Organizations implementing brokers and agent-based programs usually expertise challenges resembling implementing a number of instruments, operate calling, and orchestrating the workflows of the instrument calling. An agent makes use of a operate name to invoke an exterior instrument (like an API or database) to carry out particular actions or retrieve info it doesn’t possess internally. These instruments are built-in as an API name contained in the agent itself, resulting in challenges in scaling and power reuse throughout an enterprise. Prospects seeking to deploy brokers at scale want a constant technique to combine these instruments, whether or not inside or exterior, whatever the orchestration framework they’re utilizing or the operate of the instrument.
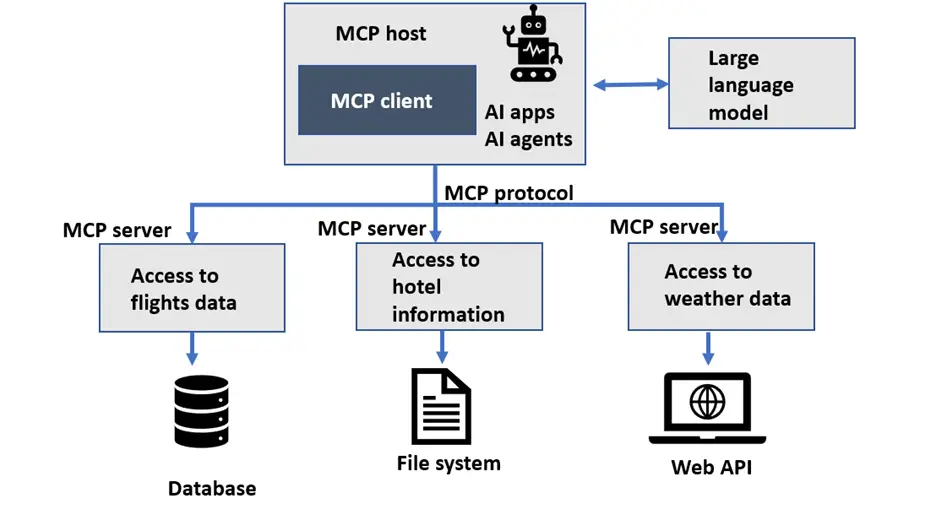
Mannequin Context Protocol (MCP) goals to standardize how these channels, brokers, instruments, and buyer knowledge can be utilized by brokers, as proven within the following determine. For patrons, this interprets immediately right into a extra seamless, constant, and environment friendly expertise in comparison with coping with fragmented programs or brokers. By making instrument integration easier and standardized, clients constructing brokers can now give attention to which instruments to make use of and easy methods to use them, relatively than spending cycles constructing customized integration code. We’ll deep dive into the MCP structure later on this put up.

For MCP implementation, you want a scalable infrastructure to host these servers and an infrastructure to host the big language mannequin (LLM), which can carry out actions with the instruments applied by the MCP server. Amazon SageMaker AI gives the power to host LLMs with out worrying about scaling or managing the undifferentiated heavy lifting. You may deploy your mannequin or LLM to SageMaker AI internet hosting companies and get an endpoint that can be utilized for real-time inference. Furthermore, you possibly can host MCP servers on the compute atmosphere of your selection from AWS, together with Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS), and AWS Lambda, in line with your most popular stage of managed service—whether or not you need to have full management of the machine operating the server, otherwise you want to not fear about sustaining and managing these servers.
On this put up, we focus on the next matters:
- Understanding the MCP structure, why you must use the MCP in comparison with implementing microservices or APIs, and two in style methods of implementing MCP utilizing LangGraph adapters:
- FastMCP for prototyping and easy use circumstances
- FastAPI for advanced routing and authentication
- Advisable structure for scalable deployment of MCP
- Utilizing SageMaker AI with FastMCP for fast prototyping
- Implementing a mortgage underwriter MCP workflow with LangGraph and SageMaker AI with FastAPI for customized routing
Understanding MCP
Let’s deep dive into the MCP structure. Developed by Anthropic as an open protocol, the MCP gives a standardized technique to join AI fashions to nearly any knowledge supply or instrument. Utilizing a client-server structure (as illustrated within the following screenshot), MCP helps builders expose their knowledge by light-weight MCP servers whereas constructing AI purposes as MCP shoppers that join to those servers.

The MCP makes use of a client-server structure containing the next elements:
- Host – A program or AI instrument that requires entry to knowledge by the MCP protocol, resembling Anthropic’s Claude Desktop, an built-in improvement atmosphere (IDE), or different AI purposes
- Consumer – Protocol shoppers that preserve one-to-one connections with servers
- Server – Light-weight applications that expose capabilities by standardized MCP or act as instruments
- Information sources – Native knowledge sources resembling databases and file programs, or exterior programs out there over the web by APIs (net APIs) that MCP servers can hook up with
Primarily based on these elements, we will outline the protocol because the communication spine connecting the MCP consumer and server throughout the structure, which incorporates the algorithm and requirements defining how shoppers and servers ought to work together, what messages they trade (utilizing JSON-RPC 2.0), and the roles of various elements.
Now let’s perceive the MCP workflow and the way it interacts with an LLM to ship you a response by utilizing an instance of a journey agent. You ask the agent to “E-book a 5-day journey to Europe in January and we like heat climate.” The host utility (appearing as an MCP consumer) identifies the necessity for exterior knowledge and connects by the protocol to specialised MCP servers for flights, resorts, and climate info. These servers return the related knowledge by the MCP, which the host then integrates with the unique immediate, offering enriched context to the LLM to generate a complete, augmented response for the person. The next diagram illustrates this workflow.

When to make use of MCP as an alternative of implementing microservices or APIs
MCP marks a big development in comparison with conventional monolithic APIs and complicated microservices architectures. Conventional APIs usually bundle the functionalities collectively, resulting in challenges the place scaling requires upgrading your entire system, updates carry excessive dangers of system-wide failures, and managing completely different variations for numerous purposes turns into overly advanced. Though microservices supply extra modularity, they sometimes demand separate, usually advanced, integrations for every service and complicated administration overhead.
MCP overcomes these limitations by establishing a standardized client-server structure particularly designed for environment friendly and safe integration. It gives a real-time, two-way communication interface enabling AI programs to seamlessly join with various exterior instruments, API companies, and knowledge sources utilizing a “write as soon as, use anyplace” philosophy. Utilizing transports like customary enter/output (stdio) or streamable HTTP beneath the unifying JSON-RPC 2.0 customary, MCP delivers key benefits resembling superior fault isolation, dynamic service discovery, constant safety controls, and plug-and-play scalability, making it exceptionally well-suited for AI purposes that require dependable, modular entry to a number of sources.
FastMCP vs. FastAPI
On this put up, we focus on two completely different approaches for implementing MCP servers: FastAPI with SageMaker, and FastMCP with LangGraph. Each are totally appropriate with the MCP structure and can be utilized interchangeably, relying in your wants. Let’s perceive the distinction between each.
FastMCP is used for fast prototyping, instructional demos, and situations the place improvement pace is a precedence. It’s a light-weight, opinionated wrapper constructed particularly for shortly standing up MCP-compliant endpoints. It abstracts away a lot of the boilerplate—resembling enter/output schemas and request dealing with—so you possibly can focus solely in your mannequin logic.
To be used circumstances the place you have to customise request routing, add authentication, or combine with observability instruments like Langfuse or Prometheus, FastAPI provides you the pliability to take action. FastAPI is a full-featured net framework that provides you finer-grained management over the server conduct. It’s well-suited for extra advanced workflows, superior request validation, detailed logging, middleware, and different production-ready options.
You may safely use both strategy in your MCP servers—the selection relies on whether or not you prioritize simplicity and pace (FastMCP) or flexibility and extensibility (FastAPI). Each approaches conform to the identical interface anticipated by brokers within the LangGraph pipeline, so your orchestration logic stays unchanged.
Answer overview
On this part, we stroll by a reference structure for scalable deployment of MCP servers and MCP shoppers, utilizing SageMaker AI because the internet hosting atmosphere for the inspiration fashions (FMs) and LLMs. Though this structure makes use of SageMaker AI as its reasoning core, it may be shortly tailored to help Amazon Bedrock fashions as properly. The next diagram illustrates the answer structure.

The structure decouples the consumer from the server by utilizing streamable HTTP because the transport layer. By doing this, shoppers and servers can scale independently, making it an ideal match for serverless orchestration powered by Lambda, AWS Fargate for Amazon ECS, or Fargate for Amazon EKS. A further good thing about decoupling is which you can higher management authorization of purposes and person by controlling AWS Identification and Entry Administration (IAM) permissions of consumer and servers individually, and propagating person entry to the backend. For those who’re operating consumer and server with a monolithic structure on the identical compute, we propose as an alternative utilizing stdio because the transport layer to cut back networking overhead.
Use SageMaker AI with FastMCP for fast prototyping
With the structure outlined, let’s analyze the appliance stream as proven within the following determine.

When it comes to utilization patterns, MCP shares a logic just like instrument calling, with an preliminary addition to find the out there instruments:
- The consumer connects to the MCP server and obtains a listing of obtainable instruments.
- The consumer invokes the LLM utilizing a immediate engineered with the listing of instruments out there on the MCP server (message of sort “person”).
- The LLM causes with respect to which of them it must name and what number of occasions, and replies (“assistant” sort message).
- The consumer asks the MCP server to execute the instrument calling and gives the consequence to the LLM (“person” sort message).
- This loop iterates till a closing reply is reached and may be given again to the person.
- The consumer disconnects from the MCP server.
Let’s begin with the MCP server definition. To create an MCP server, we use the official Mannequin Context Protocol Python SDK. For instance, let’s create a easy server with only one instrument. The instrument will simulate looking for the preferred music performed at a radio station, and return it in a Python dictionary. Ensure so as to add correct docstring and enter/output typing, in order that the each the server and consumer can uncover and devour the useful resource accurately.
As we mentioned earlier, MCP servers may be run on AWS compute companies—Amazon EC2, Amazon EC2, Amazon EKS, or Lambda—and may then be used to securely entry different sources within the AWS Cloud, for instance databases in digital personal clouds (VPCs) or an enterprise API, in addition to exterior sources. For instance, a easy technique to deploy an MCP server is to make use of Lambda help for Docker photos to put in the MCP dependency on the Lambda operate or Fargate.
With the server arrange, let’s flip our focus to the MCP consumer. Communication begins with the MCP consumer connecting to the MCP Server utilizing streamable HTTP:
When connecting to the MCP server, a great follow is to ask the server for a listing of obtainable instruments with the list_tools() API. With the instrument listing and their description, we will then outline a system immediate for instrument calling:
Instruments are normally outlined utilizing a JSON schema just like the next instance. This instrument known as top_song and its operate is to get the preferred music performed on a radio station:
With the system immediate configured, you possibly can run the chat loop as a lot as wanted, alternating between invoking the hosted LLM and calling the instruments powered by the MCP server. You should utilize packages resembling SageMaker Boto3, the Amazon SageMaker Python SDK, or one other third-party library, resembling LiteLLM or related.
A mannequin hosted on SageMaker doesn’t help operate calling natively in its API. This implies that you’ll want to parse the content material of the response utilizing an everyday expression or related strategies:
After no extra instrument requests can be found within the LLM response, you possibly can take into account the content material as the ultimate reply and return it to the person. Lastly, you shut the stream to finalize interactions with the MCP server.
Implement a mortgage underwriter MCP workflow with LangGraph and SageMaker AI with FastAPI for customized routing
To show the facility of MCP with SageMaker AI, let’s discover a mortgage underwriting system that processes purposes by three specialised personas:
- Mortgage officer – Summarizes the appliance
- Credit score analyst – Evaluates creditworthiness
- Threat supervisor – Makes closing approval or denial choices
We’ll stroll you thru these personas by the next structure for a mortgage processing workflow utilizing MCP. The code for this answer is offered within the following GitHub repo.

Within the structure, the MCP consumer and server are operating on EC2 situations and the LLM is hosted on SageMaker endpoints. The workflow consists of the next steps:
- The person enters a immediate with mortgage enter particulars resembling identify, age, earnings, and credit score rating.
- The request is routed to the mortgage MCP server by the MCP consumer.
- The mortgage parser sends output as enter to the credit score analyzer MCP server.
- The credit score analyzer sends output as enter to the danger supervisor MCP server.
- The ultimate immediate is processed by the LLM and despatched again to the MCP consumer to offer the output to the person.
You should utilize LangGraph’s built-in human-in-the-loop function when the credit score analyzer sends the output to the danger supervisor and when the danger supervisor sends the output. For this put up, now we have not applied this workflow.
Every persona is powered by an agent with LLMs hosted by SageMaker AI, and its logic is deployed by utilizing a devoted MCP server. Our MCP server implementation within the instance makes use of the Superior MCP FastAPI, however you may as well construct an ordinary MCP server implementation in line with the unique Anthropic package deal and specification. The devoted MCP server on this instance is operating on an area Docker container, however it may be shortly deployed to the AWS Cloud utilizing companies like Fargate. To run the servers regionally, use the next code:
When the servers are operating, you can begin creating the brokers and the workflow. You will have to deploy the LLM endpoint by operating the next command:
This instance makes use of LangGraph, a standard open supply framework for agentic workflows, designed to help seamless integration of language fashions into advanced workflows and purposes. Workflows are represented as graphs made from nodes—actions, instruments, or mannequin queries—and edges with the stream of data between them. LangGraph gives a structured but dynamic technique to execute duties, making it easy to write down AI purposes involving pure language understanding, automation, and decision-making.
In our instance, the primary agent we create is the mortgage officer:
The aim of the mortgage officer (or LoanParser) is to carry out the duties outlined in its MCP server. To name the MCP server, we will use the httpx library:
With that finished, we will run the workflow utilizing the scripts/run_pipeline.py file. We configured the repository to be traceable by utilizing LangSmith. If in case you have accurately configured the atmosphere variables, you will note a hint just like this one in your LangSmith UI.
Configuring LangSmith UI for experiment tracing is non-compulsory. You may skip this step.
After operating python3 scripts/run_pipeline.py, you must see the next in your terminal or log.
We use the next enter:
We get the next output:
Tracing with the LangSmith UI
LangSmith traces include the total info of all of the inputs and outputs of every step of the appliance, giving customers full visibility into their agent. That is an non-compulsory step and in case you may have configured LangSmith for tracing the MCP mortgage processing utility. You may go the LangSmith login web page and log in to the LangSmith UI. Then you possibly can select Tracing Mission and run LoanUnderwriter. It’s best to see an in depth stream of every MCP server, resembling mortgage parser, credit score analyzer, and danger assessor enter and outputs by the LLM, as proven within the following screenshot.

Conclusion
The MCP proposed by Anthropic gives a standardized manner of connecting FMs to knowledge sources, and now you should utilize this functionality with SageMaker AI. On this put up, we introduced an instance of mixing the facility of SageMaker AI and MCP to construct an utility that gives a brand new perspective on mortgage underwriting by specialised roles and automatic workflows.
Organizations can now streamline their AI integration processes by minimizing customized integrations and upkeep bottlenecks. As AI continues to evolve, the power to securely join fashions to your group’s vital programs will change into more and more beneficial. Whether or not you’re seeking to rework mortgage processing, streamline operations, or achieve deeper enterprise insights, the SageMaker AI and MCP integration gives a versatile basis to your subsequent AI innovation.
The next are some examples of what you possibly can construct by connecting your SageMaker AI fashions to MCP servers:
- A multi-agent mortgage processing system that coordinates between completely different roles and knowledge sources
- A developer productiveness assistant that integrates with enterprise programs and instruments
- A machine studying workflow orchestrator that manages advanced, multi-step processes whereas sustaining context throughout operations
For those who’re searching for methods to optimize your SageMaker AI deployment, be taught extra about easy methods to unlock price financial savings with the brand new scale all the way down to zero function in SageMaker Inference, in addition to easy methods to unlock cost-effective AI inference utilizing Amazon Bedrock serverless capabilities with a SageMaker skilled mannequin. For utility improvement, confer with Construct agentic AI options with DeepSeek-R1, CrewAI, and Amazon SageMaker AI
In regards to the Authors
 Mona Mona at present works as a Sr World Extensive Gen AI Specialist Options Architect at Amazon specializing in Gen AI Options. She was a Lead Generative AI specialist in Google Public Sector at Google earlier than becoming a member of Amazon. She is a broadcast creator of two books – Pure Language Processing with AWS AI Companies and Google Cloud Licensed Skilled Machine Studying Examine Information. She has authored 19 blogs on AI/ML and cloud expertise and a co-author on a analysis paper on CORD19 Neural Search which received an award for Finest Analysis Paper on the prestigious AAAI (Affiliation for the Development of Synthetic Intelligence) convention.
Mona Mona at present works as a Sr World Extensive Gen AI Specialist Options Architect at Amazon specializing in Gen AI Options. She was a Lead Generative AI specialist in Google Public Sector at Google earlier than becoming a member of Amazon. She is a broadcast creator of two books – Pure Language Processing with AWS AI Companies and Google Cloud Licensed Skilled Machine Studying Examine Information. She has authored 19 blogs on AI/ML and cloud expertise and a co-author on a analysis paper on CORD19 Neural Search which received an award for Finest Analysis Paper on the prestigious AAAI (Affiliation for the Development of Synthetic Intelligence) convention.
 Davide Gallitelli is a Senior Worldwide Specialist Options Architect for Generative AI at AWS, the place he empowers world enterprises to harness the transformative energy of AI. Primarily based in Europe however with a worldwide scope, Davide companions with organizations throughout industries to architect customized AI brokers that clear up advanced enterprise challenges utilizing AWS ML stack. He’s significantly obsessed with democratizing AI applied sciences and enabling groups to construct sensible, scalable options that drive organizational transformation.
Davide Gallitelli is a Senior Worldwide Specialist Options Architect for Generative AI at AWS, the place he empowers world enterprises to harness the transformative energy of AI. Primarily based in Europe however with a worldwide scope, Davide companions with organizations throughout industries to architect customized AI brokers that clear up advanced enterprise challenges utilizing AWS ML stack. He’s significantly obsessed with democratizing AI applied sciences and enabling groups to construct sensible, scalable options that drive organizational transformation.
 Surya Kari is a Senior Generative AI Information Scientist at AWS, specializing in growing options leveraging state-of-the-art basis fashions. He has intensive expertise working with superior language fashions together with DeepSeek-R1, the Llama household, and Qwen, specializing in their fine-tuning and optimization for particular scientific purposes. His experience extends to implementing environment friendly coaching pipelines and deployment methods utilizing AWS SageMaker, enabling the scaling of basis fashions from improvement to manufacturing. He collaborates with clients to design and implement generative AI options, serving to them navigate mannequin choice, fine-tuning approaches, and deployment methods to realize optimum efficiency for his or her particular use circumstances.
Surya Kari is a Senior Generative AI Information Scientist at AWS, specializing in growing options leveraging state-of-the-art basis fashions. He has intensive expertise working with superior language fashions together with DeepSeek-R1, the Llama household, and Qwen, specializing in their fine-tuning and optimization for particular scientific purposes. His experience extends to implementing environment friendly coaching pipelines and deployment methods utilizing AWS SageMaker, enabling the scaling of basis fashions from improvement to manufacturing. He collaborates with clients to design and implement generative AI options, serving to them navigate mannequin choice, fine-tuning approaches, and deployment methods to realize optimum efficiency for his or her particular use circumstances.
 Giuseppe Zappia is a Principal Options Architect at AWS, with over 20 years of expertise in full stack software program improvement, distributed programs design, and cloud structure. In his spare time, he enjoys enjoying video video games, programming, watching sports activities, and constructing issues.
Giuseppe Zappia is a Principal Options Architect at AWS, with over 20 years of expertise in full stack software program improvement, distributed programs design, and cloud structure. In his spare time, he enjoys enjoying video video games, programming, watching sports activities, and constructing issues.



{kind=link}