
datasets and are on the lookout for fast insights with out an excessive amount of guide grind, you’ve come to the precise place.
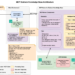
In 2025, datasets usually include hundreds of thousands of rows and a whole bunch of columns, which makes guide evaluation subsequent to not possible. Native Massive Language Fashions can remodel your uncooked DataFrame statistics into polished, readable stories in seconds — minutes at worst. This method eliminates the tedious technique of analyzing information by hand and writing government stories, particularly if the info construction doesn’t change.
Pandas handles the heavy lifting of information extraction whereas LLMs convert your technical outputs into presentable stories. You’ll nonetheless want to jot down features that pull key statistics out of your datasets, however it’s a one-time effort.
This information assumes you’ve got Ollama put in domestically. Should you don’t, you possibly can nonetheless use third-party LLM distributors, however I received’t clarify how to hook up with their APIs.
Desk of contents:
- Dataset Introduction and Exploration
- The Boring Half: Extracting Abstract Statistics
- The Cool Half: Working with LLMs
- What You Might Enhance
Dataset Introduction and Exploration
For this information, I’m utilizing the MBA admissions dataset from Kaggle. Obtain it if you wish to observe alongside.
The dataset is licensed beneath the Apache 2.0 license, which implies you should utilize it freely for each private and business initiatives.
To get began, you’ll want a couple of Python libraries put in in your system.

Upon getting all the things put in, import the required libraries in a brand new script or a pocket book:
import pandas as pd
from langchain_ollama import ChatOllama
from typing import LiteralDataset loading and preprocessing
Begin by loading the dataset with Pandas. This snippet hundreds the CSV file, prints primary details about the dataset form, and exhibits what number of lacking values exist in every column:
df = pd.read_csv("information/MBA.csv")
# Primary dataset information
print(f"Dataset form: {df.form}n")
print("Lacking worth stats:")
print(df.isnull().sum())
print("-" * 25)
df.pattern(5)
Since information cleansing isn’t the primary focus of this text, I’ll maintain the preprocessing minimal. The dataset solely has a few lacking values that want consideration:
df["race"] = df["race"].fillna("Unknown")
df["admission"] = df["admission"].fillna("Deny")That’s it! Let’s see tips on how to go from this to a significant report subsequent.
The Boring Half: Extracting Abstract Statistics
Even with all of the advances in AI functionality and availability, you in all probability don’t wish to ship your complete dataset to an LLM supplier. There are a few good the explanation why.
It may devour manner too many tokens, which interprets on to larger prices. Processing massive datasets can take a very long time, particularly while you’re operating fashions domestically by yourself {hardware}. You may additionally be coping with delicate information that shouldn’t go away your group.
Some guide work remains to be the way in which to go.
This method requires you to jot down a operate that extracts key components and statistics out of your Pandas DataFrame. You’ll have to jot down this operate from scratch for various datasets, however the core thought transfers simply between initiatives.
The get_summary_context_message() operate takes in a DataFrame and returns a formatted multi-line string with an in depth abstract. Right here’s what it consists of:
- Whole software rely and gender distribution
- Worldwide vs home applicant breakdown
- GPA and GMAT rating quartile statistics
- Admission charges by educational main (sorted by price)
- Admission charges by work trade (prime 8 industries)
- Work expertise evaluation with categorical breakdowns
- Key insights highlighting top-performing classes
Right here’s the entire supply code for the operate:
def get_summary_context_message(df: pd.DataFrame) -> str:
"""
Generate a complete abstract report of MBA admissions dataset statistics.
This operate analyzes MBA software information to supply detailed statistics on
applicant demographics, educational efficiency, skilled backgrounds, and
admission charges throughout numerous classes. The abstract consists of gender and
worldwide standing distributions, GPA and GMAT rating statistics, admission
charges by educational main and work trade, and work expertise affect evaluation.
Parameters
----------
df : pd.DataFrame
DataFrame containing MBA admissions information with the next anticipated columns:
- 'gender', 'worldwide', 'gpa', 'gmat', 'main', 'work_industry', 'work_exp', 'admission'
Returns
-------
str
A formatted multi-line string containing complete MBA admissions
statistics.
"""
# Primary software statistics
total_applications = len(df)
# Gender distribution
gender_counts = df["gender"].value_counts()
male_count = gender_counts.get("Male", 0)
female_count = gender_counts.get("Feminine", 0)
# Worldwide standing
international_count = (
df["international"].sum()
if df["international"].dtype == bool
else (df["international"] == True).sum()
)
# GPA statistics
gpa_data = df["gpa"].dropna()
gpa_avg = gpa_data.imply()
gpa_25th = gpa_data.quantile(0.25)
gpa_50th = gpa_data.quantile(0.50)
gpa_75th = gpa_data.quantile(0.75)
# GMAT statistics
gmat_data = df["gmat"].dropna()
gmat_avg = gmat_data.imply()
gmat_25th = gmat_data.quantile(0.25)
gmat_50th = gmat_data.quantile(0.50)
gmat_75th = gmat_data.quantile(0.75)
# Main evaluation - admission charges by main
major_stats = []
for main in df["major"].distinctive():
major_data = df[df["major"] == main]
admitted = len(major_data[major_data["admission"] == "Admit"])
whole = len(major_data)
price = (admitted / whole) * 100
major_stats.append((main, admitted, whole, price))
# Type by admission price (descending)
major_stats.kind(key=lambda x: x[3], reverse=True)
# Work trade evaluation - admission charges by trade
industry_stats = []
for trade in df["work_industry"].distinctive():
if pd.isna(trade):
proceed
industry_data = df[df["work_industry"] == trade]
admitted = len(industry_data[industry_data["admission"] == "Admit"])
whole = len(industry_data)
price = (admitted / whole) * 100
industry_stats.append((trade, admitted, whole, price))
# Type by admission price (descending)
industry_stats.kind(key=lambda x: x[3], reverse=True)
# Work expertise evaluation
work_exp_data = df["work_exp"].dropna()
avg_work_exp_all = work_exp_data.imply()
# Work expertise for admitted college students
admitted_students = df[df["admission"] == "Admit"]
admitted_work_exp = admitted_students["work_exp"].dropna()
avg_work_exp_admitted = admitted_work_exp.imply()
# Work expertise ranges evaluation
def categorize_work_exp(exp):
if pd.isna(exp):
return "Unknown"
elif exp < 2:
return "0-1 years"
elif exp < 4:
return "2-3 years"
elif exp < 6:
return "4-5 years"
elif exp < 8:
return "6-7 years"
else:
return "8+ years"
df["work_exp_category"] = df["work_exp"].apply(categorize_work_exp)
work_exp_category_stats = []
for class in ["0-1 years", "2-3 years", "4-5 years", "6-7 years", "8+ years"]:
category_data = df[df["work_exp_category"] == class]
if len(category_data) > 0:
admitted = len(category_data[category_data["admission"] == "Admit"])
whole = len(category_data)
price = (admitted / whole) * 100
work_exp_category_stats.append((class, admitted, whole, price))
# Construct the abstract message
abstract = f"""MBA Admissions Dataset Abstract (2025)
Whole Purposes: {total_applications:,} folks utilized to the MBA program.
Gender Distribution:
- Male candidates: {male_count:,} ({male_count/total_applications*100:.1f}%)
- Feminine candidates: {female_count:,} ({female_count/total_applications*100:.1f}%)
Worldwide Standing:
- Worldwide candidates: {international_count:,} ({international_count/total_applications*100:.1f}%)
- Home candidates: {total_applications-international_count:,} ({(total_applications-international_count)/total_applications*100:.1f}%)
Tutorial Efficiency Statistics:
GPA Statistics:
- Common GPA: {gpa_avg:.2f}
- twenty fifth percentile: {gpa_25th:.2f}
- fiftieth percentile (median): {gpa_50th:.2f}
- seventy fifth percentile: {gpa_75th:.2f}
GMAT Statistics:
- Common GMAT: {gmat_avg:.0f}
- twenty fifth percentile: {gmat_25th:.0f}
- fiftieth percentile (median): {gmat_50th:.0f}
- seventy fifth percentile: {gmat_75th:.0f}
Main Evaluation - Admission Charges by Tutorial Background:"""
for main, admitted, whole, price in major_stats:
abstract += (
f"n- {main}: {admitted}/{whole} admitted ({price:.1f}% admission price)"
)
abstract += (
"nnWork Trade Evaluation - Admission Charges by Skilled Background:"
)
# Present prime 8 industries by admission price
for trade, admitted, whole, price in industry_stats[:8]:
abstract += (
f"n- {trade}: {admitted}/{whole} admitted ({price:.1f}% admission price)"
)
abstract += "nnWork Expertise Affect on Admissions:nnOverall Work Expertise Comparability:"
abstract += (
f"n- Common work expertise (all candidates): {avg_work_exp_all:.1f} years"
)
abstract += f"n- Common work expertise (admitted college students): {avg_work_exp_admitted:.1f} years"
abstract += "nnAdmission Charges by Work Expertise Vary:"
for class, admitted, whole, price in work_exp_category_stats:
abstract += (
f"n- {class}: {admitted}/{whole} admitted ({price:.1f}% admission price)"
)
# Key insights
best_major = major_stats[0]
best_industry = industry_stats[0]
abstract += "nnKey Insights:"
abstract += (
f"n- Highest admission price by main: {best_major[0]} at {best_major[3]:.1f}%"
)
abstract += f"n- Highest admission price by trade: {best_industry[0]} at {best_industry[3]:.1f}%"
if avg_work_exp_admitted > avg_work_exp_all:
abstract += f"n- Admitted college students have barely extra work expertise on common ({avg_work_exp_admitted:.1f} vs {avg_work_exp_all:.1f} years)"
else:
abstract += "n- Work expertise exhibits minimal distinction between admitted and all candidates"
return abstractWhen you’ve outlined the operate, merely name it and print the outcomes:
print(get_summary_context_message(df))
Now let’s transfer on to the enjoyable half.
The Cool Half: Working with LLMs
That is the place issues get fascinating and your guide information extraction work pays off.
Python helper operate for working with LLMs
When you have first rate {hardware}, I strongly suggest utilizing native LLMs for easy duties like this. I exploit Ollama and the most recent model of the Mistral mannequin for the precise LLM processing.

If you wish to use one thing like ChatGPT via OpenAI API, you possibly can nonetheless try this. You’ll simply want to change the operate beneath to arrange your API key and return the suitable occasion from Langchain.
Whatever the choice you select, a name to get_llm() with a take a look at message shouldn’t return an error:
def get_llm(model_name: str = "mistral:newest") -> ChatOllama:
"""
Create and configure a ChatOllama occasion for native LLM inference.
This operate initializes a ChatOllama shopper configured to hook up with a
native Ollama server. The shopper is about up with deterministic output
(temperature=0) for constant responses throughout a number of calls with the
similar enter.
Parameters
----------
model_name : str, elective
The identify of the Ollama mannequin to make use of for chat completions.
Have to be a sound mannequin identify that's out there on the native Ollama
set up. Default is "mistral:newest".
Returns
-------
ChatOllama
A configured ChatOllama occasion prepared for chat completions.
"""
return ChatOllama(
mannequin=model_name, base_url="http://localhost:11434", temperature=0
)
print(get_llm().invoke("take a look at").content material)
Summarization immediate
That is the place you will get artistic and write ultra-specific directions to your LLM. I’ve determined to maintain issues mild for demonstration functions, however be at liberty to experiment right here.
There isn’t a single proper or incorrect immediate.
No matter you do, be sure that to incorporate the format arguments utilizing curly brackets – these values will likely be stuffed dynamically later:
SUMMARIZE_DATAFRAME_PROMPT = """
You might be an skilled information analyst and information summarizer. Your process is to soak up advanced datasets
and return user-friendly descriptions and findings.
You got this dataset:
- Title: {dataset_name}
- Supply: {dataset_source}
This dataset was analyzed in a pipeline earlier than it was given to you.
These are the findings returned by the evaluation pipeline:
{context}
Primarily based on these findings, write an in depth report in {report_format} format.
Give the report a significant title and separate findings into sections with headings and subheadings.
Output solely the report in {report_format} and nothing else.
Report:
"""Summarization Python operate
With the immediate and the get_llm() features declared, the one factor left is to attach the dots. The get_report_summary() operate takes in arguments that may fill the format placeholders within the immediate, then invokes the LLM with that immediate to generate a report.
You possibly can select between Markdown or HTML codecs:
def get_report_summary(
dataset: pd.DataFrame,
dataset_name: str,
dataset_source: str,
report_format: Literal["markdown", "html"] = "markdown",
) -> str:
"""
Generate an AI-powered abstract report from a pandas DataFrame.
This operate analyzes a dataset and generates a complete abstract report
utilizing a big language mannequin (LLM). It first extracts statistical context
from the dataset, then makes use of an LLM to create a human-readable report within the
specified format.
Parameters
----------
dataset : pd.DataFrame
The pandas DataFrame to investigate and summarize.
dataset_name : str
A descriptive identify for the dataset that will likely be included within the
generated report for context and identification.
dataset_source : str
Details about the supply or origin of the dataset.
report_format : {"markdown", "html"}, elective
The specified output format for the generated report. Choices are:
- "markdown" : Generate report in Markdown format (default)
- "html" : Generate report in HTML format
Returns
-------
str
A formatted abstract report.
"""
context_message = get_summary_context_message(df=dataset)
immediate = SUMMARIZE_DATAFRAME_PROMPT.format(
dataset_name=dataset_name,
dataset_source=dataset_source,
context=context_message,
report_format=report_format,
)
return get_llm().invoke(enter=immediate).content materialUtilizing the operate is easy – simply move within the dataset, its identify, and supply. The report format defaults to Markdown:
md_report = get_report_summary(
dataset=df,
dataset_name="MBA Admissions (2025)",
dataset_source="https://www.kaggle.com/datasets/taweilo/mba-admission-dataset"
)
print(md_report)
The HTML report is simply as detailed, however may use some styling. Perhaps you might ask the LLM to deal with that as properly!

What You Might Enhance
I may have simply turned this right into a 30-minute learn by optimizing each element of the pipeline, however I stored it easy for demonstration functions. You don’t must (and shouldn’t) cease right here although.
Listed below are the issues you possibly can enhance to make this pipeline much more highly effective:
- Write a operate that saves the report (Markdown or HTML) on to disk. This manner you possibly can automate your entire course of and generate stories on a schedule with out guide intervention.
- Within the immediate, ask the LLM so as to add CSS styling to the HTML report to make it look extra presentable. You possibly can even present your organization’s model colours and fonts to take care of consistency throughout all of your information stories.
- Broaden the immediate to observe extra particular directions. You may want stories that target particular enterprise metrics, observe a selected template, or embody suggestions based mostly on the findings.
- Broaden the
get_llm()operate so it may well join each to Ollama and different distributors like OpenAI, Anthropic, or Google. This provides you flexibility to modify between native and cloud-based fashions relying in your wants. - Do actually something within the get_summary_context_message() operate because it serves as the muse for all context information offered to the LLM. That is the place you will get artistic with characteristic engineering, statistical evaluation, and information insights that matter to your particular use case.
I hope this minimal instance has set you heading in the right direction to automate your individual information reporting workflows.


{kind=link}