
Machine studying (ML) helps organizations to extend income, drive enterprise development, and cut back prices by optimizing core enterprise capabilities corresponding to provide and demand forecasting, buyer churn prediction, credit score threat scoring, pricing, predicting late shipments, and plenty of others.
Typical ML growth cycles take weeks to many months and requires sparse knowledge science understanding and ML growth abilities. Enterprise analysts’ concepts to make use of ML fashions usually sit in extended backlogs due to knowledge engineering and knowledge science group’s bandwidth and knowledge preparation actions.
On this submit, we dive right into a enterprise use case for a banking establishment. We’ll present you the way a monetary or enterprise analyst at a financial institution can simply predict if a buyer’s mortgage can be absolutely paid, charged off, or present utilizing a machine studying mannequin that’s greatest for the enterprise downside at hand. The analyst can simply pull within the knowledge they want, use pure language to wash up and fill any lacking knowledge, and eventually construct and deploy a machine studying mannequin that may precisely predict the mortgage standing as an output, all while not having to turn into a machine studying professional to take action. The analyst will even be capable to shortly create a enterprise intelligence (BI) dashboard utilizing the outcomes from the ML mannequin inside minutes of receiving the predictions. Let’s study concerning the providers we’ll use to make this occur.
Amazon SageMaker Canvas is a web-based visible interface for constructing, testing, and deploying machine studying workflows. It permits knowledge scientists and machine studying engineers to work together with their knowledge and fashions and to visualise and share their work with others with only a few clicks.
SageMaker Canvas has additionally built-in with Knowledge Wrangler, which helps with creating knowledge flows and getting ready and analyzing your knowledge. Constructed into Knowledge Wrangler, is the Chat for knowledge prep choice, which lets you use pure language to discover, visualize, and rework your knowledge in a conversational interface.
Amazon Redshift is a quick, absolutely managed, petabyte-scale knowledge warehouse service that makes it cost-effective to effectively analyze all of your knowledge utilizing your current enterprise intelligence instruments.
Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. With QuickSight, all customers can meet various analytic wants from the identical supply of reality by trendy interactive dashboards, paginated reviews, embedded analytics, and pure language queries.
Resolution overview
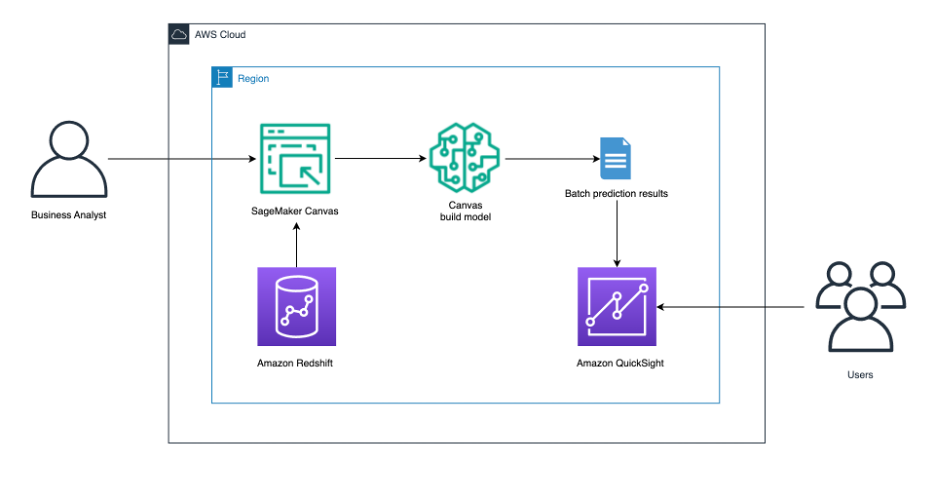
The answer structure that follows illustrates:
- A enterprise analyst signing in to SageMaker Canvas.
- The enterprise analyst connects to the Amazon Redshift knowledge warehouse and pulls the specified knowledge into SageMaker Canvas to make use of.
- We inform SageMaker Canvas to construct a predictive evaluation ML mannequin.
- After the mannequin has been constructed, get batch prediction outcomes.
- Ship the outcomes to QuickSight for customers to additional analyze.
Stipulations
Earlier than you start, be sure you have the next conditions in place:
- An AWS account and function with the AWS Id and Entry Administration (IAM) privileges to deploy the next sources:
- IAM roles.
- A provisioned or serverless Amazon Redshift knowledge warehouse. For this submit we’ll use a provisioned Amazon Redshift cluster.
- A SageMaker area.
- A QuickSight account (non-compulsory).
- Primary data of a SQL question editor.
Arrange the Amazon Redshift cluster
We’ve created a CloudFormation template to arrange the Amazon Redshift cluster.
- Deploy the Cloudformation template to your account.

- Enter a stack identify, then select Subsequent twice and hold the remainder of parameters as default.
- Within the evaluate web page, scroll right down to the Capabilities part, and choose I acknowledge that AWS CloudFormation would possibly create IAM sources.
- Select Create stack.
The stack will run for 10–quarter-hour. After it’s completed, you may view the outputs of the father or mother and nested stacks as proven within the following figures:
Mother or father stack
Nested stack 
Pattern knowledge
You’ll use a publicly accessible dataset that AWS hosts and maintains in our personal S3 bucket as a workshop for financial institution clients and their loans that features buyer demographic knowledge and mortgage phrases.
Implementation steps
Load knowledge to the Amazon Redshift cluster
- Hook up with your Amazon Redshift cluster utilizing Question Editor v2. To navigate to the Amazon Redshift Question v2 editor, please comply with the steps Opening question editor v2.
- Create a desk in your Amazon Redshift cluster utilizing the next SQL command:

- Load knowledge into the
loan_custdesk utilizing the nextCOPYcommand:
- Question the desk to see what the information seems like:

Arrange chat for knowledge
- To make use of the chat for knowledge choice in Sagemaker Canvas, you have to allow it in Amazon Bedrock.
- Open the AWS Administration Console, go to Amazon Bedrock, and select Mannequin entry within the navigation pane.
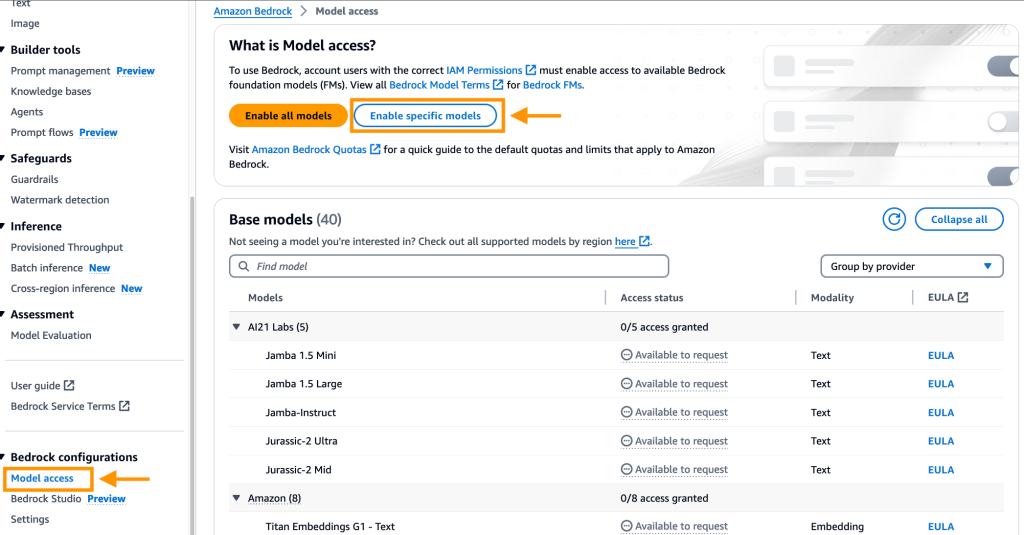
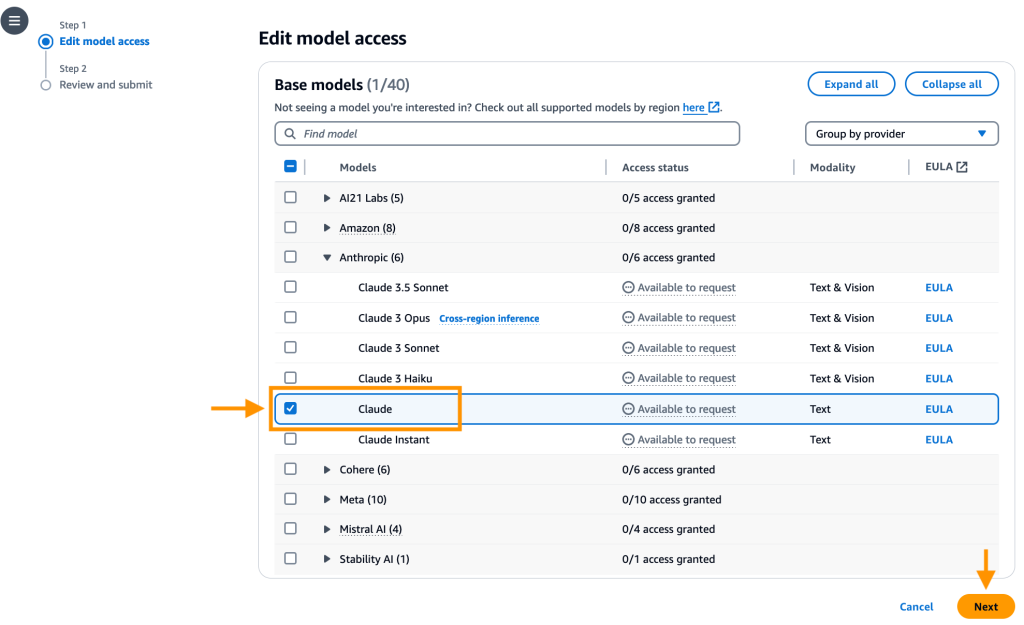
- Select Allow particular fashions, beneath Anthropic, choose Claude and choose Subsequent.
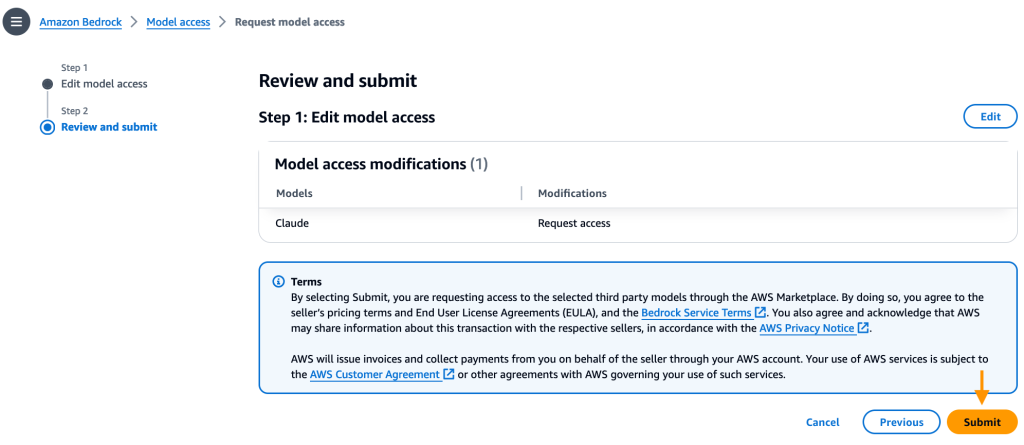
- Evaluation the choice and click on Submit.
- Open the AWS Administration Console, go to Amazon Bedrock, and select Mannequin entry within the navigation pane.
- Navigate to Amazon SageMaker service from the AWS administration console, choose Canvas and click on on Open Canvas.
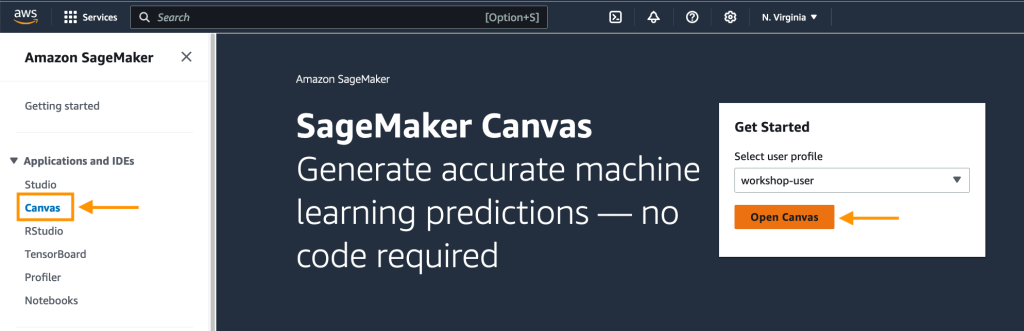
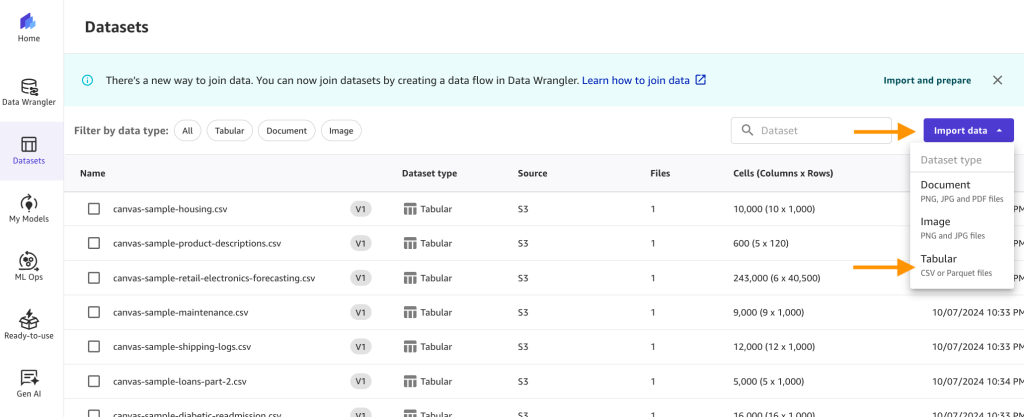
- Select Datasets from the navigation pane, then select the Import knowledge dropdown, and choose Tabular.
- For Dataset identify, enter
redshift_loandataand select Create.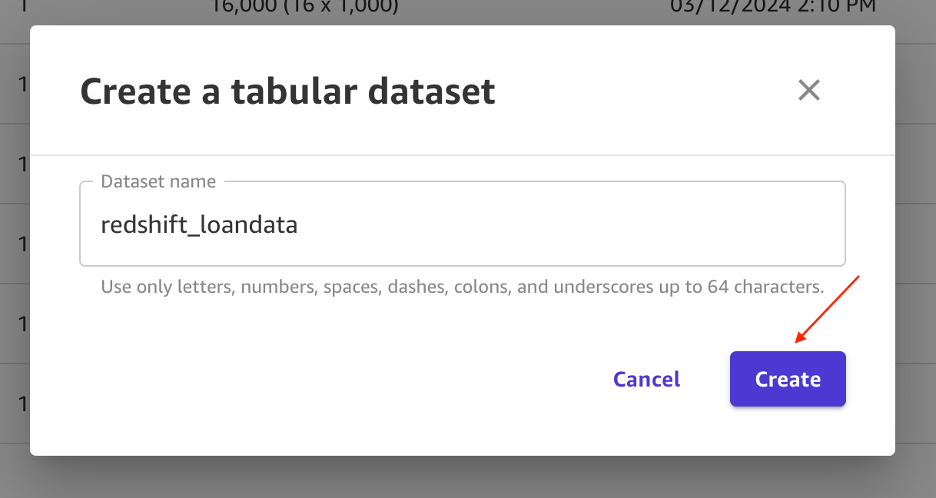
- On the following web page, select Knowledge Supply and choose Redshift because the supply. Beneath Redshift, choose + Add Connection.
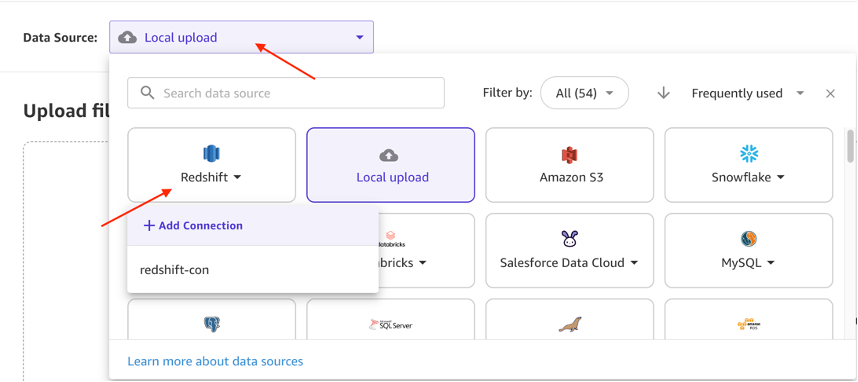
- Enter the next particulars to ascertain your Amazon Redshift connection :
- Cluster Identifier: Copy the
ProducerClusterNamefrom the CloudFormation nested stack outputs. - You’ll be able to reference the previous display shot for Nested Stack, the place one can find the cluster identifier output.
- Database identify: Enter
dev. - Database consumer: Enter
awsuser. - Unload IAM Position ARN: Copy the
RedshiftDataSharingRoleNamefrom the nested stack outputs. - Connection Title: Enter
MyRedshiftCluster. - Select Add connection.

- Cluster Identifier: Copy the
- After the connection is created, increase the
publicschema, drag theloan_custdesk into the editor, and select Create dataset.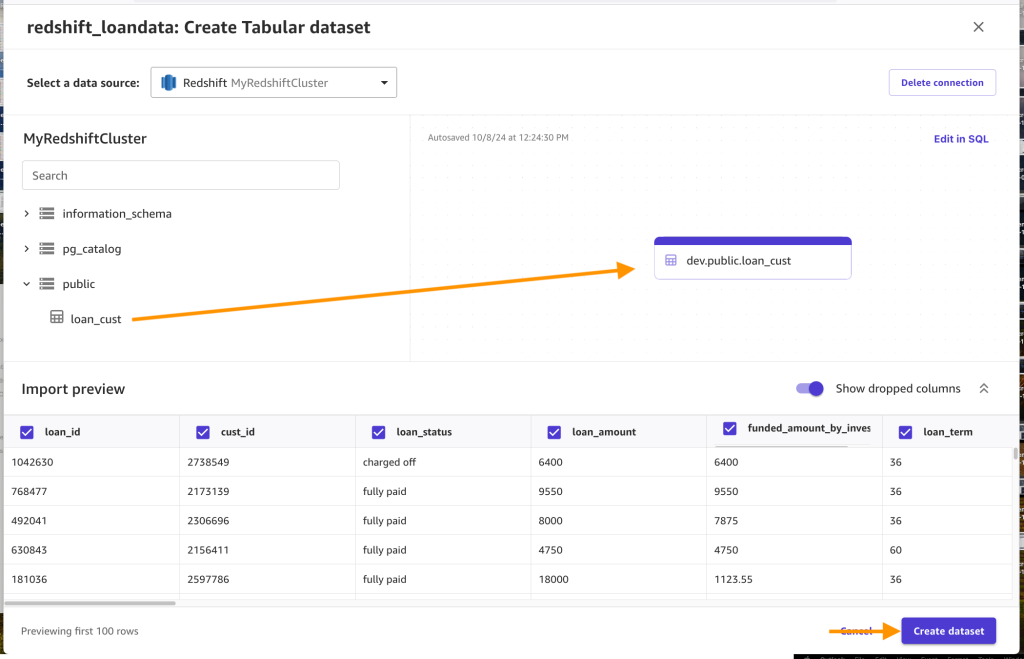
- Select the
redshift_loandatadataset and select Create a knowledge movement.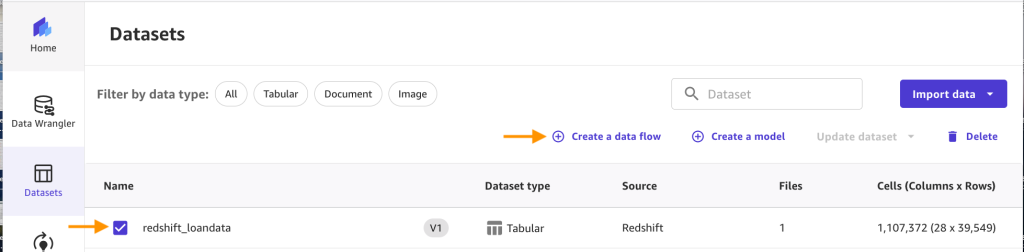
- Enter
redshift_flowfor the identify and select Create.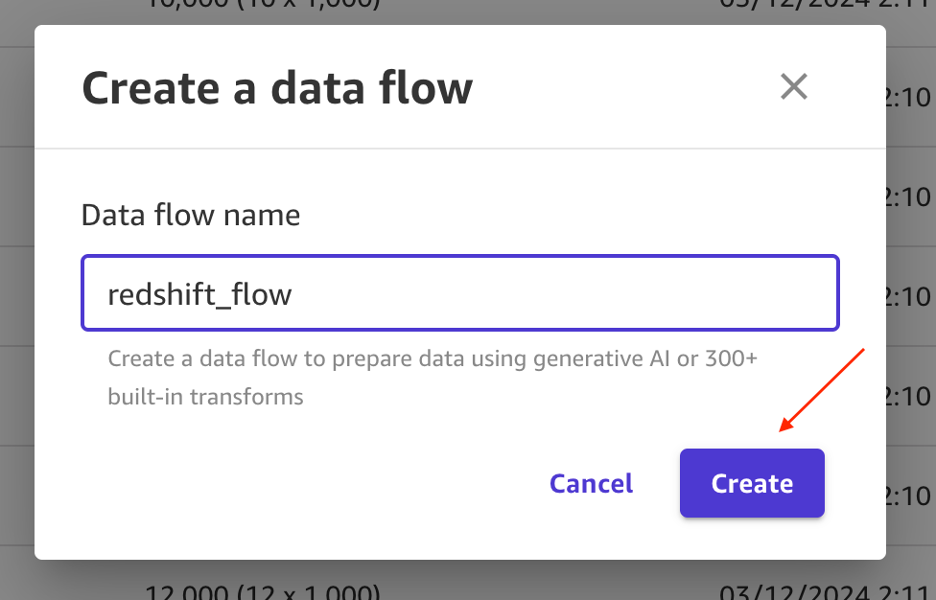
- After the movement is created, select Chat for knowledge prep.
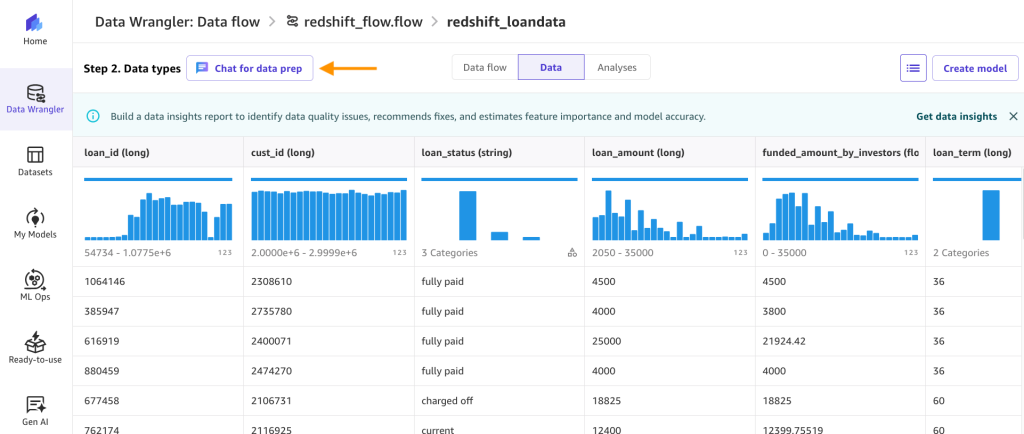
- Within the textual content field, enter
summarize my knowledgeand select the run arrow.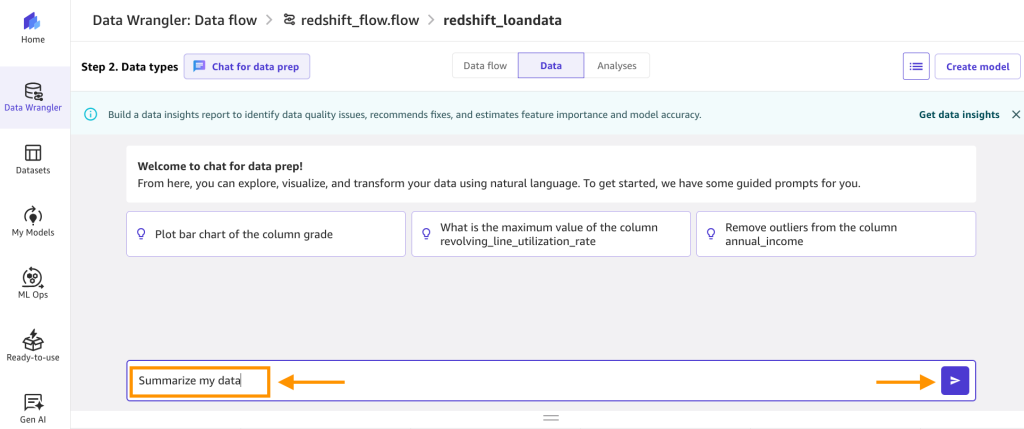
- The output ought to look one thing like the next:

- Now you should utilize pure language to prep the dataset. Enter
Drop ssn and filter for ages over 17and click on on the run arrow. You will notice it was capable of deal with each steps. You may as well view the PySpark code that it ran. So as to add these steps as dataset transforms, select Add to steps.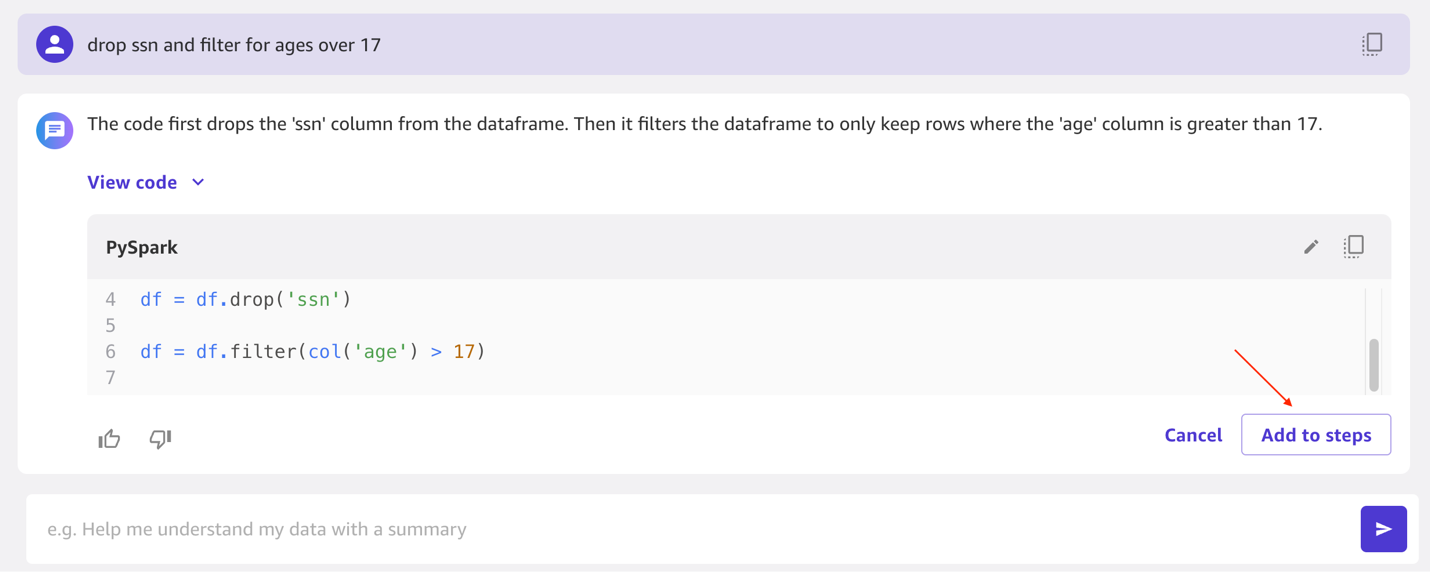
- Rename the step to
drop ssn and filter age > 17, select Replace, after which select Create mannequin.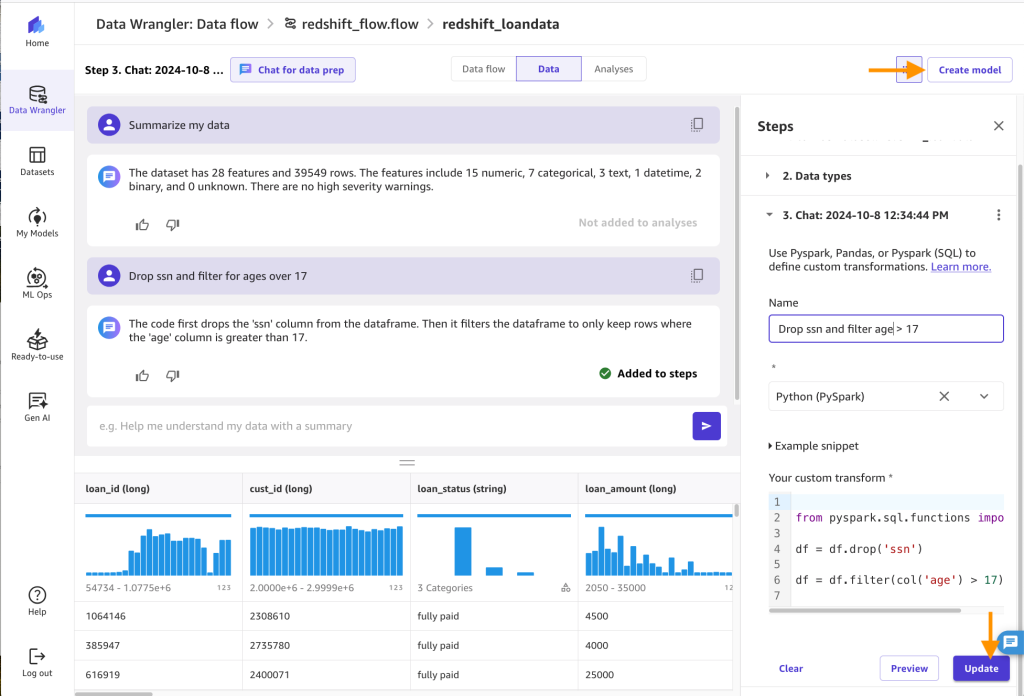
- Export knowledge and create mannequin: Enter
loan_data_forecast_datasetfor the Dateset identify, for Mannequin identify, enterloan_data_forecast, for Downside sort, selectPredictive evaluation, for Goal column, chooseloan_status, and click on Export and create mannequin.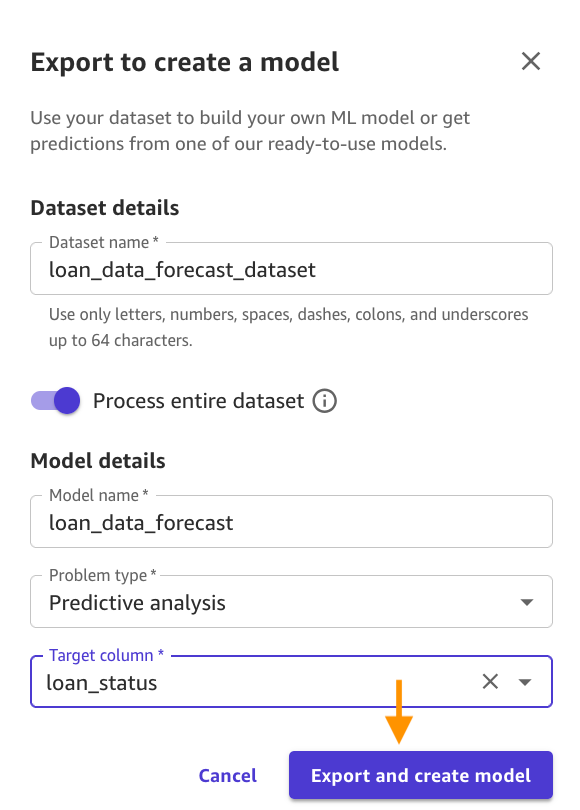
- Confirm the proper Goal column and Mannequin sort is chosen and click on on Fast construct.
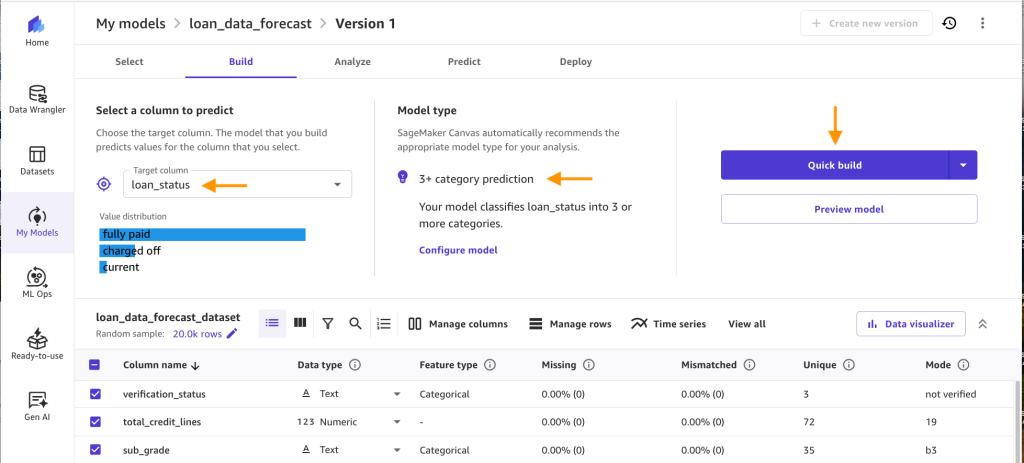
- Now the mannequin is being created. It normally takes 14–20 minutes relying on the scale of your knowledge set.
- After the mannequin has accomplished coaching, you may be routed to the Analyze tab. There, you may see the common prediction accuracy and the column affect on prediction final result. Observe that your numbers would possibly differ from those you see within the following determine, due to the stochastic nature of the ML course of.
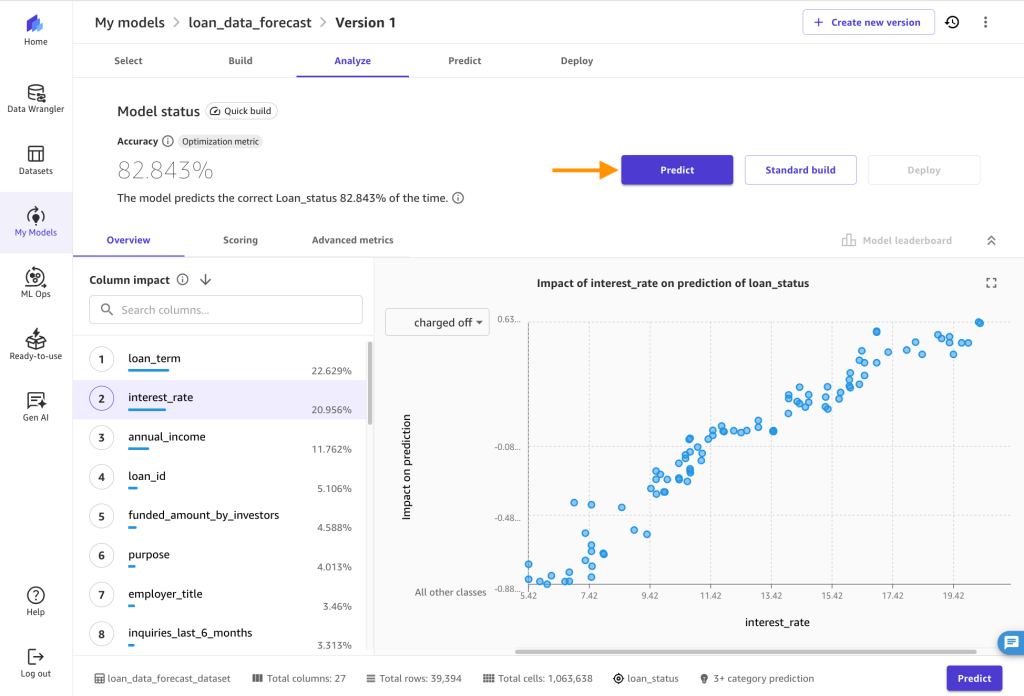
Use the mannequin to make predictions
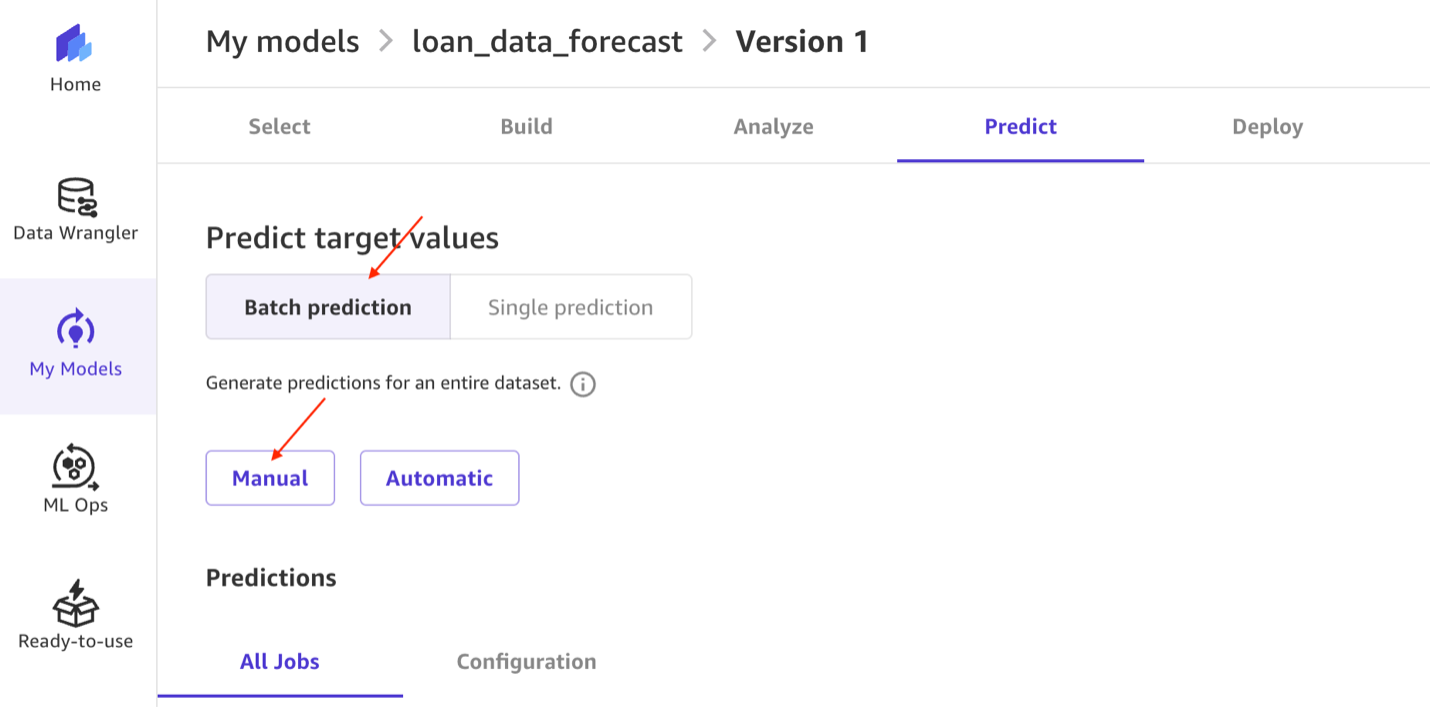
- Now let’s use the mannequin to make predictions for the long run standing of loans. Select Predict.

- Beneath Select the prediction sort, choose Batch prediction, then choose Handbook.
- Then choose loan_data_forecast_dataset from the dataset record, and click on Generate predictions.
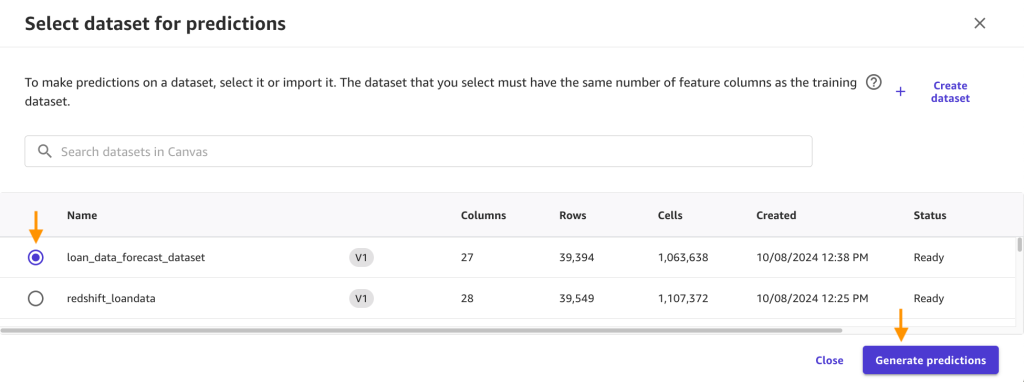
- You’ll see the next after the batch prediction is full. Click on on the breadcrumb menu subsequent to the Prepared standing and click on on Preview to view the outcomes.
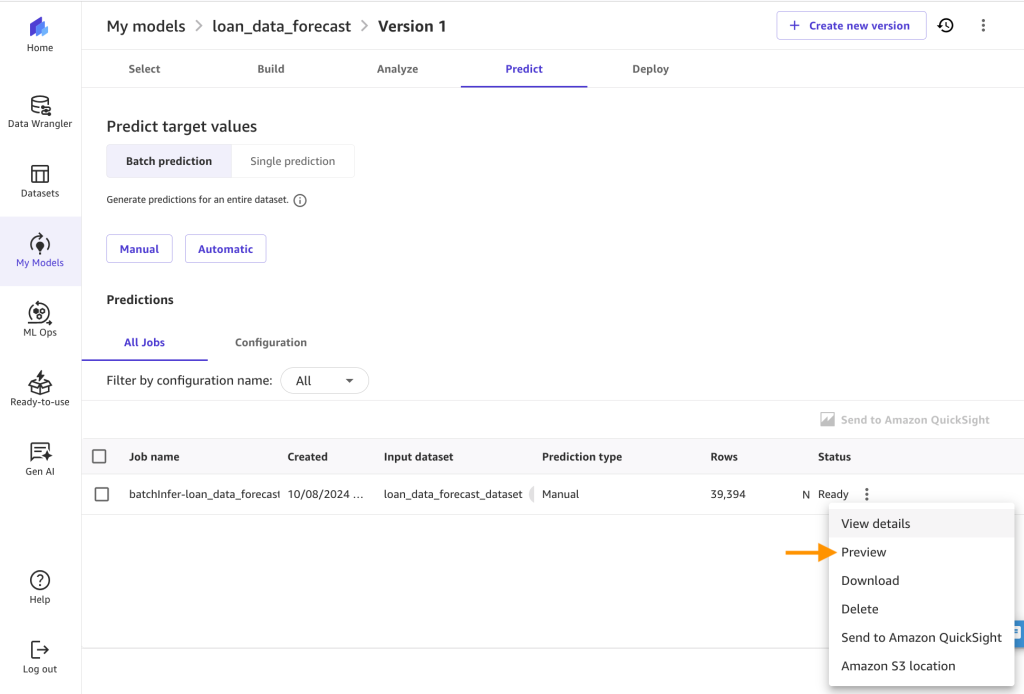
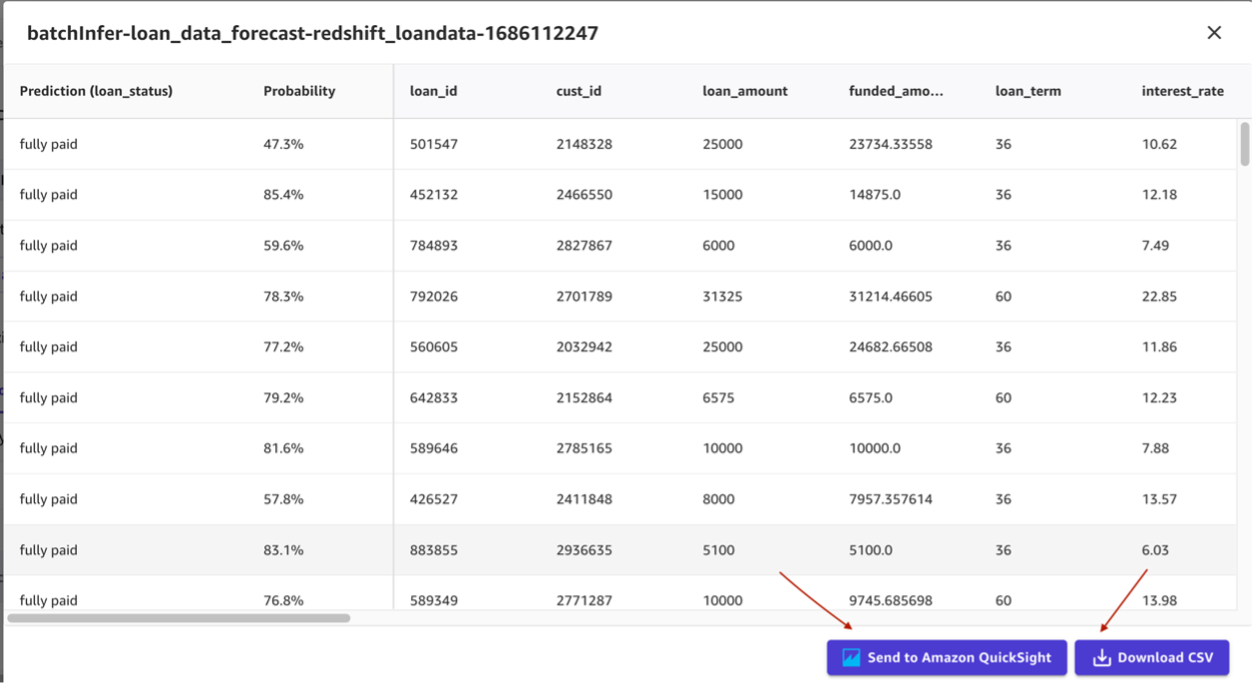
- Now you can view the predictions and obtain them as CSV.
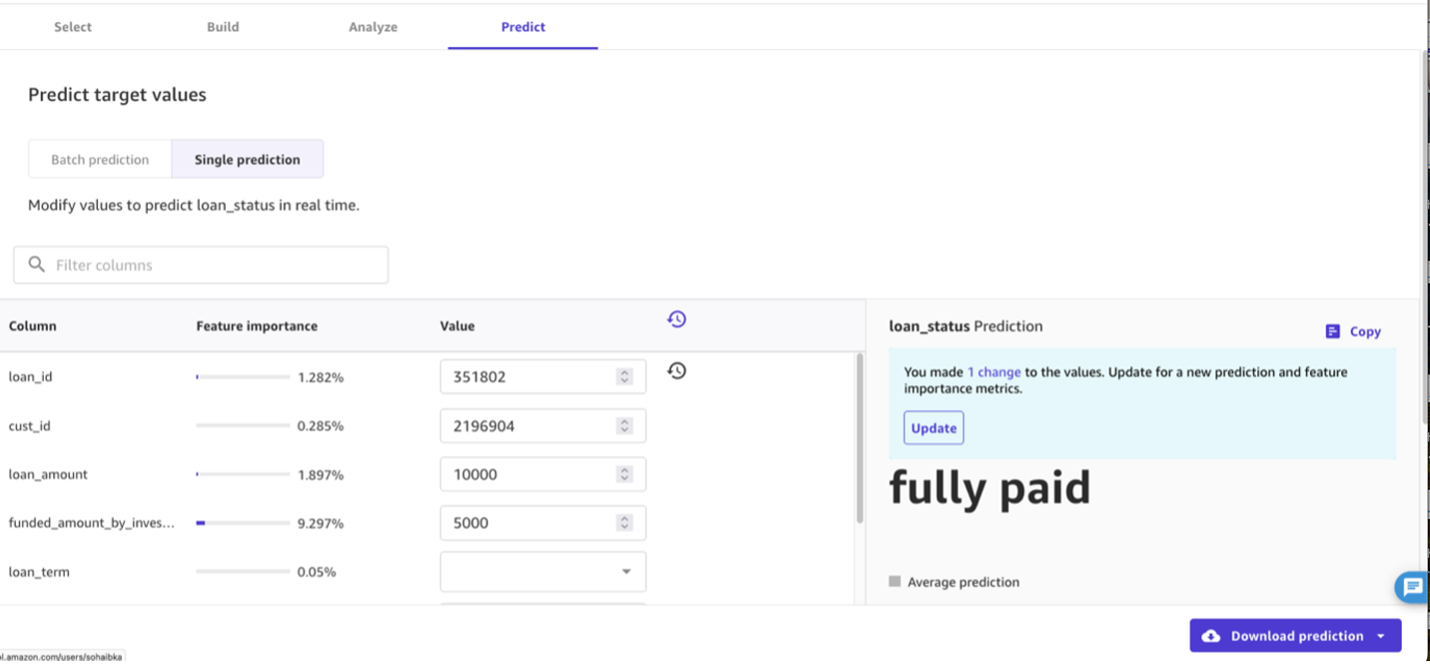
- You may as well generate single predictions for one row of knowledge at a time. Beneath Select the prediction sort, choose Single Prediction after which change the values for any of the enter fields that you simply’d like, and select Replace.
Analyze the predictions
We’ll now present you the right way to use Quicksight to visualise the predictions knowledge from SageMaker canvas to additional acquire insights out of your knowledge. SageMaker Canvas has direct integration with QuickSight, which is a cloud-powered enterprise analytics service that helps workers inside a corporation to construct visualizations, carry out ad-hoc evaluation, and shortly get enterprise insights from their knowledge, anytime, on any system.
- With the preview web page up, select Ship to Amazon QuickSight.
- Enter a QuickSight consumer identify you wish to share the outcomes to.
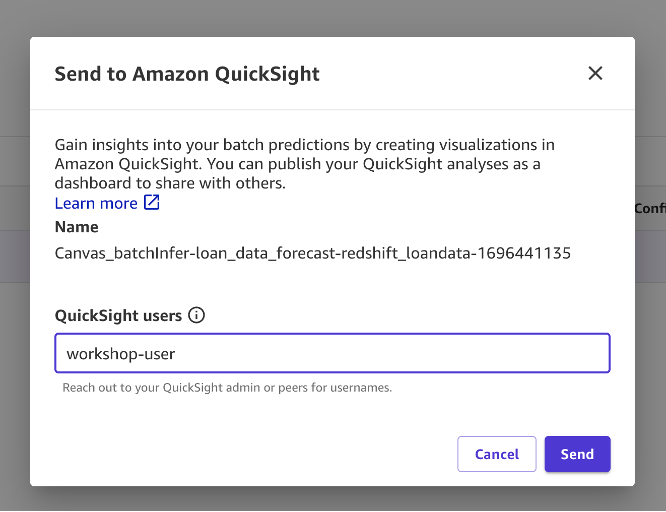
- Select Ship and it is best to see affirmation saying the outcomes have been despatched efficiently.

- Now, you may create a QuickSight dashboard for predictions.
- Go to the QuickSight console by getting into QuickSight in your console providers search bar and select QuickSight.
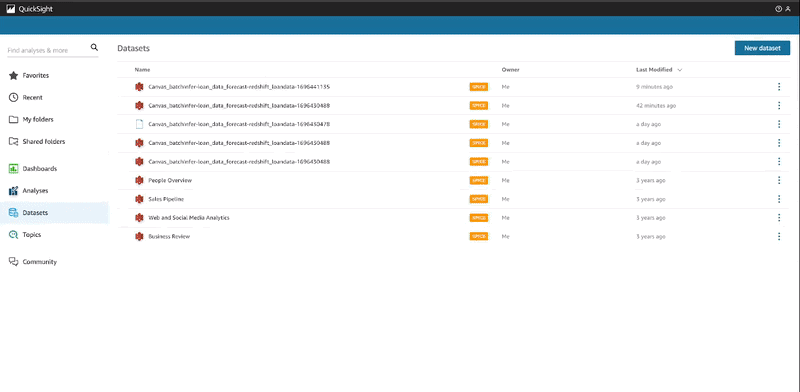
- Beneath Datasets, choose the SageMaker Canvas dataset that was simply created.
- Select Edit Dataset.
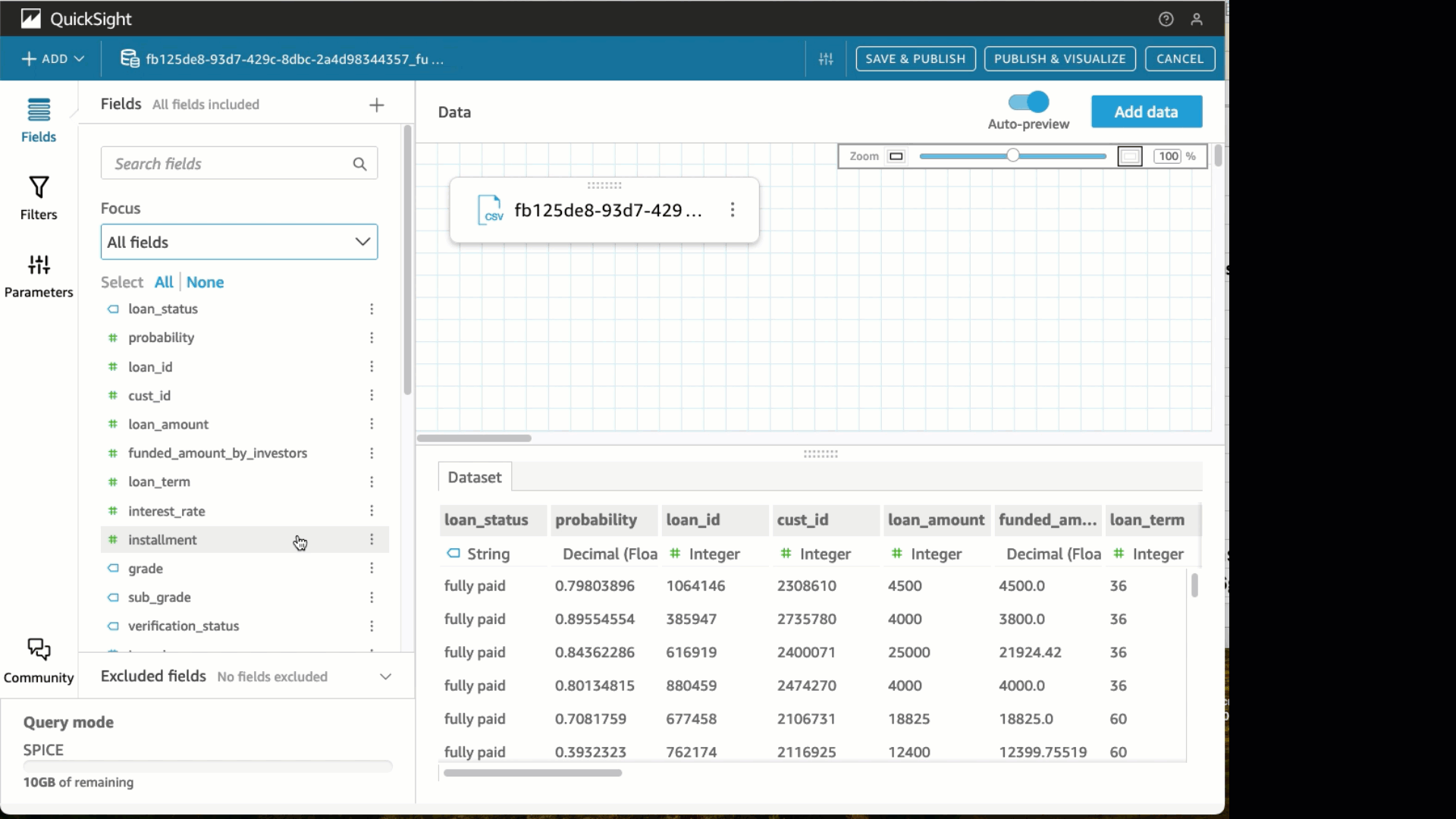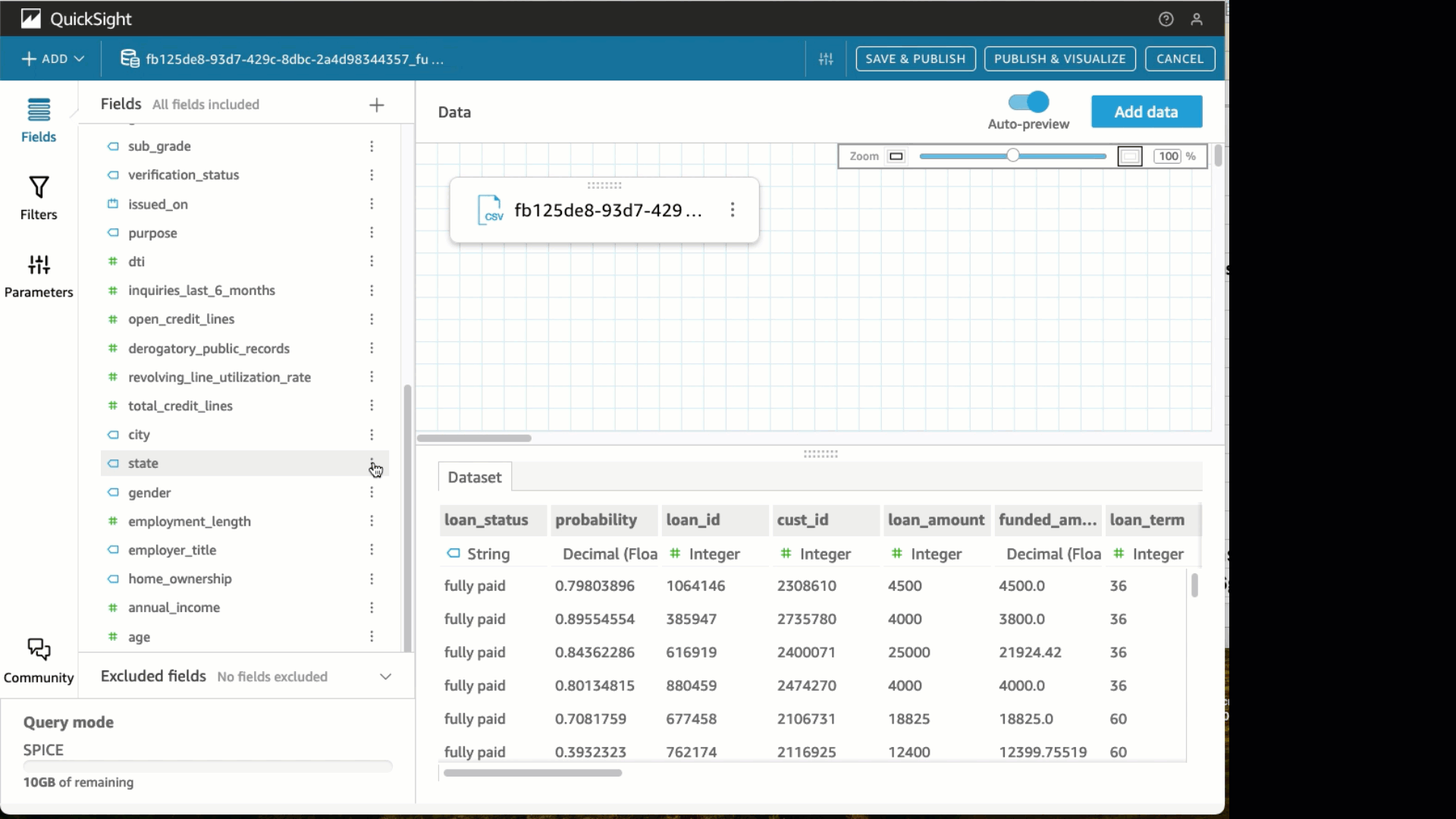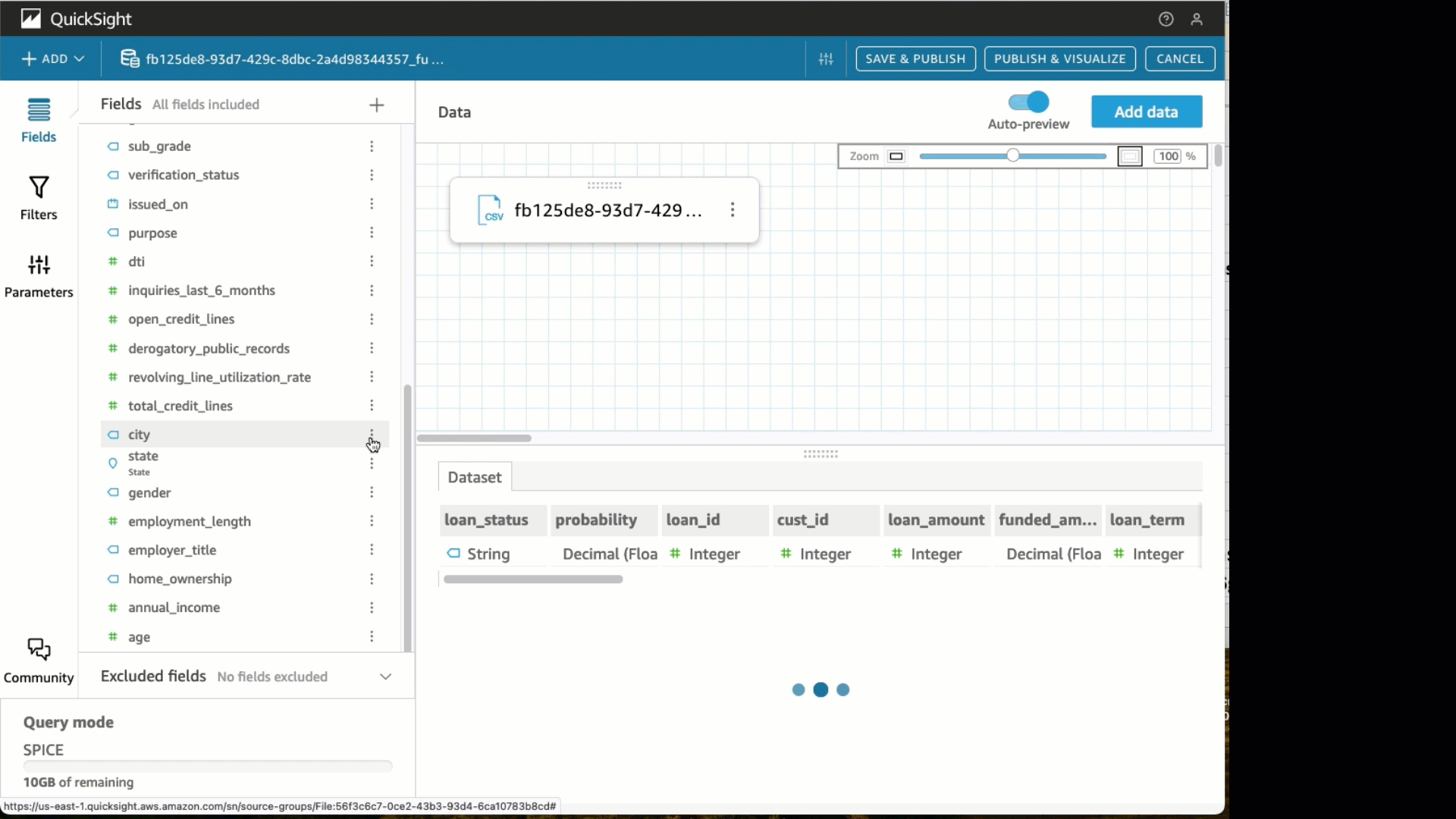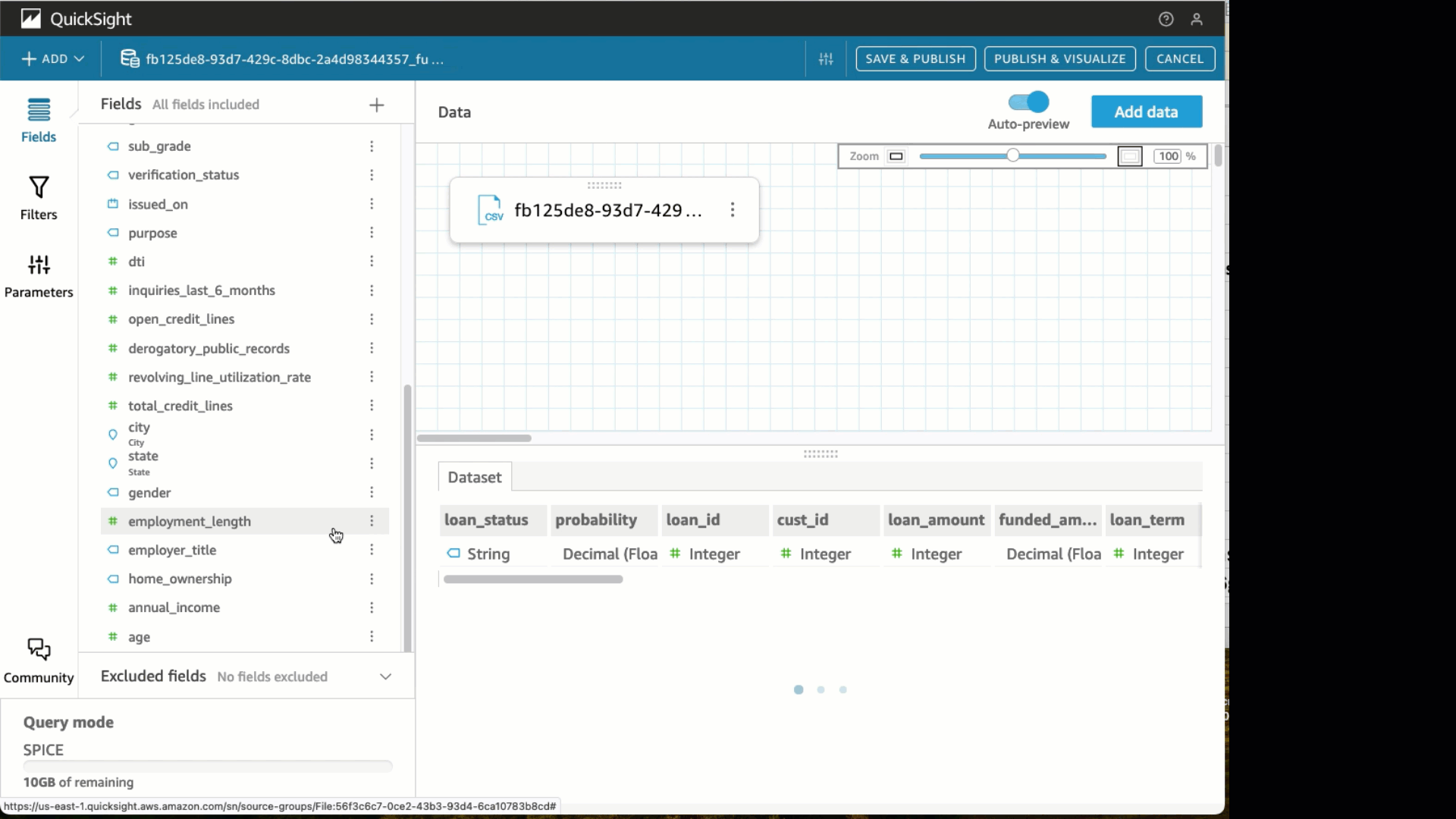
- Beneath the State discipline, change the information sort to State.
- Select Create with Interactive sheet chosen.
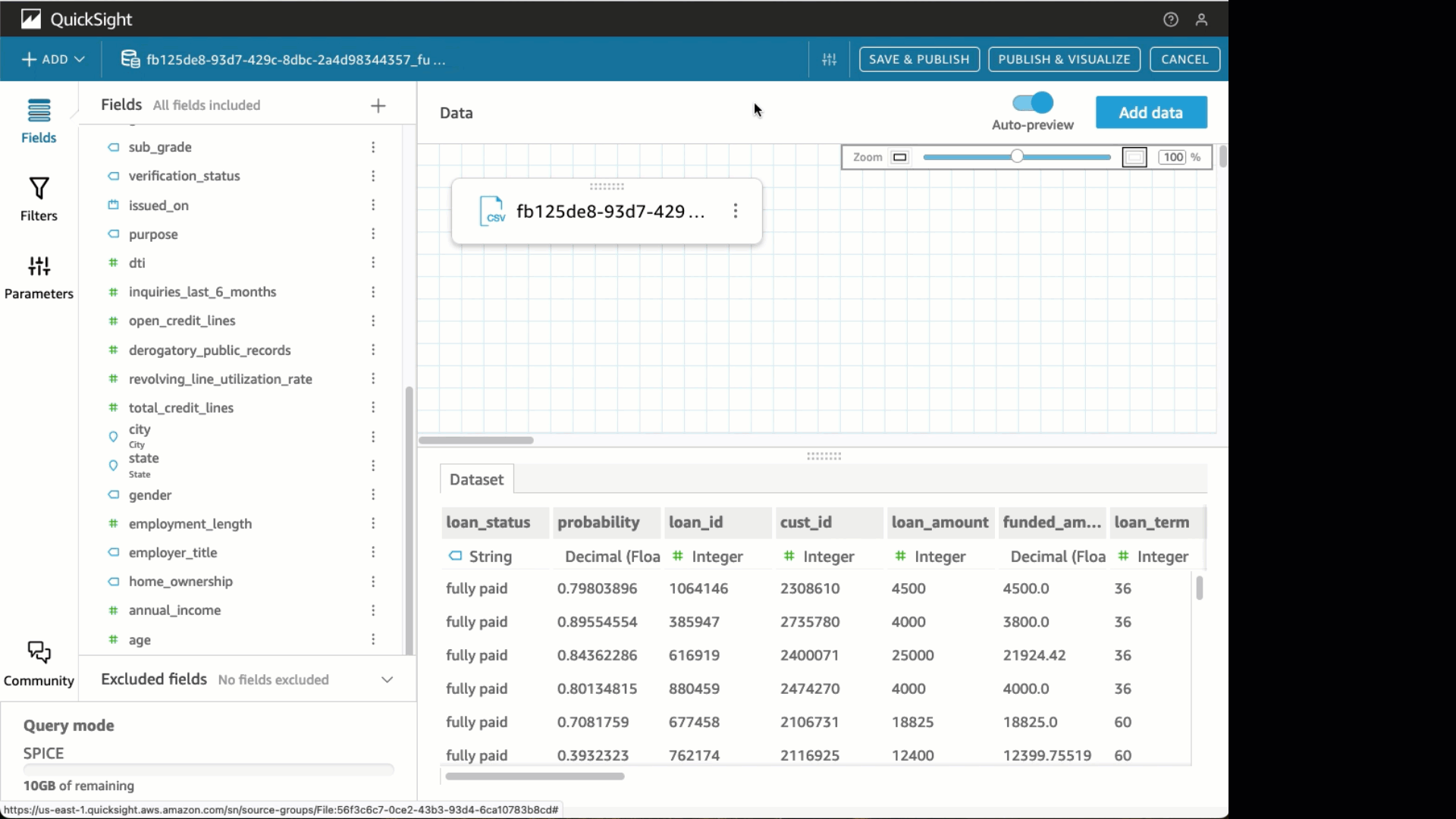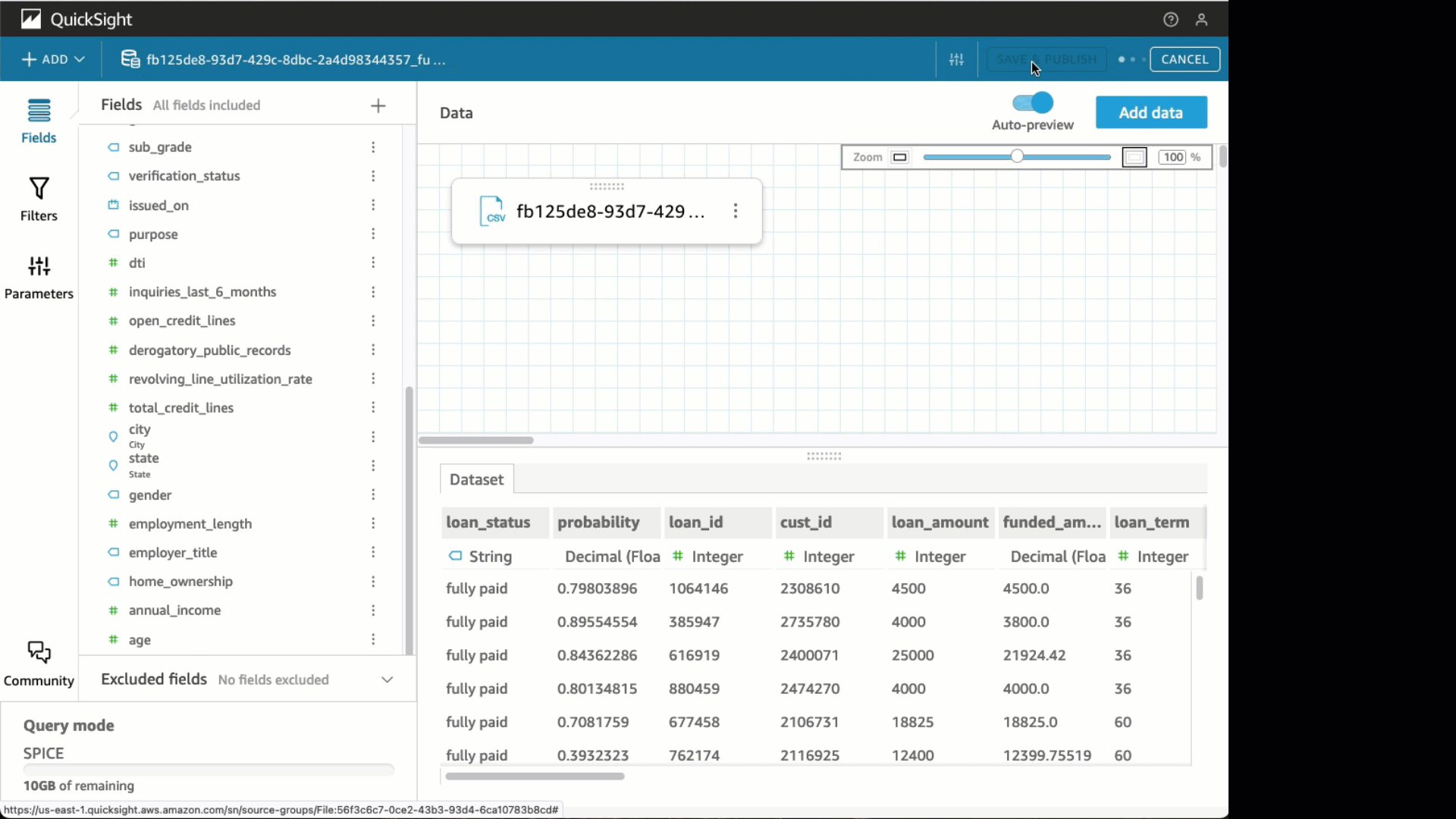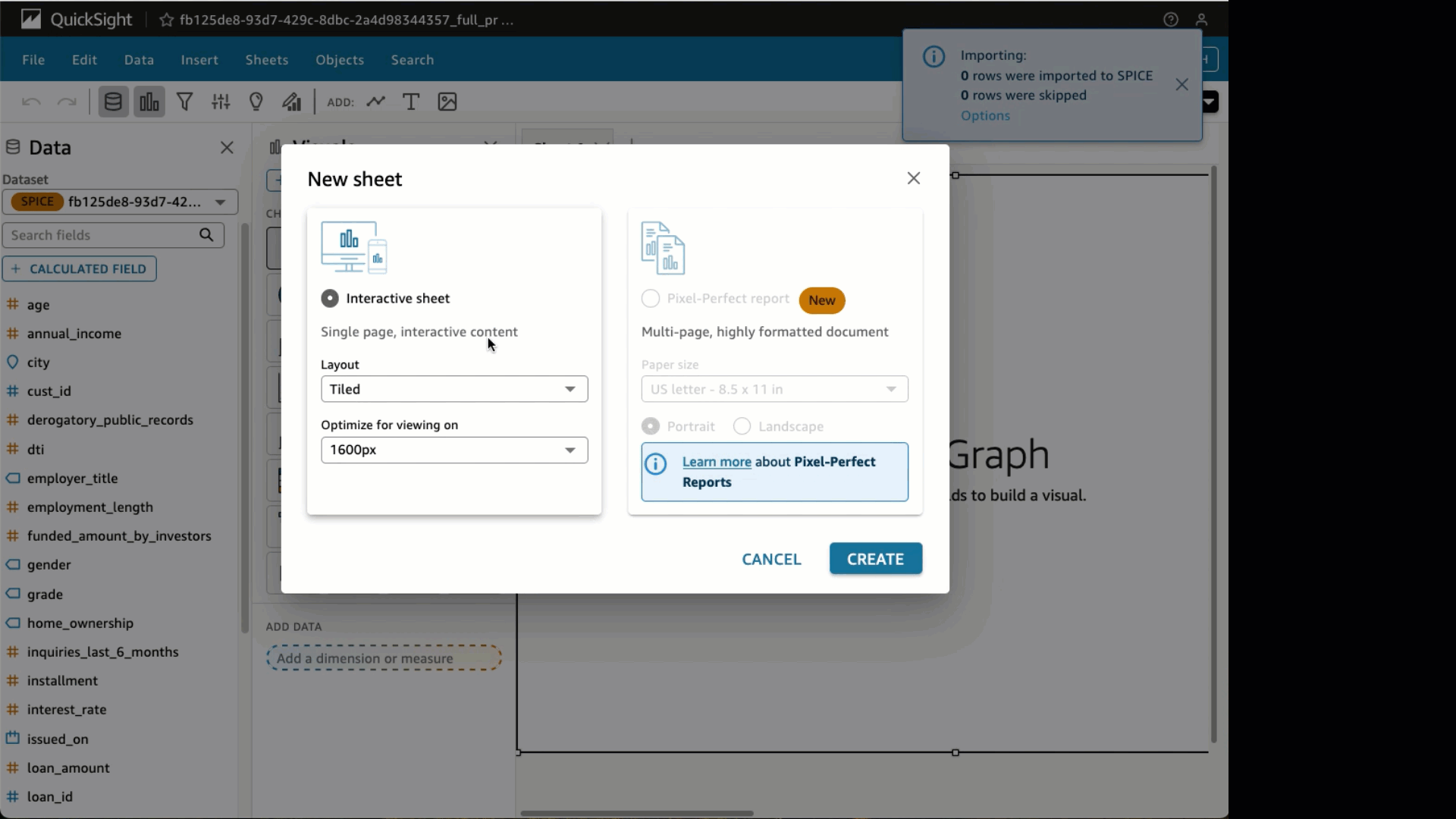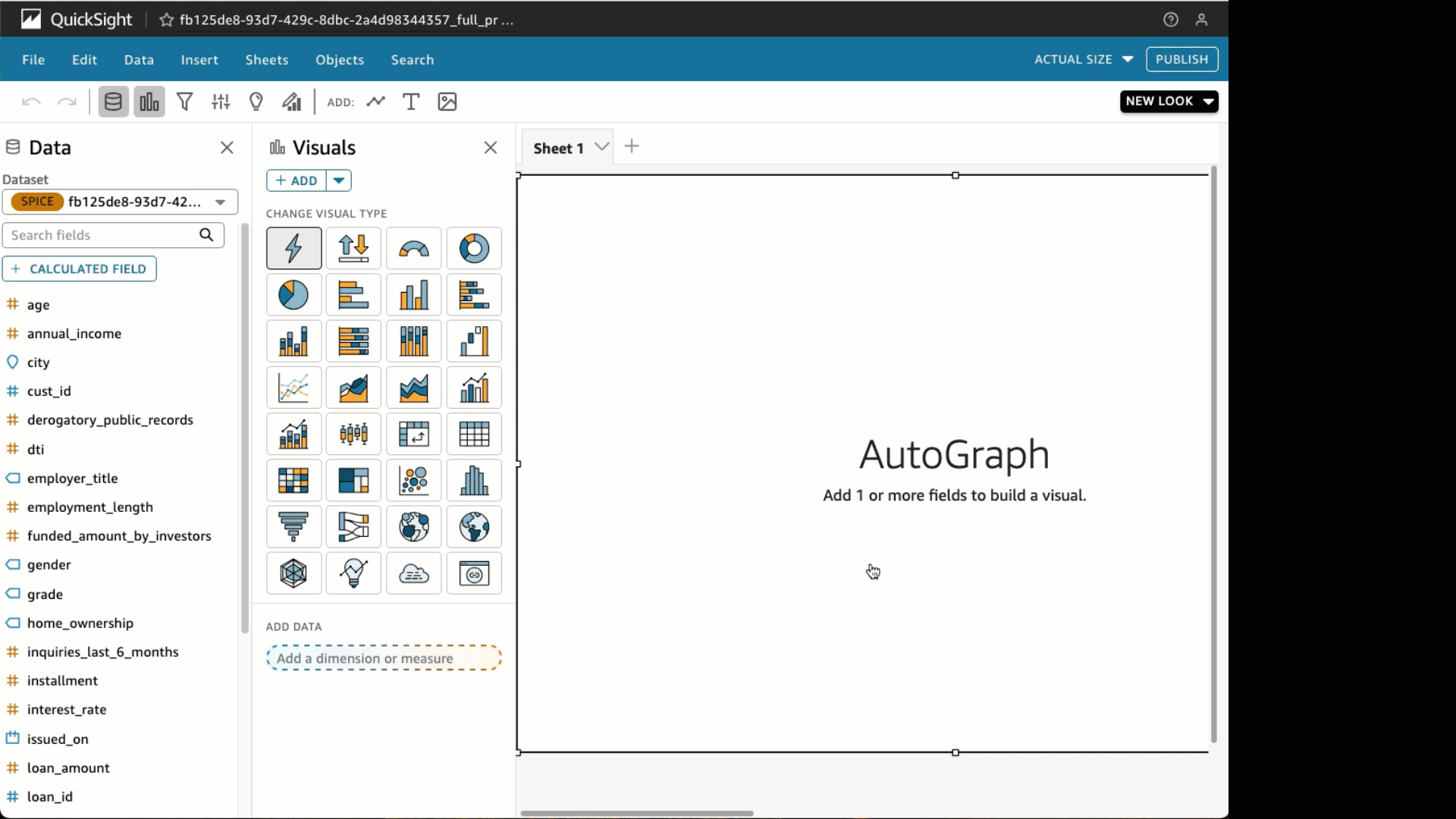
- Beneath visible varieties, select the Stuffed map
- Choose the State and Likelihood
- Beneath Area wells, select Likelihood and alter the Combination to Common and Present as to %.
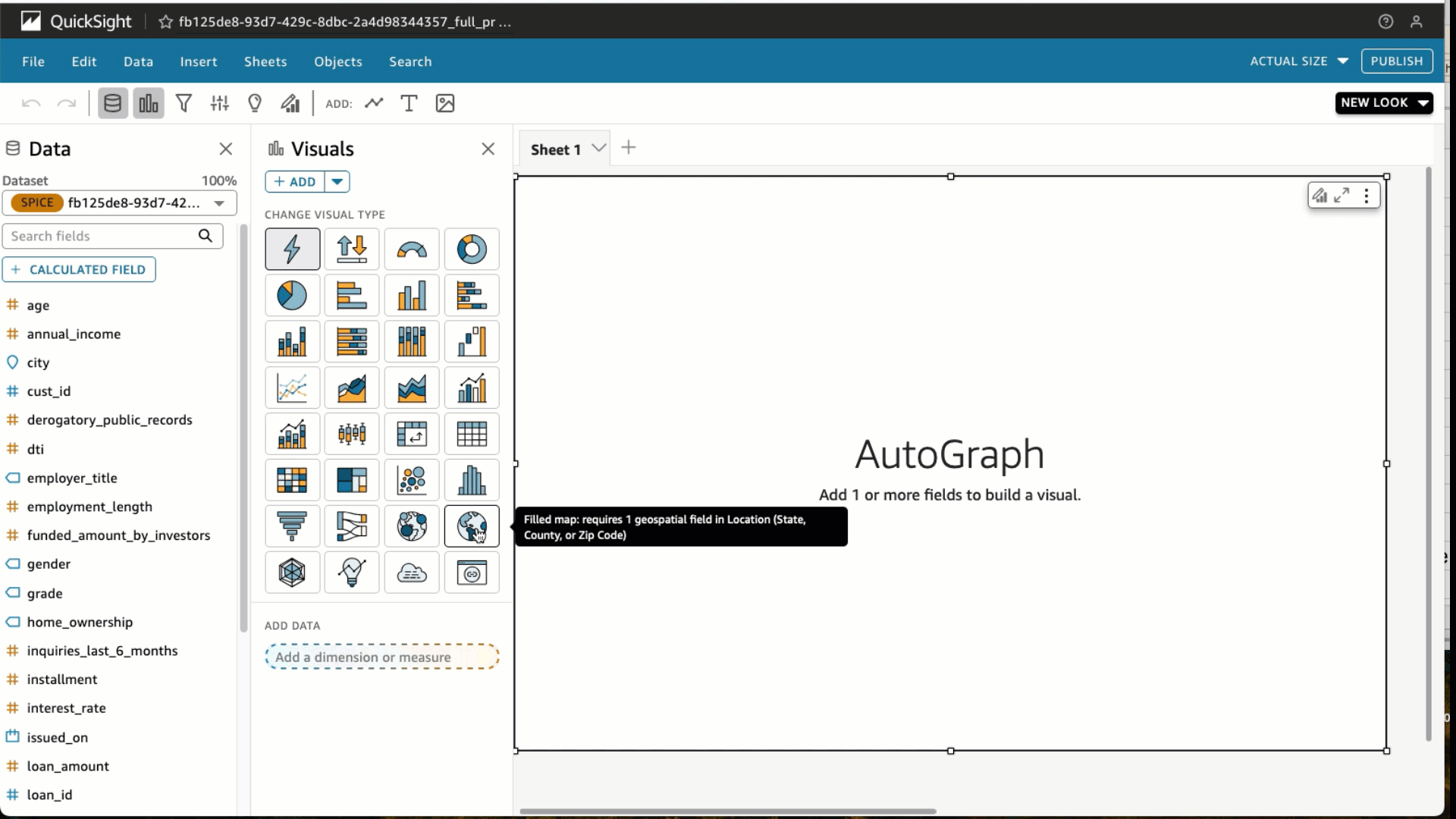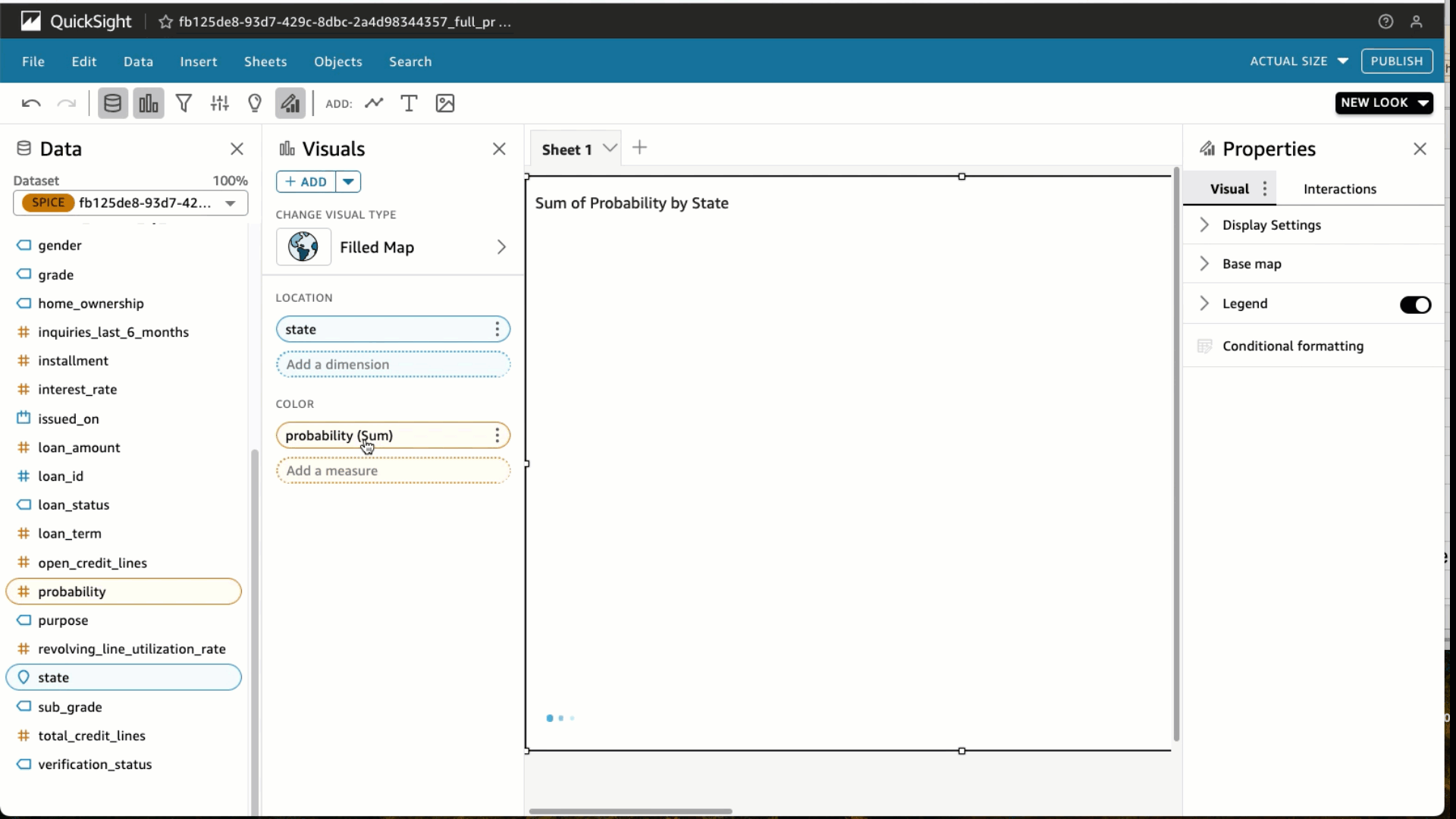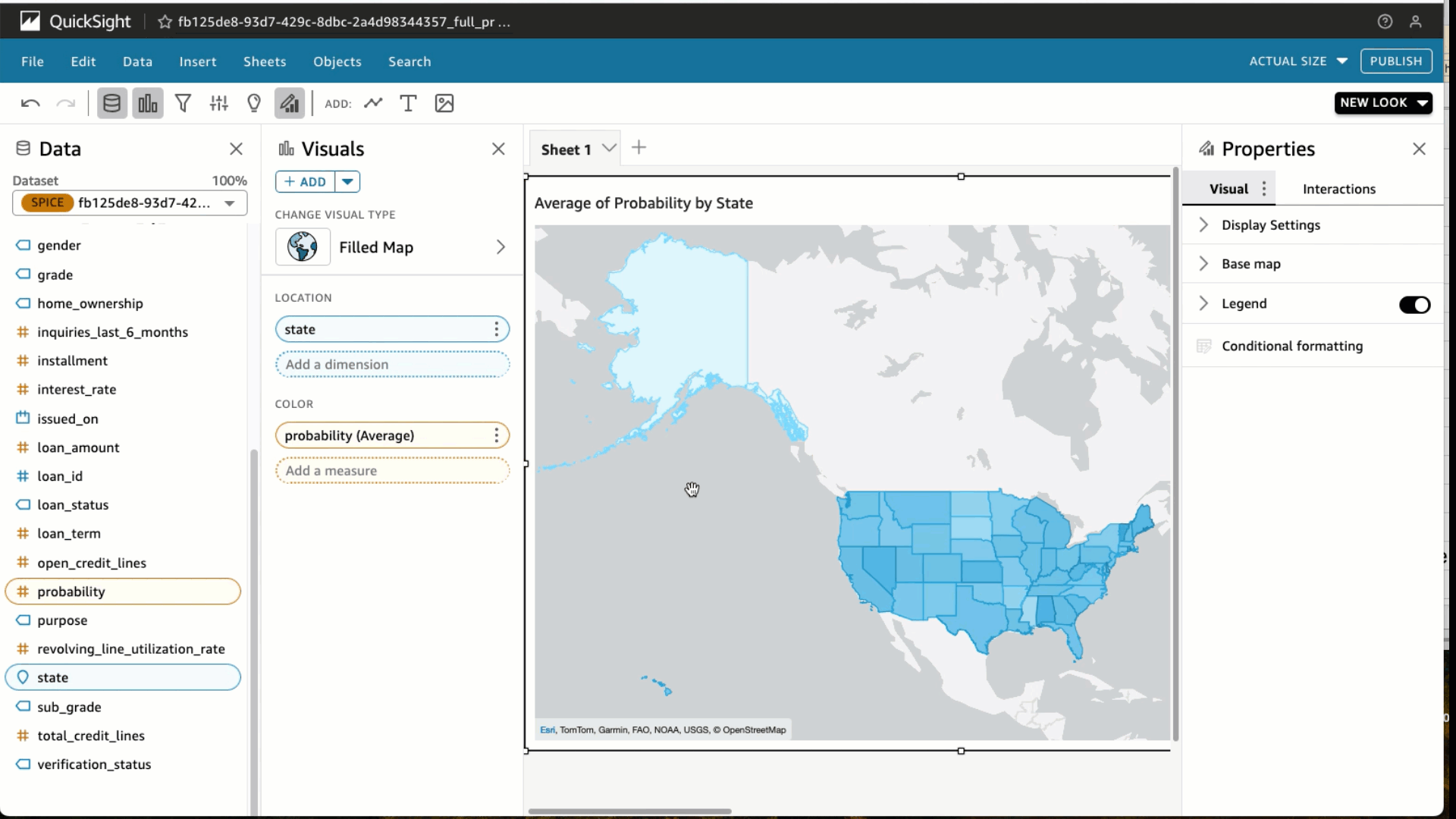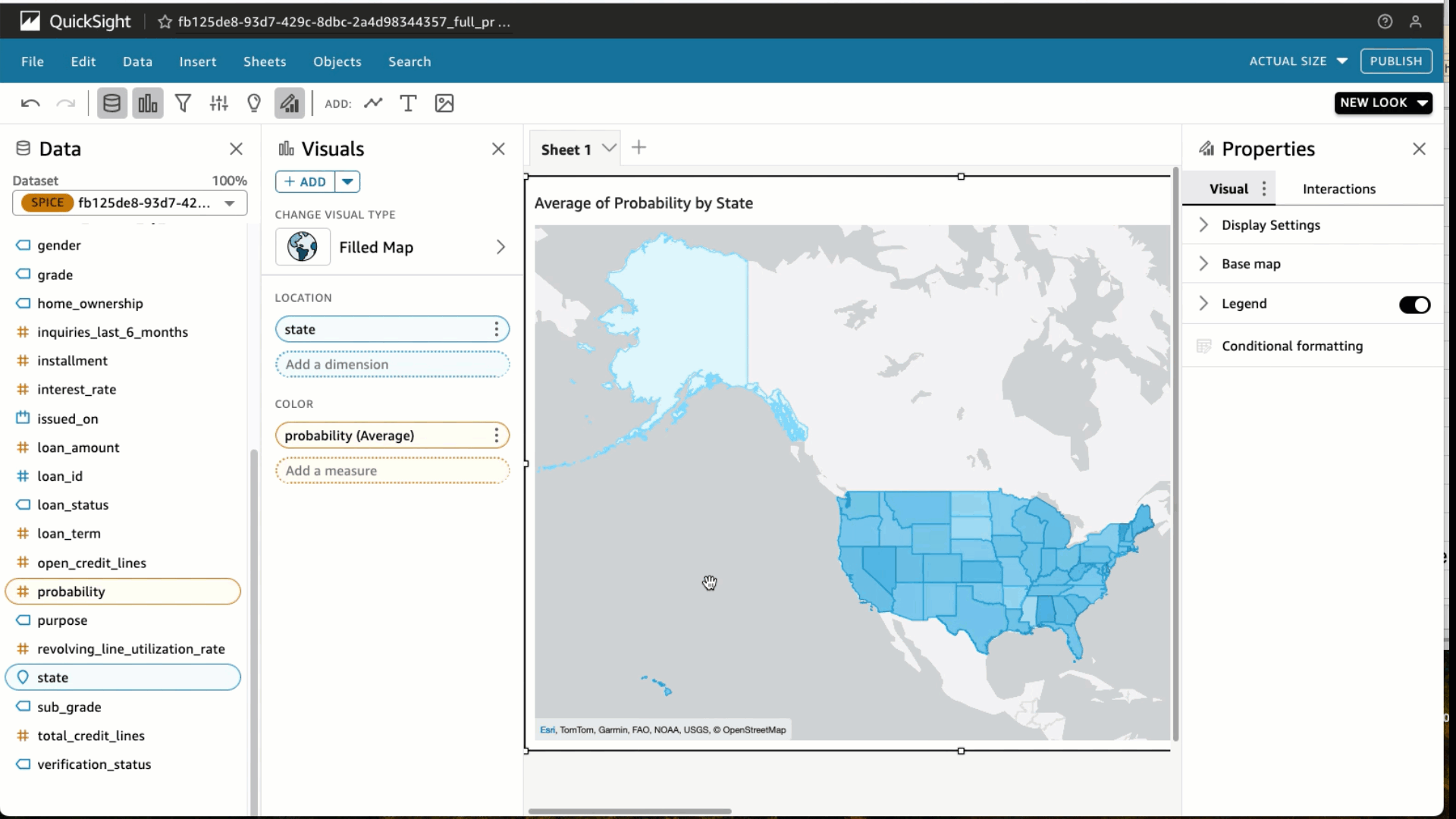
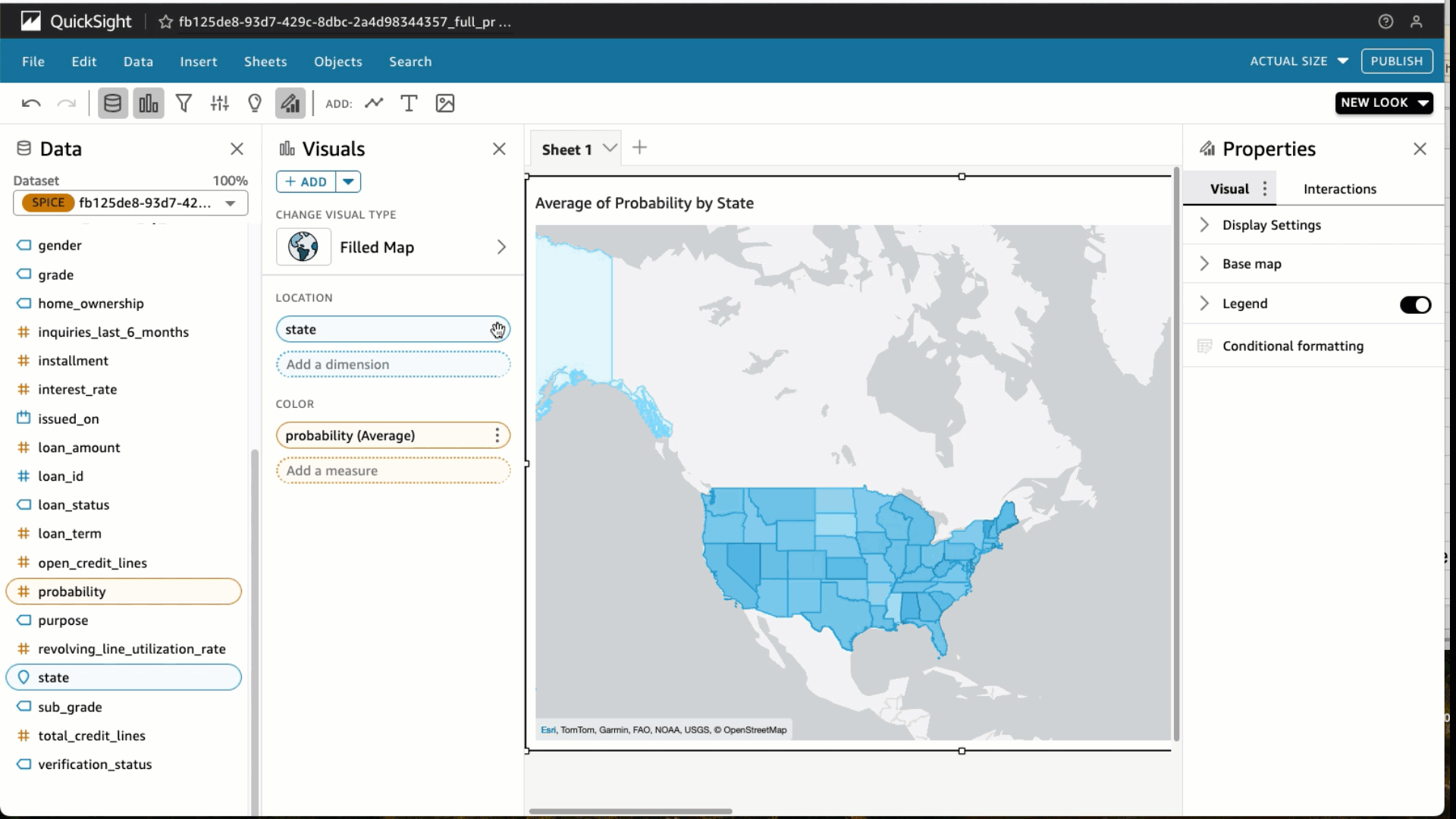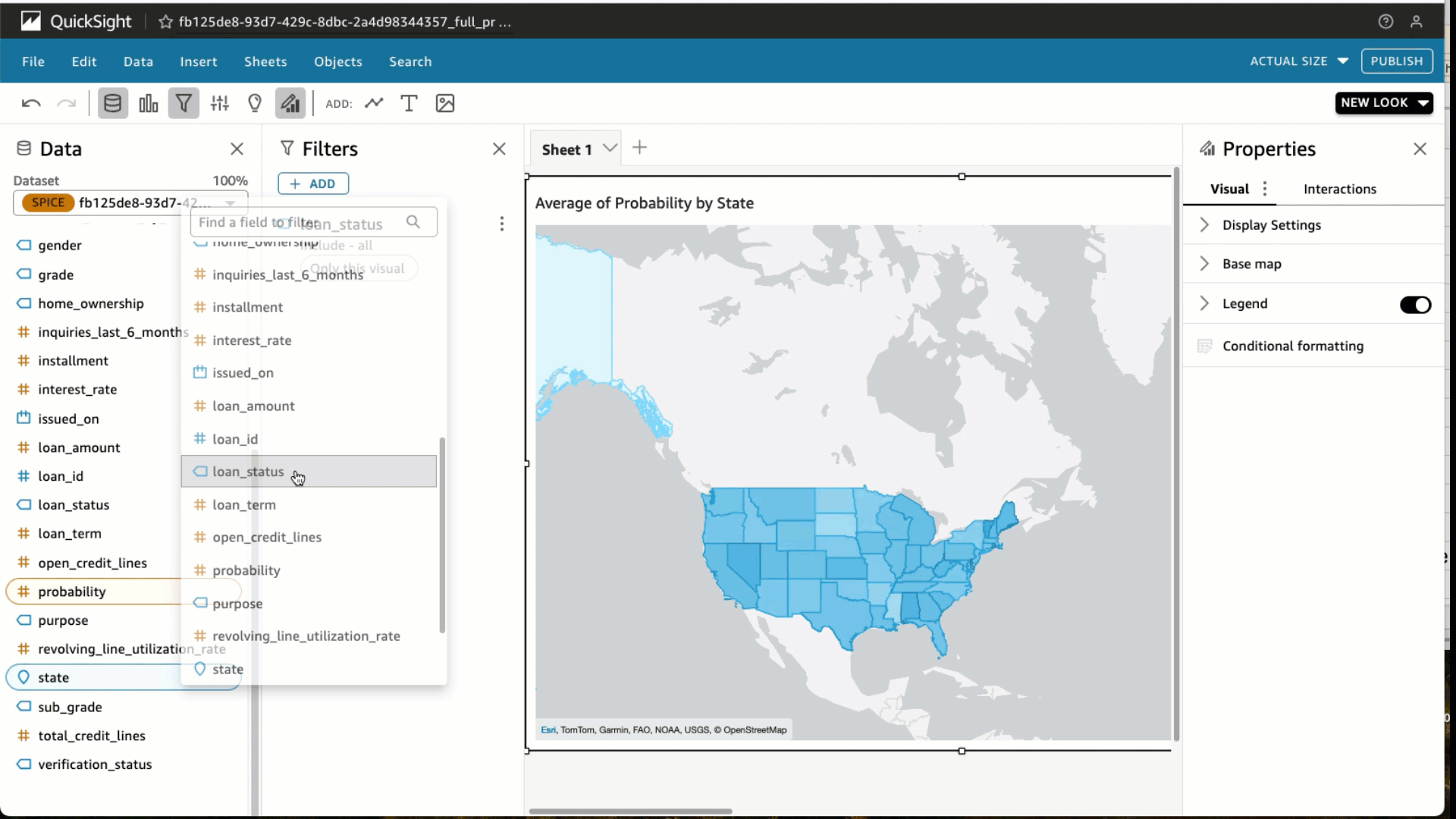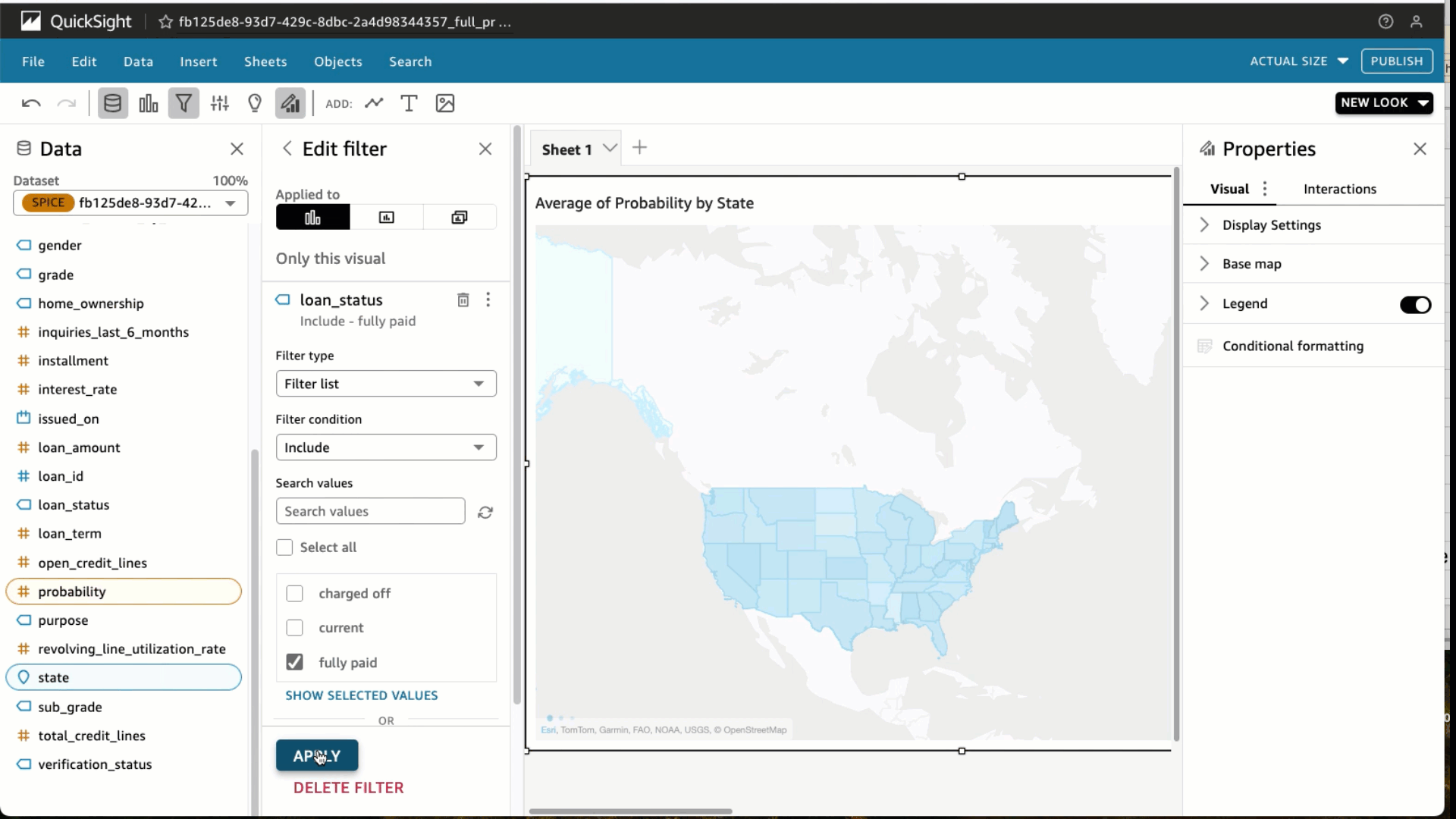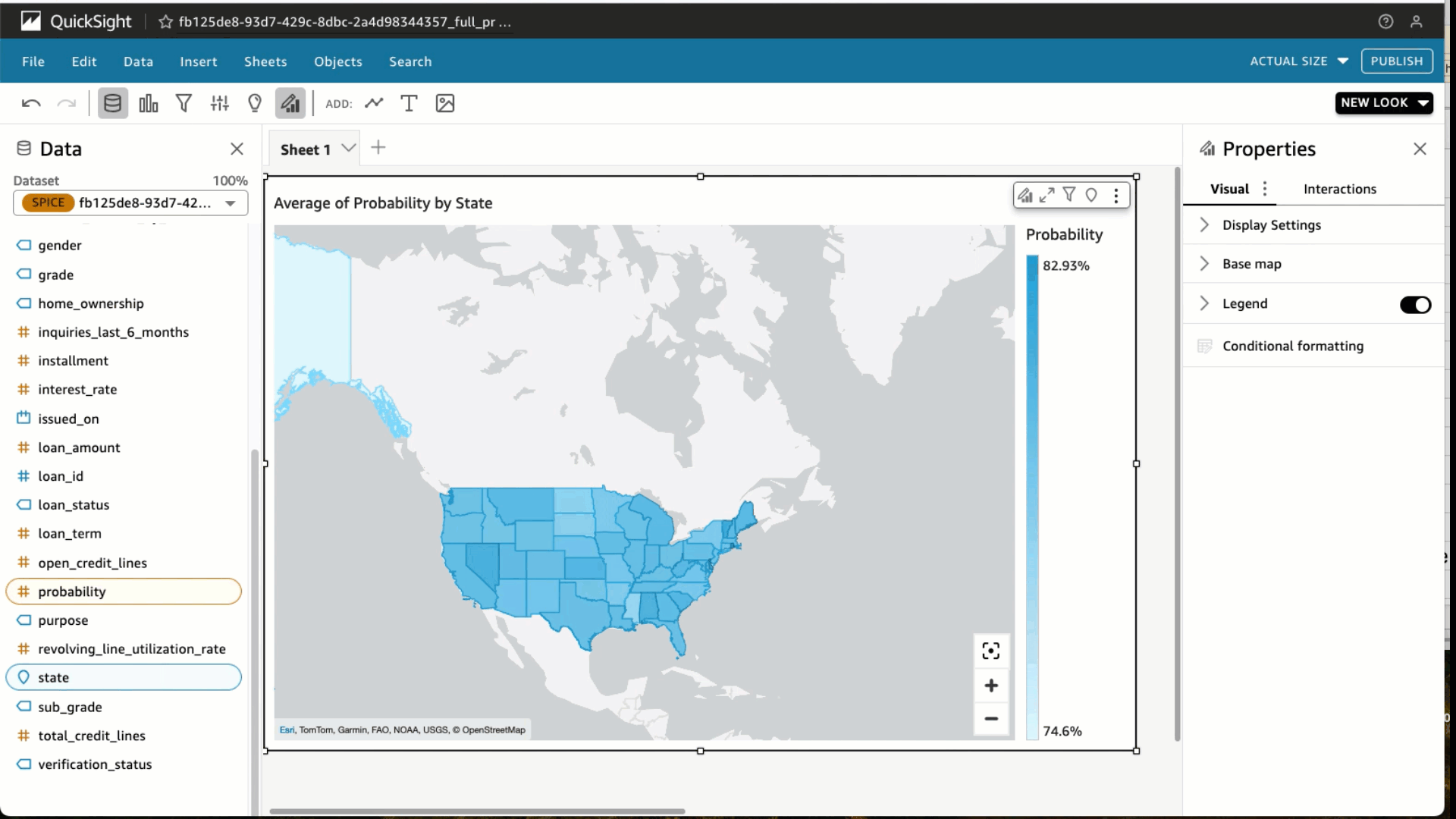
- Select Filter and add a filter for loan_status to incorporate absolutely paid loans solely. Select Apply.
- On the prime proper within the blue banner, select Share and Publish Dashboard.
- We use the identify Common likelihood for absolutely paid mortgage by state, however be at liberty to make use of your personal.
- Select Publish dashboard and also you’re completed. You’ll now be capable to share this dashboard along with your predictions to different analysts and shoppers of this knowledge.
- Go to the QuickSight console by getting into QuickSight in your console providers search bar and select QuickSight.
Clear up
Use the next steps to keep away from any additional value to your account:
- Signal out of SageMaker Canvas
- Within the AWS console, delete the CloudFormation stack you launched earlier within the submit.
Conclusion
We imagine integrating your cloud knowledge warehouse (Amazon Redshift) with SageMaker Canvas opens the door to producing many extra sturdy ML options for your enterprise at sooner and while not having to maneuver knowledge and with no ML expertise.
You now have enterprise analysts producing worthwhile enterprise insights, whereas letting knowledge scientists and ML engineers assist refine, tune, and prolong fashions as wanted. SageMaker Canvas integration with Amazon Redshift offers a unified atmosphere for constructing and deploying machine studying fashions, permitting you to concentrate on creating worth along with your knowledge moderately than specializing in the technical particulars of constructing knowledge pipelines or ML algorithms.
Extra studying:
- SageMaker Canvas Workshop
- re:Invent 2022 – SageMaker Canvas
- Fingers-On Course for Enterprise Analysts – Sensible Resolution Making utilizing No-Code ML on AWS
Concerning the Authors
 Suresh Patnam is Principal Gross sales Specialist AI/ML and Generative AI at AWS. He’s enthusiastic about serving to companies of all sizes rework into fast-moving digital organizations specializing in knowledge, AI/ML, and generative AI.
Suresh Patnam is Principal Gross sales Specialist AI/ML and Generative AI at AWS. He’s enthusiastic about serving to companies of all sizes rework into fast-moving digital organizations specializing in knowledge, AI/ML, and generative AI.
 Sohaib Katariwala is a Sr. Specialist Options Architect at AWS targeted on Amazon OpenSearch Service. His pursuits are in all issues knowledge and analytics. Extra particularly he loves to assist clients use AI of their knowledge technique to unravel modern-day challenges.
Sohaib Katariwala is a Sr. Specialist Options Architect at AWS targeted on Amazon OpenSearch Service. His pursuits are in all issues knowledge and analytics. Extra particularly he loves to assist clients use AI of their knowledge technique to unravel modern-day challenges.
 Michael Hamilton is an Analytics & AI Specialist Options Architect at AWS. He enjoys all issues knowledge associated and serving to clients answer for his or her complicated use circumstances.
Michael Hamilton is an Analytics & AI Specialist Options Architect at AWS. He enjoys all issues knowledge associated and serving to clients answer for his or her complicated use circumstances.
 Nabil Ezzarhouni is an AI/ML and Generative AI Options Architect at AWS. He’s based mostly in Austin, TX and enthusiastic about Cloud, AI/ML applied sciences, and Product Administration. When he isn’t working, he spends time along with his household, on the lookout for one of the best taco in Texas. As a result of…… why not?
Nabil Ezzarhouni is an AI/ML and Generative AI Options Architect at AWS. He’s based mostly in Austin, TX and enthusiastic about Cloud, AI/ML applied sciences, and Product Administration. When he isn’t working, he spends time along with his household, on the lookout for one of the best taco in Texas. As a result of…… why not?



{kind=link}