With the overall availability of Amazon Bedrock Brokers, you possibly can quickly develop generative AI purposes to run multi-step duties throughout a myriad of enterprise methods and knowledge sources. Nonetheless, some geographies and controlled industries sure by knowledge safety and privateness rules have sought to mix generative AI companies within the cloud with regulated knowledge on premises. On this publish, we present methods to prolong Amazon Bedrock Brokers to hybrid and edge companies similar to AWS Outposts and AWS Native Zones to construct distributed Retrieval Augmented Technology (RAG) purposes with on-premises knowledge for improved mannequin outcomes. With Outposts, we additionally cowl a reference sample for a totally native RAG utility that requires each the muse mannequin (FM) and knowledge sources to reside on premises.
Resolution overview
For organizations processing or storing delicate data similar to personally identifiable data (PII), clients have requested for AWS International Infrastructure to handle these particular localities, together with mechanisms to guarantee that knowledge is being saved and processed in compliance with native legal guidelines and rules. Via AWS hybrid and edge companies similar to Native Zones and Outposts, you possibly can profit from the scalability and suppleness of the AWS Cloud with the low latency and native processing capabilities of an on-premises (or localized) infrastructure. This hybrid strategy permits organizations to run purposes and course of knowledge nearer to the supply, lowering latency, bettering responsiveness for time-sensitive workloads, and adhering to knowledge rules.
Though architecting for knowledge residency with an Outposts rack and Native Zone has been broadly mentioned, generative AI and FMs introduce an extra set of architectural issues. As generative AI fashions develop into more and more highly effective and ubiquitous, clients have requested us how they could take into account deploying fashions nearer to the units, sensors, and finish customers producing and consuming knowledge. Furthermore, curiosity in small language fashions (SLMs) that allow resource-constrained units to carry out complicated features—similar to pure language processing and predictive automation—is rising. To be taught extra about alternatives for purchasers to make use of SLMs, see Alternatives for telecoms with small language fashions: Insights from AWS and Meta on our AWS Industries weblog.
Past SLMs, the curiosity in generative AI on the edge has been pushed by two main elements:
- Latency – Working these computationally intensive fashions on an edge infrastructure can considerably cut back latency and enhance real-time responsiveness, which is essential for a lot of time-sensitive purposes like digital assistants, augmented actuality, and autonomous methods.
- Privateness and safety – Processing delicate knowledge on the edge, moderately than sending it to the cloud, can improve privateness and safety by minimizing knowledge publicity. That is notably helpful in healthcare, monetary companies, and authorized sectors.
On this publish, we cowl two main architectural patterns: totally native RAG and hybrid RAG.
Absolutely native RAG
For the deployment of a giant language mannequin (LLM) in a RAG use case on an Outposts rack, the LLM shall be self-hosted on a G4dn occasion and data bases shall be created on the Outpost rack, utilizing both Amazon Elastic Block Storage (Amazon EBS) or Amazon S3 on Outposts. The paperwork uploaded to the data base on the rack may be non-public and delicate paperwork, in order that they received’t be transferred to the AWS Area and can stay utterly native on the Outpost rack. You should utilize a neighborhood vector database both hosted on Amazon Elastic Compute Cloud (Amazon EC2) or utilizing Amazon Relational Database Service (Amazon RDS) for PostgreSQL on the Outpost rack with the pgvector extension to retailer embeddings. See the next determine for an instance.

Hybrid RAG
Sure clients are required by knowledge safety or privateness rules to maintain their knowledge inside particular state boundaries. To align with these necessities and nonetheless use such knowledge for generative AI, clients with hybrid and edge environments must host their FMs in each a Area and on the edge. This setup lets you use knowledge for generative functions and stay compliant with safety rules. To orchestrate the habits of such a distributed system, you want a system that may perceive the nuances of your immediate and direct you to the fitting FM working in a compliant setting. Amazon Bedrock Brokers makes this distributed system in hybrid methods doable.
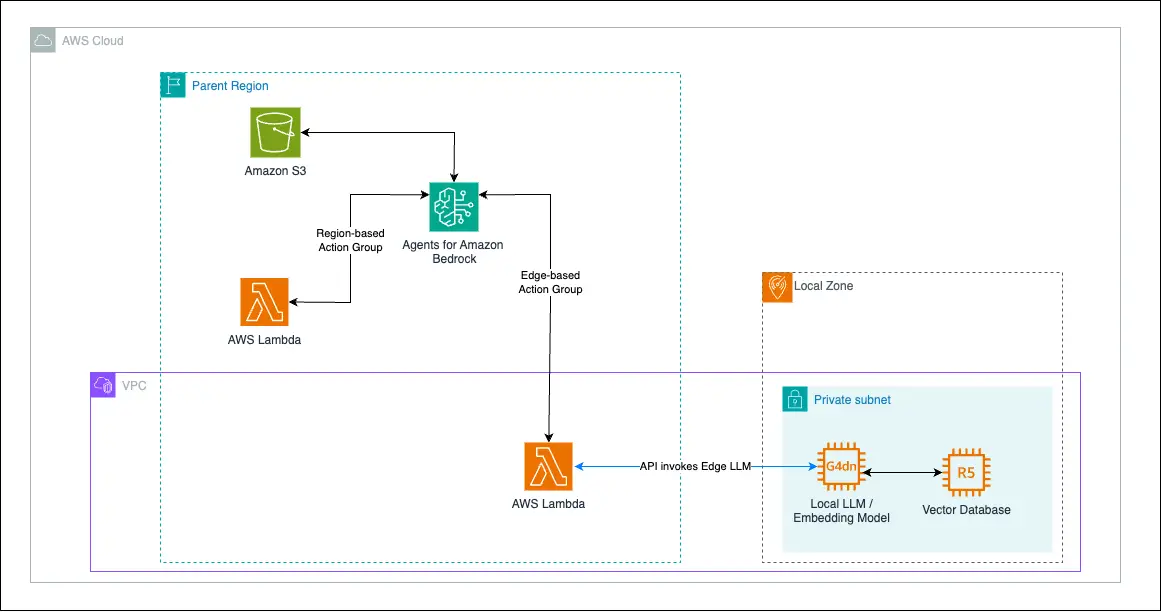
Amazon Bedrock Brokers lets you construct and configure autonomous brokers in your utility. Brokers orchestrate interactions between FMs, knowledge sources, software program purposes, and person conversations. The orchestration contains the power to invoke AWS Lambda features to invoke different FMs, opening the power to run self-managed FMs on the edge. With this mechanism, you possibly can construct distributed RAG purposes for extremely regulated industries topic to knowledge residency necessities. Within the hybrid deployment situation, in response to a buyer immediate, Amazon Bedrock can carry out some actions in a specified Area and defer different actions to a self-hosted FM in a Native Zone. The next instance illustrates the hybrid RAG high-level structure.

Within the following sections, we dive deep into each options and their implementation.
Absolutely native RAG: Resolution deep dive
To begin, that you must configure your digital non-public cloud (VPC) with an edge subnet on the Outpost rack. To create an edge subnet on the Outpost, that you must discover the Outpost Amazon Useful resource Title (ARN) on which you wish to create the subnet, in addition to the Availability Zone of the Outpost. After you create the web gateway, route tables, and subnet associations, launch a sequence of EC2 cases on the Outpost rack to run your RAG utility, together with the next parts.
- Vector retailer – To help RAG (Retrieval-Augmented Technology), deploy an open-source vector database, similar to ChromaDB or Faiss, on an EC2 occasion (C5 household) on AWS Outposts. This vector database will retailer the vector representations of your paperwork, serving as a key element of your native Data Base. Your chosen embedding mannequin shall be used to transform textual content (each paperwork and queries) into these vector representations, enabling environment friendly storage and retrieval. The precise Data Base consists of the unique textual content paperwork and their corresponding vector representations saved within the vector database. To question this information base and generate a response primarily based on the retrieved outcomes, you should use LangChain to chain the associated paperwork retrieved by the vector search to the immediate fed to your Giant Language Mannequin (LLM). This strategy permits for retrieval and integration of related data into the LLM’s technology course of, enhancing its responses with native, domain-specific data.
- Chatbot utility – On a second EC2 occasion (C5 household), deploy the next two parts: a backend service liable for ingesting prompts and proxying the requests again to the LLM working on the Outpost, and a easy React utility that enables customers to immediate a neighborhood generative AI chatbot with questions.
- LLM or SLM– On a 3rd EC2 occasion (G4 household), deploy an LLM or SLM to conduct edge inferencing by way of widespread frameworks similar to Ollama. Moreover, you should use ModelBuilder utilizing the SageMaker SDK to deploy to a neighborhood endpoint, similar to an EC2 occasion working on the edge.
Optionally, your underlying proprietary knowledge sources might be saved on Amazon Easy Storage Service (Amazon S3) on Outposts or utilizing Amazon S3-compatible options working on Amazon EC2 cases with EBS volumes.
The parts intercommunicate by means of the site visitors circulation illustrated within the following determine.

The workflow consists of the next steps:
- Utilizing the frontend utility, the person uploads paperwork that can function the data base and are saved in Amazon EBS on the Outpost rack. These paperwork are chunked by the appliance and are despatched to the embedding mannequin.
- The embedding mannequin, which is hosted on the identical EC2 occasion because the native LLM API inference server, converts the textual content chunks into vector representations.
- The generated embeddings are despatched to the vector database and saved, finishing the data base creation.
- Via the frontend utility, the person prompts the chatbot interface with a query.
- The immediate is forwarded to the native LLM API inference server occasion, the place the immediate is tokenized and is transformed right into a vector illustration utilizing the native embedding mannequin.
- The query’s vector illustration is shipped to the vector database the place a similarity search is carried out to get matching knowledge sources from the data base.
- After the native LLM has the question and the related context from the data base, it processes the immediate, generates a response, and sends it again to the chatbot utility.
- The chatbot utility presents the LLM response to the person by means of its interface.
To be taught extra in regards to the totally native RAG utility or get hands-on with the pattern utility, see Module 2 of our public AWS Workshop: Arms-on with Generative AI on AWS Hybrid & Edge Providers.
Hybrid RAG: Resolution deep dive
To begin, that you must configure a VPC with an edge subnet, both similar to an Outpost rack or Native Zone relying on the use case. After you create the web gateway, route tables, and subnet associations, launch an EC2 occasion on the Outpost rack (or Native Zone) to run your hybrid RAG utility. On the EC2 occasion itself, you possibly can reuse the identical parts because the totally native RAG: a vector retailer, backend API server, embedding mannequin and a neighborhood LLM.
On this structure, we rely closely on managed companies similar to Lambda and Amazon Bedrock as a result of solely choose FMs and data bases similar to the closely regulated knowledge, moderately than the orchestrator itself, are required to stay on the edge. To take action, we are going to prolong the prevailing Amazon Bedrock Brokers workflows to the sting utilizing a pattern FM-powered customer support bot.
On this instance customer support bot, we’re a shoe retailer bot that gives customer support help for buying footwear by offering choices in a human-like dialog. We additionally assume that the data base surrounding the observe of shoemaking is proprietary and, subsequently, resides on the edge. Because of this, questions surrounding shoemaking shall be addressed by the data base and native FM working on the edge.
To guarantee that the person immediate is successfully proxied to the fitting FM, we depend on Amazon Bedrock Brokers motion teams. An motion group defines actions that the agent can carry out, similar to place_order or check_inventory. In our instance, we may outline an extra motion inside an present motion group known as hybrid_rag or learn_shoemaking that particularly addresses prompts that may solely be addressed by the AWS hybrid and edge areas.
As a part of the agent’s InvokeAgent API, an agent interprets the immediate (similar to “How is leather-based used for shoemaking?”) with an FM and generates a logic for the subsequent step it ought to take, together with a prediction for essentially the most prudent motion in an motion group. On this instance, we wish the immediate, “Hiya, I would love suggestions to buy some footwear.” to be directed to the /check_inventory motion group, whereas the immediate, “How is leather-based used for shoemaking?” might be directed to the /hybrid_rag motion group.
The next diagram illustrates this orchestration, which is carried out by the orchestration part of the Amazon Bedrock agent.

To create the extra edge-specific motion group, the brand new OpenAPI schema should replicate the brand new motion, hybrid_rag with an in depth description, construction, and parameters that outline the motion within the motion group as an API operation particularly centered on an information area solely accessible in a selected edge location.
After you outline an motion group utilizing the OpenAPI specification, you possibly can outline a Lambda perform to program the enterprise logic for an motion group. This Lambda handler (see the next code) may embody supporting features (similar to queryEdgeModel) for the person enterprise logic corresponding to every motion group.
Nonetheless, within the motion group similar to the sting LLM (as seen within the code beneath), the enterprise logic received’t embody Area-based FM invocations, similar to utilizing Amazon Bedrock APIs. As an alternative, the customer-managed endpoint shall be invoked, for instance utilizing the non-public IP deal with of the EC2 occasion internet hosting the sting FM in a Native Zone or Outpost. This manner, AWS native companies similar to Lambda and Amazon Bedrock can orchestrate difficult hybrid and edge RAG workflows.
After the answer is totally deployed, you possibly can go to the chat playground characteristic on the Amazon Bedrock Brokers console and ask the query, “How are the rubber heels of footwear made?” Though many of the prompts shall be be solely centered on retail customer support operations for ordering footwear, the native orchestration help by Amazon Bedrock Brokers seamlessly directs the immediate to your edge FM working the LLM for shoemaking.

To be taught extra about this hybrid RAG utility or get hands-on with the cross-environment utility, consult with Module 1 of our public AWS Workshop: Arms-on with Generative AI on AWS Hybrid & Edge Providers.
Conclusion
On this publish, we demonstrated methods to prolong Amazon Bedrock Brokers to AWS hybrid and edge companies, similar to Native Zones or Outposts, to construct distributed RAG purposes in extremely regulated industries topic to knowledge residency necessities. Furthermore, for 100% native deployments to align with essentially the most stringent knowledge residency necessities, we introduced architectures converging the data base, compute, and LLM inside the Outposts {hardware} itself.
To get began with each architectures, go to AWS Workshops. To get began with our newly launched workshop, see Arms-on with Generative AI on AWS Hybrid & Edge Providers. Moreover, try different AWS hybrid cloud options or attain out to your native AWS account crew to learn to get began with Native Zones or Outposts.
Concerning the Authors
 Robert Belson is a Developer Advocate within the AWS Worldwide Telecom Enterprise Unit, specializing in AWS edge computing. He focuses on working with the developer neighborhood and enormous enterprise clients to unravel their enterprise challenges utilizing automation, hybrid networking, and the sting cloud.
Robert Belson is a Developer Advocate within the AWS Worldwide Telecom Enterprise Unit, specializing in AWS edge computing. He focuses on working with the developer neighborhood and enormous enterprise clients to unravel their enterprise challenges utilizing automation, hybrid networking, and the sting cloud.
 Aditya Lolla is a Sr. Hybrid Edge Specialist Options architect at Amazon Net Providers. He assists clients the world over with their migration and modernization journey from on-premises environments to the cloud and likewise construct hybrid architectures on AWS Edge infrastructure. Aditya’s areas of curiosity embody non-public networks, private and non-private cloud platforms, multi-access edge computing, hybrid and multi cloud methods and pc imaginative and prescient purposes.
Aditya Lolla is a Sr. Hybrid Edge Specialist Options architect at Amazon Net Providers. He assists clients the world over with their migration and modernization journey from on-premises environments to the cloud and likewise construct hybrid architectures on AWS Edge infrastructure. Aditya’s areas of curiosity embody non-public networks, private and non-private cloud platforms, multi-access edge computing, hybrid and multi cloud methods and pc imaginative and prescient purposes.


{kind=link}