Massive language fashions (LLMs) have achieved exceptional success in numerous pure language processing (NLP) duties, however they could not all the time generalize properly to particular domains or duties. Chances are you’ll must customise an LLM to adapt to your distinctive use case, bettering its efficiency in your particular dataset or process. You may customise the mannequin utilizing immediate engineering, Retrieval Augmented Era (RAG), or fine-tuning. Analysis of a custom-made LLM towards the bottom LLM (or different fashions) is important to ensure the customization course of has improved the mannequin’s efficiency in your particular process or dataset.
On this submit, we dive into LLM customization utilizing fine-tuning, exploring the important thing issues for profitable experimentation and the way Amazon SageMaker with MLflow can simplify the method utilizing Amazon SageMaker Pipelines.
LLM choice and fine-tuning journeys
When working with LLMs, clients typically have totally different necessities. Some could also be taken with evaluating and deciding on essentially the most appropriate pre-trained basis mannequin (FM) for his or her use case, whereas others may must fine-tune an current mannequin to adapt it to a selected process or area. Let’s discover two buyer journeys:

- High quality-tuning an LLM for a selected process or area adaptation – On this person journey, you want to customise an LLM for a selected process or area knowledge. This requires fine-tuning the mannequin. The fine-tuning course of might contain a number of experiment, every requiring a number of iterations with totally different mixtures of datasets, hyperparameters, prompts, and fine-tuning methods, corresponding to full or Parameter-Environment friendly High quality-Tuning (PEFT). Every iteration will be thought of a run inside an experiment.
High quality-tuning an LLM could be a complicated workflow for knowledge scientists and machine studying (ML) engineers to operationalize. To simplify this course of, you should use Amazon SageMaker with MLflow and SageMaker Pipelines for fine-tuning and analysis at scale. On this submit, we describe the step-by-step answer and supply the supply code within the accompanying GitHub repository.
Resolution overview
Working lots of of experiments, evaluating the outcomes, and holding a observe of the ML lifecycle can grow to be very complicated. That is the place MLflow may also help streamline the ML lifecycle, from knowledge preparation to mannequin deployment. By integrating MLflow into your LLM workflow, you may effectively handle experiment monitoring, mannequin versioning, and deployment, offering reproducibility. With MLflow, you may observe and evaluate the efficiency of a number of LLM experiments, establish the best-performing fashions, and deploy them to manufacturing environments with confidence.
You may create workflows with SageMaker Pipelines that allow you to organize knowledge, fine-tune fashions, and consider mannequin efficiency with easy Python code for every step.
Now you should use SageMaker managed MLflow to run LLM fine-tuning and analysis experiments at scale. Particularly:
- MLflow can handle monitoring of fine-tuning experiments, evaluating analysis outcomes of various runs, mannequin versioning, deployment, and configuration (corresponding to knowledge and hyperparameters)
- SageMaker Pipelines can orchestrate a number of experiments based mostly on the experiment configuration
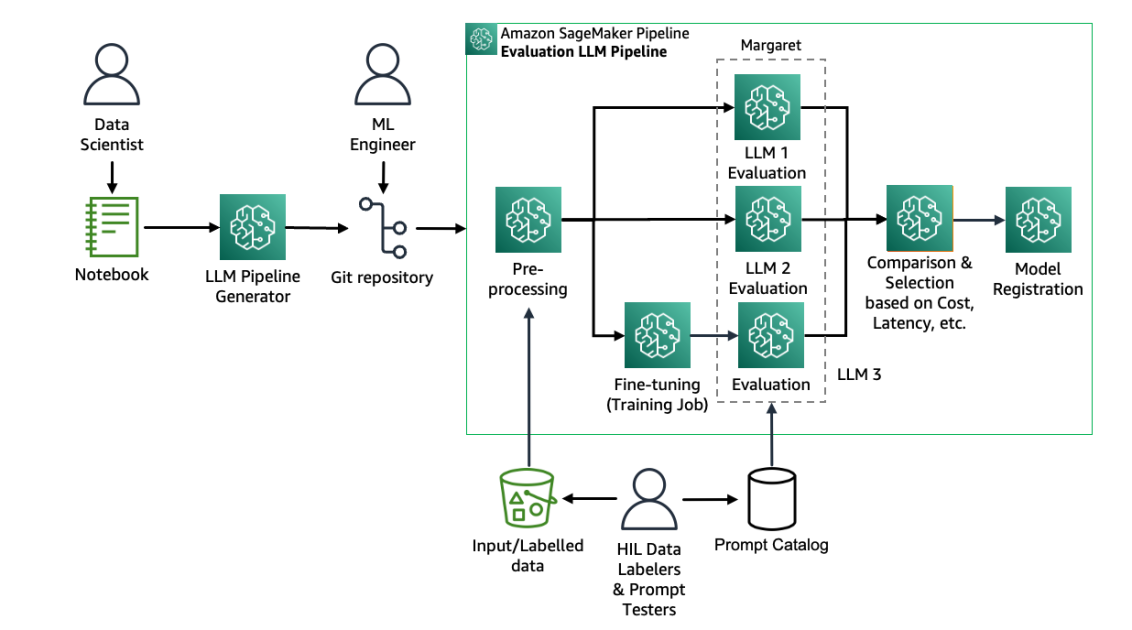
The next determine reveals the overview of the answer.

Conditions
Earlier than you start, be sure to have the next stipulations in place:
- Hugging Face login token – You want a Hugging Face login token to entry the fashions and datasets used on this submit. For directions to generate a token, see Person entry tokens.
- SageMaker entry with required IAM permissions – You must have entry to SageMaker with the mandatory AWS Id and Entry Administration (IAM) permissions to create and handle assets. Be sure you have the required permissions to create notebooks, deploy fashions, and carry out different duties outlined on this submit. To get began, see Fast setup to Amazon SageMaker. Please comply with this submit to be sure to have correct IAM function confugured for MLflow.
Arrange an MLflow monitoring server
MLflow is immediately built-in in Amazon SageMaker Studio. To create an MLflow monitoring server to trace experiments and runs, full the next steps:
- On the SageMaker Studio console, select MLflow beneath Functions within the navigation pane.

- For Identify, enter an applicable server identify.
- For Artifact storage location (S3 URI), enter the placement of an Amazon Easy Storage Service (Amazon S3) bucket.
- Select Create.

The monitoring server might require as much as 20 minutes to initialize and grow to be operational. When it’s operating, you may word its ARN to make use of within the llm_fine_tuning_experiments_mlflow.ipynb pocket book. The ARN may have the next format:
For subsequent steps, you may discuss with the detailed description offered on this submit, in addition to the step-by-step directions outlined within the llm_fine_tuning_experiments_mlflow.ipynb pocket book. You may Launch the pocket book in Amazon SageMaker Studio Traditional or SageMaker JupyterLab.
Overview of SageMaker Pipelines for experimentation at scale
We use SageMaker Pipelines to orchestrate LLM fine-tuning and analysis experiments. With SageMaker Pipelines, you may:
- Run a number of LLM experiment iterations concurrently, lowering general processing time and price
- Effortlessly scale up or down based mostly on altering workload calls for
- Monitor and visualize the efficiency of every experiment run with MLflow integration
- Invoke downstream workflows for additional evaluation, deployment, or mannequin choice
MLflow integration with SageMaker Pipelines requires the monitoring server ARN. You additionally want so as to add the mlflow and sagemaker-mlflow Python packages as dependencies within the pipeline setup. Then you should use MLflow in any pipeline step with the next code snippet:
Log datasets with MLflow
With MLflow, you may log your dataset info alongside different key metrics, corresponding to hyperparameters and mannequin analysis. This allows monitoring and reproducibility of experiments throughout totally different runs, permitting for extra knowledgeable decision-making about which fashions carry out greatest on particular duties or domains. By logging your datasets with MLflow, you may retailer metadata, corresponding to dataset descriptions, model numbers, and knowledge statistics, alongside your MLflow runs.
Within the preproccess step, you may log coaching knowledge and analysis knowledge. On this instance, we obtain the information from a Hugging Face dataset. We’re utilizing HuggingFaceH4/no_robots for fine-tuning and analysis. First, you want to set the MLflow monitoring ARN and experiment identify to log knowledge. After you course of the information and choose the required variety of rows, you may log the information utilizing the log_input API of MLflow. See the next code:
High quality-tune a Llama mannequin with LoRA and MLflow
To streamline the method of fine-tuning LLM with Low-Rank Adaption (LoRA), you should use MLflow to trace hyperparameters and save the ensuing mannequin. You may experiment with totally different LoRA parameters for coaching and log these parameters together with different key metrics, corresponding to coaching loss and analysis metrics. This allows monitoring of your fine-tuning course of, permitting you to establish the best LoRA parameters for a given dataset and process.
For this instance, we use the PEFT library from Hugging Face to fine-tune a Llama 3 mannequin. With this library, we are able to carry out LoRA fine-tuning, which gives sooner coaching with diminished reminiscence necessities. It may possibly additionally work properly with much less coaching knowledge.
We use the HuggingFace class from the SageMaker SDK to create a coaching step in SageMaker Pipelines. The precise implementation of coaching is outlined in llama3_fine_tuning.py. Similar to the earlier step, we have to set the MLflow monitoring URI and use the identical run_id:
Whereas utilizing the Coach class from Transformers, you may point out the place you need to report the coaching arguments. In our case, we need to log all of the coaching arguments to MLflow:
When the coaching is full, it can save you the complete mannequin, so you want to merge the adapter weights to the bottom mannequin:
The merged mannequin will be logged to MLflow with the mannequin signature, which defines the anticipated format for mannequin inputs and outputs, together with any further parameters wanted for inference:
Consider the mannequin
Mannequin analysis is the important thing step to pick out essentially the most optimum coaching arguments for fine-tuning the LLM for a given dataset. On this instance, we use the built-in analysis functionality of MLflow with the mlflow.consider() API. For query answering fashions, we use the default evaluator logs exact_match, token_count, toxicity, flesch_kincaid_grade_level, and ari_grade_level.
MLflow can load the mannequin that was logged within the fine-tuning step. The bottom mannequin is downloaded from Hugging Face and adapter weights are downloaded from the logged mannequin. See the next code:
These analysis outcomes are logged in MLflow in the identical run that logged the information processing and fine-tuning step.
Create the pipeline
After you could have the code prepared for all of the steps, you may create the pipeline:
You may run the pipeline utilizing the SageMaker Studio UI or utilizing the next code snippet within the pocket book:
Evaluate experiment outcomes
After you begin the pipeline, you may observe the experiment in MLflow. Every run will log particulars of the preprocessing, fine-tuning, and analysis steps. The preprocessing step will log coaching and analysis knowledge, and the fine-tuning step will log all coaching arguments and LoRA parameters. You may choose these experiments and evaluate the outcomes to seek out the optimum coaching parameters and greatest fine-tuned mannequin.
You may open the MLflow UI from SageMaker Studio.

Then you may choose the experiment to filter out runs for that experiment. You may choose a number of runs to make the comparability.

If you evaluate, you may analyze the analysis rating towards the coaching arguments.

Register the mannequin
After you analyze the analysis outcomes of various fine-tuned fashions, you may choose the very best mannequin and register it in MLflow. This mannequin might be mechanically synced with Amazon SageMaker Mannequin Registry.


Deploy the mannequin
You may deploy the mannequin by means of the SageMaker console or SageMaker SDK. You may pull the mannequin artifact from MLflow and use the ModelBuilder class to deploy the mannequin:
Clear up
With a view to not incur ongoing prices, delete the assets you created as a part of this submit:
- Delete the MLflow monitoring server.
- Run the final cell within the pocket book to delete the SageMaker pipeline:
Conclusion
On this submit, we centered on how one can run LLM fine-tuning and analysis experiments at scale utilizing SageMaker Pipelines and MLflow. You should use managed MLflow from SageMaker to check coaching parameters and analysis outcomes to pick out the very best mannequin and deploy that mannequin in SageMaker. We additionally offered pattern code in a GitHub repository that reveals the fine-tuning, analysis, and deployment workflow for a Llama3 mannequin.
You can begin profiting from SageMaker with MLflow for conventional MLOps or to run LLM experimentation at scale.
In regards to the Authors
 Jagdeep Singh Soni is a Senior Accomplice Options Architect at AWS based mostly within the Netherlands. He makes use of his ardour for Generative AI to assist clients and companions construct GenAI functions utilizing AWS providers. Jagdeep has 15 years of expertise in innovation, expertise engineering, digital transformation, cloud structure and ML functions.
Jagdeep Singh Soni is a Senior Accomplice Options Architect at AWS based mostly within the Netherlands. He makes use of his ardour for Generative AI to assist clients and companions construct GenAI functions utilizing AWS providers. Jagdeep has 15 years of expertise in innovation, expertise engineering, digital transformation, cloud structure and ML functions.
 Dr. Sokratis Kartakis is a Principal Machine Studying and Operations Specialist Options Architect for Amazon Net Providers. Sokratis focuses on enabling enterprise clients to industrialize their ML and generative AI options by exploiting AWS providers and shaping their working mannequin, corresponding to MLOps/FMOps/LLMOps foundations, and transformation roadmap utilizing greatest improvement practices. He has spent over 15 years inventing, designing, main, and implementing revolutionary end-to-end production-level ML and AI options within the domains of vitality, retail, well being, finance, motorsports, and extra.
Dr. Sokratis Kartakis is a Principal Machine Studying and Operations Specialist Options Architect for Amazon Net Providers. Sokratis focuses on enabling enterprise clients to industrialize their ML and generative AI options by exploiting AWS providers and shaping their working mannequin, corresponding to MLOps/FMOps/LLMOps foundations, and transformation roadmap utilizing greatest improvement practices. He has spent over 15 years inventing, designing, main, and implementing revolutionary end-to-end production-level ML and AI options within the domains of vitality, retail, well being, finance, motorsports, and extra.
 Kirit Thadaka is a Senior Product Supervisor at AWS centered on generative AI experimentation on Amazon SageMaker. Kirit has intensive expertise working with clients to construct scalable workflows for MLOps to make them extra environment friendly at bringing fashions to manufacturing.
Kirit Thadaka is a Senior Product Supervisor at AWS centered on generative AI experimentation on Amazon SageMaker. Kirit has intensive expertise working with clients to construct scalable workflows for MLOps to make them extra environment friendly at bringing fashions to manufacturing.
 Piyush Kadam is a Senior Product Supervisor for Amazon SageMaker, a completely managed service for generative AI builders. Piyush has intensive expertise delivering merchandise that assist startups and enterprise clients harness the facility of basis fashions.
Piyush Kadam is a Senior Product Supervisor for Amazon SageMaker, a completely managed service for generative AI builders. Piyush has intensive expertise delivering merchandise that assist startups and enterprise clients harness the facility of basis fashions.



{kind=link}