As companies and builders more and more search to optimize their language fashions for particular duties, the choice between mannequin customization and Retrieval Augmented Era (RAG) turns into important. On this put up, we search to handle this rising want by providing clear, actionable pointers and greatest practices on when to make use of every strategy, serving to you make knowledgeable choices that align together with your distinctive necessities and targets.
The introduction of Amazon Nova fashions characterize a big development within the discipline of AI, providing new alternatives for big language mannequin (LLM) optimization. On this put up, we exhibit learn how to successfully carry out mannequin customization and RAG with Amazon Nova fashions as a baseline. We carried out a complete comparability examine between mannequin customization and RAG utilizing the most recent Amazon Nova fashions, and share these beneficial insights.
Method and base mannequin overview
On this part, we talk about the variations between a fine-tuning and RAG strategy, current frequent use circumstances for every strategy, and supply an outline of the bottom mannequin used for experiments.
Demystifying RAG and mannequin customization
RAG is a method to reinforce the aptitude of pre-trained fashions by permitting the mannequin entry to exterior domain-specific information sources. It combines two elements: retrieval of exterior information and era of responses. It permits pre-trained language fashions to dynamically incorporate exterior information through the response-generation course of, enabling extra contextually correct and up to date outputs. Not like fine-tuning, in RAG, the mannequin doesn’t bear any coaching and the mannequin weights aren’t up to date to be taught the area information. Though fine-tuning implicitly makes use of domain-specific data by embedding the required information immediately into the mannequin, RAG explicitly makes use of the domain-specific data via exterior retrieval.
Mannequin customization refers to adapting a pre-trained language mannequin to raised match particular duties, domains, or datasets. Fantastic-tuning is one such method, which helps in injecting task-specific or domain-specific information for bettering mannequin efficiency. It adjusts the mannequin’s parameters to raised align with the nuances of the goal activity whereas utilizing its normal information.
Widespread use circumstances for every strategy
RAG is perfect to be used circumstances requiring dynamic or continuously up to date information (equivalent to buyer assist FAQs and ecommerce catalogs), domain-specific insights (equivalent to authorized or medical Q&A), scalable options for broad functions (equivalent to software program as a service (SaaS) platforms), multimodal information retrieval (equivalent to doc summarization), and strict compliance with safe or delicate information (equivalent to monetary and regulatory programs).
Conversely, fine-tuning thrives in eventualities demanding exact customization (equivalent to personalised chatbots or artistic writing), excessive accuracy for slim duties (equivalent to code era or specialised summarization), ultra-low latency (equivalent to real-time buyer interactions), stability with static datasets (equivalent to domain-specific glossaries), and cost-efficient scaling for high-volume duties (equivalent to name heart automation).
Though RAG excels at real-time grounding in exterior information and fine-tuning makes a speciality of static, structured, and personalised workflows, selecting between them usually relies on nuanced components. This put up gives a complete comparability of RAG and fine-tuning, clarifying their strengths, limitations, and contexts the place every strategy delivers the most effective efficiency.
Introduction to Amazon Nova fashions
Amazon Nova is a brand new era of basis mannequin (FM) providing frontier intelligence and industry-leading price-performance. Amazon Nova Professional and Amazon Nova Lite are multimodal fashions excelling in accuracy and pace, with Amazon Nova Lite optimized for low-cost, quick processing. Amazon Nova Micro focuses on textual content duties with ultra-low latency. They provide quick inference, assist agentic workflows with Amazon Bedrock Data Bases and RAG, and permit fine-tuning for textual content and multi-modal information. Optimized for cost-effective efficiency, they’re skilled on information in over 200 languages.
Resolution overview
To judge the effectiveness of RAG in comparison with mannequin customization, we designed a complete testing framework utilizing a set of AWS-specific questions. Our examine used Amazon Nova Micro and Amazon Nova Lite as baseline FMs and examined their efficiency throughout completely different configurations.
We structured our analysis as follows:
- Base mannequin:
- Used out-of-box Amazon Nova Micro and Amazon Nova Lite
- Generated responses to AWS-specific questions with out further context
- Base mannequin with RAG:
- Linked the bottom fashions to Amazon Bedrock Data Bases
- Supplied entry to related AWS documentation and blogs
- Mannequin customization:
- Fantastic-tuned each Amazon Nova fashions utilizing 1,000 AWS-specific question-answer pairs generated from the identical set of AWS articles
- Deployed the custom-made fashions via provisioned throughput
- Generated responses to AWS-specific questions with fine-tuned fashions
- Mannequin customization and RAG mixed strategy:
-
- Linked the fine-tuned fashions to Amazon Bedrock Data Bases
- Supplied fine-tuned fashions entry to related AWS articles at inference time
Within the following sections, we stroll via learn how to arrange the second and third approaches (base mannequin with RAG and mannequin customization with fine-tuning) in Amazon Bedrock.
Conditions
To comply with together with this put up, you want the next conditions:
- An AWS account and acceptable permissions
- An Amazon Easy Storage Service (Amazon S3) bucket with two folders: one containing your coaching information, and one in your mannequin output and coaching metrics
Implement RAG with the baseline Amazon Nova mannequin
On this part, we stroll via the steps to implement RAG with the baseline mannequin. To take action, we create a information base. Full the next steps:
- On the Amazon Bedrock console, select Data Bases within the navigation pane.
- Underneath Data Bases, select Create.
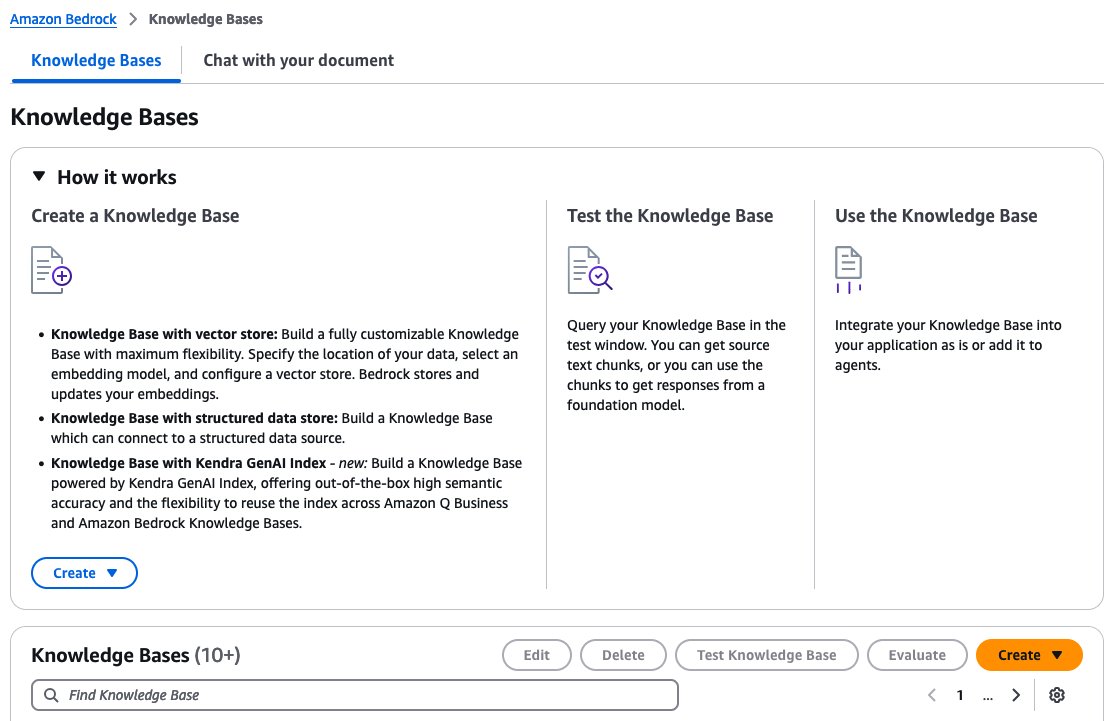
- On the Configure information supply web page, present the next data:
- Specify the Amazon S3 location of the paperwork.
- Specify a chunking technique.
- Select Subsequent.
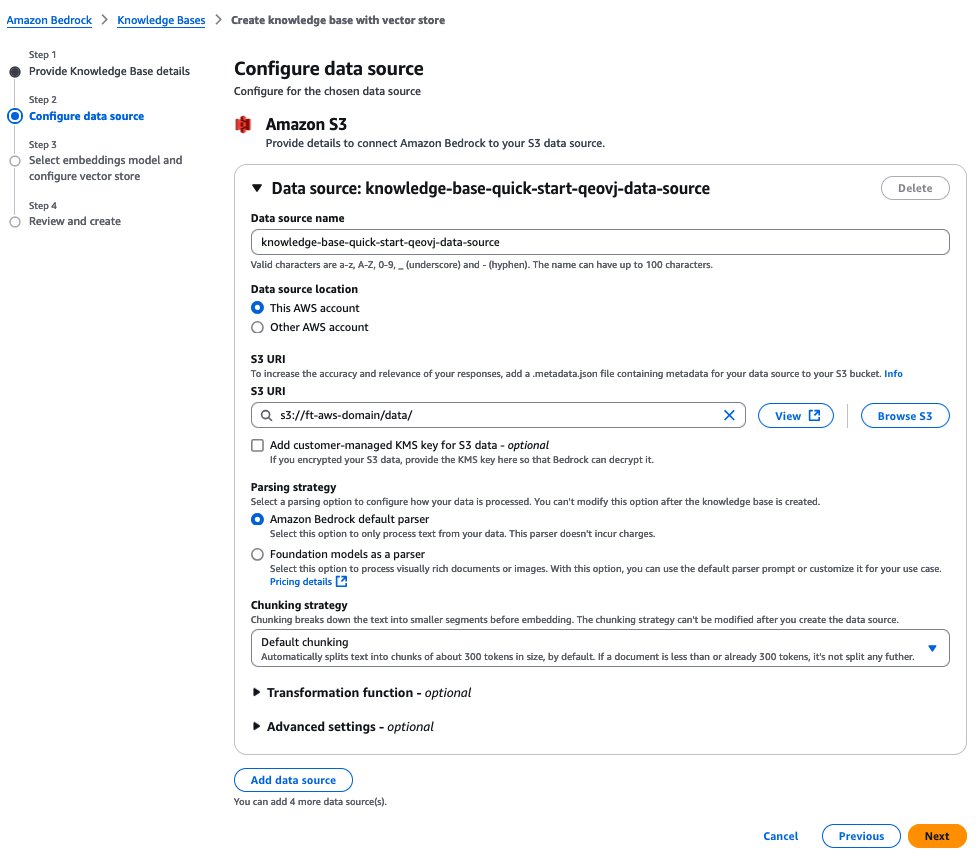
- On the Choose embeddings mannequin and configure vector retailer web page, present the next data:
- Within the Embeddings mannequin part, select your embeddings mannequin, which is used for embedding the chunks.
- Within the Vector database part, create a brand new vector retailer or use an current one the place the embeddings might be saved for retrieval.
- Select Subsequent.
- On the Assessment and create web page, overview the settings and select Create Data Base.
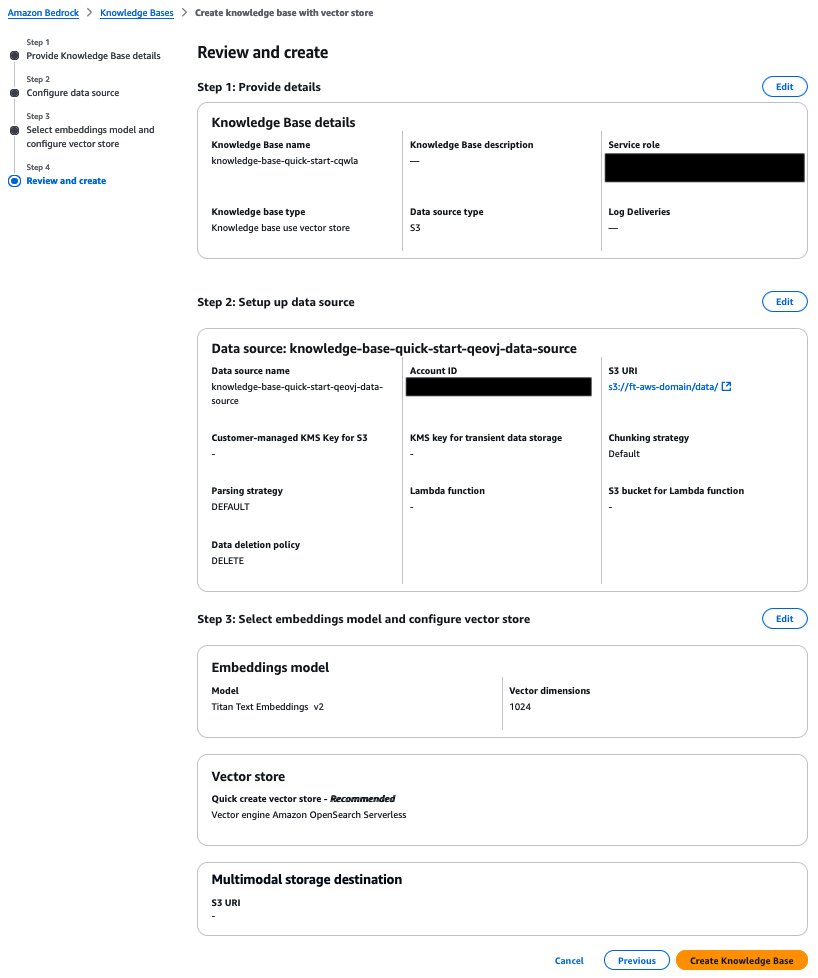
Fantastic-tune an Amazon Nova mannequin utilizing the Amazon Bedrock API
On this part, we offer detailed walkthroughs on fine-tuning and internet hosting custom-made Amazon Nova fashions utilizing Amazon Bedrock. The next diagram illustrates the answer structure.

Create a fine-tuning job
Fantastic-tuning Amazon Nova fashions via the Amazon Bedrock API is a streamlined course of:
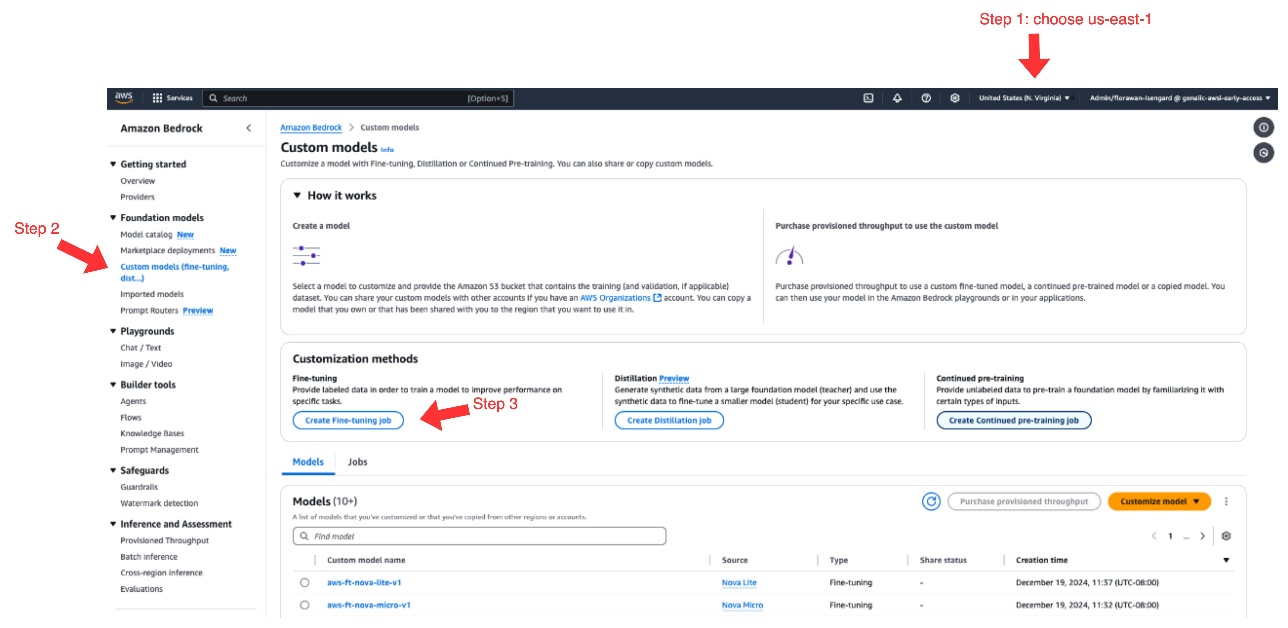
- On the Amazon Bedrock console, select us-east-1 as your AWS Area.
On the time of writing, Amazon Nova mannequin fine-tuning is completely out there in us-east-1.
- Select Customized fashions beneath Basis fashions within the navigation pane.
- Underneath Customization strategies, select Create Fantastic-tuning job.
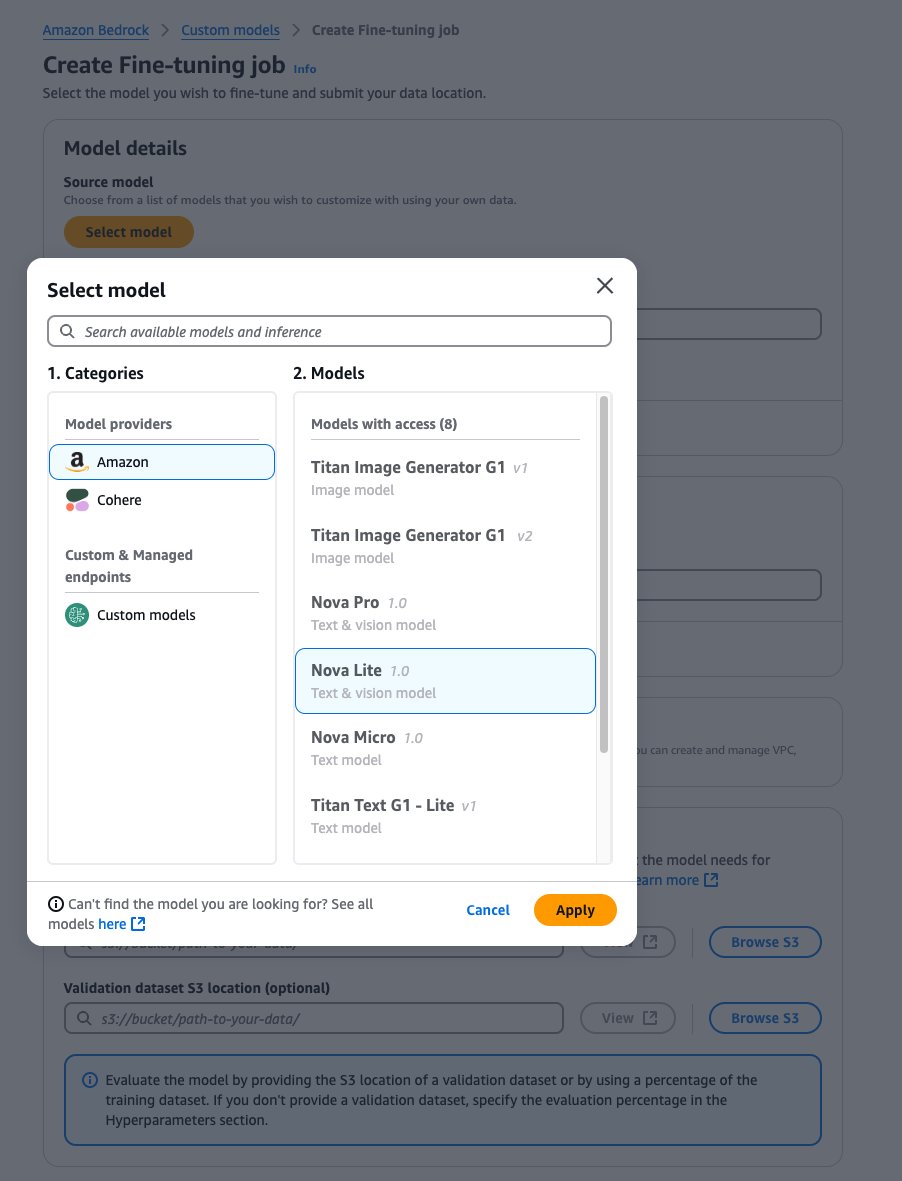
- For Supply mannequin, select Choose mannequin.
- Select Amazon because the supplier and the Amazon Nova mannequin of your selection.
- Select Apply.
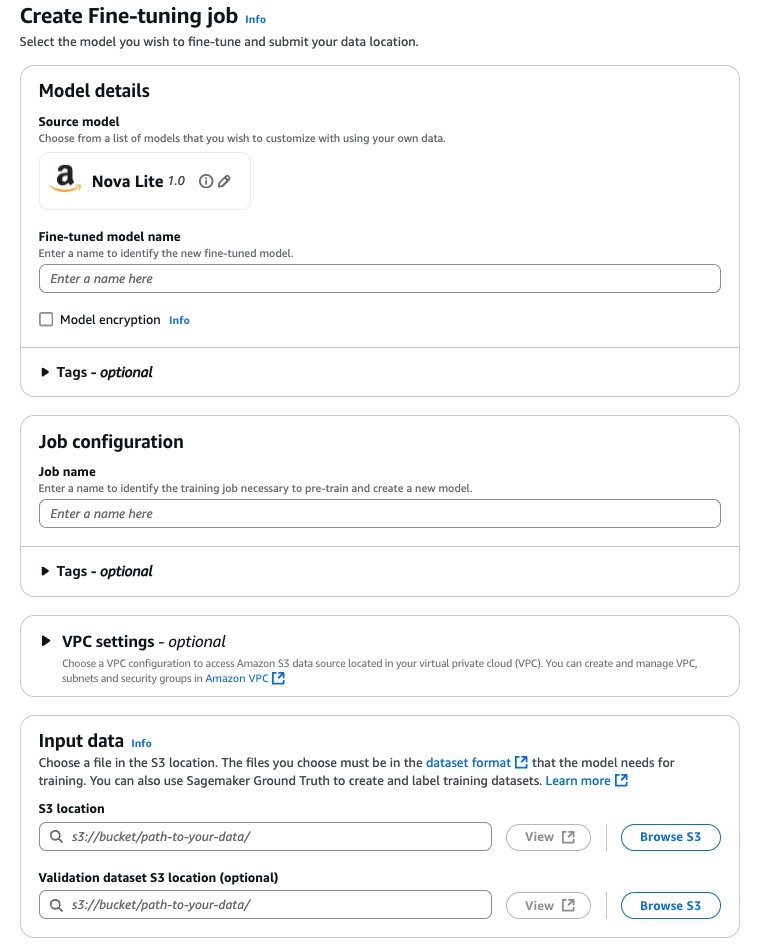
- For Fantastic-tuned mannequin title, enter a novel title for the fine-tuned mannequin.
- For Job title, enter a reputation for the fine-tuning job.
- Underneath Enter information, enter the placement of the supply S3 bucket (coaching information) and goal S3 bucket (mannequin outputs and coaching metrics), and optionally the placement of your validation dataset.
Configure hyperparameters
For Amazon Nova fashions, the next hyperparameters could be custom-made:
| Parameter | Vary/Constraints |
| Epochs | 1–5 |
| Batch Dimension | Fastened at 1 |
| Studying Price | 0.000001–0.0001 |
| Studying Price Warmup Steps | 0–100 |
Put together the dataset for compatibility with Amazon Nova fashions
Much like different LLMs, Amazon Nova requires prompt-completion pairs, often known as query and reply (Q&A) pairs, for supervised fine-tuning (SFT). This dataset ought to comprise the perfect outputs you need the language mannequin to provide for particular duties or prompts. Confer with Tips for making ready your information for Amazon Nova on greatest practices and instance codecs when making ready datasets for fine-tuning Amazon Nova fashions.
Study fine-tuning job standing and coaching artifacts
After you create your fine-tuning job, select Customized fashions beneath Basis fashions within the navigation pane. You will see that the present fine-tuning job listed beneath Jobs. You should use this web page to observe your fine-tuning job standing.
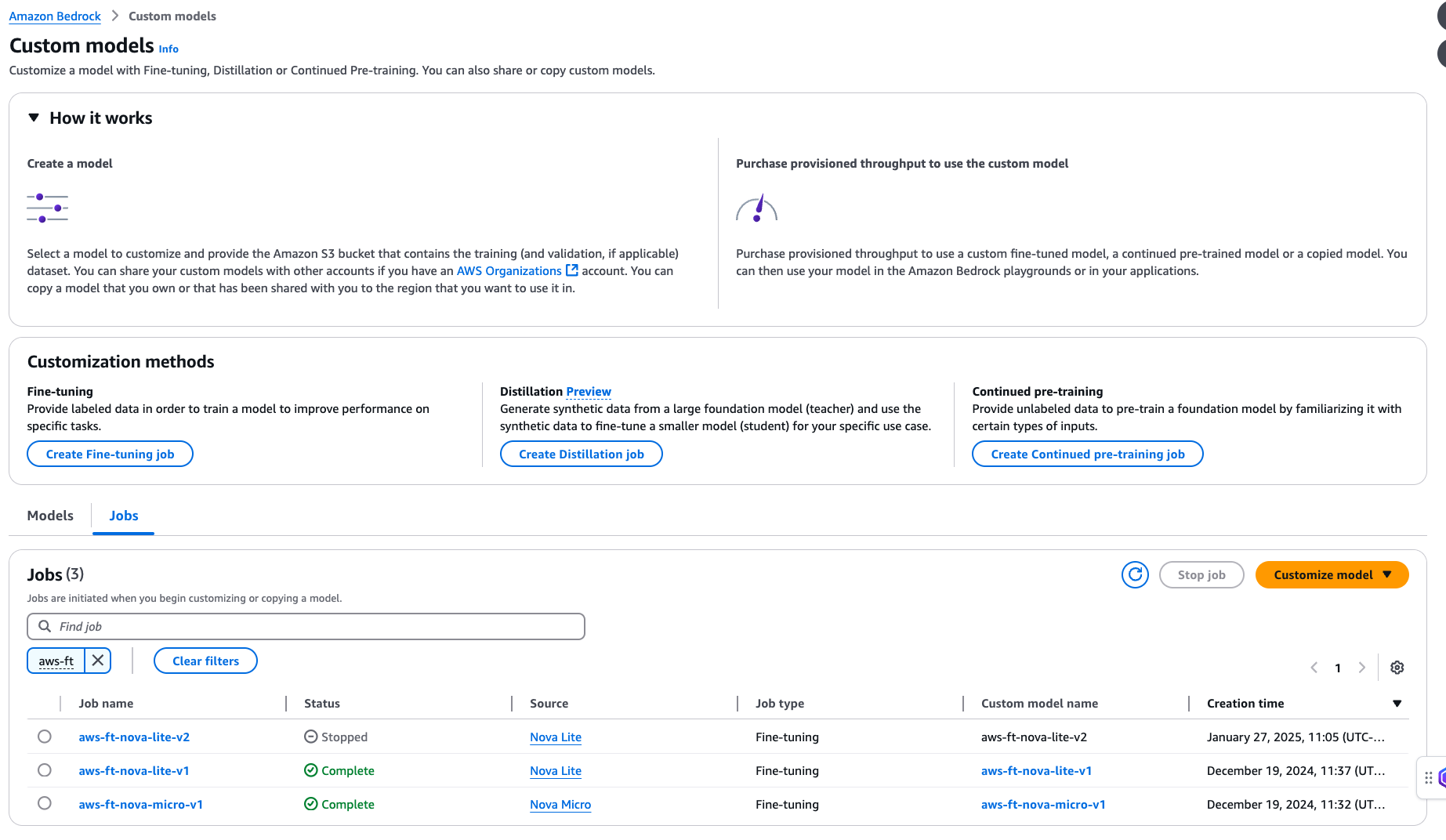
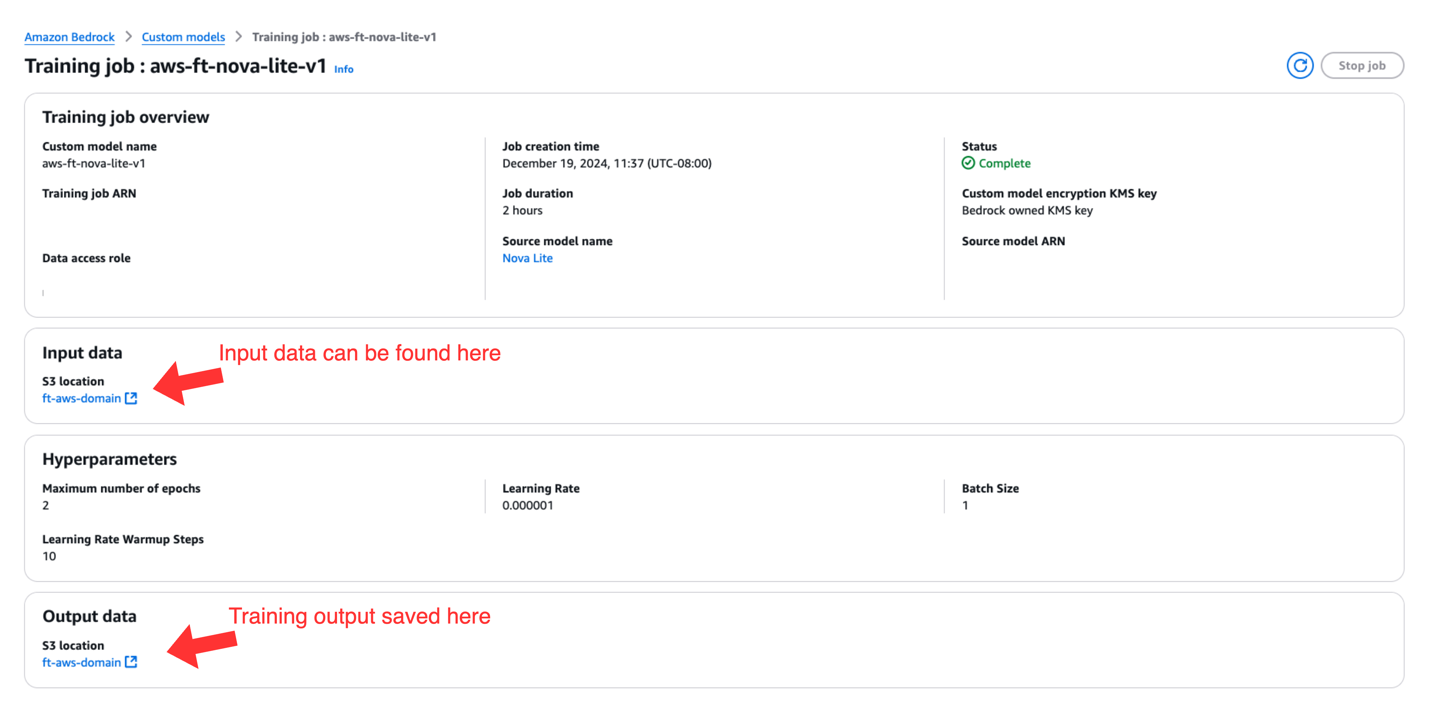
When your fine-tuning job standing adjustments to Full, you possibly can select the job title and navigate to the Coaching job overview web page. You will see that the next data:
- Coaching job specs
- Amazon S3 location for enter information used for fine-tuning
- Hyperparameters used throughout fine-tuning
- Amazon S3 location for coaching output
Host the fine-tuned mannequin with provisioned throughput
After your fine-tuning job completes efficiently, you possibly can entry your custom-made mannequin via the next steps:
- On the Amazon Bedrock console, select Customized fashions beneath Basis fashions within the navigation pane.
- Underneath Fashions, select your customized mannequin.
The mannequin particulars web page exhibits the next data:
- Fantastic-tuned mannequin particulars
- Amazon S3 location for enter information used for fine-tuning
- Hyperparameters used throughout fine-tuning
- Amazon S3 location for coaching output
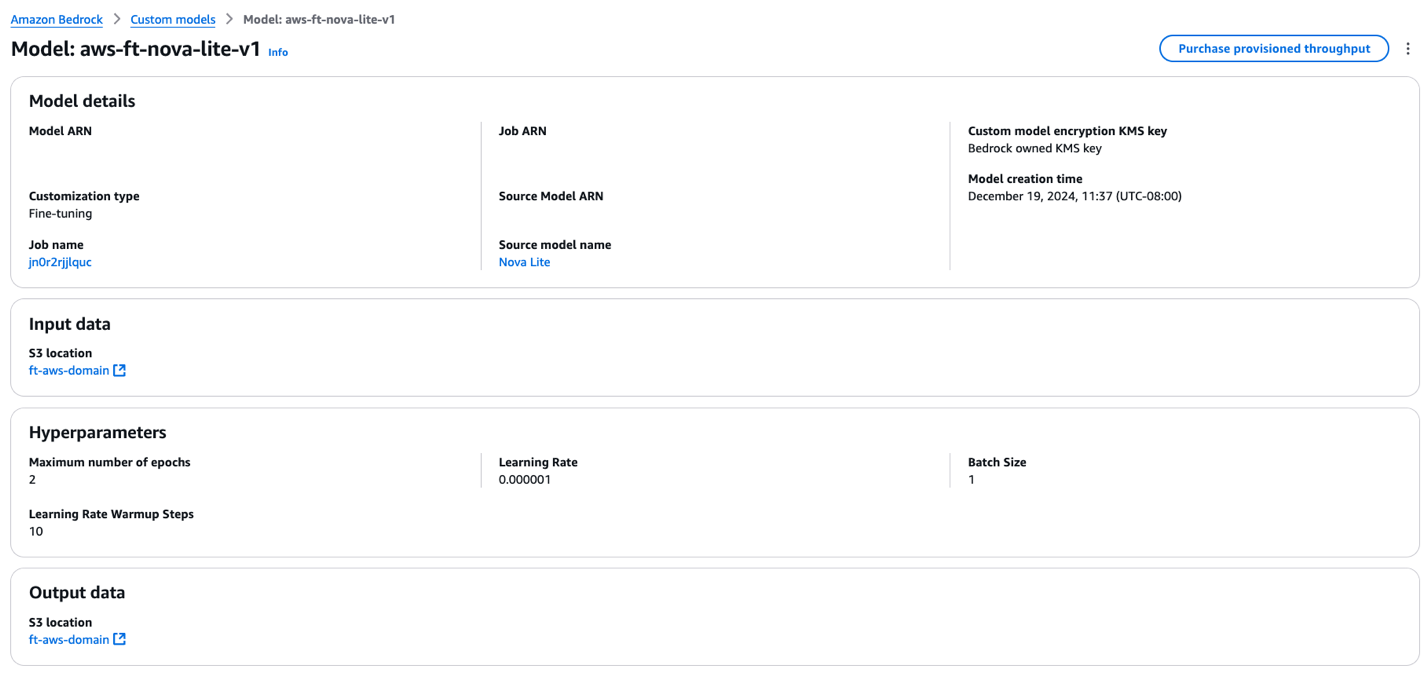
- To make your fine-tuned mannequin out there for inference, select Buy provisioned throughput.
- Select a dedication time period (no dedication, 1 month, or 6 months) and overview the related value for internet hosting the fine-tuned fashions.
After the custom-made mannequin is hosted via provisioned throughput, a mannequin ID might be assigned and can be utilized for inference.
The aforementioned fine-tuning and inference steps may also be carried out programmatically. For extra data, check with the next GitHub repo, which comprises pattern code.
Analysis framework and outcomes
On this part, we first introduce our multi-LLM-judge analysis framework, which is ready as much as mitigate a person LLM choose’s bias. We then examine RAG vs. fine-tuning outcomes when it comes to response high quality in addition to latency and token implications.
A number of LLMs as judges to mitigate bias
The next diagram illustrates our workflow utilizing a number of LLMs as judges.
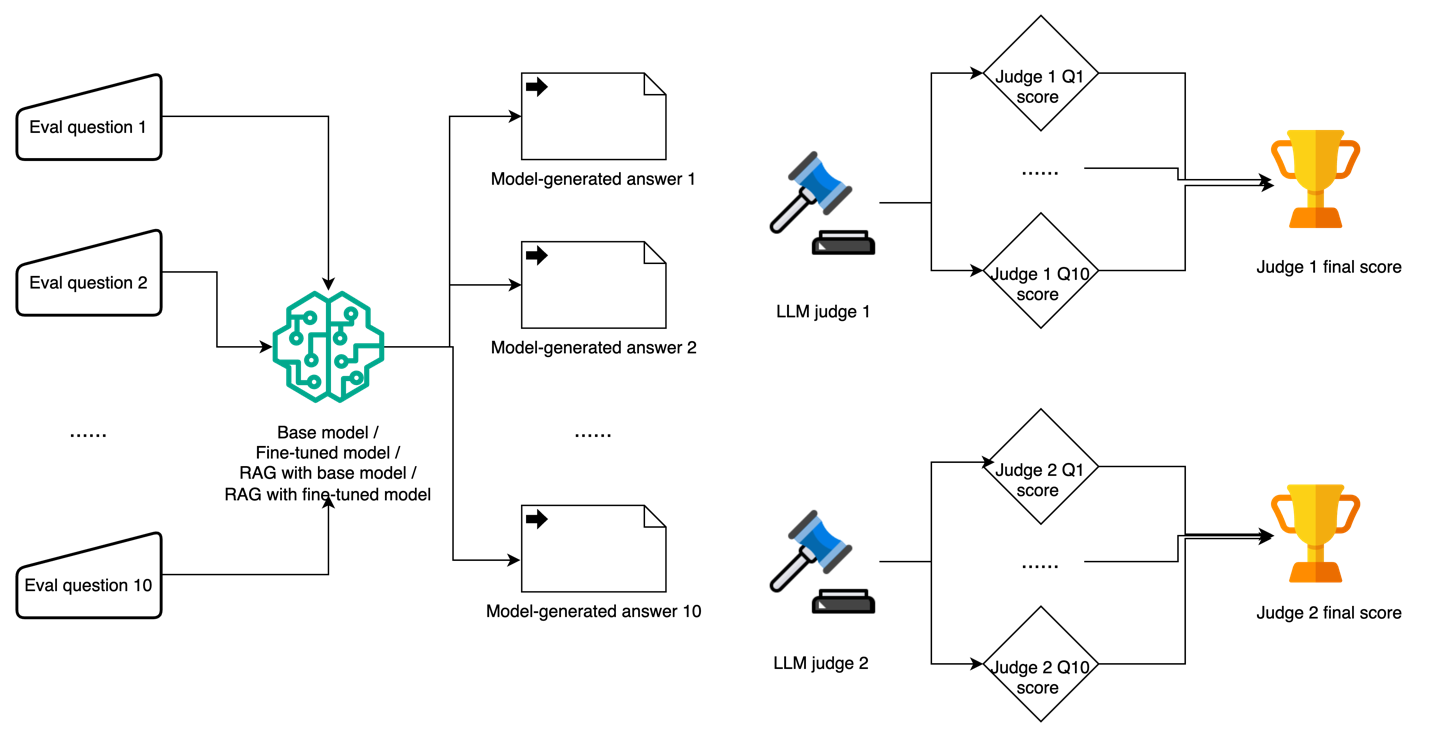
Utilizing LLMs as judges has grow to be an more and more in style strategy to guage duties which can be difficult to evaluate via conventional strategies or human analysis. For our analysis framework, we constructed 10 domain-specific check questions masking key elements of AWS companies and options, designed to check each factual accuracy and depth of understanding. Every model-generated response was evaluated utilizing a standardized scoring system on a scale of 0–10, the place 0–3 signifies incorrect or deceptive data, 4–6 represents partially right however incomplete solutions, 7–8 signifies principally right with minor inaccuracies, and 9–10 denotes utterly correct with complete clarification.
We use the next LLM choose analysis immediate:
We use the next pattern analysis query and floor fact:
To mitigate potential intrinsic biases amongst completely different LLM judges, we adopted two LLM judges to guage the model-generated responses: Anthropic’s Claude Sonnet 3.5 and Meta’s Llama 3.1 70B. Every choose was supplied with the unique check query, the model-generated response, and particular scoring standards specializing in factual accuracy, completeness, relevance, and readability. Total, we noticed a excessive degree of rank correlation amongst LLM judges in assessing completely different approaches, with constant analysis patterns throughout all check circumstances.
Response high quality comparability
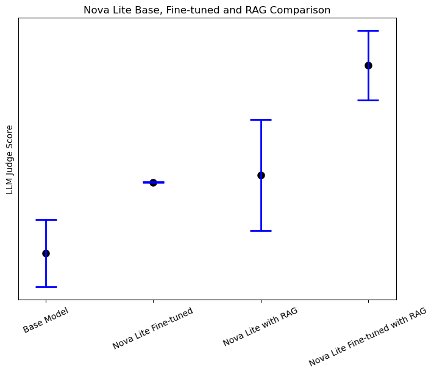
Each fine-tuning and RAG considerably enhance the standard of generated responses on AWS-specific questions over the bottom mannequin. Utilizing Amazon Nova Lite as the bottom mannequin, we noticed that each fine-tuning and RAG improved the typical LLM choose rating on response high quality by 30%, whereas combining fine-tuning with RAG enhanced the response high quality by a complete of 83%, as proven within the following determine.
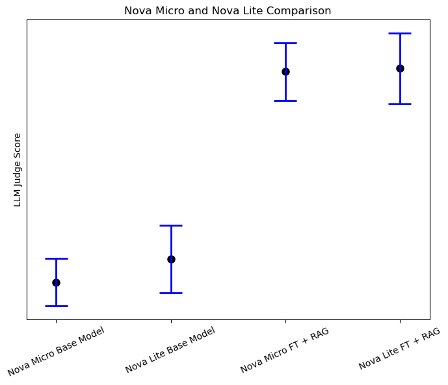
Notably, our analysis revealed an attention-grabbing discovering (as proven within the following determine): when combining fine-tuning and RAG approaches, smaller fashions like Amazon Nova Micro confirmed important efficiency enhancements in domain-specific duties, almost matching the efficiency of larger fashions. This means that for specialised use circumstances with well-defined scope, utilizing smaller fashions with each fine-tuning and RAG could possibly be a more cost effective resolution in comparison with deploying bigger fashions.
Latency and token implications
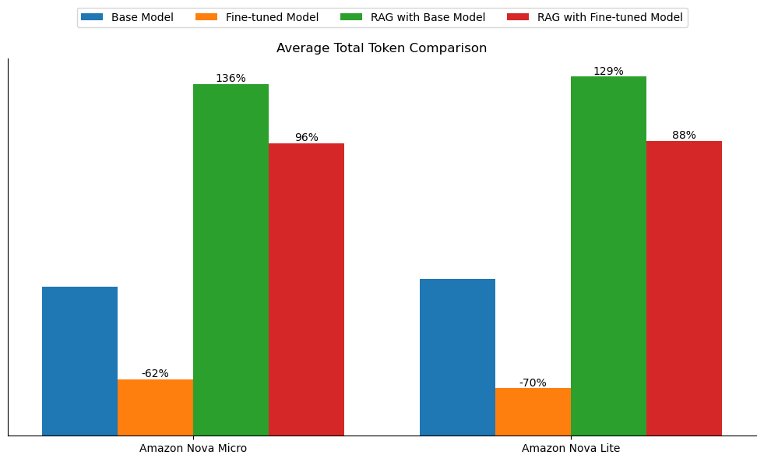
Along with enhancing the response high quality, each fine-tuning and RAG assist cut back the response era latency in comparison with the bottom mannequin. For each Amazon Nova Micro and Amazon Nova Lite, fine-tuning decreased the bottom mannequin latency by roughly 50%, whereas RAG decreased it by about 30%, as proven within the following determine.
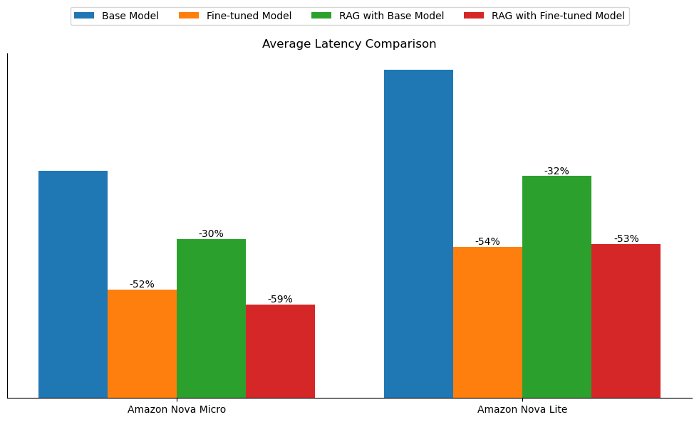
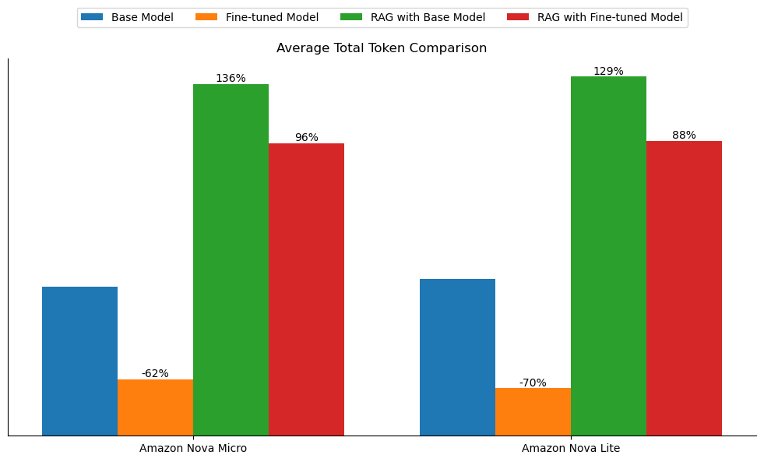
Fantastic-tuning additionally introduced the distinctive benefit of bettering the tone and elegance of the generated solutions to align extra intently with the coaching information. In our experiments, the typical whole tokens (enter and output tokens) dropped by greater than 60% with each fine-tuned fashions. Nevertheless, the typical whole tokens greater than doubled with the RAG strategy as a result of passing of context, as proven within the following determine. This discovering means that for latency-sensitive use circumstances or when the target is to align the mannequin’s responses to a selected tone, type, or model voice, mannequin customization would possibly provide extra enterprise worth.
Conclusion
On this put up, we in contrast mannequin customization (fine-tuning) and RAG for domain-specific duties with Amazon Nova. We first supplied an in depth walkthrough on learn how to fine-tune, host, and conduct inference with custom-made Amazon Nova via the Amazon Bedrock API. We then adopted an LLM-as-a-judge strategy to guage response high quality from completely different approaches. As well as, we examined the latency and token implications of various setups.
Each fine-tuning and RAG improved the mannequin efficiency. Relying on the duty and analysis standards, mannequin customization confirmed comparable, or generally higher, efficiency in comparison with RAG. Mannequin customization may also be useful to enhance the type and tone of a generated reply. On this experiment, the custom-made mannequin’s response follows the succinct reply type of the given coaching information, which resulted in decrease latency in comparison with the baseline counterpart. Moreover, mannequin customization may also be used for a lot of use circumstances the place RAG isn’t as simple for use, equivalent to instrument calling, sentiment evaluation, entity extraction, and extra. Total, we suggest combining mannequin customization and RAG for query answering or comparable duties to maximise efficiency.
For extra data on Amazon Bedrock and the most recent Amazon Nova fashions, check with the Amazon Bedrock Person Information and Amazon Nova Person Information. The AWS Generative AI Innovation Middle has a bunch of AWS science and technique specialists with complete experience spanning the generative AI journey, serving to prospects prioritize use circumstances, construct a roadmap, and transfer options into manufacturing. Take a look at the Generative AI Innovation Middle for our newest work and buyer success tales.
Concerning the Authors
 Mengdie (Flora) Wang is a Knowledge Scientist at AWS Generative AI Innovation Middle, the place she works with prospects to architect and implement scalable Generative AI options that tackle their distinctive enterprise challenges. She makes a speciality of mannequin customization strategies and agent-based AI programs, serving to organizations harness the total potential of generative AI know-how. Previous to AWS, Flora earned her Grasp’s diploma in Pc Science from the College of Minnesota, the place she developed her experience in machine studying and synthetic intelligence.
Mengdie (Flora) Wang is a Knowledge Scientist at AWS Generative AI Innovation Middle, the place she works with prospects to architect and implement scalable Generative AI options that tackle their distinctive enterprise challenges. She makes a speciality of mannequin customization strategies and agent-based AI programs, serving to organizations harness the total potential of generative AI know-how. Previous to AWS, Flora earned her Grasp’s diploma in Pc Science from the College of Minnesota, the place she developed her experience in machine studying and synthetic intelligence.
 Sungmin Hong is a Senior Utilized Scientist at Amazon Generative AI Innovation Middle the place he helps expedite the number of use circumstances of AWS prospects. Earlier than becoming a member of Amazon, Sungmin was a postdoctoral analysis fellow at Harvard Medical Faculty. He holds Ph.D. in Pc Science from New York College. Exterior of labor, he prides himself on retaining his indoor vegetation alive for 3+ years.
Sungmin Hong is a Senior Utilized Scientist at Amazon Generative AI Innovation Middle the place he helps expedite the number of use circumstances of AWS prospects. Earlier than becoming a member of Amazon, Sungmin was a postdoctoral analysis fellow at Harvard Medical Faculty. He holds Ph.D. in Pc Science from New York College. Exterior of labor, he prides himself on retaining his indoor vegetation alive for 3+ years.
 Jae Oh Woo is a Senior Utilized Scientist on the AWS Generative AI Innovation Middle, the place he makes a speciality of creating customized options and mannequin customization for a various vary of use circumstances. He has a powerful ardour for interdisciplinary analysis that connects theoretical foundations with sensible functions within the quickly evolving discipline of generative AI. Previous to becoming a member of Amazon, Jae Oh was a Simons Postdoctoral Fellow on the College of Texas at Austin, the place he carried out analysis throughout the Arithmetic and Electrical and Pc Engineering departments. He holds a Ph.D. in Utilized Arithmetic from Yale College.
Jae Oh Woo is a Senior Utilized Scientist on the AWS Generative AI Innovation Middle, the place he makes a speciality of creating customized options and mannequin customization for a various vary of use circumstances. He has a powerful ardour for interdisciplinary analysis that connects theoretical foundations with sensible functions within the quickly evolving discipline of generative AI. Previous to becoming a member of Amazon, Jae Oh was a Simons Postdoctoral Fellow on the College of Texas at Austin, the place he carried out analysis throughout the Arithmetic and Electrical and Pc Engineering departments. He holds a Ph.D. in Utilized Arithmetic from Yale College.
 Rahul Ghosh is an Utilized Scientist at Amazon’s Generative AI Innovation Middle, the place he works with AWS prospects throughout completely different verticals to expedite their use of Generative AI. Rahul holds a Ph.D. in Pc Science from the College of Minnesota.
Rahul Ghosh is an Utilized Scientist at Amazon’s Generative AI Innovation Middle, the place he works with AWS prospects throughout completely different verticals to expedite their use of Generative AI. Rahul holds a Ph.D. in Pc Science from the College of Minnesota.
 Baishali Chaudhury is an Utilized Scientist on the Generative AI Innovation Middle at AWS,
Baishali Chaudhury is an Utilized Scientist on the Generative AI Innovation Middle at AWS,
the place she focuses on advancing Generative AI options for real-world functions. She has a
sturdy background in laptop imaginative and prescient, machine studying, and AI for healthcare. Baishali holds a PhD in Pc Science from College of South Florida and PostDoc from Moffitt Most cancers Centre.
 Anila Joshi has greater than a decade of expertise constructing AI options. As a AWSI Geo Chief at AWS Generative AI Innovation Middle, Anila pioneers progressive functions of AI that push the boundaries of chance and speed up the adoption of AWS companies with prospects by serving to prospects ideate, establish, and implement safe generative AI options.
Anila Joshi has greater than a decade of expertise constructing AI options. As a AWSI Geo Chief at AWS Generative AI Innovation Middle, Anila pioneers progressive functions of AI that push the boundaries of chance and speed up the adoption of AWS companies with prospects by serving to prospects ideate, establish, and implement safe generative AI options.


{kind=link}