Immediately, we’re excited to announce that Mistral-Small-3.2-24B-Instruct-2506—a 24-billion-parameter massive language mannequin (LLM) from Mistral AI that’s optimized for enhanced instruction following and decreased repetition errors—is obtainable for purchasers by means of Amazon SageMaker JumpStart and Amazon Bedrock Market. Amazon Bedrock Market is a functionality in Amazon Bedrock that builders can use to find, take a look at, and use over 100 widespread, rising, and specialised basis fashions (FMs) alongside the present collection of industry-leading fashions in Amazon Bedrock.
On this publish, we stroll by means of the way to uncover, deploy, and use Mistral-Small-3.2-24B-Instruct-2506 by means of Amazon Bedrock Market and with SageMaker JumpStart.
Overview of Mistral Small 3.2 (2506)
Mistral Small 3.2 (2506) is an replace of Mistral-Small-3.1-24B-Instruct-2503, sustaining the identical 24-billion-parameter structure whereas delivering enhancements in key areas. Launched underneath Apache 2.0 license, this mannequin maintains a stability between efficiency and computational effectivity. Mistral provides each the pretrained (Mistral-Small-3.1-24B-Base-2503) and instruction-tuned (Mistral-Small-3.2-24B-Instruct-2506) checkpoints of the mannequin underneath Apache 2.0.
Key enhancements in Mistral Small 3.2 (2506) embrace:
- Improves in following exact directions with 84.78% accuracy in comparison with 82.75% in model 3.1 from Mistral’s benchmarks
- Produces twice as fewer infinite generations or repetitive solutions, lowering from 2.11% to 1.29% in accordance with Mistral
- Presents a extra strong and dependable operate calling template for structured API interactions
- Now contains image-text-to-text capabilities, permitting the mannequin to course of and purpose over each textual and visible inputs. This makes it very best for duties similar to doc understanding, visible Q&A, and image-grounded content material era.
These enhancements make the mannequin significantly well-suited for enterprise purposes on AWS the place reliability and precision are essential. With a 128,000-token context window, the mannequin can course of intensive paperwork and preserve context all through longer dialog.
SageMaker JumpStart overview
SageMaker JumpStart is a completely managed service that provides state-of-the-art FMs for numerous use instances similar to content material writing, code era, query answering, copywriting, summarization, classification, and data retrieval. It supplies a group of pre-trained fashions that you would be able to deploy rapidly, accelerating the event and deployment of machine studying (ML) purposes. One of many key elements of SageMaker JumpStart is mannequin hubs, which supply an enormous catalog of pre-trained fashions, similar to Mistral, for quite a lot of duties.
Now you can uncover and deploy Mistral fashions in Amazon SageMaker Studio or programmatically by means of the Amazon SageMaker Python SDK, deriving mannequin efficiency and MLOps controls with SageMaker options similar to Amazon SageMaker Pipelines, Amazon SageMaker Debugger, or container logs. The mannequin is deployed in a safe AWS surroundings and underneath your digital non-public cloud (VPC) controls, serving to to assist information safety for enterprise safety wants.
Stipulations
To deploy Mistral-Small-3.2-24B-Instruct-2506, you could have the next conditions:
- An AWS account that may include all of your AWS assets.
- An AWS Identification and Entry Administration (IAM) position to entry SageMaker. To be taught extra about how IAM works with SageMaker, see Identification and Entry Administration for Amazon SageMaker.
- Entry to SageMaker Studio, a SageMaker pocket book occasion, or an interactive growth surroundings (IDE) similar to PyCharm or Visible Studio Code. We suggest utilizing SageMaker Studio for easy deployment and inference.
- Entry to accelerated cases (GPUs) for internet hosting the mannequin.
If wanted, request a quota improve and speak to your AWS account workforce for assist. This mannequin requires a GPU-based occasion sort (roughly 55 GB of GPU RAM in bf16 or fp16) similar to ml.g6.12xlarge.
Deploy Mistral-Small-3.2-24B-Instruct-2506 in Amazon Bedrock Market
To entry Mistral-Small-3.2-24B-Instruct-2506 in Amazon Bedrock Market, full the next steps:
- On the Amazon Bedrock console, within the navigation pane underneath Uncover, select Mannequin catalog.
- Filter for Mistral as a supplier and select the Mistral-Small-3.2-24B-Instruct-2506 mannequin.
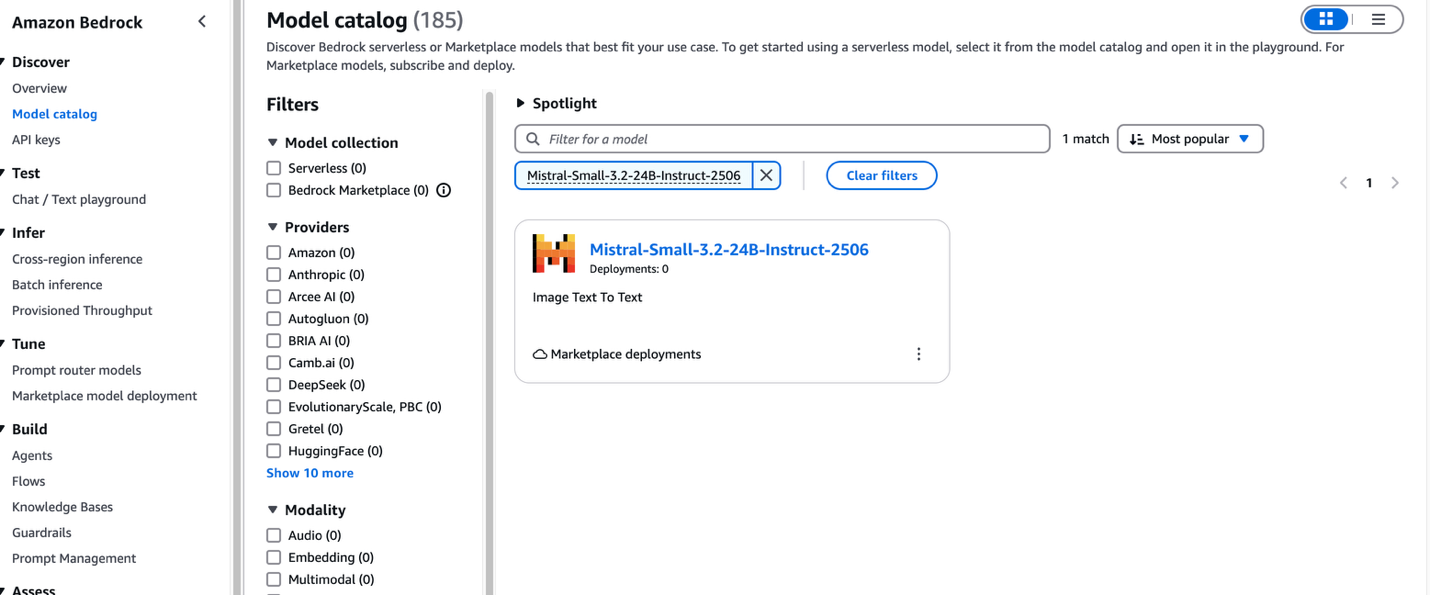
The mannequin element web page supplies important details about the mannequin’s capabilities, pricing construction, and implementation tips. You could find detailed utilization directions, together with pattern API calls and code snippets for integration.The web page additionally contains deployment choices and licensing info that can assist you get began with Mistral-Small-3.2-24B-Instruct-2506 in your purposes.
- To start utilizing Mistral-Small-3.2-24B-Instruct-2506, select Deploy.
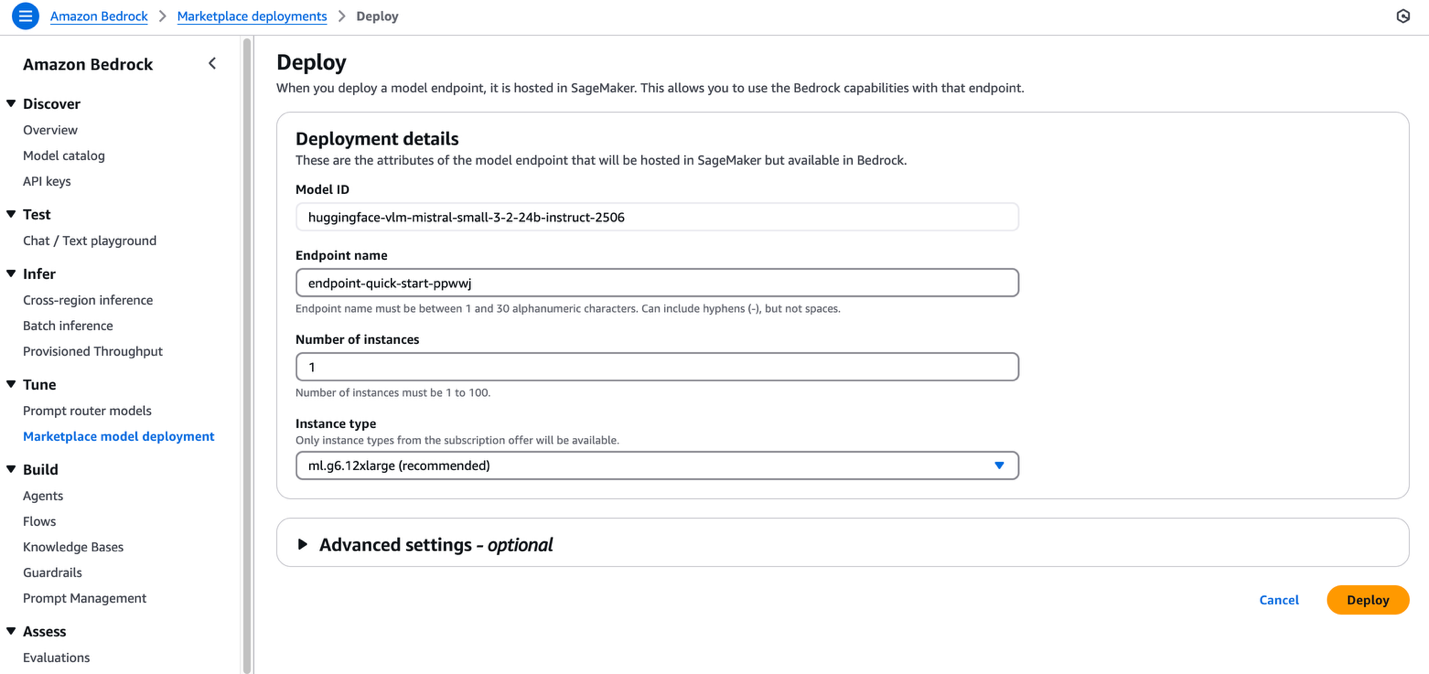
- You can be prompted to configure the deployment particulars for Mistral-Small-3.2-24B-Instruct-2506. The mannequin ID can be pre-populated.
- For Endpoint title, enter an endpoint title (as much as 50 alphanumeric characters).
- For Variety of cases, enter a quantity between 1–100.
- For Occasion sort, select your occasion sort. For optimum efficiency with Mistral-Small-3.2-24B-Instruct-2506, a GPU-based occasion sort similar to ml.g6.12xlarge is really helpful.
- Optionally, configure superior safety and infrastructure settings, together with VPC networking, service position permissions, and encryption settings. For many use instances, the default settings will work effectively. Nevertheless, for manufacturing deployments, assessment these settings to align along with your group’s safety and compliance necessities.
- Select Deploy to start utilizing the mannequin.
When the deployment is full, you’ll be able to take a look at Mistral-Small-3.2-24B-Instruct-2506 capabilities instantly within the Amazon Bedrock playground, a device on the Amazon Bedrock console to offer a visible interface to experiment with operating completely different fashions.
- Select Open in playground to entry an interactive interface the place you’ll be able to experiment with completely different prompts and modify mannequin parameters similar to temperature and most size.

The playground supplies fast suggestions, serving to you perceive how the mannequin responds to varied inputs and letting you fine-tune your prompts for optimum outcomes.
To invoke the deployed mannequin programmatically with Amazon Bedrock APIs, you have to get the endpoint Amazon Useful resource Identify (ARN). You should use the Converse API for multimodal use instances. For device use and performance calling, use the Invoke Mannequin API.
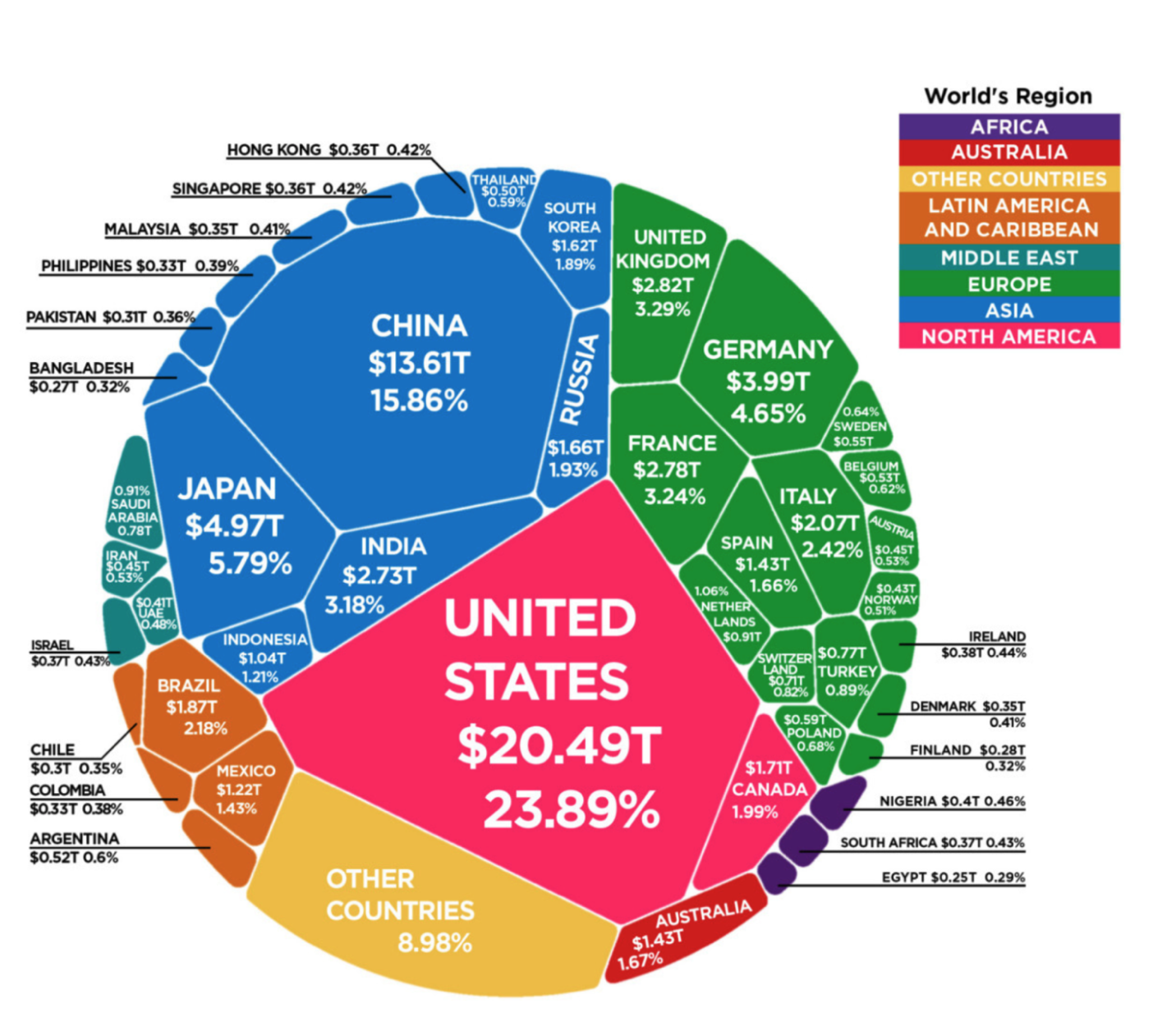
Reasoning of complicated figures
VLMs excel at deciphering and reasoning about complicated figures, charts, and diagrams. On this specific use case, we use Mistral-Small-3.2-24B-Instruct-2506 to research an intricate picture containing GDP information. Its superior capabilities in doc understanding and complicated determine evaluation make it well-suited for extracting insights from visible representations of financial information. By processing each the visible parts and accompanying textual content, Mistral Small 2506 can present detailed interpretations and reasoned evaluation of the GDP figures introduced within the picture.
We use the next enter picture.
We have now outlined helper capabilities to invoke the mannequin utilizing the Amazon Bedrock Converse API:
Our immediate and enter payload are as follows:
The next is a response utilizing the Converse API:
Deploy Mistral-Small-3.2-24B-Instruct-2506 in SageMaker JumpStart
You may entry Mistral-Small-3.2-24B-Instruct-2506 by means of SageMaker JumpStart within the SageMaker JumpStart UI and the SageMaker Python SDK. SageMaker JumpStart is an ML hub with FMs, built-in algorithms, and prebuilt ML options that you would be able to deploy with just some clicks. With SageMaker JumpStart, you’ll be able to customise pre-trained fashions to your use case, along with your information, and deploy them into manufacturing utilizing both the UI or SDK.
Deploy Mistral-Small-3.2-24B-Instruct-2506 by means of the SageMaker JumpStart UI
Full the next steps to deploy the mannequin utilizing the SageMaker JumpStart UI:
- On the SageMaker console, select Studio within the navigation pane.
- First-time customers can be prompted to create a site. If not, select Open Studio.
- On the SageMaker Studio console, entry SageMaker JumpStart by selecting JumpStart within the navigation pane.
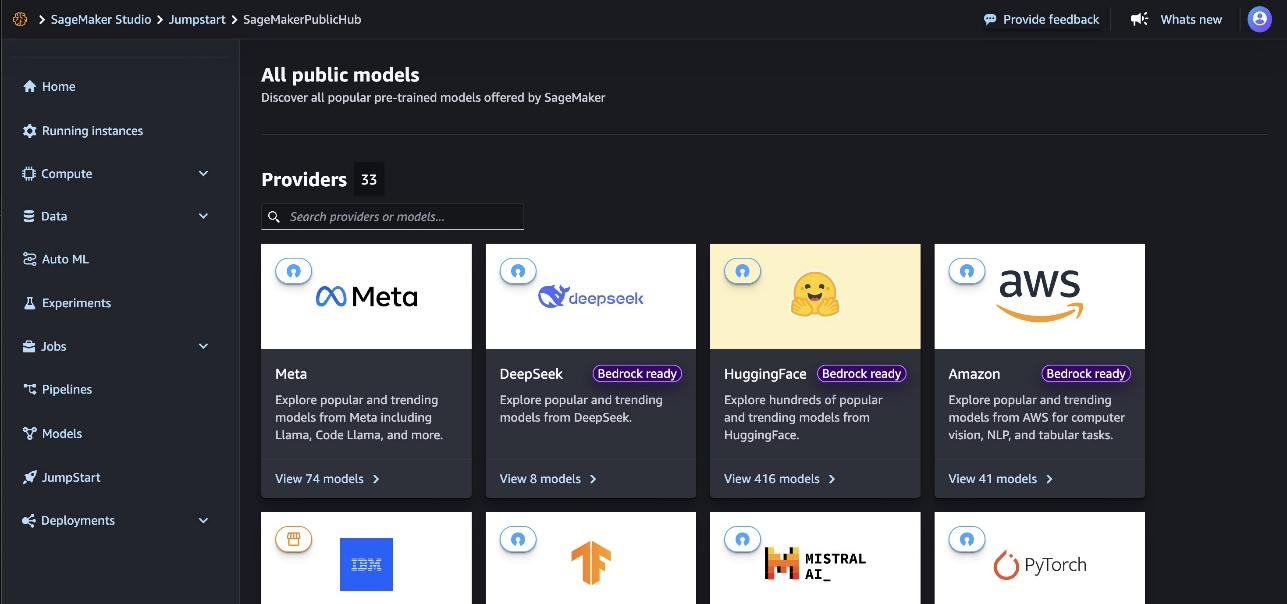
- Seek for and select Mistral-Small-3.2-24B-Instruct-2506 to view the mannequin card.
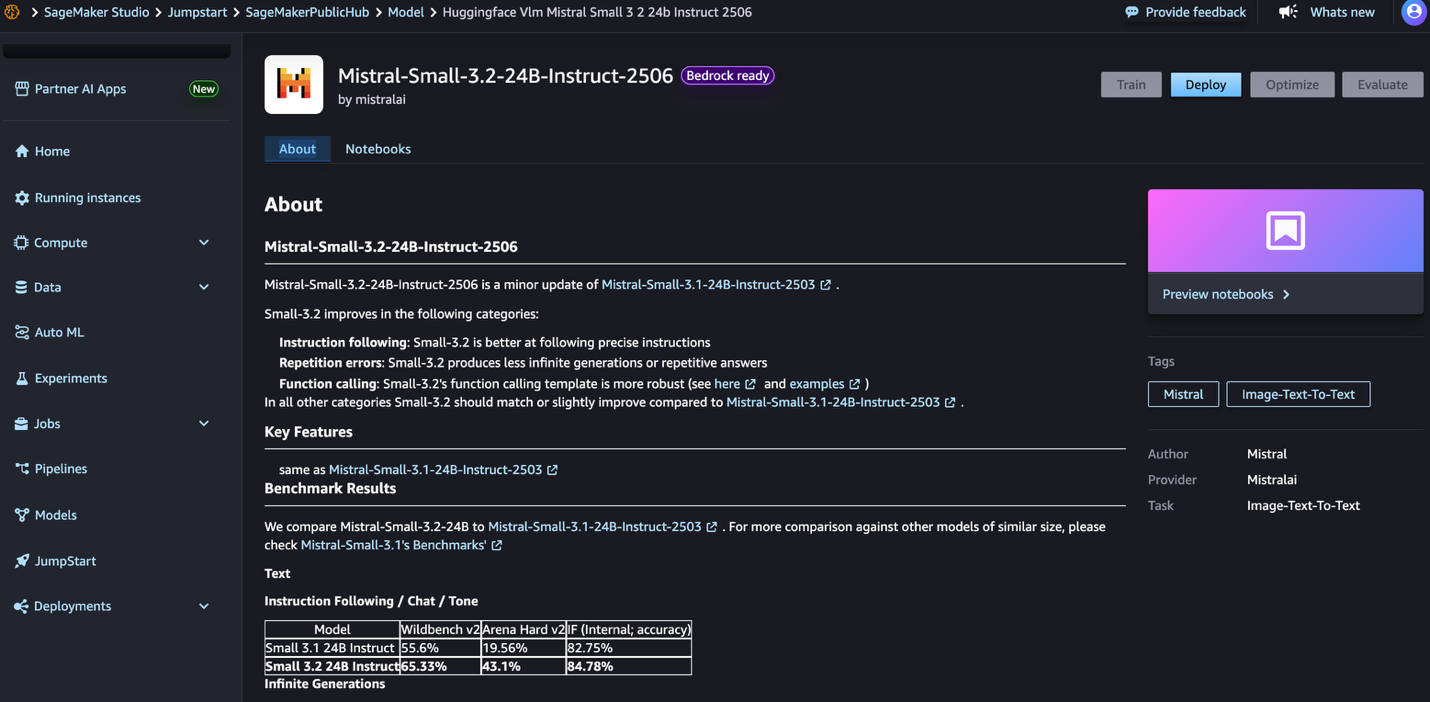
- Click on the mannequin card to view the mannequin particulars web page. Earlier than you deploy the mannequin, assessment the configuration and mannequin particulars from this mannequin card. The mannequin particulars web page contains the next info:
- The mannequin title and supplier info.
- A Deploy button to deploy the mannequin.
- About and Notebooks tabs with detailed info.
- The Bedrock Prepared badge (if relevant) signifies that this mannequin might be registered with Amazon Bedrock, so you should utilize Amazon Bedrock APIs to invoke the mannequin.
- Select Deploy to proceed with deployment.
- For Endpoint title, enter an endpoint title (as much as 50 alphanumeric characters).
- For Variety of cases, enter a quantity between 1–100 (default: 1).
- For Occasion sort, select your occasion sort. For optimum efficiency with Mistral-Small-3.2-24B-Instruct-2506, a GPU-based occasion sort similar to ml.g6.12xlarge is really helpful.
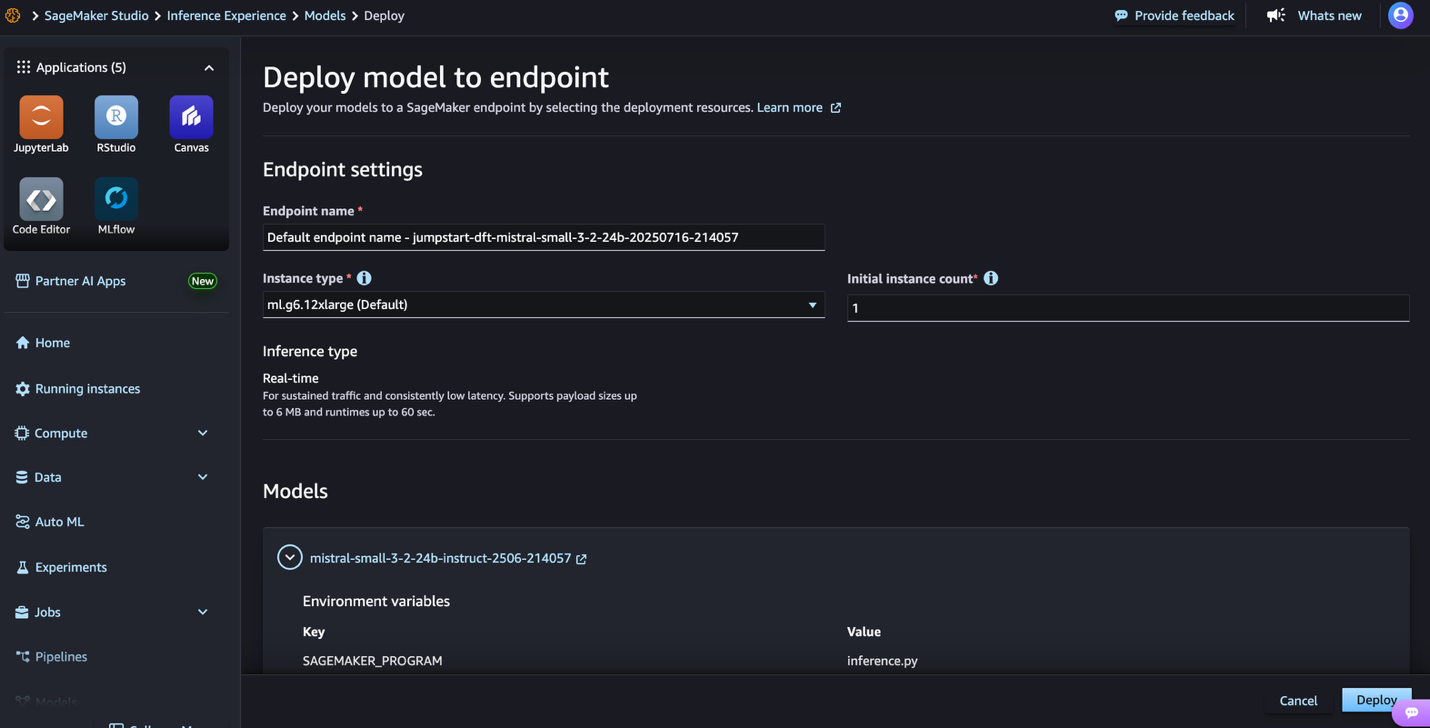
- Select Deploy to deploy the mannequin and create an endpoint.
When deployment is full, your endpoint standing will change to InService. At this level, the mannequin is able to settle for inference requests by means of the endpoint. You may invoke the mannequin utilizing a SageMaker runtime consumer and combine it along with your purposes.
Deploy Mistral-Small-3.2-24B-Instruct-2506 with the SageMaker Python SDK
Deployment begins while you select Deploy. After deployment finishes, you will notice that an endpoint is created. Check the endpoint by passing a pattern inference request payload or by choosing the testing possibility utilizing the SDK. When you choose the choice to make use of the SDK, you will notice instance code that you should utilize within the pocket book editor of your alternative in SageMaker Studio.
To deploy utilizing the SDK, begin by choosing the Mistral-Small-3.2-24B-Instruct-2506 mannequin, specified by the model_id with the worth mistral-small-3.2-24B-instruct-2506. You may deploy your alternative of the chosen fashions on SageMaker utilizing the next code. Equally, you’ll be able to deploy Mistral-Small-3.2-24B-Instruct-2506 utilizing its mannequin ID.
After the mannequin is deployed, you’ll be able to run inference towards the deployed endpoint by means of the SageMaker predictor:
Imaginative and prescient reasoning instance
Utilizing the multimodal capabilities of Mistral-Small-3.2-24B-Instruct-2506, you’ll be able to course of each textual content and pictures for complete evaluation. The next instance highlights how the mannequin can concurrently analyze a tuition ROI chart to extract visible patterns and information factors. The next picture is the enter chart.png.
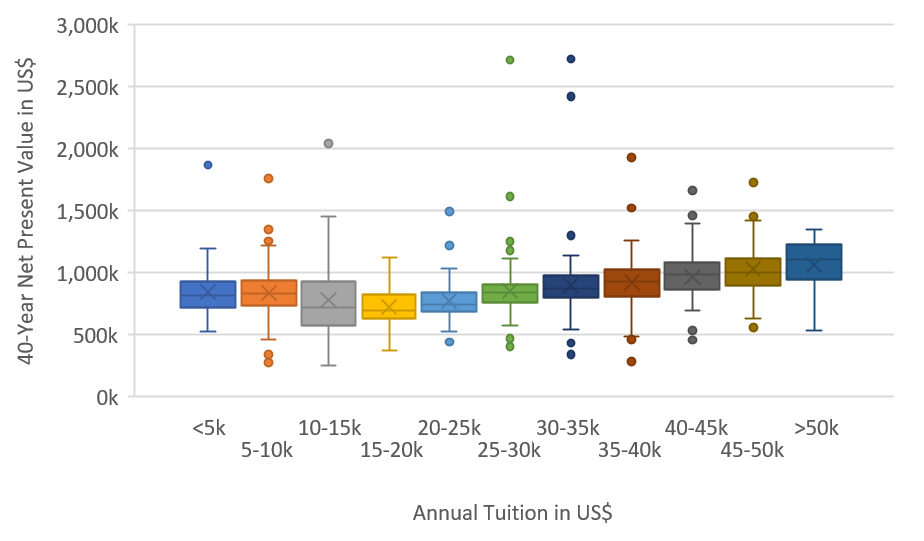
Our immediate and enter payload are as follows:
We get following response:
Operate calling instance
This following instance reveals Mistral Small 3.2’s operate calling by demonstrating how the mannequin identifies when a consumer query wants exterior information and calls the proper operate with correct parameters.Our immediate and enter payload are as follows:
We get following response:
Clear up
To keep away from undesirable costs, full the next steps on this part to scrub up your assets.
Delete the Amazon Bedrock Market deployment
Should you deployed the mannequin utilizing Amazon Bedrock Market, full the next steps:
- On the Amazon Bedrock console, underneath Tune within the navigation pane, choose Market mannequin deployment.
- Within the Managed deployments part, find the endpoint you need to delete.
- Choose the endpoint, and on the Actions menu, select Delete.
- Confirm the endpoint particulars to ensure you’re deleting the proper deployment:
- Endpoint title
- Mannequin title
- Endpoint standing
- Select Delete to delete the endpoint.
- Within the deletion affirmation dialog, assessment the warning message, enter affirm, and select Delete to completely take away the endpoint.
Delete the SageMaker JumpStart predictor
After you’re performed operating the pocket book, ensure that to delete the assets that you simply created within the course of to keep away from extra billing. For extra particulars, see Delete Endpoints and Sources. You should use the next code:
Conclusion
On this publish, we confirmed you the way to get began with Mistral-Small-3.2-24B-Instruct-2506 and deploy the mannequin utilizing Amazon Bedrock Market and SageMaker JumpStart for inference. This newest model of the mannequin brings enhancements in instruction following, decreased repetition errors, and enhanced operate calling capabilities whereas sustaining efficiency throughout textual content and imaginative and prescient duties. The mannequin’s multimodal capabilities, mixed with its improved reliability and precision, assist enterprise purposes requiring strong language understanding and era.
Go to SageMaker JumpStart in Amazon SageMaker Studio or Amazon Bedrock Market now to get began with Mistral-Small-3.2-24B-Instruct-2506.
For extra Mistral assets on AWS, try the Mistral-on-AWS GitHub repo.
Concerning the authors
 Niithiyn Vijeaswaran is a Generative AI Specialist Options Architect with the Third-Celebration Mannequin Science workforce at AWS. His space of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s diploma in Laptop Science and Bioinformatics.
Niithiyn Vijeaswaran is a Generative AI Specialist Options Architect with the Third-Celebration Mannequin Science workforce at AWS. His space of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s diploma in Laptop Science and Bioinformatics.
 Breanne Warner is an Enterprise Options Architect at Amazon Internet Companies supporting healthcare and life science (HCLS) prospects. She is obsessed with supporting prospects to make use of generative AI on AWS and evangelizing mannequin adoption for first- and third-party fashions. Breanne can be Vice President of the Ladies at Amazon board with the aim of fostering inclusive and various tradition at Amazon. Breanne holds a Bachelor’s of Science in Laptop Engineering from the College of Illinois Urbana-Champaign.
Breanne Warner is an Enterprise Options Architect at Amazon Internet Companies supporting healthcare and life science (HCLS) prospects. She is obsessed with supporting prospects to make use of generative AI on AWS and evangelizing mannequin adoption for first- and third-party fashions. Breanne can be Vice President of the Ladies at Amazon board with the aim of fostering inclusive and various tradition at Amazon. Breanne holds a Bachelor’s of Science in Laptop Engineering from the College of Illinois Urbana-Champaign.
 Koushik Mani is an Affiliate Options Architect at AWS. He beforehand labored as a Software program Engineer for two years specializing in machine studying and cloud computing use instances at Telstra. He accomplished his Grasp’s in Laptop Science from the College of Southern California. He’s obsessed with machine studying and generative AI use instances and constructing options.
Koushik Mani is an Affiliate Options Architect at AWS. He beforehand labored as a Software program Engineer for two years specializing in machine studying and cloud computing use instances at Telstra. He accomplished his Grasp’s in Laptop Science from the College of Southern California. He’s obsessed with machine studying and generative AI use instances and constructing options.



{kind=link}