This publish is co-written with Qing Chen and Mark Sinclair from Radial.
Radial is the biggest 3PL success supplier, additionally providing built-in fee, fraud detection, and omnichannel options to mid-market and enterprise manufacturers. With over 30 years of business experience, Radial tailors its companies and options to align strategically with every model’s distinctive wants.
Radial helps manufacturers in tackling widespread ecommerce challenges, from scalable, versatile success enabling supply consistency to offering safe transactions. With a dedication to fulfilling guarantees from click on to supply, Radial empowers manufacturers to navigate the dynamic digital panorama with the boldness and functionality to ship a seamless, safe, and superior ecommerce expertise.
On this publish, we share how Radial optimized the fee and efficiency of their fraud detection machine studying (ML) functions by modernizing their ML workflow utilizing Amazon SageMaker.
Companies want for fraud detection fashions
ML has confirmed to be an efficient strategy in fraud detection in comparison with conventional approaches. ML fashions can analyze huge quantities of transactional information, be taught from historic fraud patterns, and detect anomalies that sign potential fraud in actual time. By repeatedly studying and adapting to new fraud patterns, ML can be sure fraud detection techniques keep resilient and strong towards evolving threats, enhancing detection accuracy and lowering false positives over time. This publish showcases how firms like Radial can modernize and migrate their on-premises fraud detection ML workflows to SageMaker. Through the use of the AWS Expertise-Primarily based Acceleration (EBA) program, they will improve effectivity, scalability, and maintainability by means of shut collaboration.
Challenges of on-premises ML fashions
Though ML fashions are extremely efficient at combating evolving fraud traits, managing these fashions on premises presents important scalability and upkeep challenges.
Scalability
On-premises techniques are inherently restricted by the bodily {hardware} accessible. Throughout peak procuring seasons, when transaction volumes surge, the infrastructure may battle to maintain up with out substantial upfront funding. This can lead to slower processing instances or a lowered capability to run a number of ML functions concurrently, probably resulting in missed fraud detections. Scaling an on-premises infrastructure is usually a sluggish and resource-intensive course of, hindering a enterprise’s capacity to adapt shortly to elevated demand. On the mannequin coaching facet, information scientists typically face bottlenecks attributable to restricted sources, forcing them to attend for infrastructure availability or cut back the scope of their experiments. This delays innovation and might result in suboptimal mannequin efficiency, placing companies at an obstacle in a quickly altering fraud panorama.
Upkeep
Sustaining an on-premises infrastructure for fraud detection requires a devoted IT crew to handle servers, storage, networking, and backups. Sustaining uptime typically includes implementing and sustaining redundant techniques, as a result of a failure might end in crucial downtime and an elevated danger of undetected fraud. Furthermore, fraud detection fashions naturally degrade over time and require common retraining, deployment, and monitoring. On-premises techniques sometimes lack the built-in automation instruments wanted to handle the complete ML lifecycle. Because of this, IT groups should manually deal with duties reminiscent of updating fashions, monitoring for drift, and deploying new variations. This provides operational complexity, will increase the probability of errors, and diverts worthwhile sources from different business-critical actions.
Widespread modernization challenges in ML cloud migration
Organizations face a number of important challenges when modernizing their ML workloads by means of cloud migration. One main hurdle is the talent hole, the place builders and information scientists may lack experience in microservices structure, superior ML instruments, and DevOps practices for cloud environments. This could result in growth delays, complicated and dear architectures, and elevated safety vulnerabilities. Cross-functional obstacles, characterised by restricted communication and collaboration between groups, can even impede modernization efforts by hindering data sharing. Gradual decision-making is one other crucial problem. Many organizations take too lengthy to make selections about their cloud transfer. They spend an excessive amount of time fascinated about choices as an alternative of taking motion. This delay may cause them to overlook possibilities to hurry up their modernization. It additionally stops them from utilizing the cloud’s capacity to shortly strive new issues and make adjustments. Within the fast-moving world of ML and cloud know-how, being sluggish to determine can put firms behind their opponents. One other important impediment is complicated mission administration, as a result of modernization initiatives typically require coordinating work throughout a number of groups with conflicting priorities. This problem is compounded by difficulties in aligning stakeholders on enterprise outcomes, quantifying and monitoring advantages to show worth, and balancing long-term advantages with short-term objectives. To handle these challenges and streamline modernization efforts, AWS gives the EBA program. This technique is designed to help clients in aligning executives’ imaginative and prescient and resolving roadblocks, accelerating their cloud journey, and reaching a profitable migration and modernization of their ML workloads to the cloud.
EBA: AWS crew collaboration
EBA is a 3-day interactive workshop that makes use of SageMaker to speed up enterprise outcomes. It guides members by means of a prescriptive ML lifecycle, beginning with figuring out enterprise objectives and ML downside framing, and progressing by means of information processing, mannequin growth, manufacturing deployment, and monitoring.
We acknowledge that clients have totally different beginning factors. For these starting from scratch, it’s typically easier to start out with low code or no code options like Amazon SageMaker Canvas and Amazon SageMaker JumpStart, steadily transitioning to growing customized fashions on Amazon SageMaker Studio. Nevertheless, as a result of Radial has an present on-premises ML infrastructure, we will start instantly through the use of SageMaker to deal with challenges of their present resolution.
Throughout the EBA, skilled AWS ML material consultants and the AWS Account Staff labored carefully with Radial’s cross-functional crew. The AWS crew supplied tailor-made recommendation, tackled obstacles, and enhanced the group’s capability for ongoing ML integration. As an alternative of concentrating solely on information and ML know-how, the emphasis is on addressing crucial enterprise challenges. This technique helps organizations extract important worth from beforehand underutilized sources.
Modernizing ML workflows: From a legacy on-premises information heart to SageMaker
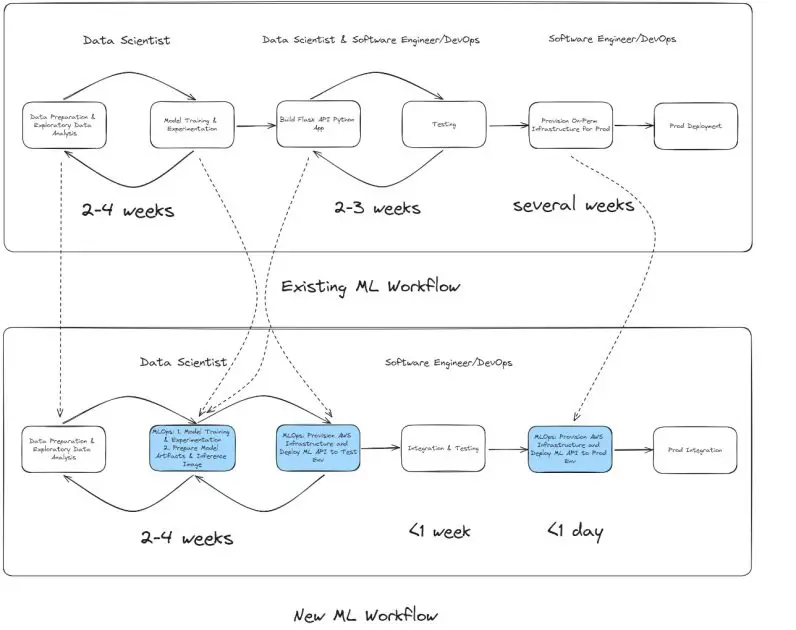
Earlier than modernization, Radial hosted its ML functions on premises inside its information heart. The legacy ML workflow offered a number of challenges, significantly within the time-intensive mannequin growth and deployment processes.
Legacy workflow: On-premises ML growth and deployment
When the information science crew wanted to construct a brand new fraud detection mannequin, the event course of sometimes took 2–4 weeks. Throughout this section, information scientists carried out duties reminiscent of the next:
- Knowledge cleansing and exploratory information evaluation (EDA)
- Function engineering
- Mannequin prototyping and coaching experiments
- Mannequin analysis to finalize the fraud detection mannequin
These steps have been carried out utilizing on-premises servers, which restricted the variety of experiments that may very well be run concurrently attributable to {hardware} constraints. After the mannequin was finalized, the information science crew handed over the mannequin artifacts and implementation code—together with detailed directions—to the software program builders and DevOps groups. This transition initiated the mannequin deployment course of, which concerned:
- Provisioning infrastructure – The software program crew arrange the required infrastructure to host the ML API in a take a look at atmosphere.
- API implementation and testing – Intensive testing and communication between the information science and software program groups have been required to verify the mannequin inference API behaved as anticipated. This section sometimes added 2–3 weeks to the timeline.
- Manufacturing deployment – The DevOps and system engineering groups provisioned and scaled on-premises {hardware} to deploy the ML API into manufacturing, a course of that might take as much as a number of weeks relying on useful resource availability.
Total, the legacy workflow was susceptible to delays and inefficiencies, with important communication overhead and a reliance on handbook provisioning.
Fashionable workflow: SageMaker and MLOps
With the migration to SageMaker and the adoption of a machine studying operations (MLOps) structure, Radial streamlined its complete ML lifecycle—from growth to deployment. The brand new workflow consists of the next phases:
- Mannequin growth – The info science crew continues to carry out duties reminiscent of information cleansing, EDA, characteristic engineering, and mannequin coaching inside 2–4 weeks. Nevertheless, with the scalable and on-demand compute sources of SageMaker, they will conduct extra coaching experiments in the identical timeframe, resulting in improved mannequin efficiency and quicker iterations.
- Seamless mannequin deployment – When a mannequin is prepared, the information science crew approves it in SageMaker and triggers the MLOps pipeline to deploy the mannequin to the take a look at (pre-production) atmosphere. This eliminates the necessity for back-and-forth communication with the software program crew at this stage. Key enhancements embody:
- The ML API inference code is preconfigured and wrapped by the information scientists throughout growth, offering constant conduct between growth and deployment.
- Deployment to check environments takes minutes, as a result of the MLOps pipeline automates infrastructure provisioning and deployment.
- Ultimate integration and testing – The software program crew shortly integrates the API and performs essential checks, reminiscent of integration and cargo testing. After the checks are profitable, the crew triggers the pipeline to deploy the ML fashions into manufacturing, which takes solely minutes.
The MLOps pipeline not solely automates the provisioning of cloud sources, but in addition gives consistency between pre-production and manufacturing environments, minimizing deployment dangers.
Legacy vs. fashionable workflow comparability
The brand new workflow considerably reduces time and complexity:
- Handbook provisioning and communication overheads are lowered
- Deployment instances are lowered from weeks to minutes
- Consistency between environments gives smoother transitions from growth to manufacturing
This transformation allows Radial to reply extra shortly to evolving fraud traits whereas sustaining excessive requirements of effectivity and reliability. The next determine gives a visible comparability of the legacy and fashionable ML workflows.
 Resolution overview
Resolution overview
When Radial migrated their fraud detection techniques to the cloud, they collaborated with AWS Machine Studying Specialists and Options Architects to revamp how Radial handle the lifecycle of ML fashions. Through the use of AWS and integrating steady integration and supply (CI/CD) pipelines with GitLab, Terraform, and AWS CloudFormation, Radial developed a scalable, environment friendly, and safe MLOps structure. This new design accelerates mannequin growth and deployment, so Radial can reply quicker to evolving fraud detection challenges.
The structure incorporates greatest practices in MLOps, ensuring that the totally different phases of the ML lifecycle—from information preparation to manufacturing deployment—are optimized for efficiency and reliability. Key parts of the answer embody:
- SageMaker – Central to the structure, SageMaker facilitates mannequin coaching, analysis, and deployment with built-in instruments for monitoring and model management
- GitLab CI/CD pipelines – These pipelines automate the workflows for testing, constructing, and deploying ML fashions, lowering handbook overhead and offering constant processes throughout environments
- Terraform and AWS CloudFormation – These companies allow infrastructure as code (IaC) to provision and handle AWS sources, offering a repeatable and scalable setup for ML functions
The general resolution structure is illustrated within the following determine, showcasing how every element integrates seamlessly to assist Radial’s fraud detection initiatives.

Account isolation for safe and scalable MLOps
To streamline operations and implement safety, the MLOps structure is constructed on a multi-account technique that isolates environments primarily based on their objective. This design enforces strict safety boundaries, reduces dangers, and promotes environment friendly collaboration throughout groups. The accounts are as follows:
- Improvement account (mannequin growth workspace) – The event account is a devoted workspace for information scientists to experiment and develop fashions. Safe information administration is enforced by isolating datasets inside Amazon Easy Storage Service (Amazon S3) buckets. Knowledge scientists use SageMaker Studio for information exploration, characteristic engineering, and scalable mannequin coaching. When the mannequin construct CI/CD pipeline in GitLab is triggered, Terraform and CloudFormation scripts automate the provisioning of infrastructure and AWS sources wanted for SageMaker coaching pipelines. Skilled fashions that meet predefined analysis metrics are versioned and registered within the Amazon SageMaker Mannequin Registry. With this setup, information scientists and ML engineers can carry out a number of rounds of coaching experiments, assessment outcomes, and finalize the perfect mannequin for deployment testing.
- Pre-production account (staging atmosphere) – After a mannequin is validated and authorised within the growth account, it’s moved to the pre-production account for staging. At this stage, the information science crew triggers the mannequin deploy CI/CD pipeline in GitLab to configure the endpoint within the pre-production atmosphere. Mannequin artifacts and inference pictures are synced from the event account to the pre-production atmosphere. The newest authorised mannequin is deployed as an API in a SageMaker endpoint, the place it undergoes thorough integration and cargo testing to validate efficiency and reliability.
- Manufacturing account (reside atmosphere) – After passing the pre-production checks, the mannequin is promoted to the manufacturing account for reside deployment. This account mirrors the configurations of the pre-production atmosphere to take care of consistency and reliability. The MLOps manufacturing crew triggers the mannequin deploy CI/CD pipeline to launch the manufacturing ML API. When it’s reside, the mannequin is repeatedly monitored utilizing Amazon SageMaker Mannequin Monitor and Amazon CloudWatch to verify it performs as anticipated. Within the occasion of deployment points, automated rollback mechanisms revert to a steady mannequin model, minimizing disruptions and sustaining enterprise continuity.
With this multi-account structure, information scientists can work independently whereas offering seamless transitions between growth and manufacturing. The automation of CI/CD pipelines reduces deployment cycles, enhances scalability, and gives the safety and efficiency essential to take care of efficient fraud detection techniques.
Knowledge privateness and compliance necessities
Radial prioritizes the safety and safety of their clients’ information. As a frontrunner in ecommerce options, they’re dedicated to assembly the excessive requirements of information privateness and regulatory compliance reminiscent of CPPA and PCI. Radial fraud detection ML APIs course of delicate data reminiscent of transaction particulars and behavioral analytics. To satisfy strict compliance necessities, they use AWS Direct Join, Amazon Digital Non-public Cloud (Amazon VPC), and Amazon S3 with AWS Key Administration Service (AWS KMS) encryption to construct a safe and compliant structure.
Defending information in transit with Direct Join
Knowledge is rarely uncovered to the general public web at any stage. To take care of the safe switch of delicate information between on-premises techniques and AWS environments, Radial makes use of Direct Join, which gives the next capabilities:
- Devoted community connection – Direct Join establishes a non-public, high-speed connection between the information heart and AWS, assuaging the dangers related to public web site visitors, reminiscent of interception or unauthorized entry
- Constant and dependable efficiency – Direct Join gives constant bandwidth and low latency, ensuring fraud detection APIs function with out delays, even throughout peak transaction volumes
Isolating workloads with Amazon VPC
When information reaches AWS, it’s processed in a VPC for max safety. This gives the next advantages:
- Non-public subnets for delicate information – The parts of the fraud detection ML API, together with SageMaker endpoints and AWS Lambda capabilities, reside in non-public subnets, which aren’t accessible from the general public web
- Managed entry with safety teams – Strict entry management is enforced by means of safety teams and community entry management lists (ACLs), permitting solely approved techniques and customers to work together with VPC sources
- Knowledge segregation by account – As talked about beforehand relating to the multi-account technique, workloads are remoted throughout growth, staging, and manufacturing accounts, every with its personal VPC, to restrict cross-environment entry and keep compliance.
Securing information at relaxation with Amazon S3 and AWS KMS encryption
Knowledge concerned within the fraud detection workflows (for each mannequin growth and real-time inference) is securely saved in Amazon S3, with encryption powered by AWS KMS. This gives the next advantages:
- AWS KMS encryption for delicate information – Transaction logs, mannequin artifacts, and prediction outcomes are encrypted at relaxation utilizing managed KMS keys
- Encryption in transit – Interactions with Amazon S3, together with uploads and downloads, are encrypted to verify information stays safe throughout switch
- Knowledge retention insurance policies – Lifecycle insurance policies implement information retention limits, ensuring delicate information is saved solely so long as essential for compliance and enterprise functions earlier than scheduled deletion
Knowledge privateness by design
Knowledge privateness is built-in into each step of the ML API workflow:
- Safe inference – Incoming transaction information is processed inside VPC-secured SageMaker endpoints, ensuring predictions are made in a non-public atmosphere
- Minimal information retention – Actual-time transaction information is anonymized the place attainable, and solely aggregated outcomes are saved for future evaluation
- Entry management and governance – Sources are ruled by AWS Id and Entry Administration (IAM) insurance policies, ensuring solely approved personnel and companies can entry information and infrastructure
Advantages of the brand new ML workflow on AWS
To summarize, the implementation of the brand new ML workflow on AWS gives a number of key advantages:
- Dynamic scalability – AWS allows Radial to scale their infrastructure dynamically to deal with spikes in each mannequin coaching and real-time inference site visitors, offering optimum efficiency throughout peak intervals.
- Quicker infrastructure provisioning – The brand new workflow accelerates the mannequin deployment cycle, lowering the time to provision infrastructure and deploy new fashions by as much as a number of weeks.
- Consistency in mannequin coaching and deployment – By streamlining the method, Radial achieves constant mannequin coaching and deployment throughout environments. This reduces communication overhead between the information science crew and engineering/DevOps groups, simplifying the implementation of mannequin deployment.
- Infrastructure as code – With IaC, they profit from model management and reusability, lowering handbook configurations and minimizing the chance of errors throughout deployment.
- Constructed-in mannequin monitoring – The built-in capabilities of SageMaker, reminiscent of experiment monitoring and information drift detection, assist them keep mannequin efficiency and supply well timed updates.
Key takeaways and classes discovered from Radial’s ML mannequin migration
To assist modernize your MLOps workflow on AWS, the next are just a few key takeaways and classes discovered from Radial’s expertise:
- Collaborate with AWS for custom-made options – Have interaction with AWS to debate your particular use instances and establish templates that carefully match your necessities. Though AWS gives a variety of templates for widespread MLOps eventualities, they may should be custom-made to suit your distinctive wants. Discover methods to adapt these templates for migrating or revamping your ML workflows.
- Iterative customization and assist – As you customise your resolution, work carefully with each your inner crew and AWS Help to deal with any points. Plan for execution-based assessments and schedule workshops with AWS to resolve challenges at every stage. This may be an iterative course of, however it makes positive your modules are optimized in your atmosphere.
- Use account isolation for safety and collaboration – Use account isolation to separate mannequin growth, pre-production, and manufacturing environments. This setup promotes seamless collaboration between your information science crew and DevOps/MLOps crew, whereas additionally implementing sturdy safety boundaries between environments.
- Preserve scalability with correct configuration – Radial’s fraud detection fashions efficiently dealt with transaction spikes throughout peak seasons. To take care of scalability, configure occasion quota limits appropriately inside AWS, and conduct thorough load testing earlier than peak site visitors intervals to keep away from any efficiency points throughout high-demand instances.
- Safe mannequin metadata sharing – Think about opting out of sharing mannequin metadata when constructing your SageMaker pipeline to verify your aggregate-level mannequin data stays safe.
- Forestall picture conflicts with correct configuration – When utilizing an AWS managed picture for mannequin inference, specify a hash digest inside your SageMaker pipeline. As a result of the most recent hash digest may change dynamically for a similar picture mannequin model, this step helps keep away from conflicts when retrieving inference pictures throughout mannequin deployment.
- Positive-tune scaling metrics by means of load testing – Positive-tune scaling metrics, reminiscent of occasion sort and automated scaling thresholds, primarily based on correct load testing. Simulate your corporation’s site visitors patterns throughout each regular and peak intervals to verify your infrastructure scales successfully.
- Applicability past fraud detection – Though the implementation described right here is tailor-made to fraud detection, the MLOps structure is adaptable to a variety of ML use instances. Corporations seeking to modernize their MLOps workflows can apply the identical ideas to varied ML tasks.
Conclusion
This publish demonstrated the high-level strategy taken by Radial’s fraud crew to efficiently modernize their ML workflow by implementing an MLOps pipeline and migrating from on premises to the AWS Cloud. This was achieved by means of shut collaboration with AWS in the course of the EBA course of. The EBA course of begins with 4–6 weeks of preparation, culminating in a 3-day intensive workshop the place a minimal viable MLOps pipeline is created utilizing SageMaker, Amazon S3, GitLab, Terraform, and AWS CloudFormation. Following the EBA, groups sometimes spend a further 2–6 weeks to refine the pipeline and fine-tune the fashions by means of characteristic engineering and hyperparameter optimization earlier than manufacturing deployment. This strategy enabled Radial to successfully choose related AWS companies and options, accelerating the coaching, deployment, and testing of ML fashions in a pre-production SageMaker atmosphere. Because of this, Radial efficiently deployed a number of new ML fashions on AWS of their manufacturing atmosphere round Q3 2024, reaching a greater than 75% discount in ML mannequin deployment cycle and a 9% enchancment in general mannequin efficiency.
“Within the ecommerce retail house, mitigating fraudulent transactions and enhancing shopper experiences are high priorities for retailers. Excessive-performing machine studying fashions have turn out to be invaluable instruments in reaching these objectives. By leveraging AWS companies, we’ve efficiently constructed a modernized machine studying workflow that permits speedy iterations in a steady and safe atmosphere.”
– Lan Zhang, Head of Knowledge Science and Superior Analytics
To be taught extra about EBAs and the way this strategy can profit your group, attain out to your AWS Account Supervisor or Buyer Options Supervisor. For extra data, consult with Utilizing experience-based acceleration to attain your transformation and Get to Know EBA.
Concerning the Authors
 Jake Wen is a Options Architect at AWS, pushed by a ardour for Machine Studying, Pure Language Processing, and Deep Studying. He assists Enterprise clients in reaching modernization and scalable deployment within the Cloud. Past the tech world, Jake finds enjoyment of skateboarding, climbing, and piloting air drones.
Jake Wen is a Options Architect at AWS, pushed by a ardour for Machine Studying, Pure Language Processing, and Deep Studying. He assists Enterprise clients in reaching modernization and scalable deployment within the Cloud. Past the tech world, Jake finds enjoyment of skateboarding, climbing, and piloting air drones.
 Qing Chen is a senior information scientist at Radial, a full-stack resolution supplier for ecommerce retailers. In his function, he modernizes and manages the machine studying framework within the fee & fraud group, driving a stable data-driven fraud decisioning movement to steadiness danger & buyer friction for retailers.
Qing Chen is a senior information scientist at Radial, a full-stack resolution supplier for ecommerce retailers. In his function, he modernizes and manages the machine studying framework within the fee & fraud group, driving a stable data-driven fraud decisioning movement to steadiness danger & buyer friction for retailers.
 Mark Sinclair is a senior cloud architect at Radial, a full-stack resolution supplier for ecommerce retailers. In his function, he designs, implements and manages the cloud infrastructure and DevOps for Radial engineering techniques, driving a stable engineering structure and workflow to offer extremely scalable transactional companies for Radial shoppers.
Mark Sinclair is a senior cloud architect at Radial, a full-stack resolution supplier for ecommerce retailers. In his function, he designs, implements and manages the cloud infrastructure and DevOps for Radial engineering techniques, driving a stable engineering structure and workflow to offer extremely scalable transactional companies for Radial shoppers.



{kind=link}