RAG brings important worth to each software-as-a-service (SaaS) suppliers and their customers (tenants).
SaaS suppliers can use a multi-tenant structure that delivers companies to a number of tenants from a single code base. As tenants use the service, their knowledge accumulates whereas being protected by applicable entry management and knowledge isolation. When implementing AI capabilities utilizing LLMs in such environments, RAG makes it potential to make use of every tenant’s particular knowledge to offer customized AI companies.
Let’s think about a customer support name heart SaaS for instance. Every tenant’s historic inquiry information, FAQs, and product manuals are collected as tenant-specific information bases. By implementing a RAG system, the LLM can generate applicable responses related to every tenant’s context by referencing these tenant-specific knowledge sources. This allows extremely correct interactions that incorporate tenant-specific enterprise information—a stage of customization that may not be potential with generic AI assistants. RAG serves as a vital element for delivering customized AI experiences in SaaS, contributing to service differentiation and worth enhancement.
Nevertheless, utilizing tenant-specific knowledge by way of RAG presents technical challenges from safety and privateness views. The first concern is implementing safe structure that maintains knowledge isolation between tenants and helps stop unintended knowledge leakage or cross-tenant entry. In multi-tenant environments, the implementation of knowledge safety critically impacts the trustworthiness and aggressive benefit of SaaS suppliers.
Amazon Bedrock Data Bases permits less complicated RAG implementation. When utilizing OpenSearch as a vector database, there are two choices: Amazon OpenSearch Service or Amazon OpenSearch Serverless. Every choice has totally different traits and permission fashions when constructing multi-tenant environments:
- Amazon OpenSearch Serverless:
- Amazon OpenSearch Service:
On this publish, we introduce tenant isolation patterns utilizing a mix of JSON Internet Token (JWT) and FGAC, together with tenant useful resource routing. If the aforementioned permission mannequin limits you from reaching your FGAC aims, you need to use the answer on this publish. The answer is applied utilizing OpenSearch Service because the vector database and AWS Lambda because the orchestration layer.
Within the subsequent part, we discover the particular implementation of tenant isolation utilizing JWT and FGAC in OpenSearch Service, and the way this permits a safe multi-tenant RAG atmosphere.
Effectiveness of JWT in multi-tenant knowledge isolation in OpenSearch Service
As launched in Storing Multi-Tenant SaaS Information with Amazon OpenSearch Service, OpenSearch Service provides a number of strategies for managing multi-tenant knowledge: domain-level isolation, index-level isolation, and document-level isolation.
To implement entry permission segregation on the index and doc ranges, you need to use FGAC, which is supported by the OpenSearch Safety plugin.
In OpenSearch Service, you may obtain granular entry management by mapping IAM identities to OpenSearch roles. This allows detailed permission settings in OpenSearch for every IAM identification. Nevertheless, this method presents important scalability challenges. Because the variety of tenants will increase, the required variety of IAM customers or roles additionally will increase, probably hitting the restrict of AWS service quotas. Moreover, managing quite a few IAM entities results in operational complexity. Though dynamically generated IAM insurance policies may overcome this problem, every dynamically generated coverage is connected to a single IAM function. A single IAM function will be mapped to a single OpenSearch function, however this might nonetheless require an IAM function and dynamic coverage per tenant for applicable isolation, which leads to comparable operational complexity managing quite a few entities.
This publish supplies another method and focuses on the effectiveness of JWT, a self-contained token for implementing knowledge isolation and entry management in multi-tenant environments. Utilizing JWT supplies the next benefits:
- Dynamic tenant identification – JWT payloads can embody attribute data (tenant context) to establish tenants. This allows the system to dynamically establish tenants for every request and permits passing this context to subsequent sources and companies.
- Integration with FGAC in OpenSearch – FGAC can straight use attribute data in JWT for function mapping. This enables mapping of entry permissions to particular indexes or paperwork primarily based on data corresponding to tenant IDs within the JWT.
Combining JWT with FGAC supplies safe, versatile, and scalable knowledge isolation and entry management in a multi-tenant RAG atmosphere utilizing OpenSearch Service. Within the subsequent part, we discover particular implementation particulars and technical issues for making use of this idea in precise programs.
Resolution overview
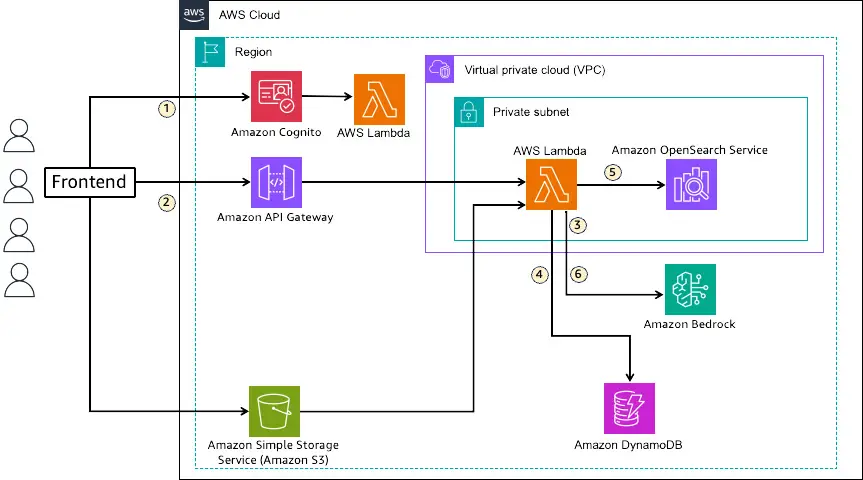
In RAG, knowledge corresponding to related paperwork used to enhance LLM outputs are vectorized by embedding language fashions and listed in a vector database. Consumer questions in pure language are transformed to vectors utilizing the embedding mannequin and searched within the vector database. The info retrieved by way of vector search is handed to the LLM as context to enhance the output. The next diagram illustrates the answer structure.
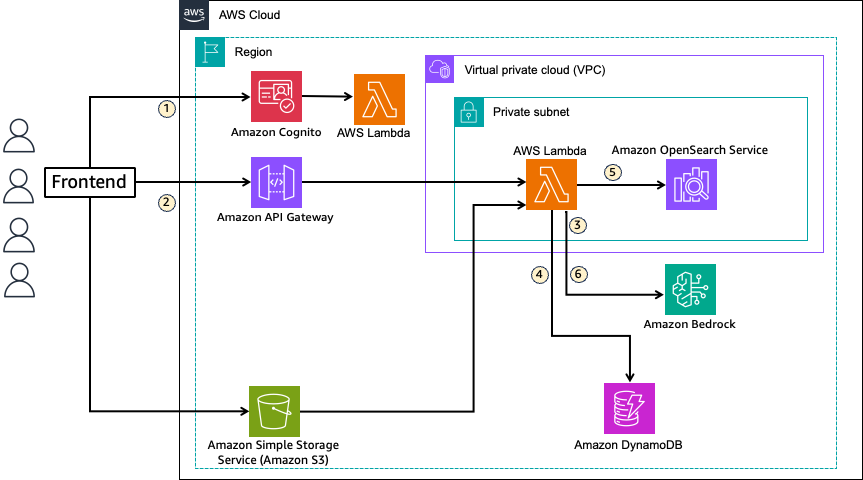
This resolution makes use of OpenSearch Service because the vector knowledge retailer for storing information sources in RAG. The stream is as follows:
- RAG software customers for every tenant are created as customers in an Amazon Cognito consumer pool, receiving a JWT enriched with tenant ID data when logging in to the frontend. Every consumer’s tenant data is saved in Amazon DynamoDB and added to the JWT by a pre-token era Lambda set off throughout consumer authentication.
- When a consumer initiates a chat on the frontend, the consumer question is handed to Lambda utilizing Amazon API Gateway together with the JWT.
- The consumer question is vectorized at the side of textual content embedding fashions out there in Amazon Bedrock.
- Area and index data for retrieval is obtained from DynamoDB.
- Vector search is carried out on OpenSearch Service to retrieve data associated to the question from the index.
- The retrieved data is added to the immediate as context and handed to an LLM out there in Amazon Bedrock to generate a response.
The important thing side of this resolution is utilizing JWT for tenant knowledge isolation in OpenSearch Service and routing to every tenant’s knowledge. It separates entry permissions for every dataset utilizing FGAC out there in OpenSearch Service and makes use of tenant ID data added to the JWT for mapping software customers to separated permission units. The answer supplies three totally different patterns for knowledge isolation granularity to satisfy buyer necessities. Routing can also be enabled by defining the mapping between tenant ID data from JWT and knowledge location (area, index) in DynamoDB.
When customers add paperwork, recordsdata are uploaded to Amazon Easy Storage Service (Amazon S3) and metadata is written to DynamoDB administration desk. When storing knowledge in OpenSearch Service, the textual content embedding mannequin (Amazon Bedrock) known as by the ingest pipeline for vectorization. For doc creation, replace, and deletion, JWT is connected to requests, permitting tenant identification.
This resolution is applied utilizing the AWS Cloud Growth Equipment (AWS CDK). For particulars, consult with the GitHub repository. The directions to deploy the answer are included within the README file within the repository.
Stipulations
To do this resolution, you have to have the next conditions:
- An AWS account.
- IAM entry permissions mandatory for operating the AWS CDK.
- A frontend execution atmosphere: node.js and npm set up is required.
- The AWS CDK have to be configured. For particulars, consult with Tutorial: Create your first AWS CDK app.
- Entry to the fashions utilized in Amazon Bedrock have to be configured. This resolution makes use of Anthropic’s Claude 3.5 Sonnet v2 and Amazon Titan Textual content Embedding V2. For particulars, consult with Add or take away entry to Amazon Bedrock basis fashions.
Along with the sources proven within the structure diagram, the next sources and configurations are created as AWS CloudFormation customized sources by way of AWS CDK deployment:
- Amazon Cognito consumer pool:
- Customers for tenant-a, tenant-b, tenant-c, and tenant-d
- DynamoDB desk:
- Mapping between customers and tenants
- Mapping between tenants and OpenSearch connection locations and indexes
- OpenSearch Service area:
- JWT authentication settings
- Ingest pipeline for vector embedding
- FGAC roles and function mappings for every tenant
- k-NN index
Consumer authentication and JWT era with Amazon Cognito
This resolution makes use of an Amazon Cognito consumer pool for RAG software consumer authentication. Amazon Cognito consumer swimming pools challenge JWT throughout authentication. As a result of FGAC in OpenSearch Service helps JWT authentication, entry from customers authenticated by the Amazon Cognito consumer pool will be permitted by registering public keys issued by the consumer pool with the OpenSearch Service area. Moreover, authorization is carried out utilizing attributes that may be added to the JWT payload for tenant knowledge entry permission segregation with FGAC, which we focus on within the following sections. To attain this, a pre-token era Lambda set off is configured within the Amazon Cognito consumer pool to retrieve tenant ID data for every consumer saved in DynamoDB and add it to the token. The obtained JWT is retained by the frontend and used for requests to the backend. DynamoDB shops the mapping between consumer ID (sub) and tenant ID as follows:
Though a number of patterns exist for implementing multi-tenant authentication with Amazon Cognito, this implementation makes use of a single consumer pool with user-tenant mappings in DynamoDB. Further issues are mandatory for manufacturing environments; consult with Multi-tenant software greatest practices.
Request routing to tenant knowledge utilizing JWT
In multi-tenant architectures the place sources are separated by tenant, requests from tenants are important to path to applicable sources. To study extra about tenant routing methods, see Tenant routing methods for SaaS purposes on AWS. This resolution makes use of an method just like data-driven routing as described within the publish for routing to OpenSearch Service.
The DynamoDB desk shops mapping data for tenant IDs, goal OpenSearch Service domains, and indexes as follows:
The JWT is obtained from the Authorization header in HTTP requests despatched from the frontend to the Lambda operate by way of API Gateway. The routing vacation spot is decided by retrieving the routing data utilizing the tenant ID obtained from parsing the JWT. Moreover, the JWT is used as authentication data for requests to OpenSearch, as described within the following part.
Multi-tenant isolation of knowledge places and entry permissions in OpenSearch Service
Multi-tenant knowledge isolation methods in OpenSearch Service embody three sorts of isolation patterns: domain-level, index-level, and document-level isolation, and hybrid fashions combining these. This resolution makes use of FGAC for entry permission management to tenant knowledge, creating devoted roles for every tenant.
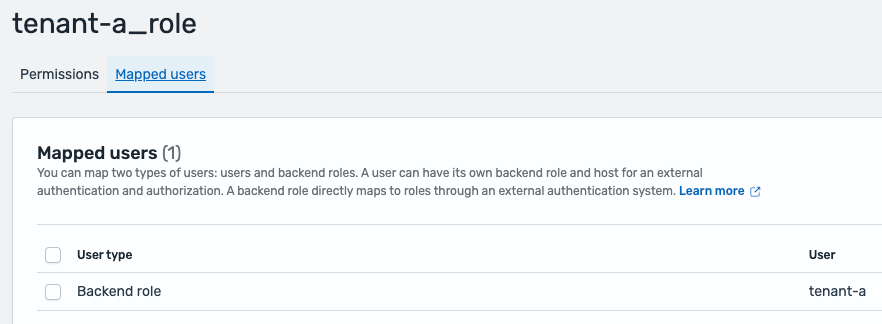
Mapping between tenant customers and FGAC tenant roles is applied by way of backend roles. In JWT authentication out there in OpenSearch Service, the attribute throughout the JWT payload to be linked with backend roles will be specified because the Roles key. The next screenshot reveals this area config.

The JWT payload features a tenant_id attribute as follows:"tenant_id": "tenant-a" Tenant customers and FGAC roles are linked by setting this attribute because the roles key in OpenSearch JWT authentication and mapping roles as follows:
The next screenshot reveals an instance of tenant function mapping in FGAC in OpenSearch Dashboards.
The pattern on this resolution supplies 4 tenants—tenant-a, tenant-b, tenant-c, and tenant-d—so you may strive all three isolation strategies. The next diagram illustrates this structure.
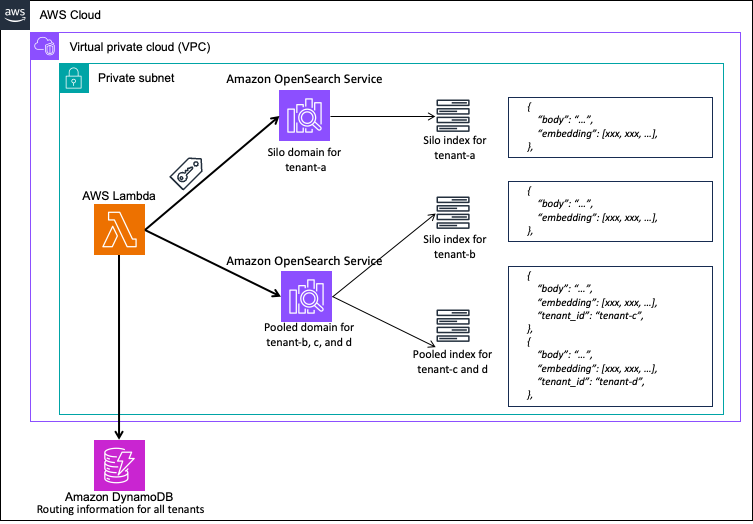
Every function is assigned permissions to entry solely the corresponding tenant knowledge. On this part, we introduce the best way to implement every of the three isolation strategies utilizing JWT and FGAC:
- Area-level isolation – Assign particular person OpenSearch Service domains to every tenant. As a result of domains are devoted to every tenant on this sample of isolation, there’s no want for knowledge isolation throughout the area. Due to this fact, FGAC roles grant entry permissions throughout the indexes. The next code is a part of
index_permissionswithin the FGAC function definition that grants entry to the indexes:
- Index-level isolation – A number of tenants share an OpenSearch Service area, with particular person indexes assigned to every tenant. Every tenant ought to solely be capable to entry their very own index, so
index_permissionswithin the FGAC function is configured as follows (instance for tenant-b):
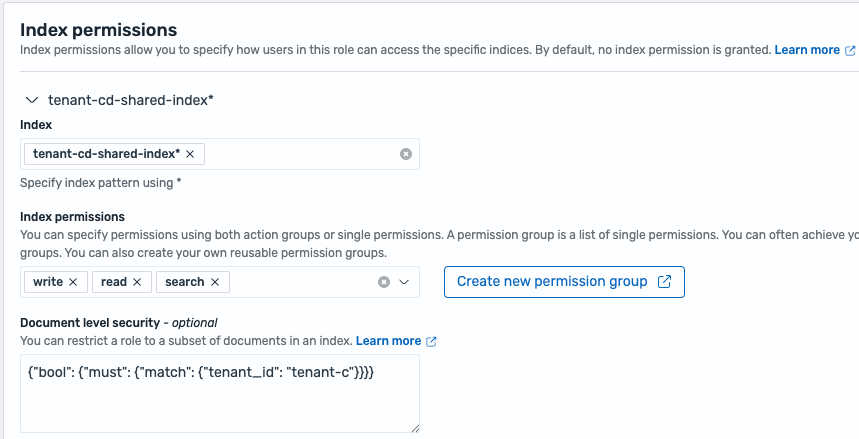
- Doc-level isolation – A number of tenants share OpenSearch Service domains and indexes, utilizing FGAC document-level safety for entry permission segregation of tenant knowledge throughout the index. Every index features a subject to retailer tenant ID data, and document-level safety queries are set for that subject. The next code is a part of
index_permissionsfor an FGAC function that permits tenant-c to entry solely its personal knowledge in a configuration the place tenant-c and tenant-d share an index:
The next screenshot reveals an instance of index permission for document-level isolation within the FGAC function.
Issues
The implementation on this publish makes use of a mannequin the place DynamoDB tables and S3 buckets are shared between tenants. For manufacturing use, think about partitioning fashions as launched in Partitioning Pooled Multi-Tenant SaaS Information with Amazon DynamoDB and Partitioning and Isolating Multi-Tenant SaaS Information with Amazon S3) and decide the optimum mannequin primarily based in your necessities.
Moreover, you need to use dynamic era of IAM insurance policies as a further layer to limit entry permissions to every useful resource.
Clear up
To keep away from surprising prices, we suggest deleting sources when they’re not wanted. As a result of the sources are created with the AWS CDK, run the cdk destroy command to delete them. This operation will even delete the paperwork uploaded to Amazon S3.
Conclusions
On this publish, we launched an answer that makes use of OpenSearch Service as a vector knowledge retailer in multi-tenant RAG, reaching knowledge isolation and routing utilizing JWT and FGAC.
This resolution makes use of a mix of JWT and FGAC to implement strict tenant knowledge entry isolation and routing, necessitating the usage of OpenSearch Service. The RAG software is applied independently, as a result of on the time of writing, Amazon Bedrock Data Bases can’t use JWT-based entry to OpenSearch Service.Multi-tenant RAG utilization is essential for SaaS corporations, and techniques fluctuate relying on necessities corresponding to knowledge isolation strictness, ease of administration, and price. This resolution implements a number of isolation fashions, so you may select primarily based in your necessities.For different options and data concerning multi-tenant RAG implementation, consult with the next sources:
In regards to the authors
 Kazuki Nagasawa is a Cloud Assist Engineer at Amazon Internet Companies. He focuses on Amazon OpenSearch Service and focuses on fixing clients’ technical challenges. In his spare time, he enjoys exploring whiskey varieties and discovering new ramen eating places.
Kazuki Nagasawa is a Cloud Assist Engineer at Amazon Internet Companies. He focuses on Amazon OpenSearch Service and focuses on fixing clients’ technical challenges. In his spare time, he enjoys exploring whiskey varieties and discovering new ramen eating places.
 Kensuke Fukumoto is a Senior Options Architect at Amazon Internet Companies. He’s enthusiastic about serving to ISVs and SaaS suppliers modernize their purposes and transition to SaaS fashions. In his free time, he enjoys driving bikes and visiting saunas.
Kensuke Fukumoto is a Senior Options Architect at Amazon Internet Companies. He’s enthusiastic about serving to ISVs and SaaS suppliers modernize their purposes and transition to SaaS fashions. In his free time, he enjoys driving bikes and visiting saunas.


{kind=link}