
We’re excited to announce the overall availability of multimodal retrieval for Amazon Bedrock Information Bases. This new functionality provides native help for video and audio content material, on prime of textual content and pictures. With it you possibly can construct Retrieval Augmented Technology (RAG) purposes that may search and retrieve data throughout textual content, photographs, audio, and video—all inside a completely managed service.
Trendy enterprises retailer priceless data in a number of codecs. Product documentation consists of diagrams and screenshots, coaching supplies comprise educational movies, and buyer insights are captured in recorded conferences. Till now, constructing synthetic intelligence (AI) purposes that would successfully search throughout these content material sorts required complicated customized infrastructure and important engineering effort.
Beforehand, Bedrock Information Bases used text-based embedding fashions for retrieval. Whereas it supported textual content paperwork and pictures, photographs needed to be processed utilizing basis fashions (FM) or Bedrock Knowledge Automation to generate textual content descriptions—a text-first strategy that misplaced visible context and prevented visible search capabilities. Video and audio required customized preprocessing exterior pipelines. Now, with multimodal embeddings, the retriever natively helps textual content, photographs, audio, and video inside a single embedding mannequin.
With multimodal retrieval in Bedrock Information Bases, now you can ingest, index, and retrieve data from textual content, photographs, video, and audio utilizing a single, unified workflow. Content material is encoded utilizing multimodal embeddings that protect visible and audio context, enabling your purposes to seek out related data throughout media sorts. You may even search utilizing a picture to seek out visually comparable content material or find particular scenes in movies.
On this submit, we’ll information you thru constructing multimodal RAG purposes. You’ll find out how multimodal information bases work, how to decide on the fitting processing technique primarily based in your content material sort, and the way to configure and implement multimodal retrieval utilizing each the console and code examples.
Understanding multimodal information bases
Amazon Bedrock Information Bases automates the whole RAG workflow: ingesting content material out of your knowledge sources, parsing and chunking it into searchable segments, changing chunks to vector embeddings, and storing them in a vector database. Throughout retrieval, person queries are embedded and matched in opposition to saved vectors to seek out semantically comparable content material, which augments the immediate despatched to your basis mannequin.
With multimodal retrieval, this workflow now handles photographs, video, and audio alongside textual content by two processing approaches. Amazon Nova Multimodal Embeddings encodes content material natively right into a unified vector area, for cross-modal retrieval the place you possibly can question with textual content and retrieve movies, or search utilizing photographs to seek out visible content material.
Alternatively, Bedrock Knowledge Automation converts multimedia into wealthy textual content descriptions and transcripts earlier than embedding, offering high-accuracy retrieval over spoken content material. Your selection is dependent upon whether or not visible context or speech precision issues most to your use case.
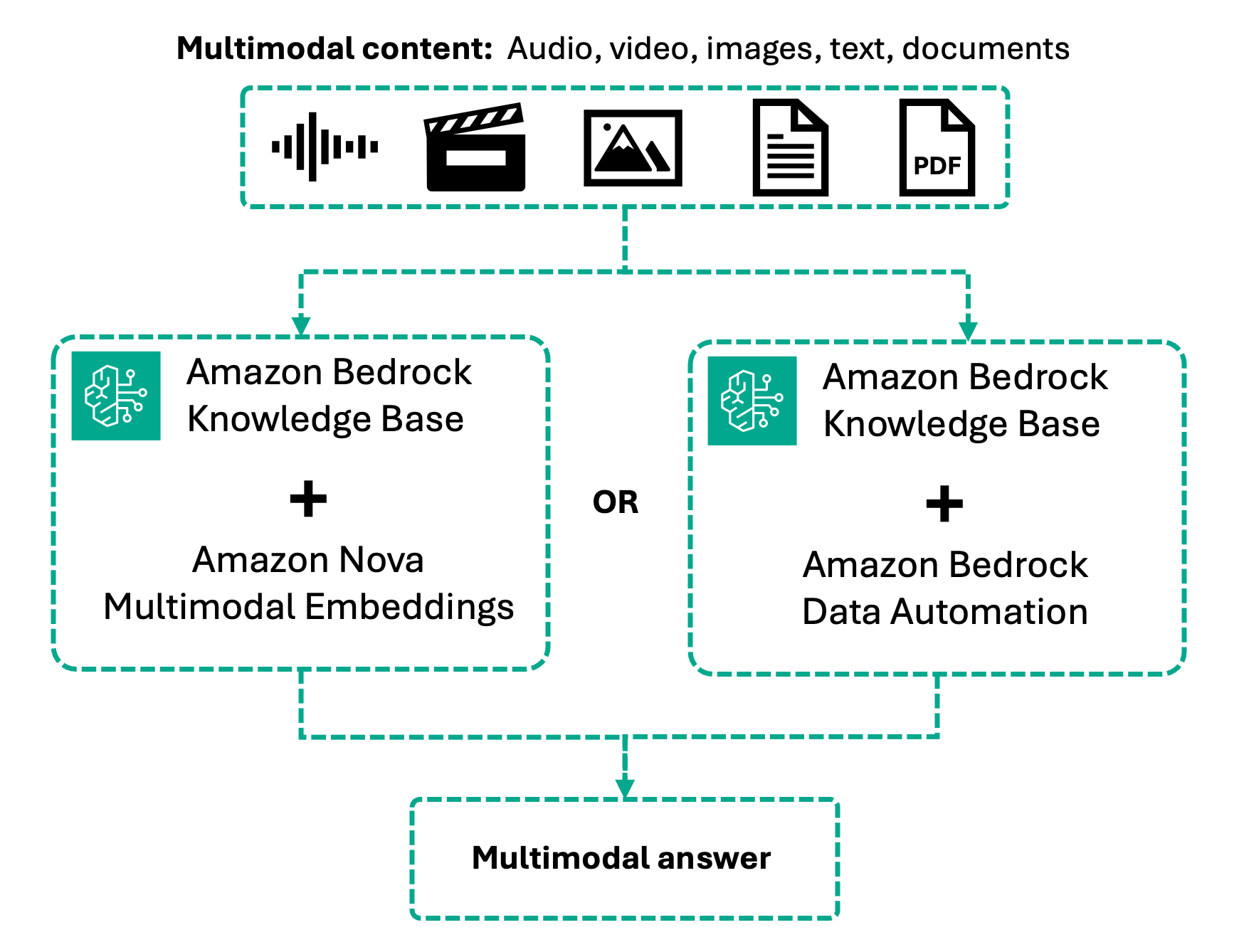
We discover every of those approaches on this submit.
Amazon Nova Multimodal Embeddings
Amazon Nova Multimodal Embeddings is the primary unified embedding mannequin that encodes textual content, paperwork, photographs, video, and audio right into a single shared vector area. Content material is processed natively with out textual content conversion. The mannequin helps as much as 8,172 tokens for textual content and 30 seconds for video/audio segments, handles over 200 languages, and affords 4 embedding dimensions (with 3072-dimension as default, 1,024, 384, 256) to steadiness accuracy and effectivity. Bedrock Information Bases segments video and audio robotically into configurable chunks (5-30 seconds), with every section independently embedded.
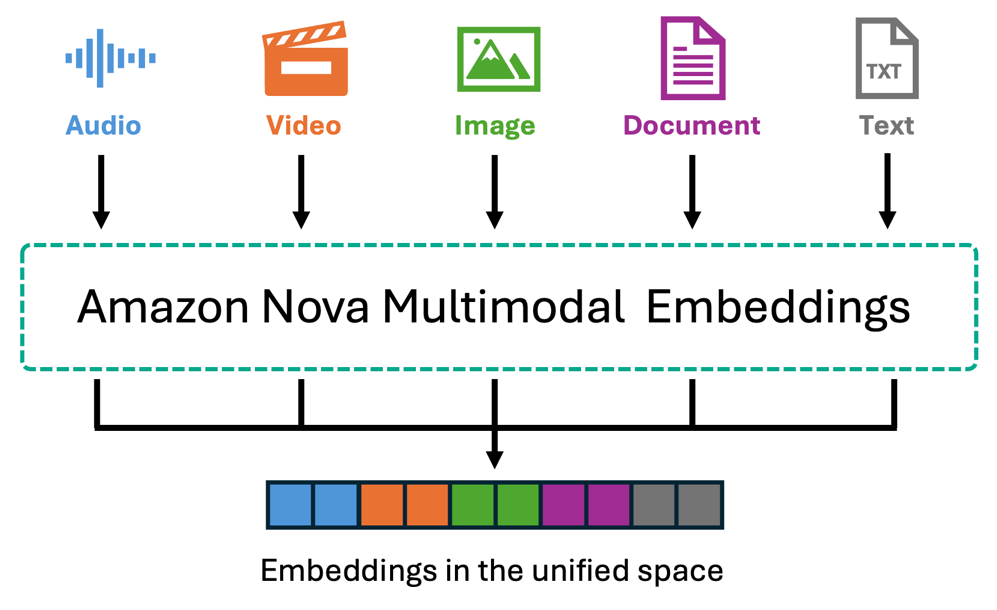
For video content material, Nova embeddings seize visible parts—scenes, objects, movement, and actions—in addition to audio traits like music, sounds, and ambient noise. For movies the place spoken dialogue is vital to your use case, you should use Bedrock Knowledge Automation to extract transcripts alongside visible descriptions. For standalone audio recordsdata, Nova processes acoustic options resembling music, environmental sounds, and audio patterns. The cross-modal functionality allows use instances resembling describing a visible scene in textual content to retrieve matching movies, add a reference picture to seek out comparable merchandise, or find particular actions in footage—all with out pre-existing textual content descriptions.
Finest for: Product catalogs, visible search, manufacturing movies, sports activities footage, safety cameras, and situations the place visible content material drives the use case.
Amazon Bedrock Knowledge Automation
Bedrock Knowledge Automation takes a distinct strategy by changing multimedia content material into wealthy textual representations earlier than embedding. For photographs, it generates detailed descriptions together with objects, scenes, textual content inside photographs, and spatial relationships. For video, it produces scene-by-scene summaries, identifies key visible parts, and extracts the on-screen textual content. For audio and video with speech, Bedrock Knowledge Automation supplies correct transcriptions with timestamps and speaker identification, together with section summaries that seize the important thing factors mentioned.
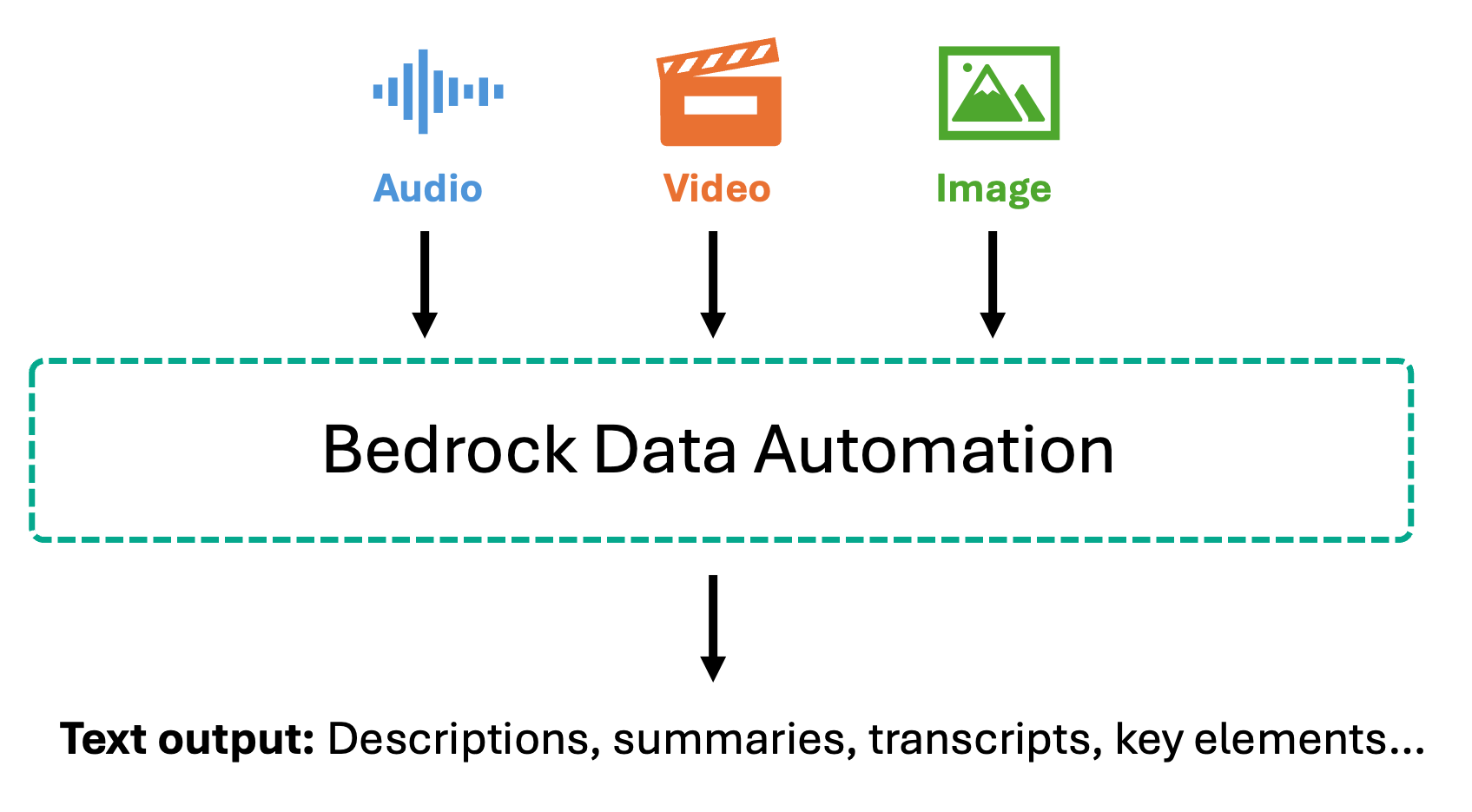
As soon as transformed to textual content, this content material is chunked and embedded utilizing textual content embedding fashions like Amazon Titan Textual content Embeddings or Amazon Nova Multimodal Embeddings. This text-first strategy allows extremely correct question-answering over spoken content material—when customers ask about particular statements made in a gathering or subjects mentioned in a podcast, the system searches by exact transcripts moderately than audio embeddings. This makes it significantly priceless for compliance situations the place you want precise quotes and verbatim information for audit trails, assembly evaluation, buyer help name mining, and use instances the place you could retrieve and confirm particular spoken data.
Finest for: Conferences, webinars, interviews, podcasts, coaching movies, help calls, and situations requiring exact retrieval of particular statements or discussions.
Use case situation: Visible product seek for e-commerce
Multimodal information bases can be utilized for purposes starting from enhanced buyer experiences and worker coaching to upkeep operations and authorized evaluation. Conventional e-commerce search depends on textual content queries, requiring prospects to articulate what they’re on the lookout for with the fitting key phrases. This breaks down once they’ve seen a product elsewhere, have a photograph of one thing they like, or wish to discover objects just like what seems in a video. Now, prospects can search your product catalog utilizing textual content descriptions, add a picture of an merchandise they’ve photographed, or reference a scene from a video to seek out matching merchandise. The system retrieves visually comparable objects by evaluating the embedded illustration of their question—whether or not textual content, picture, or video—in opposition to the multimodal embeddings of your product stock. For this situation, Amazon Nova Multimodal Embeddings is the best selection. Product discovery is basically visible—prospects care about colours, kinds, shapes, and visible particulars. By encoding your product photographs and movies into the Nova unified vector area, the system matches primarily based on visible similarity with out counting on textual content descriptions which may miss refined visible traits. Whereas a whole suggestion system would incorporate buyer preferences, buy historical past, and stock availability, retrieval from a multimodal information base supplies the foundational functionality: discovering visually related merchandise no matter how prospects select to look.
Console walkthrough
Within the following part, we stroll by the high-level steps to arrange and take a look at a multimodal information base for our e-commerce product search instance. We create a information base containing smartphone product photographs and movies, then exhibit how prospects can search utilizing textual content descriptions, uploaded photographs, or video references. The GitHub repository supplies a guided pocket book that you may comply with to deploy this instance in your account.
Stipulations
Earlier than you get began, just be sure you have the next conditions:
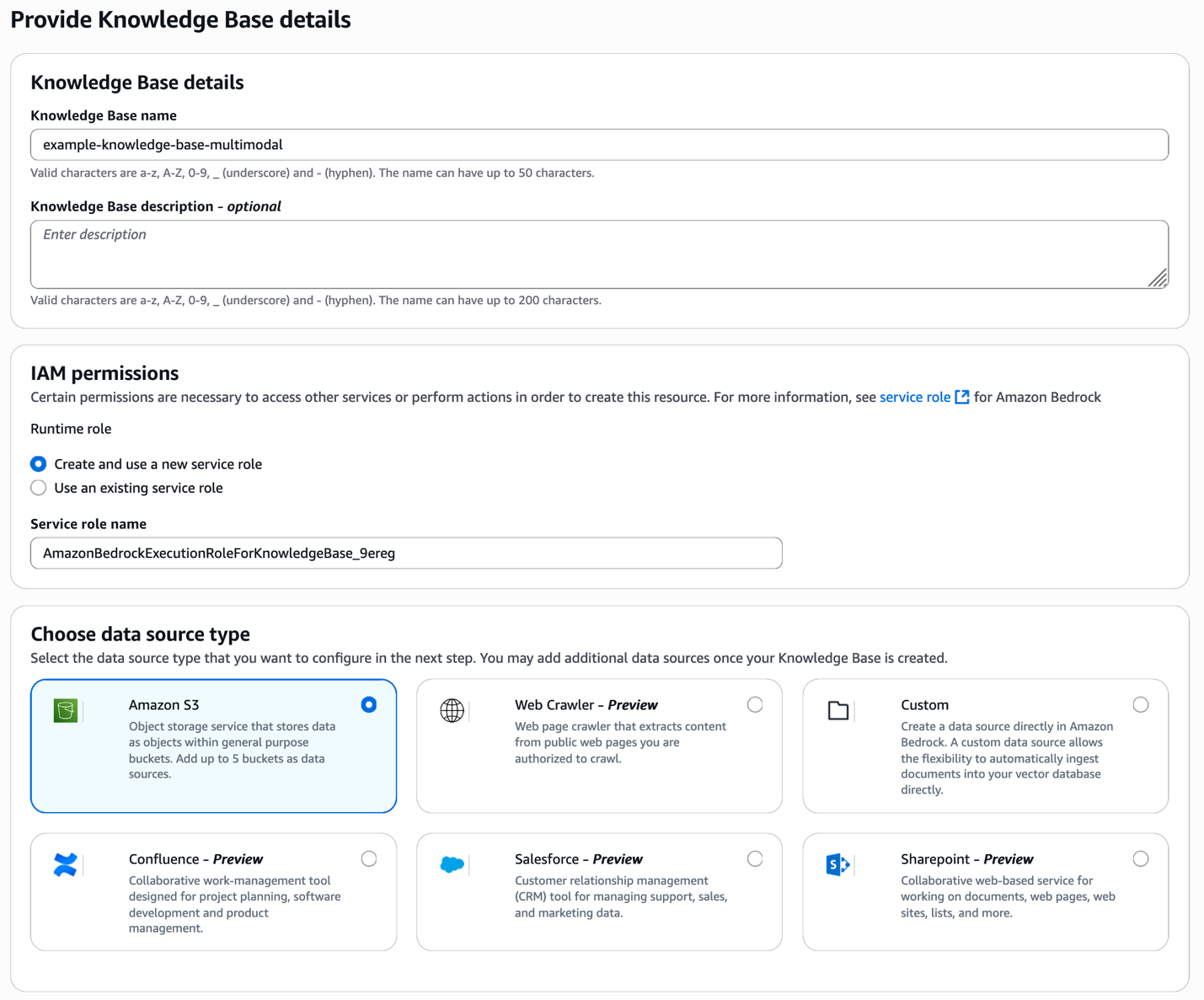
Present the information base particulars and knowledge supply sort
Begin by opening the Amazon Bedrock console and creating a brand new information base. Present a descriptive title to your information base and choose your knowledge supply sort—on this case, Amazon S3 the place your product photographs and movies are saved.
Configure knowledge supply
Join your S3 bucket containing product photographs and movies. For the parsing technique, choose Amazon Bedrock default parser. Since we’re utilizing Nova Multimodal Embeddings, the photographs and movies are processed natively and embedded immediately into the unified vector area, preserving their visible traits with out conversion to textual content.
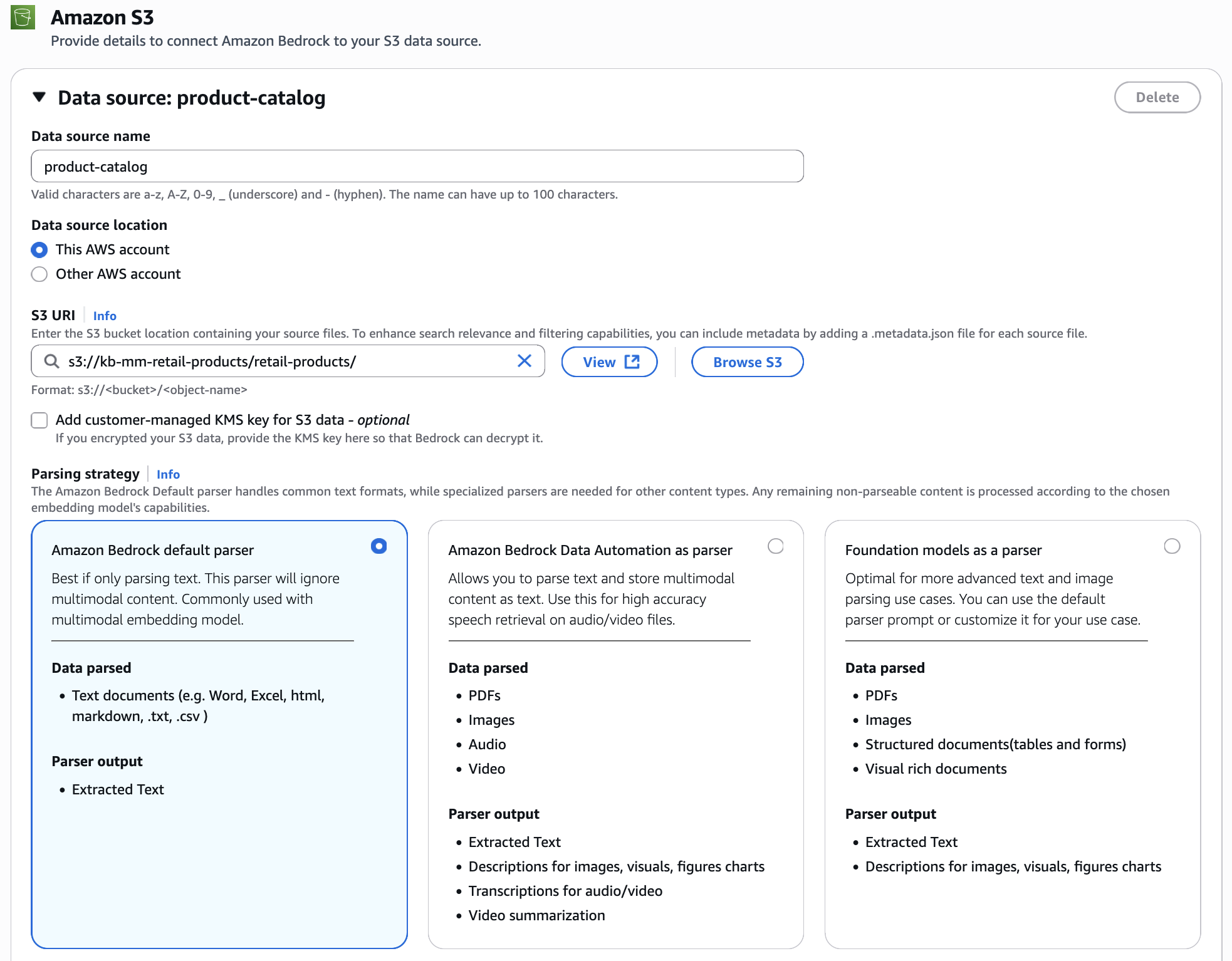
Configure knowledge storage and processing
Choose Amazon Nova Multimodal Embeddings as your embedding mannequin. This unified embedding mannequin encodes each your product photographs and buyer queries into the identical vector area, enabling cross-modal retrieval the place textual content queries can retrieve photographs and picture queries can discover visually comparable merchandise. For this instance, we use Amazon S3 Vectors because the vector retailer (you might optionally use different out there vector shops), which supplies cost-effective and sturdy storage optimized for large-scale vector knowledge units whereas sustaining sub-second question efficiency. You additionally must configure the multimodal storage vacation spot by specifying an S3 location. Information Bases makes use of this location to retailer extracted photographs and different media out of your knowledge supply. When customers question the information base, related media is retrieved from this storage.
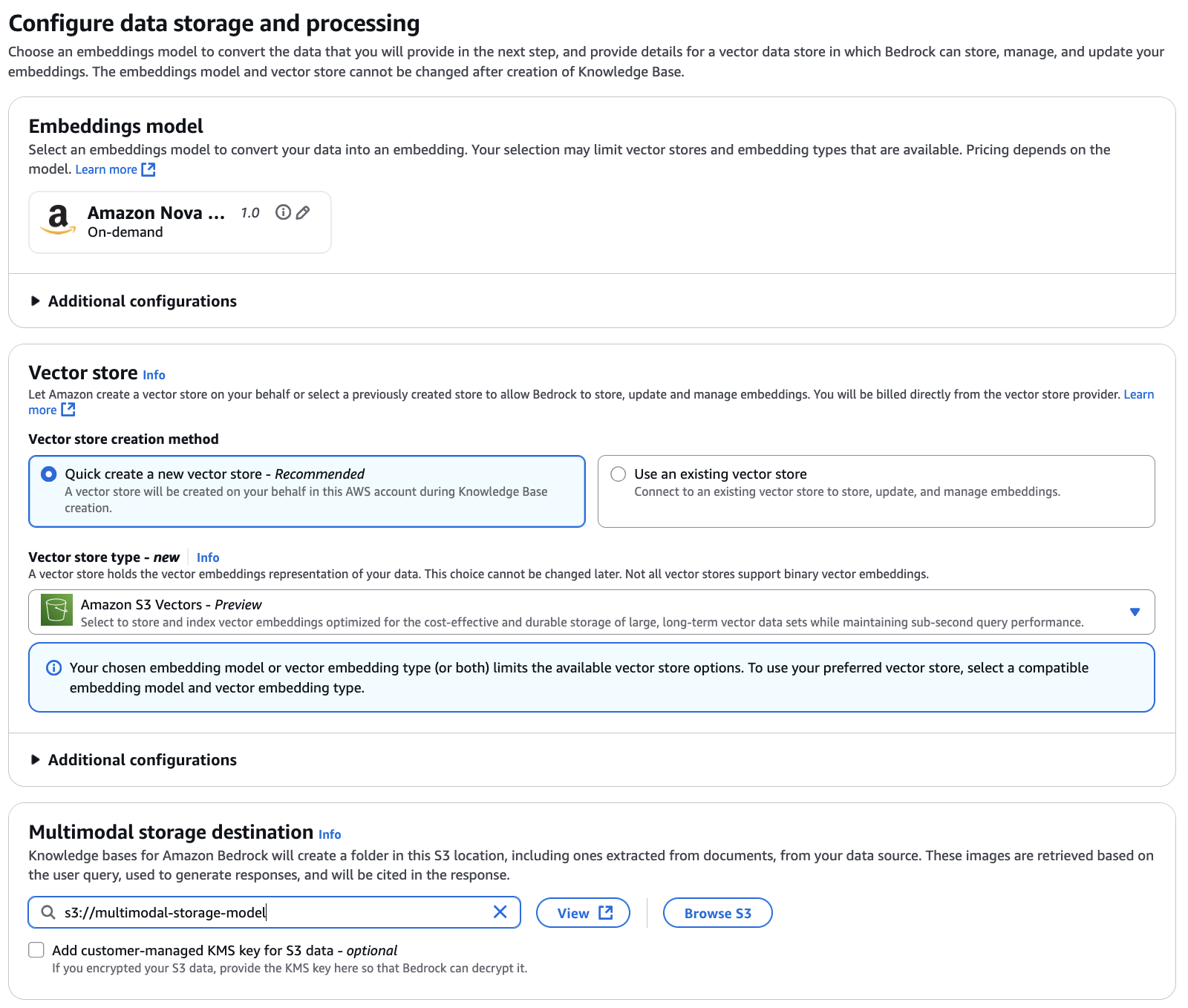
Evaluation and create
Evaluation your configuration settings together with the information base particulars, knowledge supply configuration, embedding mannequin choice—we’re utilizing Amazon Nova Multimodal Embeddings v1 with 3072 vector dimensions (increased dimensions present richer representations; you should use decrease dimensions like 1,024, 384, or 256 to optimize for storage and value) —and vector retailer setup (Amazon S3 Vectors). As soon as every thing appears appropriate, create your information base.
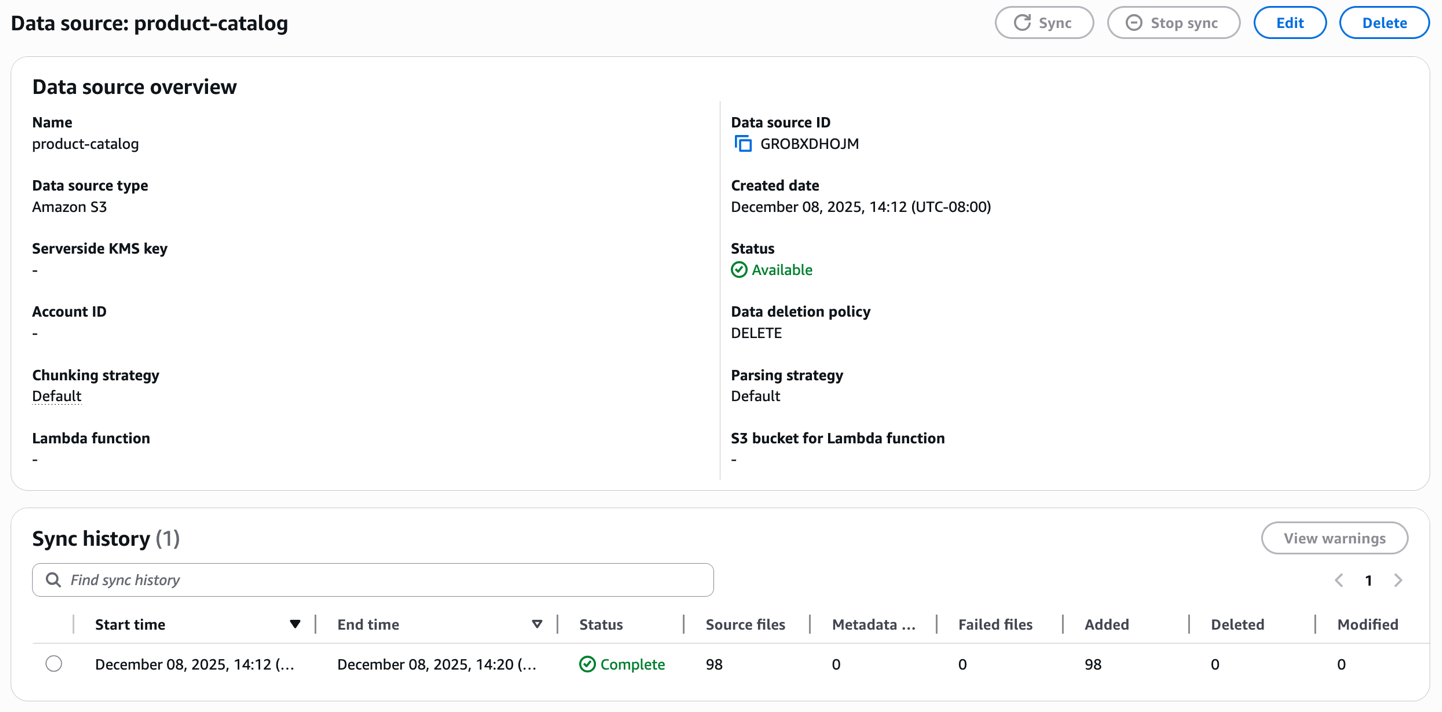
Create an ingestion job
As soon as created, provoke the sync course of to ingest your product catalog. The information base processes every picture and video, generates embeddings and shops them within the managed vector database. Monitor the sync standing to substantiate the paperwork are efficiently listed.
Check the information base utilizing textual content as enter in your immediate
Together with your information base prepared, take a look at it utilizing a textual content question within the console. Search with product descriptions like “A metallic telephone cowl” (or something equal that could possibly be related to your merchandise media) to confirm that text-based retrieval works accurately throughout your catalog.

Check the information base utilizing a reference picture and retrieve totally different modalities
Now for the highly effective half—visible search. Add a reference picture of a product you wish to discover. For instance, think about you noticed a cellphone cowl on one other web site and wish to discover comparable objects in your catalog. Merely add the picture with out further textual content immediate.
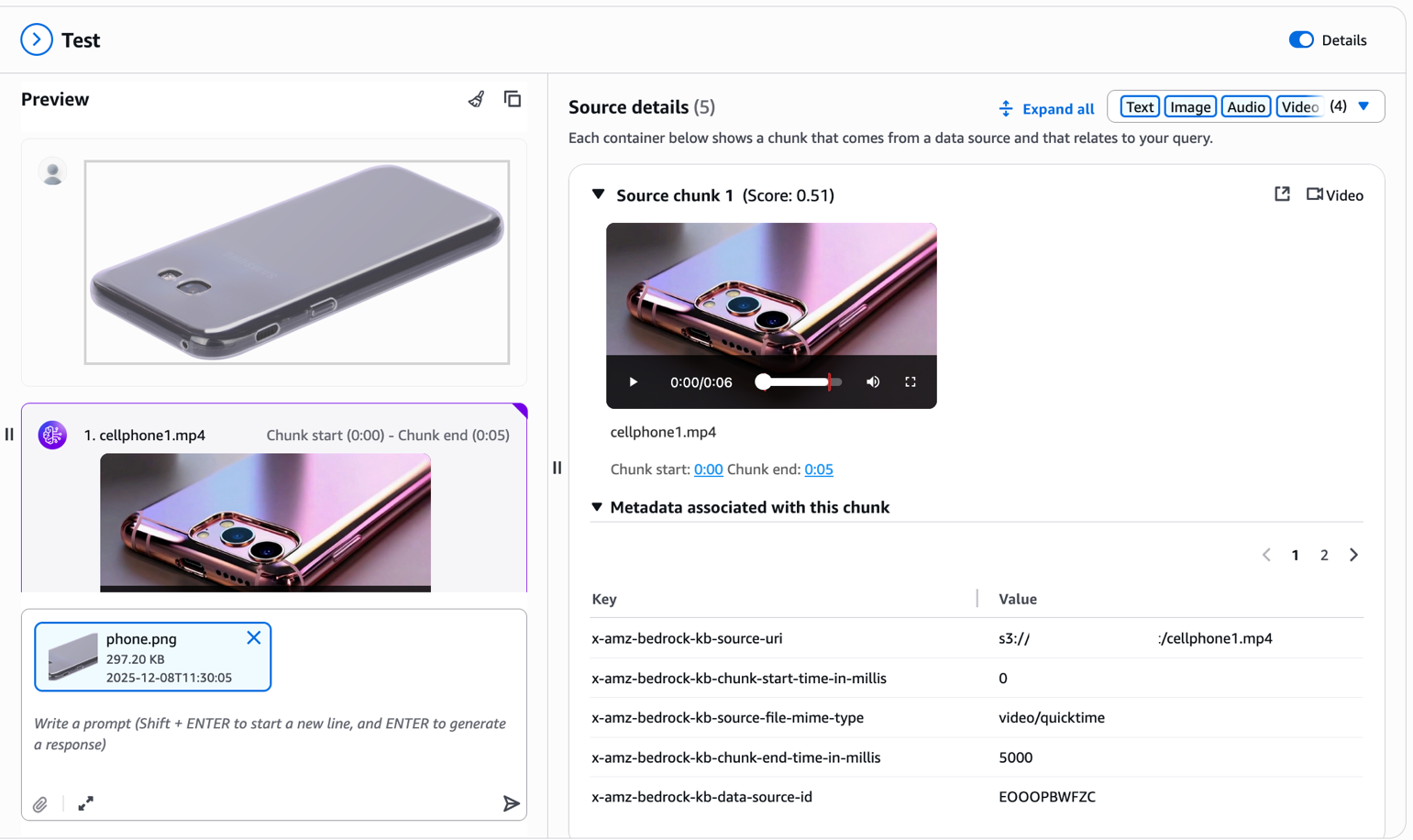
The multimodal information base extracts visible options out of your uploaded picture and retrieves visually comparable merchandise out of your catalog. As you possibly can see within the outcomes, the system returns telephone covers with comparable design patterns, colours, or visible traits. Discover the metadata related to every chunk within the Supply particulars panel. The x-amz-bedrock-kb-chunk-start-time-in-millis and x-amz-bedrock-kb-chunk-end-time-in-millis fields point out the precise temporal location of this section throughout the supply video. When constructing purposes programmatically, you should use these timestamps to extract and show the particular video section that matched the question, enabling options like “leap to related second” or clip era immediately out of your supply movies. This cross-modal functionality transforms the procuring expertise—prospects now not want to explain what they’re on the lookout for with phrases; they’ll present you.
Check the information base utilizing a reference picture and retrieve totally different modalities utilizing Bedrock Knowledge Automation
Now we take a look at what the outcomes would appear like when you configured Bedrock Knowledge Automation parsing in the course of the knowledge supply setup. Within the following screenshot, discover the transcript part within the Supply particulars panel.
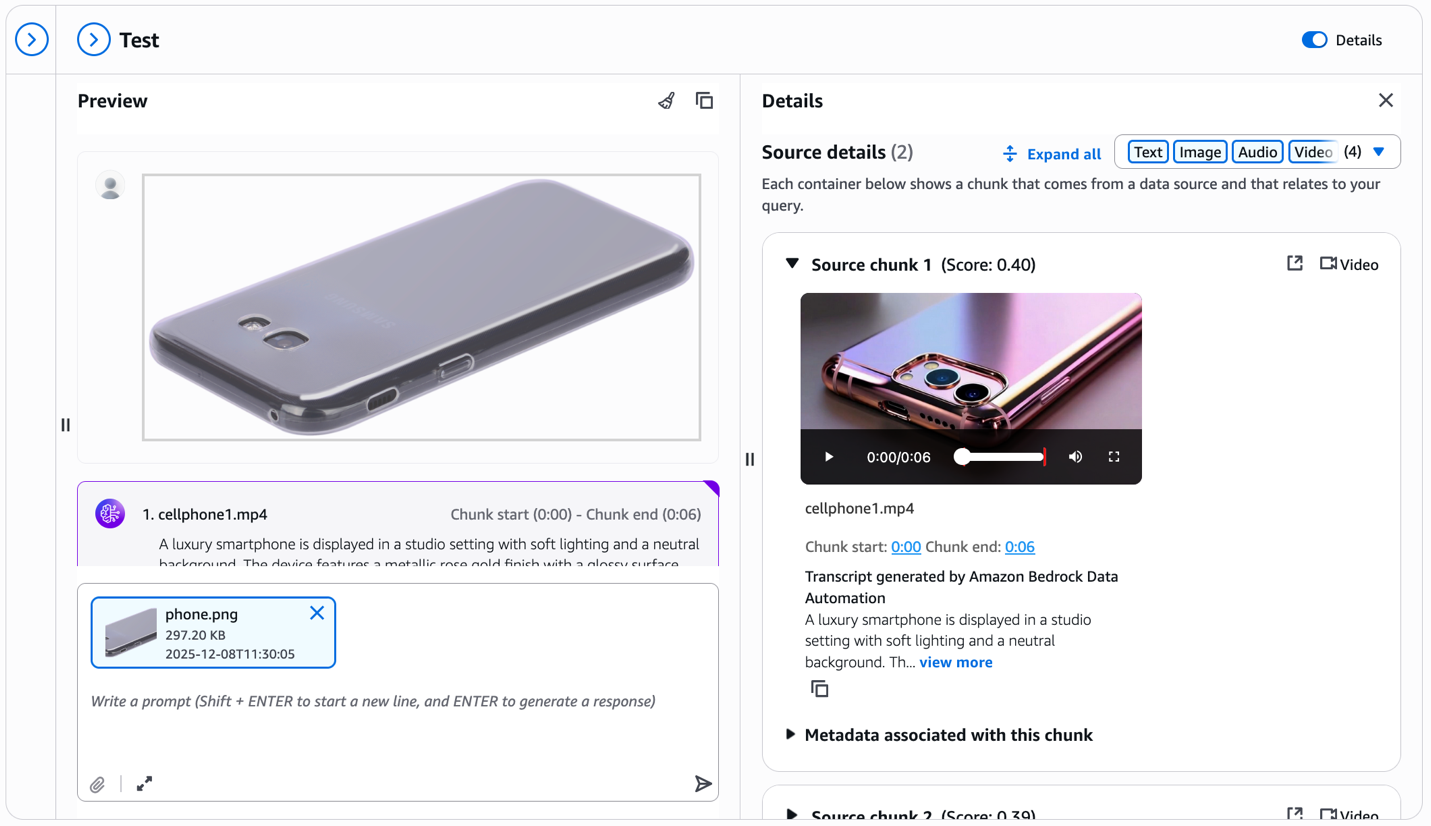
For every retrieved video chunk, Bedrock Knowledge Automation robotically generates an in depth textual content description—on this instance, describing the smartphone’s metallic rose gold end, studio lighting, and visible traits. This transcript seems immediately within the take a look at window alongside the video, offering wealthy textual context. You get each visible similarities matching from the multimodal embeddings and detailed product descriptions that may reply particular questions on options, colours, supplies, and different attributes seen within the video.
Clear-up
To scrub up your sources, full the next steps, beginning with deleting the information base:
- On the Amazon Bedrock console, select Information Bases
- Choose your Information Base and be aware each the IAM service function title and S3 Vector index ARN
- Select Delete and ensure
To delete the S3 Vector as a vector retailer, use the next AWS Command Line Interface (AWS CLI) instructions:
- On the IAM console, discover the function famous earlier
- Choose and delete the function
To delete the pattern dataset:
- On the Amazon S3 console, discover your S3 bucket
- Choose and delete the recordsdata you uploaded for this tutorial
Conclusion
Multimodal retrieval for Amazon Bedrock Information Bases removes the complexity of constructing RAG purposes that span textual content, photographs, video, and audio. With native help for video and audio content material, now you can construct complete information bases that unlock insights out of your enterprise knowledge—not simply textual content paperwork.
The selection between Amazon Nova Multimodal Embeddings and Bedrock Knowledge Automation offers you flexibility to optimize to your particular content material. The Nova unified vector area allows cross-modal retrieval for visual-driven use instances, whereas the Bedrock Knowledge Automation text-first strategy delivers exact transcription-based retrieval for speech-heavy content material. Each approaches combine seamlessly into the identical absolutely managed workflow, assuaging the necessity for customized preprocessing pipelines.
Availability
Area availability relies on the options chosen for multimodal help, please discuss with the documentation for particulars.
Subsequent steps
Get began with multimodal retrieval in the present day:
- Discover the documentation: Evaluation the Amazon Bedrock Information Bases documentation and Amazon Nova Person Information for added technical particulars.
- Experiment with code examples: Take a look at the Amazon Bedrock samples repository for hands-on notebooks demonstrating multimodal retrieval.
- Be taught extra about Nova: Learn the Amazon Nova Multimodal Embeddings announcement for deeper technical insights.
Concerning the authors
 Dani Mitchell is a Generative AI Specialist Options Architect at Amazon Internet Companies (AWS). He’s centered on serving to speed up enterprises internationally on their generative AI journeys with Amazon Bedrock and Bedrock AgentCore.
Dani Mitchell is a Generative AI Specialist Options Architect at Amazon Internet Companies (AWS). He’s centered on serving to speed up enterprises internationally on their generative AI journeys with Amazon Bedrock and Bedrock AgentCore.
 Pallavi Nargund is a Principal Options Architect at AWS. She is a generative AI lead for US Greenfield and leads the AWS for Authorized Tech group. She is enthusiastic about girls in expertise and is a core member of Girls in AI/ML at Amazon. She speaks at inner and exterior conferences resembling AWS re:Invent, AWS Summits, and webinars. Pallavi holds a Bachelor’s of Engineering from the College of Pune, India. She lives in Edison, New Jersey, along with her husband, two women, and her two pups.
Pallavi Nargund is a Principal Options Architect at AWS. She is a generative AI lead for US Greenfield and leads the AWS for Authorized Tech group. She is enthusiastic about girls in expertise and is a core member of Girls in AI/ML at Amazon. She speaks at inner and exterior conferences resembling AWS re:Invent, AWS Summits, and webinars. Pallavi holds a Bachelor’s of Engineering from the College of Pune, India. She lives in Edison, New Jersey, along with her husband, two women, and her two pups.
 Jean-Pierre Dodel is a Principal Product Supervisor for Amazon Bedrock, Amazon Kendra, and Amazon Fast Index. He brings 15 years of Enterprise Search and AI/ML expertise to the group, with prior work at Autonomy, HP, and search startups earlier than becoming a member of Amazon 8 years in the past. JP is at present specializing in improvements for multimodal RAG, agentic retrieval, and structured RAG.
Jean-Pierre Dodel is a Principal Product Supervisor for Amazon Bedrock, Amazon Kendra, and Amazon Fast Index. He brings 15 years of Enterprise Search and AI/ML expertise to the group, with prior work at Autonomy, HP, and search startups earlier than becoming a member of Amazon 8 years in the past. JP is at present specializing in improvements for multimodal RAG, agentic retrieval, and structured RAG.



{kind=link}