
Amazon Bedrock gives mannequin customization capabilities for purchasers to tailor variations of basis fashions (FMs) to their particular wants by means of options resembling fine-tuning and distillation. Right now, we’re saying the launch of on-demand deployment for custom-made fashions able to be deployed on Amazon Bedrock.
On-demand deployment for custom-made fashions supplies a further deployment choice that scales together with your utilization patterns. This strategy permits for invoking custom-made fashions solely when wanted, with requests processed in actual time with out requiring pre-provisioned compute sources.
The on-demand deployment choice features a token-based pricing mannequin that prices primarily based on the variety of tokens processed throughout inference. This pay-as-you-go strategy enhances the prevailing Provisioned Throughput choice, giving customers flexibility to decide on the deployment technique that finest aligns with their particular workload necessities and price goals.
On this submit, we stroll by means of the customized mannequin on-demand deployment workflow for Amazon Bedrock and supply step-by-step implementation guides utilizing each the AWS Administration Console and APIs or AWS SDKs. We additionally talk about finest practices and concerns for deploying custom-made Amazon Nova fashions on Amazon Bedrock.
Understanding customized mannequin on-demand deployment workflow
The mannequin customization lifecycle represents the end-to-end journey from conceptualization to deployment. This course of begins with defining your particular use case, getting ready and formatting acceptable information, after which performing mannequin customization by means of options resembling Amazon Bedrock fine-tuning or Amazon Bedrock Mannequin Distillation. Every stage builds upon the earlier one, making a pathway towards deploying production-ready generative AI capabilities that you just tailor to your necessities. The next diagram illustrates this workflow.
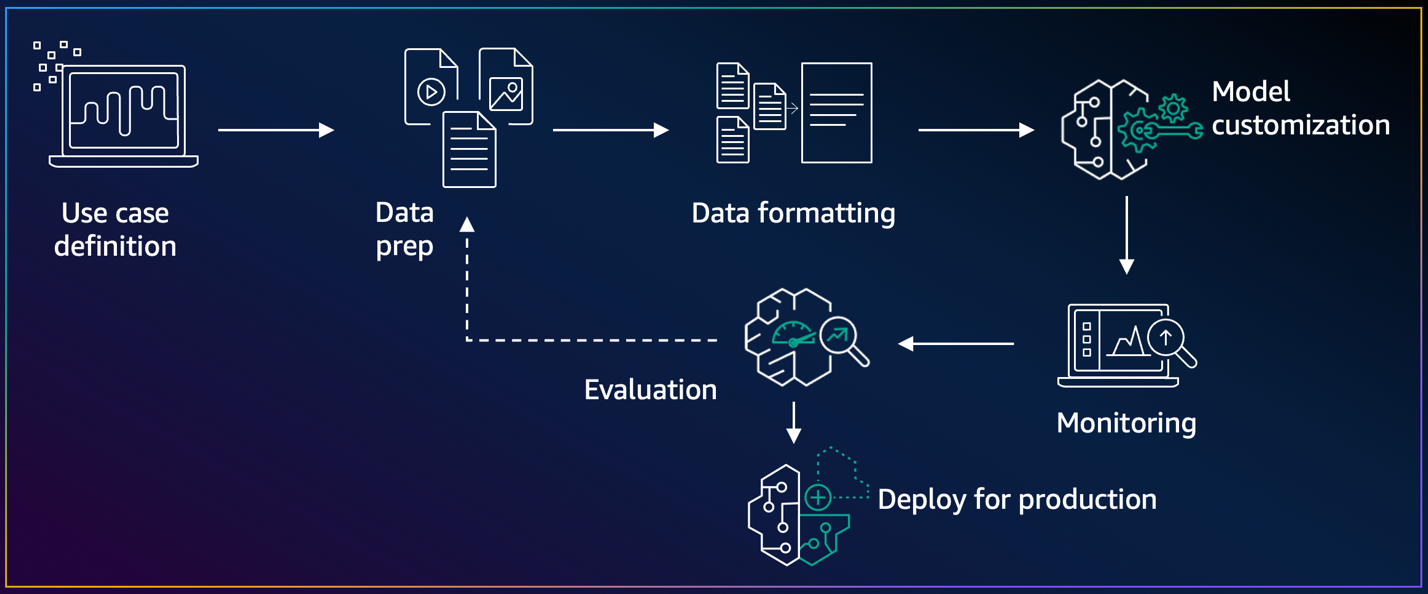
After customizing your mannequin, the analysis and deployment phases decide how the mannequin will likely be made out there for inference. That is the place customized mannequin on-demand deployment turns into useful, providing a deployment choice that aligns with variable workloads and cost-conscious implementations. When utilizing on-demand deployment, you possibly can invoke your custom-made mannequin by means of the AWS console or customary API operations utilizing the mannequin identifier, with compute sources mechanically allotted solely when wanted. The on-demand deployment supplies flexibility whereas sustaining efficiency expectations, so you possibly can seamlessly combine custom-made fashions into your functions with the identical serverless expertise supplied by Amazon Bedrock—all compute sources are mechanically managed for you, primarily based in your precise utilization. As a result of the workflow helps iterative enhancements, you possibly can refine your fashions primarily based on analysis outcomes and evolving enterprise wants.
Stipulations
This submit assumes you’ve gotten a custom-made Amazon Nova mannequin earlier than deploying it utilizing on-demand deployment. On-demand deployment requires newly custom-made Amazon Nova fashions after this launch. Beforehand custom-made fashions aren’t suitable with this deployment choice. For directions on creating or customizing your Nova mannequin by means of fine-tuning or distillation, refer to those sources:
After you’ve efficiently custom-made your Amazon Nova mannequin, you possibly can proceed with deploying it utilizing the on-demand deployment choice as detailed within the following sections.
Implementation information for on-demand deployment
There are two foremost approaches to implementing on-demand deployment in your custom-made Amazon Nova fashions on Amazon Bedrock: utilizing the Amazon Bedrock console or utilizing the API or SDK. First, we discover the way to deploy your mannequin by means of the Amazon Bedrock console, which supplies a user-friendly interface for establishing and managing your deployments.
Step-by-step implementation utilizing the Amazon Bedrock console
To implement on-demand deployment in your custom-made Amazon Nova fashions on Amazon Bedrock utilizing the console, observe these steps:
- On the Amazon Bedrock console, choose your custom-made mannequin (fine-tuning or mannequin distillation) to be deployed. Select Arrange inference and choose Deploy for on-demand, as proven within the following screenshot.
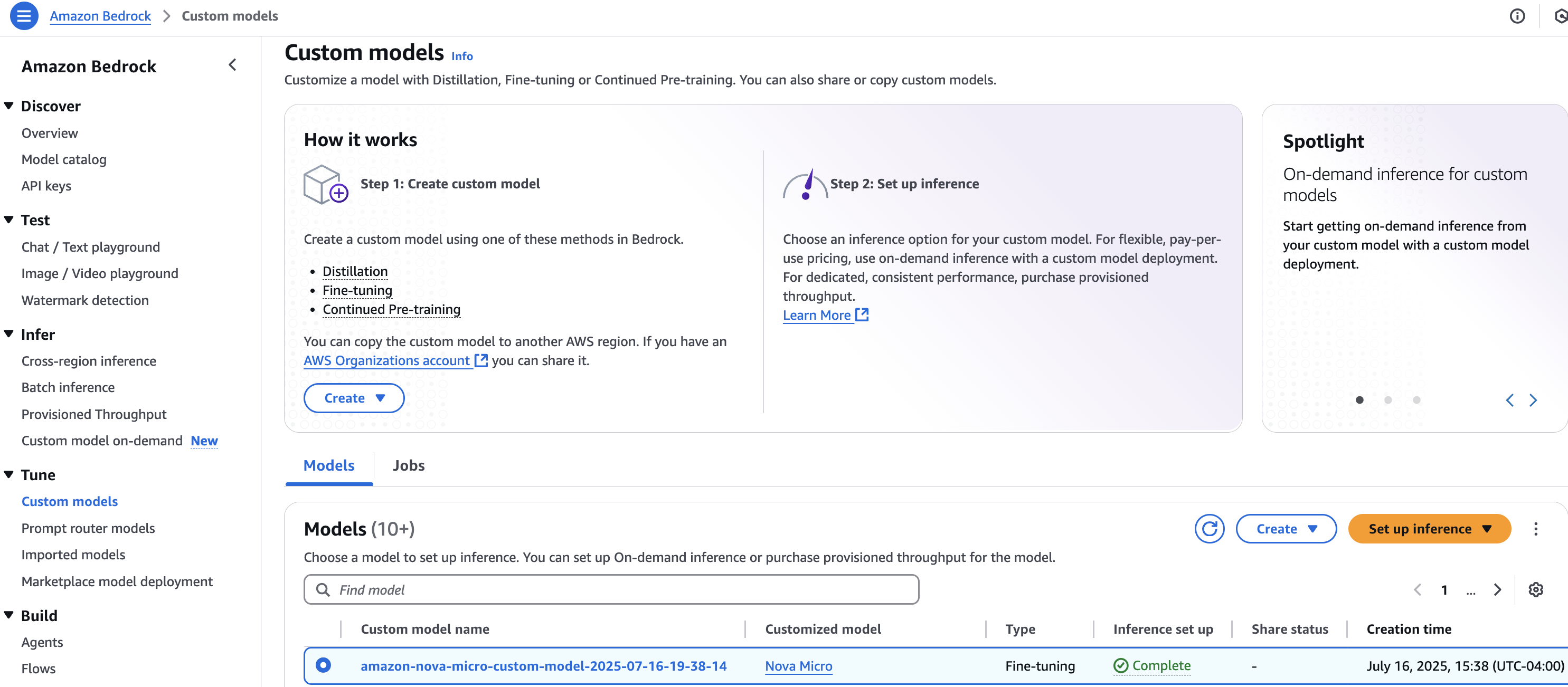
- Underneath Deployment particulars, enter a Identify and a Description. You’ve gotten the choice so as to add Tags, as proven within the following screenshot. Select Create to begin on-demand deployment of custom-made mannequin.
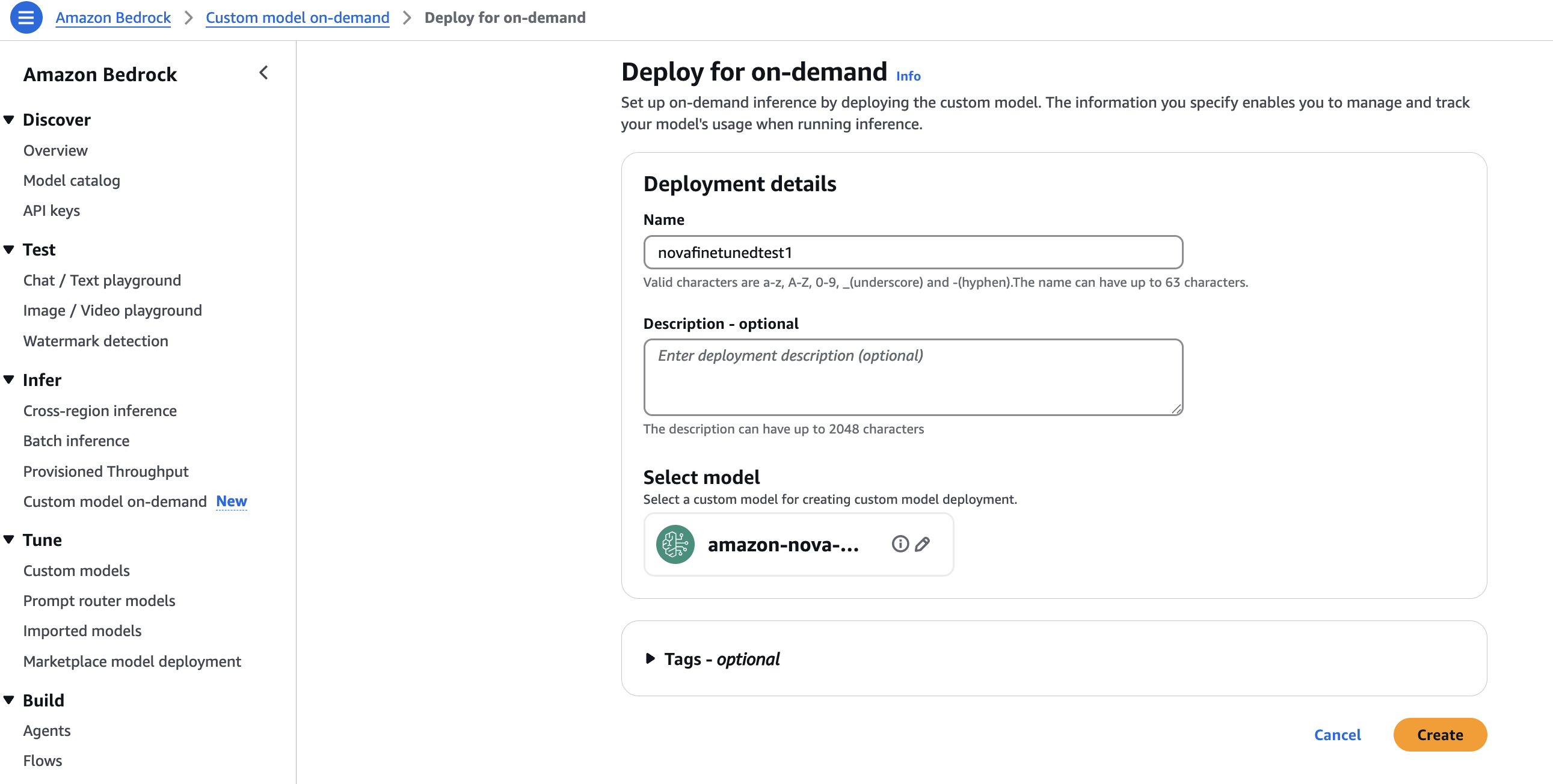
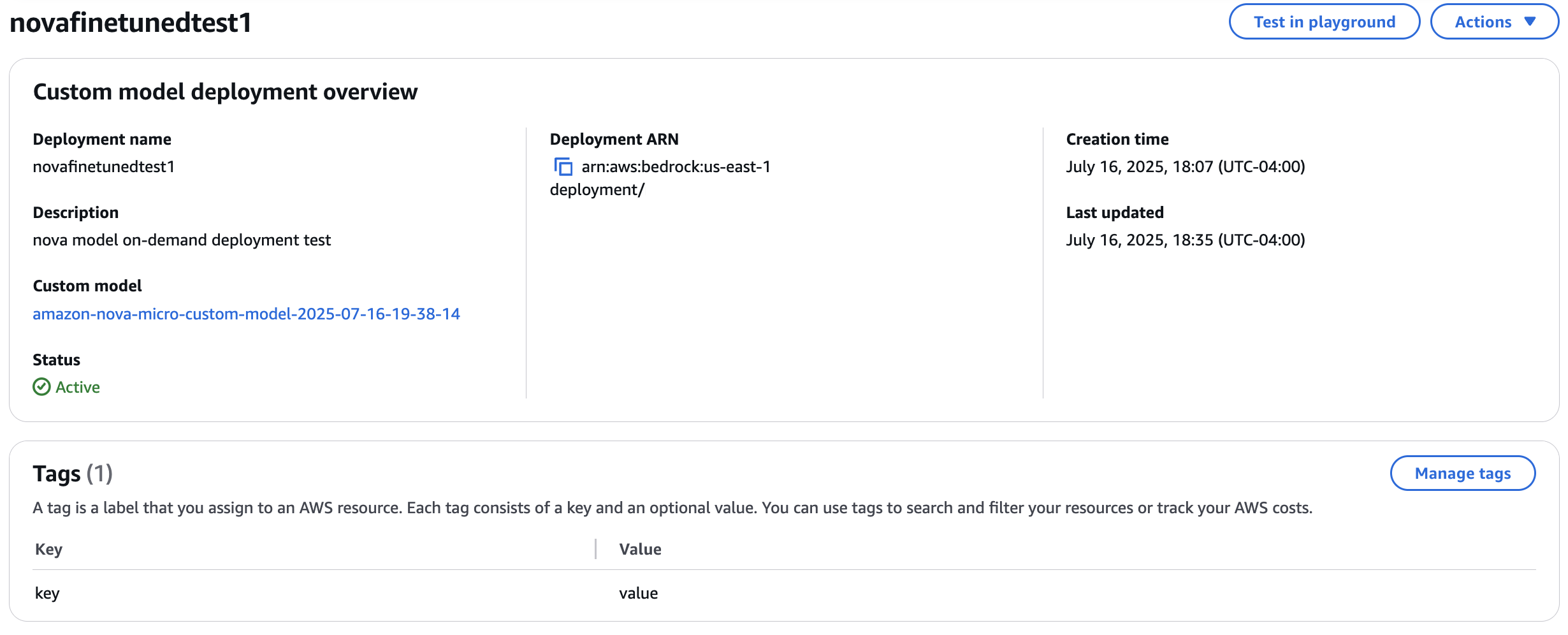
Underneath Customized mannequin deployments, the standing of your deployment ought to be InProgress, Lively, or Failed, as proven within the following screenshot.
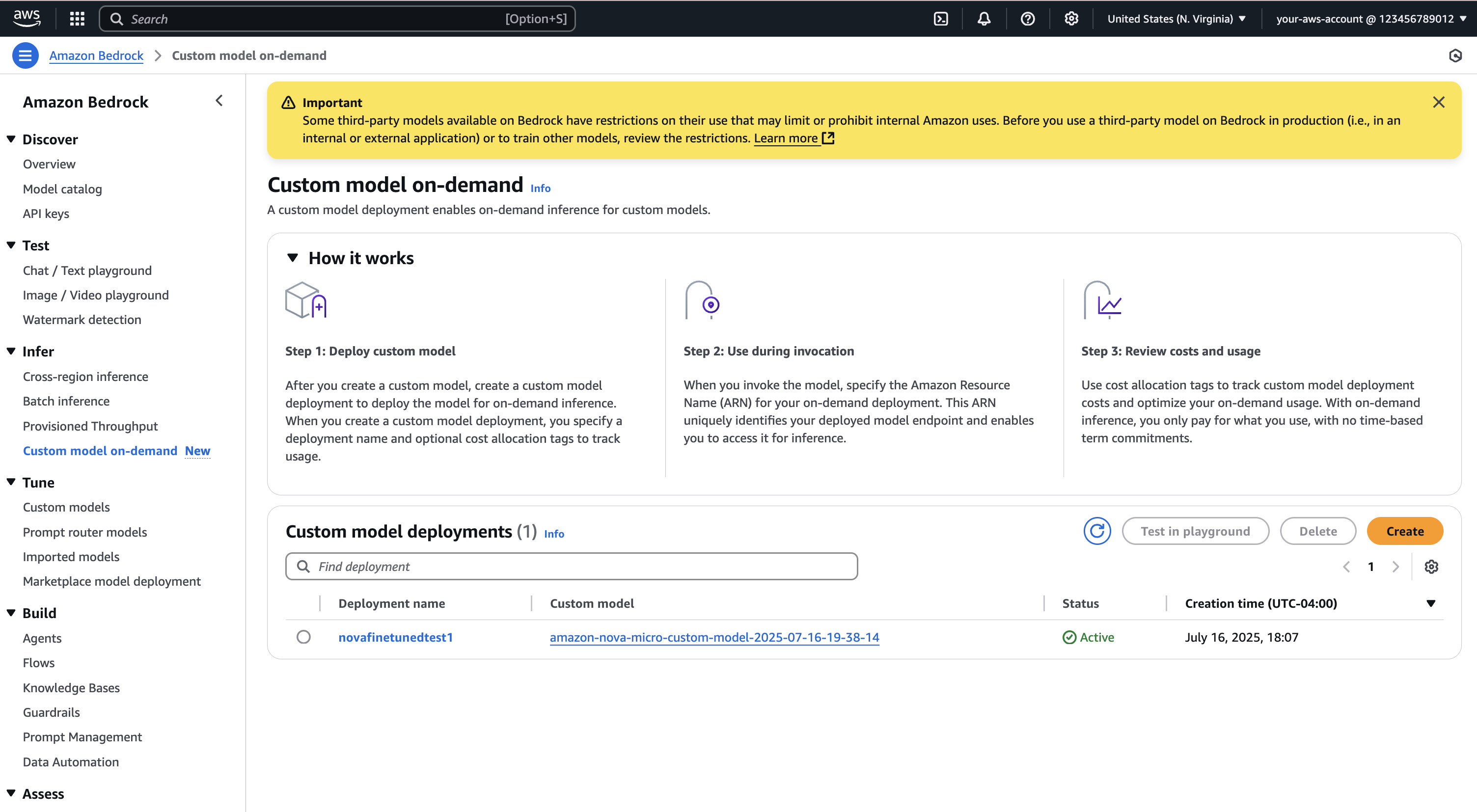
You may choose a deployment to search out Deployment ARN, Creation time, Final up to date, and Standing for the chosen customized mannequin.
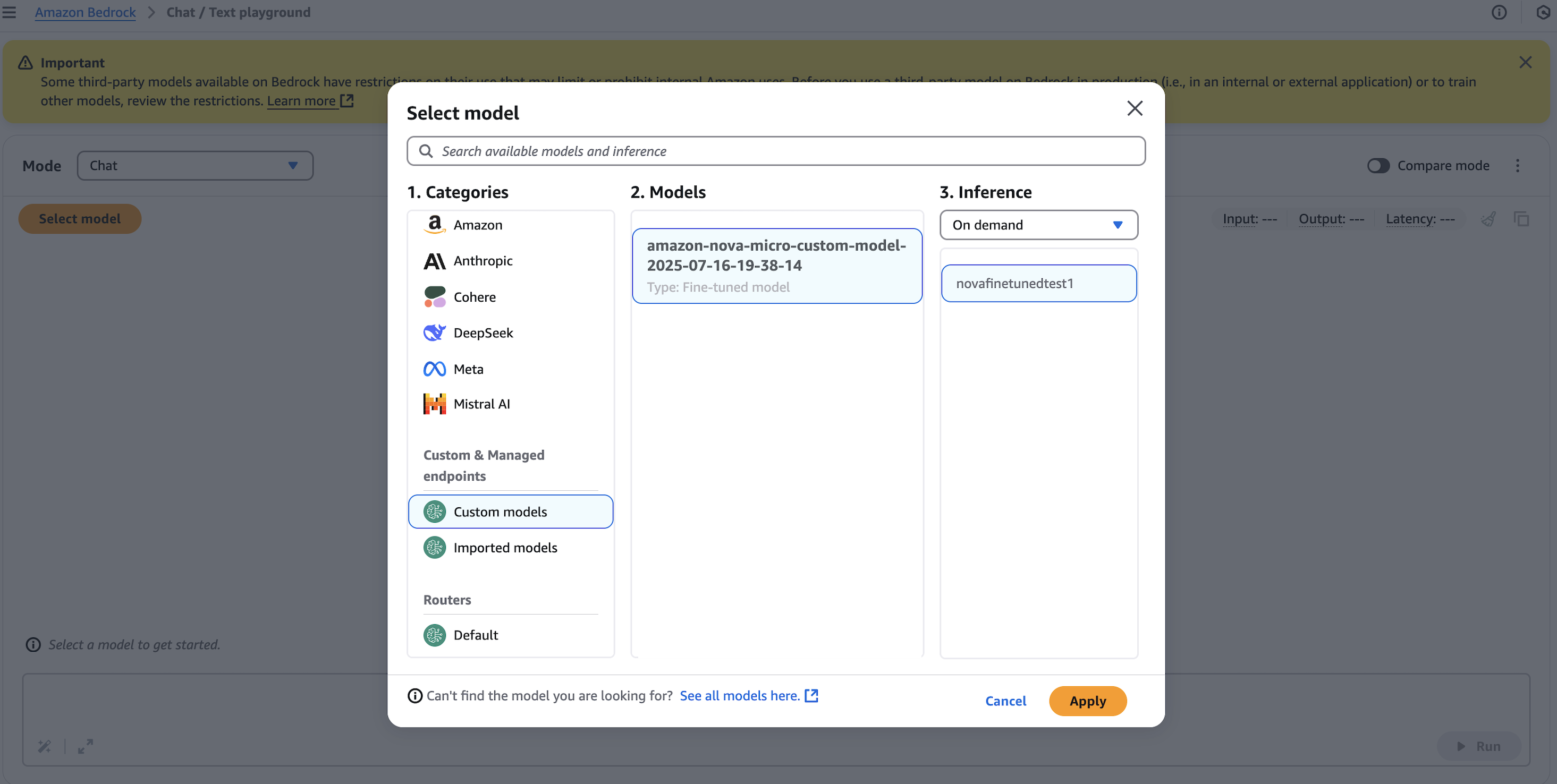
The customized mannequin is deployed and prepared utilizing on-demand deployment. Attempt it out within the check playground or go to Chat/Textual content playground, select Customized fashions beneath Classes. Choose your mannequin, select On demand beneath Inference, and choose by the deployment title, as proven within the following screenshot.
Step-by-step implementation utilizing API or SDK
After you’ve gotten skilled the mannequin efficiently, you possibly can deploy it to guage the response high quality and latency or to make use of the mannequin as a manufacturing mannequin in your use case. You employ CreateCustomModelDeployment API to create mannequin deployment for the skilled mannequin. The next steps present the way to use the APIs for deploying and deleting the customized mannequin deployment for on-demand inference.
After you’ve efficiently created a mannequin deployment, you possibly can test the standing of the deployment by utilizing GetCustomModelDeployment API as follows:
GetCustomModelDeployment helps three states: Creating , Lively , and Failed. When the standing in response is Lively, you must have the ability to use the customized mannequin by means of on-demand deployment with InvokeModel or Converse API, as proven within the following instance:
By following these steps, you possibly can deploy and use your custom-made mannequin by means of Amazon Bedrock API and immediately use your environment friendly and high-performing mannequin tailor-made to your use circumstances by means of on-demand deployment.
Greatest practices and concerns
Profitable implementation of on-demand deployment with custom-made fashions is dependent upon understanding a number of operational elements. These concerns—together with latency, Regional availability, quota limitations, deployment choice alternatives, and price administration methods—straight influence your potential to deploy efficient options whereas optimizing useful resource utilization. The next tips provide help to make knowledgeable choices when implementing your inference technique:
- Chilly begin latency – When utilizing on-demand deployment, you would possibly expertise preliminary chilly begin latencies, usually lasting a number of seconds, relying on the mannequin dimension. This happens when the deployment hasn’t acquired current visitors and must reinitialize compute sources.
- Regional availability – At launch, customized mannequin deployment will likely be out there in US East (N. Virginia) for Amazon Nova fashions.
- Quota administration – Every customized mannequin deployment has particular quotas:
- Tokens per minute (TPM)
- Requests per minute (RPM)
- The variety of
Creatingstanding deployment - Complete on-demand deployments in a single account
Every deployment operates independently inside its assigned quota. If a deployment exceeds its TPM or RPM allocation, incoming requests will likely be throttled. You may request quota will increase by submitting a ticket or contacting your AWS account staff.
- Selecting between customized mannequin deployment and Provisioned Throughput – You may arrange inference on a customized mannequin by both making a customized mannequin deployment (for on-demand utilization) or buying Provisioned Throughput. The selection is dependent upon the supported Areas and fashions for every inference choice, throughput requirement, and price concerns. These two choices function independently and can be utilized concurrently for a similar customized mannequin.
- Price administration – On-demand deployment makes use of a pay-as-you-go pricing mannequin primarily based on the variety of tokens processed throughout inference. You need to use price allocation tags in your on-demand deployments to trace and handle inference prices, permitting higher finances monitoring and price optimization by means of AWS Price Explorer.
Cleanup
In the event you’ve been testing the on-demand deployment characteristic and don’t plan to proceed utilizing it, it’s essential to scrub up your sources to keep away from incurring pointless prices. Right here’s the way to delete utilizing the Amazon Bedrock Console:
- Navigate to your customized mannequin deployment
- Choose the deployment you need to take away
- Delete the deployment
Right here’s the way to delete utilizing the API or SDK:
To delete a customized mannequin deployment, you should use DeleteCustomModelDeployment API. The next instance demonstrates the way to delete your customized mannequin deployment:
Conclusion
The introduction of on-demand deployment for custom-made fashions on Amazon Bedrock represents a big development in making AI mannequin deployment extra accessible, cost-effective, and versatile for companies of all sizes. On-demand deployment gives the next benefits:
- Price optimization – Pay-as-you-go pricing permits you solely pay for the compute sources you truly use
- Operational simplicity – Automated useful resource administration eliminates the necessity for handbook infrastructure provisioning
- Scalability – Seamless dealing with of variable workloads with out upfront capability planning
- Flexibility – Freedom to decide on between on-demand and Provisioned Throughput primarily based in your particular wants
Getting began is simple. Start by finishing your mannequin customization by means of fine-tuning or distillation, then select on-demand deployment utilizing the AWS Administration Console or API. Configure your deployment particulars, validate mannequin efficiency in a check atmosphere, and seamlessly combine into your manufacturing workflows.
Begin exploring on-demand deployment for custom-made fashions on Amazon Bedrock in the present day! Go to the Amazon Bedrock documentation to start your mannequin customization journey and expertise the advantages of versatile, cost-effective AI infrastructure. For hands-on implementation examples, take a look at our GitHub repository which comprises detailed code samples for customizing Amazon Nova fashions and evaluating them utilizing on-demand customized mannequin deployment.
Concerning the Authors
 Yanyan Zhang is a Senior Generative AI Information Scientist at Amazon Internet Companies, the place she has been engaged on cutting-edge AI/ML applied sciences as a Generative AI Specialist, serving to clients use generative AI to attain their desired outcomes. Yanyan graduated from Texas A&M College with a PhD in Electrical Engineering. Exterior of labor, she loves touring, understanding, and exploring new issues.
Yanyan Zhang is a Senior Generative AI Information Scientist at Amazon Internet Companies, the place she has been engaged on cutting-edge AI/ML applied sciences as a Generative AI Specialist, serving to clients use generative AI to attain their desired outcomes. Yanyan graduated from Texas A&M College with a PhD in Electrical Engineering. Exterior of labor, she loves touring, understanding, and exploring new issues.
 Sovik Kumar Nath is an AI/ML and Generative AI senior answer architect with AWS. He has intensive expertise designing end-to-end machine studying and enterprise analytics options in finance, operations, advertising and marketing, healthcare, provide chain administration, and IoT. He has double masters levels from the College of South Florida, College of Fribourg, Switzerland, and a bachelors diploma from the Indian Institute of Expertise, Kharagpur. Exterior of labor, Sovik enjoys touring, taking ferry rides, and watching films.
Sovik Kumar Nath is an AI/ML and Generative AI senior answer architect with AWS. He has intensive expertise designing end-to-end machine studying and enterprise analytics options in finance, operations, advertising and marketing, healthcare, provide chain administration, and IoT. He has double masters levels from the College of South Florida, College of Fribourg, Switzerland, and a bachelors diploma from the Indian Institute of Expertise, Kharagpur. Exterior of labor, Sovik enjoys touring, taking ferry rides, and watching films.
 Ishan Singh is a Sr. Generative AI Information Scientist at Amazon Internet Companies, the place he helps clients construct progressive and accountable generative AI options and merchandise. With a powerful background in AI/ML, Ishan makes a speciality of constructing generative AI options that drive enterprise worth. Exterior of labor, he enjoys taking part in volleyball, exploring native bike trails, and spending time along with his spouse and canine, Beau.
Ishan Singh is a Sr. Generative AI Information Scientist at Amazon Internet Companies, the place he helps clients construct progressive and accountable generative AI options and merchandise. With a powerful background in AI/ML, Ishan makes a speciality of constructing generative AI options that drive enterprise worth. Exterior of labor, he enjoys taking part in volleyball, exploring native bike trails, and spending time along with his spouse and canine, Beau.
 Koushik Mani is an affiliate options architect at AWS. He had labored as a Software program Engineer for 2 years specializing in machine studying and cloud computing use circumstances at Telstra. He accomplished his masters in laptop science from College of Southern California. He’s enthusiastic about machine studying and generative AI use circumstances and constructing options.
Koushik Mani is an affiliate options architect at AWS. He had labored as a Software program Engineer for 2 years specializing in machine studying and cloud computing use circumstances at Telstra. He accomplished his masters in laptop science from College of Southern California. He’s enthusiastic about machine studying and generative AI use circumstances and constructing options.
 Rishabh Agrawal is a Senior Software program Engineer engaged on AI providers at AWS. In his spare time, he enjoys mountaineering, touring and studying.
Rishabh Agrawal is a Senior Software program Engineer engaged on AI providers at AWS. In his spare time, he enjoys mountaineering, touring and studying.
 Shreeya Sharma is a Senior Technical Product Supervisor at AWS, the place she has been engaged on leveraging the ability of generative AI to ship progressive and customer-centric merchandise. Shreeya holds a grasp’s diploma from Duke College. Exterior of labor, she loves touring, dancing, and singing.
Shreeya Sharma is a Senior Technical Product Supervisor at AWS, the place she has been engaged on leveraging the ability of generative AI to ship progressive and customer-centric merchandise. Shreeya holds a grasp’s diploma from Duke College. Exterior of labor, she loves touring, dancing, and singing.



{kind=link}