ZURU Tech is on a mission to vary the best way we construct, from city homes and hospitals to workplace towers, faculties, house blocks, and extra. Dreamcatcher is a user-friendly platform developed by ZURU that permits customers with any stage of expertise to collaborate within the constructing design and building course of. With the straightforward click on of a button, a whole constructing could be ordered, manufactured and delivered to the development website for meeting.
ZURU collaborated with AWS Generative AI Innovation Heart and AWS Skilled Providers to implement a extra correct text-to-floor plan generator utilizing generative AI. With it, customers can specify an outline of the constructing they wish to design utilizing pure language. For instance, as an alternative of designing the muse, partitions, and key facets of a constructing from scratch, a person might enter, “Create a home with three bedrooms, two bogs, and an outside house for leisure.” The answer would generate a singular ground plan throughout the 3D design house, permitting customers with a non-technical understanding of structure and building to create a well-designed home
On this submit, we present you why an answer utilizing a giant language mannequin (LLM) was chosen. We discover how mannequin choice, immediate engineering, and fine-tuning can be utilized to enhance outcomes. And we clarify how the staff made certain they may iterate shortly by way of an analysis framework utilizing key providers akin to Amazon Bedrock and Amazon SageMaker.
Understanding the problem
The muse for producing a home inside Dreamcatcher’s 3D constructing system is to first verify we are able to generate a 2D ground plan based mostly on the person’s immediate. The ZURU staff discovered that producing 2D ground plans, such because the one within the following picture, utilizing totally different machine studying (ML) methods requires success throughout two key standards.

First, the mannequin should perceive rooms, the aim of every room, and their orientation to at least one one other inside a two-dimensional vector system. This can be described as how properly the mannequin can adhere to the options described from a person’s immediate. Second, there’s additionally a mathematical part to creating certain rooms adhere to standards akin to particular dimensions and ground house. To make sure that they had been heading in the right direction and to permit for quick R&D iteration cycles, the ZURU staff created a novel analysis framework that may measure the output of various fashions based mostly on displaying the extent of accuracy throughout these two key metrics.
The ZURU staff initially checked out utilizing generative adversarial networks (GAN) for ground plan technology, however experimentation with a GPT2 LLM had constructive outcomes based mostly on the check framework. This strengthened the concept that an LLM-based method might present the required accuracy for a text-to–ground plan generator.
Bettering the outcomes
To enhance on the outcomes of the GPT2 mannequin, we labored collectively and outlined two additional experiments. The primary was a immediate engineering method. Utilizing Anthropic’s Claude 3.5 Sonnet in Amazon Bedrock the staff was in a position to consider the affect of a number one proprietary mannequin with contextual examples included within the prompts. The second method targeted on utilizing fine-tuning with Llama 3B variants to judge the advance of accuracy when the mannequin weights are instantly influenced utilizing high-quality examples.
Dataset preparation and evaluation
To create the preliminary dataset, ground plans from 1000’s of homes had been gathered from publicly out there sources and reviewed by a staff of in-house architects. To streamline the assessment course of, the ZURU staff constructed a customized utility with a easy sure/no choice mechanism much like these present in widespread social matching purposes, permitting architects to shortly approve plans appropriate with the ZURU constructing system or reject these with disqualifying options. This intuitive method considerably accelerated ZURU’s analysis course of whereas sustaining clear choice standards for every ground plan.
To additional improve this dataset, we started with cautious dataset preparation together with filtering out the low-quality knowledge (30%) by evaluating the metric rating of floor reality dataset. Following this filtering mechanism, knowledge factors not reaching 100% accuracy on instruction adherence are faraway from the coaching dataset. This knowledge preparation method helped to enhance the effectivity and high quality of the fine-tuning and immediate engineering by greater than 20%.
Throughout our exploratory knowledge evaluation we discovered that the dataset contained prompts that may match a number of ground plans in addition to ground plans that would match a number of prompts. By transferring all associated immediate and ground plan mixtures to the identical knowledge break up (both coaching, validation, or testing) we had been in a position to stop knowledge leakage and promote sturdy analysis.
Immediate engineering method
As a part of our method, we applied dynamic matching for few-shot prompting that’s totally different from conventional static sampling strategies. Combining this with the implementation of immediate decomposition, we might enhance the general accuracy of the generated ground plan content material.
With a dynamic few-shot prompting methodology, we retrieve probably the most related examples at run time based mostly on the main points of the enter immediate from a high-quality dataset and supply this as a part of the immediate to the generative AI mannequin.
The dynamic few-shot prompting method is additional enhanced by immediate decomposition, the place we break down advanced duties into smaller, extra manageable parts to attain higher outcomes from language fashions. By decomposing queries, every part could be optimized for its particular goal. We discovered that combining these strategies resulted in improved relevancy in instance choice and decrease latency in retrieving the instance knowledge, main to higher efficiency and better high quality outcomes.
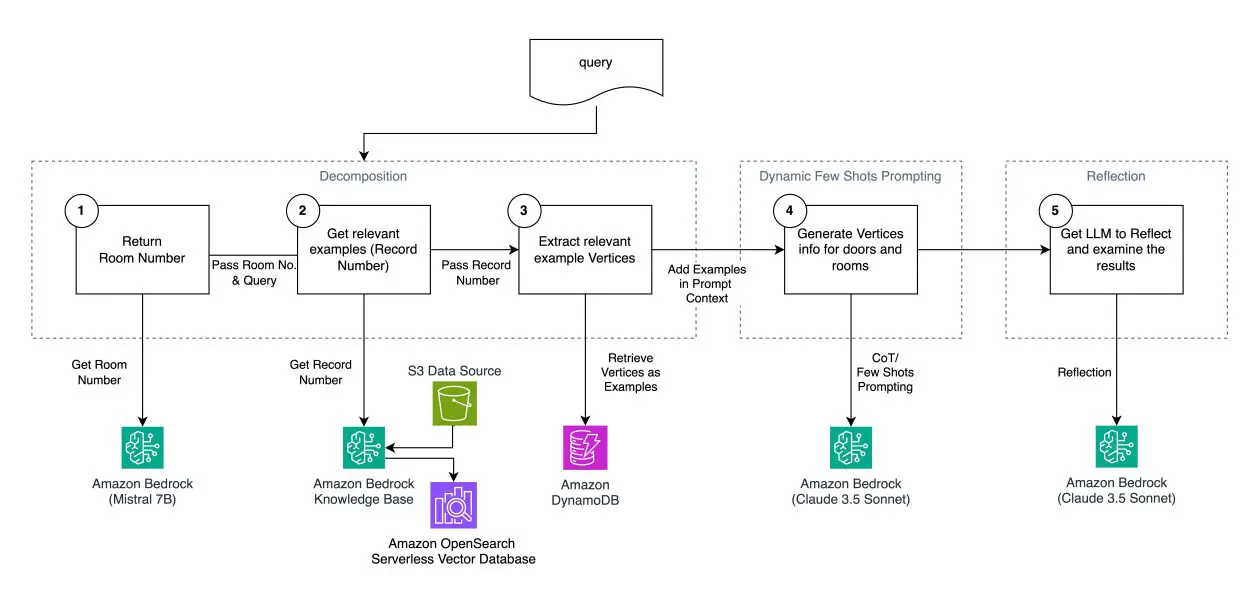
Immediate engineering structure
The workflow and structure applied for prototyping proven within the following determine demonstrates a scientific method to AI mannequin optimization. When a person question akin to “Construct me a home with three bedrooms and two bogs” is entered, the workflow follows these steps:
- We use immediate decomposition to execute three smaller duties that retrieve extremely related examples that match the identical options for a home that the person has requested
- We use the related examples and inject it into the immediate to carry out dynamic few-shot prompting to generate a ground plan
- We use the reflection method to ask the generative AI mannequin to self-reflect and asses that the generated content material adheres to our necessities

Deep dive on workflow and structure
Step one in our workflow is to grasp the distinctive options of the home, which we are able to use as search standards to seek out probably the most related examples within the subsequent steps. For this step, we use Amazon Bedrock, which gives a serverless API-driven endpoint for inference. From the big selection of generative AI fashions provided by Amazon Bedrock, we select Mistral 7B, which gives the correct steadiness between value, latency, and accuracy required for this small decomposed step.
The second step is to seek for probably the most related examples utilizing the distinctive options we discovered. We use Amazon Bedrock Information Bases backed by Amazon OpenSearch Serverless as a vector database to implement metadata filtering and hybrid search to retrieve probably the most related document identifiers. Amazon Easy Storage Service (Amazon S3) is used for storage of the information set, and Amazon Bedrock Information Bases gives a managed resolution for vectorizing and indexing the metadata into the vector database.
Within the third step, we retrieve the precise ground plan knowledge by document identifier utilizing Amazon DynamoDB. By splitting the search and retrieval of ground plan examples into two steps, we had been ready to make use of purpose-built providers with Amazon OpenSearch, permitting for low-latency search, and DynamoDB for low-latency knowledge retrieval by key worth resulting in optimized efficiency.
After retrieving probably the most related examples for the person’s immediate, in step 4 we use Amazon Bedrock and Anthropic’s Claude 3.5 Sonnet as a mannequin with main benchmarks in deep reasoning and arithmetic to generate our new ground plan.
Lastly, in step 5, we implement reflection. We use Amazon Bedrock with Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock once more and go the unique immediate, directions, examples and newly generated ground plan again with a remaining instruction for the mannequin to replicate and double-check its generated ground plan and proper errors.
Advantageous-tuning method
We explored two strategies for optimizing LLMs for automated floorplan technology: full parameter fine-tuning and Low-Rank Adaptation (LoRA)–based mostly fine-tuning. Full fine-tuning adjusts all LLM parameters, which requires vital reminiscence and coaching time. In distinction, LoRA tunes solely a small subset of parameters, lowering reminiscence necessities and coaching time.
Workflow and structure
We applied our workflow containing knowledge processing, fine-tuning, and inference and testing steps proven within the following determine under, all inside a SageMaker Jupyter Lab Pocket book provisioned with an ml.p4.24xlarge occasion, giving us entry to Nvidia A100 GPUs. As a result of we used a Jupyter pocket book and ran all elements of our workflow interactively, we had been in a position to iterate shortly and debug our experiments whereas maturing the coaching and testing scripts.

Deep dive on effective tuning workflow
One key perception from our experiments was the crucial significance of dataset high quality and variety. Additional to our preliminary dataset preparation, when fine-tuning a mannequin, we discovered that fastidiously choosing coaching samples with bigger variety helped the mannequin be taught extra sturdy representations. Moreover, though bigger batch sizes typically improved efficiency (inside reminiscence constraints), we needed to fastidiously steadiness this in opposition to computational sources (320 GB GPU reminiscence in an ml.p4.24xlarge occasion) and coaching time (ideally inside 1–2 days).
We carried out a number of iterations to optimize efficiency, experimenting with numerous approaches together with preliminary few-sample fast instruction fine-tuning, bigger dataset fine-tuning, fine-tuning with early stopping, evaluating Llama 3.1 8B and Llama 3 8B fashions, and ranging instruction size in fine-tuning samples. By way of these iterations, we discovered that full fine-tuning of the Llama 3.1 8B mannequin utilizing a curated dataset of 200,000 samples produced the very best outcomes.
The coaching course of for full fine-tuning Llama 3.1 8B with BF16 and a microbatch measurement of three concerned eight epochs with 30,000 steps, taking 25 hours to finish. In distinction, the LoRA method confirmed vital computational effectivity, requiring solely 2 hours of coaching time and producing an 89 MB checkpoint.
Analysis framework
The testing framework implements an environment friendly analysis methodology that optimizes useful resource utilization and time whereas sustaining statistical validity. Key parts embrace:
- A immediate deduplication system that identifies and consolidates duplicate directions within the check dataset, lowering computational overhead and enabling quicker iteration cycles for mannequin enchancment
- A distribution-based efficiency evaluation that filters distinctive check instances, promotes consultant sampling by way of statistical evaluation, and tasks outcomes throughout the complete dataset
- A metric-based analysis that implements scoring throughout key standards enabling comparative evaluation in opposition to each the baseline GPT2 mannequin and different approaches.
Outcomes and enterprise affect
To know how properly every method in our experiment carried out, we used the analysis framework and in contrast a number of key metrics. For the needs of this submit, we deal with two of those key metrics. The primary displays how properly the mannequin was in a position to observe customers’ directions to replicate the options required in the home. The second metric appears to be like at how properly the options of the home adhered to directions in mathematical and positioning and orientation. The next picture present these leads to a graph.

We discovered that the immediate engineering method with Anthropic’s Claude 3.5 Sonnet in addition to the complete fine-tuning method with Llama 3.1 8b elevated the instruction adherence high quality over the baseline GPT2 mannequin by 109%, displaying that, relying on a staff’s skillsets, each approaches could possibly be used to enhance the standard of understanding an LLM when producing content material akin to ground plans.
When mathematical correctness, our immediate engineering method wasn’t in a position to create vital enhancements over the baseline, however full fine-tuning was a transparent winner with a 54% enhance over the baseline GPT2 outcomes.
The LoRA-based tuning method achieves barely decrease efficiency scores being 20% much less within the metric scores on instruction adherence and 50% decrease scores on mathematical correctness in comparison with full fine-tuning, demonstrating the tradeoffs that may be made with regards to time, value, and {hardware} in comparison with mannequin accuracy.
Conclusion
ZURU Tech has set its imaginative and prescient on basically reworking the best way we design and assemble buildings. On this submit, we highlighted the method to constructing and enhancing a text-to–ground plan generator based mostly on LLMs to create a extremely useable and streamlined workflow inside a 3D-modeling system. We dived into superior ideas of immediate engineering utilizing Amazon Bedrock and detailed approaches to fine-tuning LLMs utilizing Amazon SageMaker, displaying the totally different tradeoffs you may make to considerably enhance on the accuracy of the content material that’s generated.
To be taught extra concerning the Generative AI Innovation Heart program, get in contact together with your account staff.
Concerning the Authors
 Federico Di Mattia is the staff chief and Product Proprietor of ZURU AI at ZURU Tech in Modena, Italy. With a deal with AI-driven innovation, he leads the event of Generative AI options that improve enterprise processes and drive ZURU’s development.
Federico Di Mattia is the staff chief and Product Proprietor of ZURU AI at ZURU Tech in Modena, Italy. With a deal with AI-driven innovation, he leads the event of Generative AI options that improve enterprise processes and drive ZURU’s development.
 Niro Amerasinghe is a Senior Options Architect based mostly out of Auckland, New Zealand. With expertise in structure, product improvement, and engineering, he helps prospects in utilizing Amazon Net Providers (AWS) to develop their companies.
Niro Amerasinghe is a Senior Options Architect based mostly out of Auckland, New Zealand. With expertise in structure, product improvement, and engineering, he helps prospects in utilizing Amazon Net Providers (AWS) to develop their companies.
 Haofei Feng is a Senior Cloud Architect at AWS with over 18 years of experience in DevOps, IT Infrastructure, Knowledge Analytics, and AI. He focuses on guiding organizations by way of cloud transformation and generative AI initiatives, designing scalable and safe GenAI options on AWS. Based mostly in Sydney, Australia, when not architecting options for purchasers, he cherishes time along with his household and Border Collies.
Haofei Feng is a Senior Cloud Architect at AWS with over 18 years of experience in DevOps, IT Infrastructure, Knowledge Analytics, and AI. He focuses on guiding organizations by way of cloud transformation and generative AI initiatives, designing scalable and safe GenAI options on AWS. Based mostly in Sydney, Australia, when not architecting options for purchasers, he cherishes time along with his household and Border Collies.
 Sheldon Liu is an utilized scientist, ANZ Tech Lead on the AWS Generative AI Innovation Heart. He companions with enterprise prospects throughout various industries to develop and implement revolutionary generative AI options, accelerating their AI adoption journey whereas driving vital enterprise outcomes.
Sheldon Liu is an utilized scientist, ANZ Tech Lead on the AWS Generative AI Innovation Heart. He companions with enterprise prospects throughout various industries to develop and implement revolutionary generative AI options, accelerating their AI adoption journey whereas driving vital enterprise outcomes.
 Xuefeng Liu leads a science staff on the AWS Generative AI Innovation Heart within the Asia Pacific areas. His staff companions with AWS prospects on generative AI tasks, with the objective of accelerating prospects’ adoption of generative AI.
Xuefeng Liu leads a science staff on the AWS Generative AI Innovation Heart within the Asia Pacific areas. His staff companions with AWS prospects on generative AI tasks, with the objective of accelerating prospects’ adoption of generative AI.
 Simone Bartoli is a Machine Studying Software program Engineer at ZURU Tech, in Modena, Italy. With a background in pc imaginative and prescient, machine studying, and full-stack net improvement, Simone focuses on creating revolutionary options that leverage cutting-edge applied sciences to reinforce enterprise processes and drive development.
Simone Bartoli is a Machine Studying Software program Engineer at ZURU Tech, in Modena, Italy. With a background in pc imaginative and prescient, machine studying, and full-stack net improvement, Simone focuses on creating revolutionary options that leverage cutting-edge applied sciences to reinforce enterprise processes and drive development.
 Marco Venturelli is a Senior Machine Studying Engineer at ZURU Tech in Modena, Italy. With a background in pc imaginative and prescient and AI, he leverages his expertise to innovate with generative AI, enriching the Dreamcatcher software program with sensible options.
Marco Venturelli is a Senior Machine Studying Engineer at ZURU Tech in Modena, Italy. With a background in pc imaginative and prescient and AI, he leverages his expertise to innovate with generative AI, enriching the Dreamcatcher software program with sensible options.
 Stefano Pellegrini is a Generative AI Software program Engineer at ZURU Tech in Italy. Specializing in GAN and diffusion-based picture technology, he creates tailor-made image-generation options for numerous departments throughout ZURU.
Stefano Pellegrini is a Generative AI Software program Engineer at ZURU Tech in Italy. Specializing in GAN and diffusion-based picture technology, he creates tailor-made image-generation options for numerous departments throughout ZURU.
 Enrico Petrucci is a Machine Studying Software program Engineer at ZURU Tech, based mostly in Modena, Italy. With a robust background in machine studying and NLP duties, he at present focuses on leveraging Generative AI and Massive Language Fashions to develop revolutionary agentic programs that present tailor-made options for particular enterprise instances.
Enrico Petrucci is a Machine Studying Software program Engineer at ZURU Tech, based mostly in Modena, Italy. With a robust background in machine studying and NLP duties, he at present focuses on leveraging Generative AI and Massive Language Fashions to develop revolutionary agentic programs that present tailor-made options for particular enterprise instances.


{kind=link}