
Organizations typically face challenges when implementing single-shot fine-tuning approaches for his or her generative AI fashions. The one-shot fine-tuning methodology entails choosing coaching information, configuring hyperparameters, and hoping the outcomes meet expectations with out the power to make incremental changes. Single-shot fine-tuning continuously results in suboptimal outcomes and requires beginning your entire course of from scratch when enhancements are wanted.
Amazon Bedrock now helps iterative fine-tuning, enabling systematic mannequin refinement by managed, incremental coaching rounds. With this functionality you possibly can construct upon beforehand custom-made fashions, whether or not they had been created by fine-tuning or distillation, offering a basis for steady enchancment with out the dangers related to full retraining.
On this publish, we are going to discover how you can implement the iterative fine-tuning functionality of Amazon Bedrock to systematically enhance your AI fashions. We’ll cowl the important thing benefits over single-shot approaches, stroll by sensible implementation utilizing each the console and SDK, talk about deployment choices, and share finest practices for maximizing your iterative fine-tuning outcomes.
When to make use of iterative fine-tuning
Iterative fine-tuning supplies a number of benefits over single-shot approaches that make it beneficial for manufacturing environments. Danger mitigation turns into potential by incremental enhancements, so you possibly can take a look at and validate modifications earlier than committing to bigger modifications. With this strategy, you may make data-driven optimization based mostly on actual efficiency suggestions quite than theoretical assumptions about what would possibly work. The methodology additionally helps builders to use totally different coaching strategies sequentially to refine mannequin conduct. Most significantly, iterative fine-tuning accommodates evolving enterprise necessities pushed by steady reside information visitors. As person patterns change over time and new use circumstances emerge that weren’t current in preliminary coaching, you possibly can leverage this contemporary information to refine your mannequin’s efficiency with out ranging from scratch.
How one can implement iterative fine-tuning on Amazon Bedrock
Establishing iterative fine-tuning entails getting ready your surroundings and creating coaching jobs that construct upon your current {custom} fashions, whether or not by the console interface or programmatically utilizing the SDK.
Conditions
Earlier than starting iterative fine-tuning, you want a beforehand custom-made mannequin as your place to begin. This base mannequin can originate from both fine-tuning or distillation processes and helps customizable fashions and variants accessible on Amazon Bedrock. You’ll additionally want:
- Normal IAM permissions for Amazon Bedrock mannequin customization
- Incremental coaching information targeted on addressing particular efficiency gaps
- S3 bucket for coaching information and job outputs
Your incremental coaching information ought to goal the particular areas the place your present mannequin wants enchancment quite than making an attempt to retrain on all potential eventualities.
Utilizing the AWS Administration Console
The Amazon Bedrock console supplies an easy interface for creating iterative fine-tuning jobs.
Navigate to the Customized Fashions part and choose Create fine-tuning job. The important thing distinction in iterative fine-tuning lies within the base mannequin choice, the place you select your beforehand custom-made mannequin as a substitute of a basis mannequin.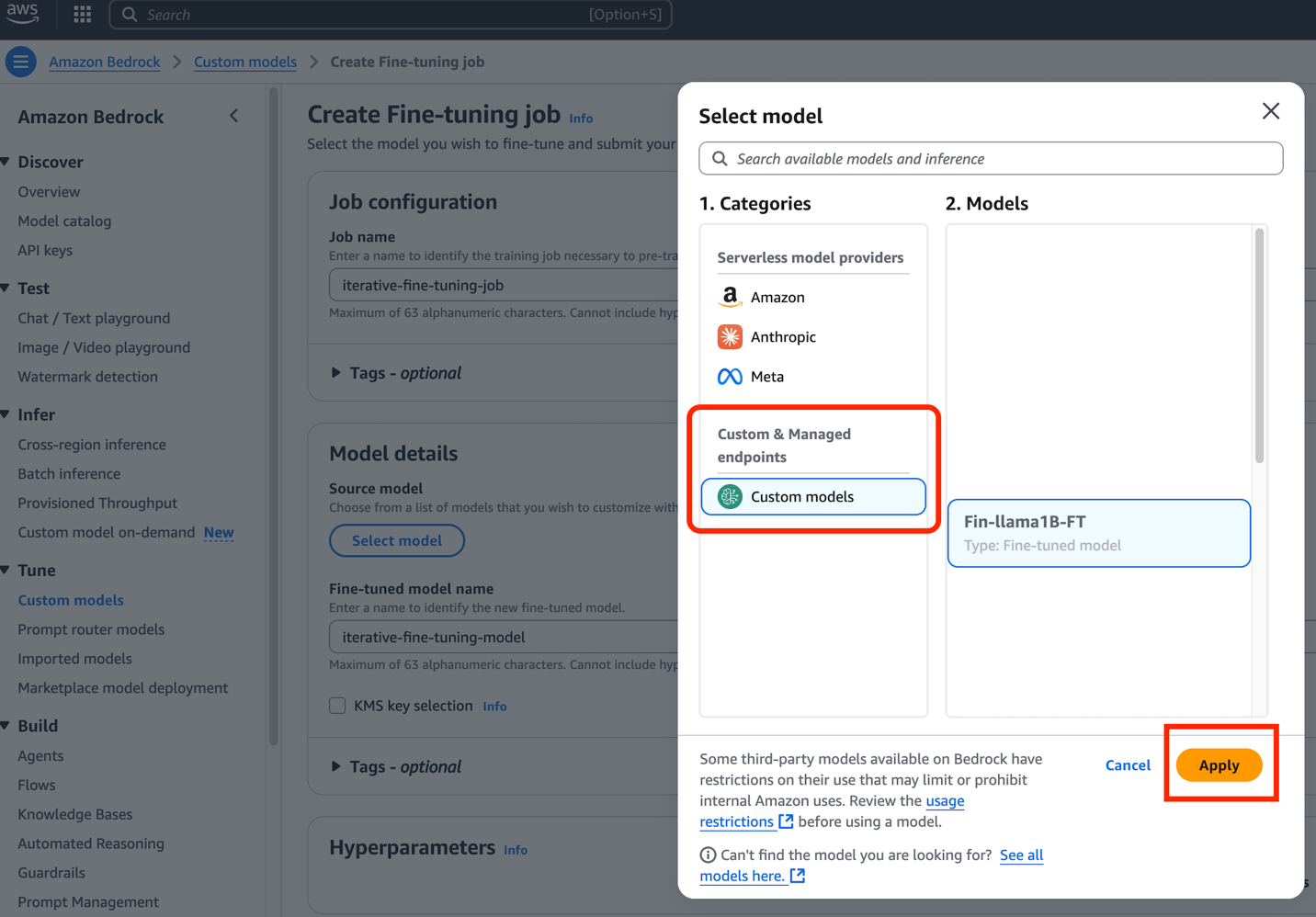
Throughout coaching, you possibly can go to the Customized fashions web page within the Amazon Bedrock console to trace the job standing.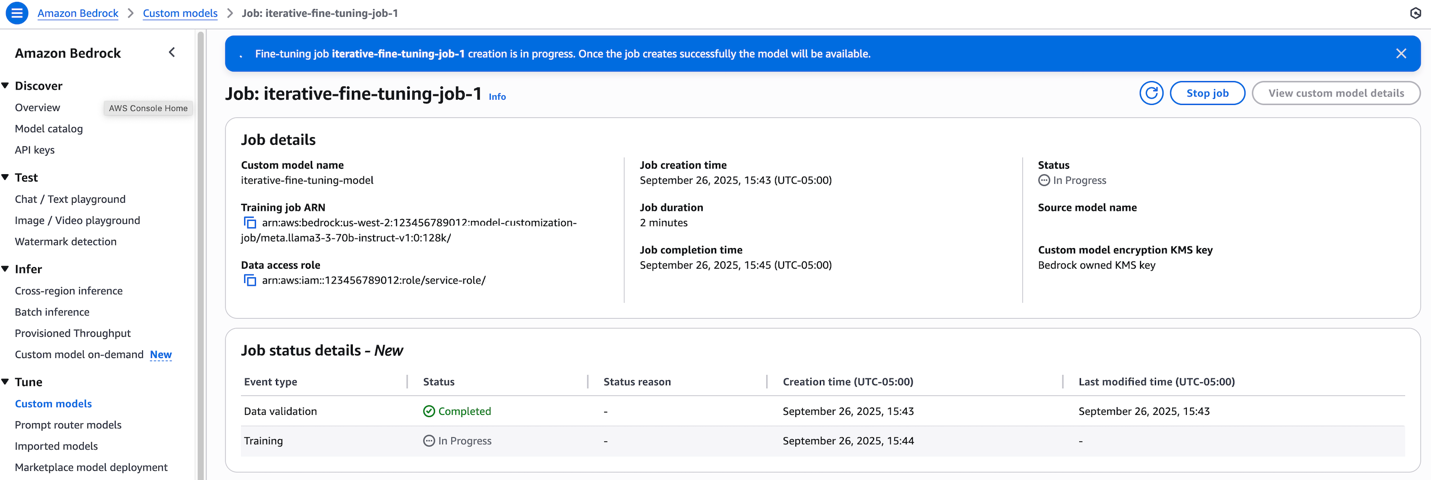
As soon as full, you possibly can monitor your jobs efficiency metrics on console by a number of metric charts, on the Coaching metrics and Validation metrics tabs.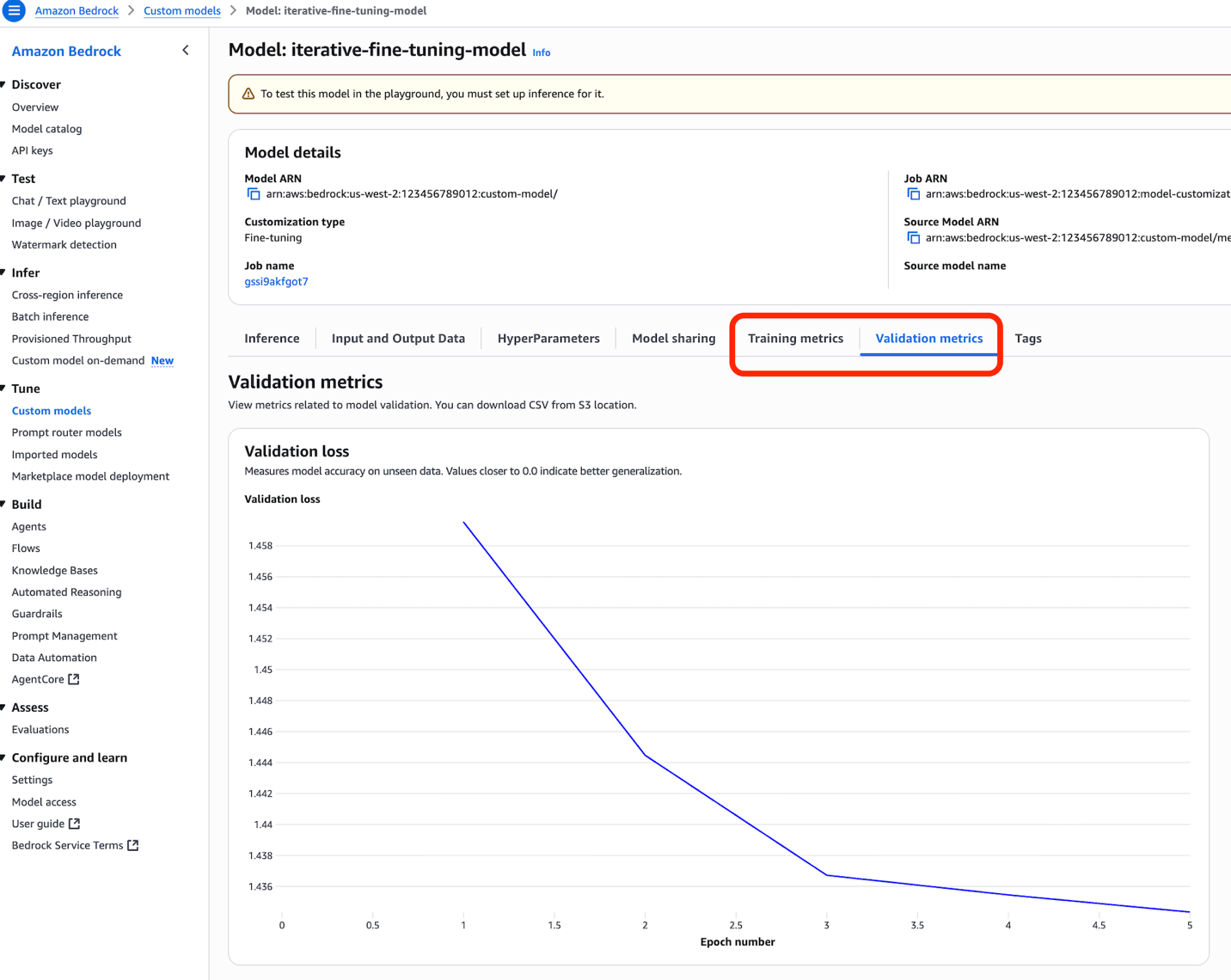
Utilizing the SDK
Programmatic implementation of iterative fine-tuning follows related patterns to plain fine-tuning with one crucial distinction: specifying your beforehand custom-made mannequin as the bottom mannequin identifier. Right here’s an instance implementation:
Establishing inference in your iteratively fine-tuned mannequin
As soon as your iterative fine-tuning job completes, you could have two main choices for deploying your mannequin for inference, provisioned throughput and on-demand inference, every suited to totally different utilization patterns and necessities.
Provisioned Throughput
Provisioned Throughput gives secure efficiency for predictable workloads the place constant throughput necessities exist. This selection supplies devoted capability in order that the iteratively fine-tuned mannequin maintains efficiency requirements throughout peak utilization intervals. Setup entails buying mannequin items based mostly on anticipated visitors patterns and efficiency necessities.
On-demand inference
On-demand inference supplies flexibility for variable workloads and experimentation eventualities. Amazon Bedrock now helps Amazon Nova Micro, Lite, and Professional fashions in addition to Llama 3.3 fashions for on-demand inference with pay-per-token pricing. This selection avoids the necessity for capability planning so you possibly can take a look at your iteratively fine-tuned mannequin with out upfront commitments. The pricing mannequin scales robotically with utilization, making it cost-effective for purposes with unpredictable or low-volume inference patterns.
Finest practices
Profitable iterative fine-tuning requires consideration to a number of key areas. Most significantly, your information technique ought to emphasize high quality over amount in incremental datasets. Relatively than including giant volumes of recent coaching examples, concentrate on high-quality information that addresses particular efficiency gaps recognized in earlier iterations.
To trace progress successfully, analysis consistency throughout iterations permits significant comparability of enhancements. Set up baseline metrics throughout your first iteration and keep the identical analysis framework all through the method. You should utilize Amazon Bedrock Evaluations that can assist you systematically establish the place gaps exist in your mannequin efficiency after every customization run. This consistency helps you perceive whether or not modifications are producing significant enhancements.
Lastly, recognizing when to cease the iterative course of helps to stop diminishing returns in your funding. Monitor efficiency enhancements between iterations and contemplate concluding the method when beneficial properties change into marginal relative to the trouble required.
Conclusion
Iterative fine-tuning on Amazon Bedrock supplies a scientific strategy to mannequin enchancment that reduces dangers whereas enabling steady refinement. With the iterative fine-tuning methodology organizations can construct upon current investments in {custom} fashions quite than ranging from scratch when changes are wanted.
To get began with iterative fine-tuning, entry the Amazon Bedrock console and navigate to the Customized fashions part. For detailed implementation steering, consult with the Amazon Bedrock documentation.
Concerning the authors
 Yanyan Zhang is a Senior Generative AI Information Scientist at Amazon Internet Providers, the place she has been engaged on cutting-edge AI/ML applied sciences as a Generative AI Specialist, serving to clients use generative AI to attain their desired outcomes. Yanyan graduated from Texas A&M College with a PhD in Electrical Engineering. Outdoors of labor, she loves touring, understanding, and exploring new issues.
Yanyan Zhang is a Senior Generative AI Information Scientist at Amazon Internet Providers, the place she has been engaged on cutting-edge AI/ML applied sciences as a Generative AI Specialist, serving to clients use generative AI to attain their desired outcomes. Yanyan graduated from Texas A&M College with a PhD in Electrical Engineering. Outdoors of labor, she loves touring, understanding, and exploring new issues.
 Gautam Kumar is an Engineering Supervisor at AWS AI Bedrock, main mannequin customization initiatives throughout large-scale basis fashions. He focuses on distributed coaching and fine-tuning. Outdoors work, he enjoys studying and touring.
Gautam Kumar is an Engineering Supervisor at AWS AI Bedrock, main mannequin customization initiatives throughout large-scale basis fashions. He focuses on distributed coaching and fine-tuning. Outdoors work, he enjoys studying and touring.
 Jesse Manders is a Senior Product Supervisor on Amazon Bedrock, the AWS Generative AI developer service. He works on the intersection of AI and human interplay with the purpose of making and enhancing generative AI services to fulfill our wants. Beforehand, Jesse held engineering group management roles at Apple and Lumileds, and was a senior scientist in a Silicon Valley startup. He has an M.S. and Ph.D. from the College of Florida, and an MBA from the College of California, Berkeley, Haas College of Enterprise.
Jesse Manders is a Senior Product Supervisor on Amazon Bedrock, the AWS Generative AI developer service. He works on the intersection of AI and human interplay with the purpose of making and enhancing generative AI services to fulfill our wants. Beforehand, Jesse held engineering group management roles at Apple and Lumileds, and was a senior scientist in a Silicon Valley startup. He has an M.S. and Ph.D. from the College of Florida, and an MBA from the College of California, Berkeley, Haas College of Enterprise.



{kind=link}