This submit is a joint collaboration between Salesforce and AWS and is being cross-published on each the Salesforce Engineering Weblog and the AWS Machine Studying Weblog.
The Salesforce AI Mannequin Serving staff is working to push the boundaries of pure language processing and AI capabilities for enterprise functions. Their key focus areas embody optimizing giant language fashions (LLMs) by integrating cutting-edge options, collaborating with main know-how suppliers, and driving efficiency enhancements that affect Salesforce’s AI-driven options. The AI Mannequin Serving staff helps a variety of fashions for each conventional machine studying (ML) and generative AI together with LLMs, multi-modal basis fashions (FMs), speech recognition, and laptop vision-based fashions. By means of innovation and partnerships with main know-how suppliers, this staff enhances efficiency and capabilities, tackling challenges comparable to throughput and latency optimization and safe mannequin deployment for real-time AI functions. They accomplish this via analysis of ML fashions throughout a number of environments and in depth efficiency testing to attain scalability and reliability for inferencing on AWS.
The staff is answerable for the end-to-end strategy of gathering necessities and efficiency goals, internet hosting, optimizing, and scaling AI fashions, together with LLMs, constructed by Salesforce’s knowledge science and analysis groups. This contains optimizing the fashions to attain excessive throughput and low latency and deploying them rapidly via automated, self-service processes throughout a number of AWS Areas.
On this submit, we share how the AI Mannequin Service staff achieved high-performance mannequin deployment utilizing Amazon SageMaker AI.
Key challenges
The staff faces a number of challenges in deploying fashions for Salesforce. An instance can be balancing latency and throughput whereas reaching cost-efficiency when scaling these fashions primarily based on demand. Sustaining efficiency and scalability whereas minimizing serving prices is important throughout the whole inference lifecycle. Inference optimization is an important facet of this course of, as a result of the mannequin and their internet hosting surroundings have to be fine-tuned to fulfill price-performance necessities in real-time AI functions. Salesforce’s fast-paced AI innovation requires the staff to consistently consider new fashions (proprietary, open supply, or third-party) throughout various use circumstances. They then should rapidly deploy these fashions to remain in cadence with their product groups’ go-to-market motions. Lastly, the fashions have to be hosted securely, and buyer knowledge have to be protected to abide by Salesforce’s dedication to offering a trusted and safe platform.
Answer overview
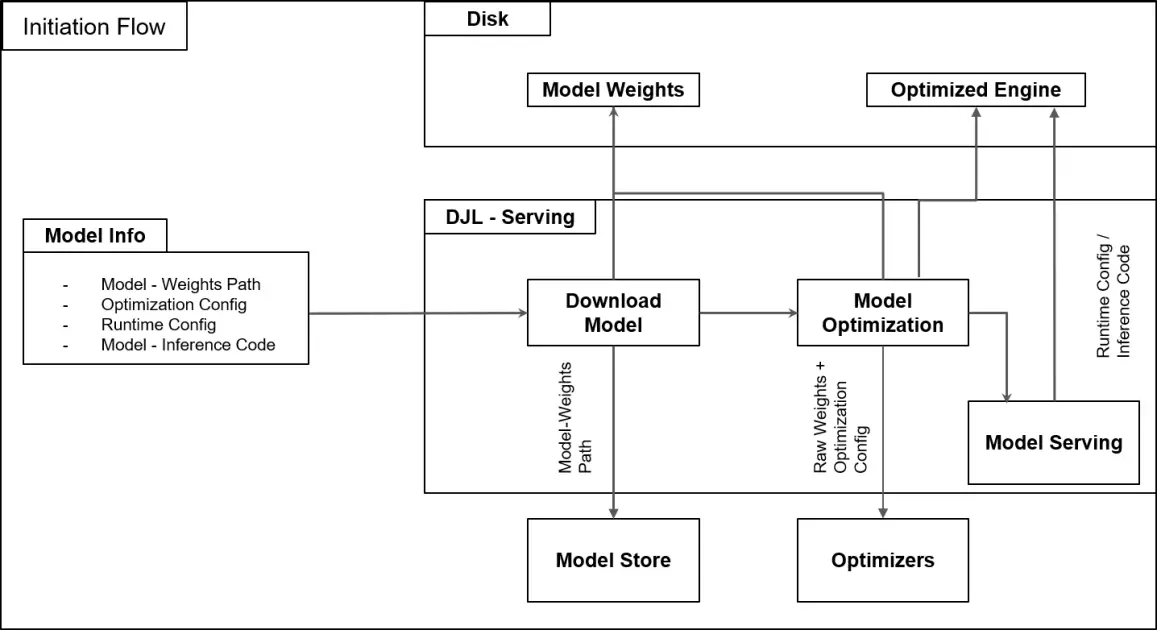
To assist such a important operate for Salesforce AI, the staff developed a internet hosting framework on AWS to simplify their mannequin lifecycle, permitting them to rapidly and securely deploy fashions at scale whereas optimizing for value. The next diagram illustrates the answer workflow.

Managing efficiency and scalability
Managing scalability within the venture entails balancing efficiency with effectivity and useful resource administration. With SageMaker AI, the staff helps distributed inference and multi-model deployments, stopping reminiscence bottlenecks and lowering {hardware} prices. SageMaker AI gives entry to superior GPUs, helps multi-model deployments, and permits clever batching methods to steadiness throughput with latency. This flexibility makes positive efficiency enhancements don’t compromise scalability, even in high-demand eventualities. To be taught extra, see Revolutionizing AI: How Amazon SageMaker Enhances Einstein’s Massive Language Mannequin Latency and Throughput.
Accelerating growth with SageMaker Deep Studying Containers
SageMaker AI Deep Studying Containers (DLCs) play an important function in accelerating mannequin growth and deployment. These pre-built containers include optimized deep studying frameworks and best-practice configurations, offering a head begin for AI groups. DLCs present optimized library variations, preconfigured CUDA settings, and different efficiency enhancements that enhance inference speeds and effectivity. This considerably reduces the setup and configuration overhead, permitting engineers to deal with mannequin optimization fairly than infrastructure issues.
Greatest follow configurations for deployment in SageMaker AI
A key benefit of utilizing SageMaker AI is the perfect follow configurations for deployment. SageMaker AI gives default parameters for setting GPU utilization and reminiscence allocation, which simplifies the method of configuring high-performance inference environments. These options make it simple to deploy optimized fashions with minimal handbook intervention, offering excessive availability and low-latency responses.
The staff makes use of the DLC’s rolling-batch functionality, which optimizes request batching to maximise throughput whereas sustaining low latency. SageMaker AI DLCs expose configurations for rolling batch inference with best-practice defaults, simplifying the implementation course of. By adjusting parameters comparable to max_rolling_batch_size and job_queue_size, the staff was in a position to fine-tune efficiency with out in depth customized engineering. This streamlined method gives optimum GPU utilization whereas sustaining real-time response necessities.
SageMaker AI gives elastic load balancing, occasion scaling, and real-time mannequin monitoring, and gives Salesforce management over scaling and routing methods to swimsuit their wants. These measures keep constant efficiency throughout environments whereas optimizing scalability, efficiency, and cost-efficiency.
As a result of the staff helps a number of simultaneous deployments throughout tasks, they wanted to ensure enhancements in every venture didn’t compromise others. To deal with this, they adopted a modular growth method. The SageMaker AI DLC structure is designed with modular elements such because the engine abstraction layer, mannequin retailer, and workload supervisor. This construction permits the staff to isolate and optimize particular person elements on the container, like rolling batch inference for throughput, with out disrupting important performance comparable to latency or multi-framework assist. This permits venture groups to work on particular person tasks comparable to efficiency tuning whereas permitting others to deal with enabling different functionalities comparable to streaming in parallel.
This cross-functional collaboration is complemented by complete testing. The Salesforce AI mannequin staff carried out steady integration (CI) pipelines utilizing a mixture of inside and exterior instruments comparable to Jenkins and Spinnaker to detect any unintended unwanted effects early. Regression testing made positive that optimizations, comparable to deploying fashions with TensorRT or vLLM, didn’t negatively affect scalability or consumer expertise. Common opinions, involving collaboration between the event, basis mannequin operations (FMOps), and safety groups, made positive that optimizations aligned with project-wide goals.
Configuration administration can also be a part of the CI pipeline. To be exact, configuration is saved in git alongside inference code. Configuration administration utilizing easy YAML information enabled speedy experimentation throughout optimizers and hyperparameters with out altering the underlying code. These practices made positive that efficiency or safety enhancements have been well-coordinated and didn’t introduce trade-offs in different areas.
Sustaining safety via speedy deployment
Balancing speedy deployment with excessive requirements of belief and safety requires embedding safety measures all through the event and deployment lifecycle. Safe-by-design rules are adopted from the outset, ensuring that safety necessities are built-in into the structure. Rigorous testing of all fashions is performed in growth environments alongside efficiency testing to offer scalable efficiency and safety earlier than manufacturing.
To take care of these excessive requirements all through the event course of, the staff employs a number of methods:
- Automated steady integration and supply (CI/CD) pipelines with built-in checks for vulnerabilities, compliance validation, and mannequin integrity
- Using DJL-Serving’s encryption mechanisms for knowledge in transit and at relaxation
- Utilizing AWS providers like SageMaker AI that present enterprise-grade safety features comparable to role-based entry management (RBAC) and community isolation
Frequent automated testing for each efficiency and safety is employed via small incremental deployments, permitting for early subject identification whereas minimizing dangers. Collaboration with cloud suppliers and steady monitoring of deployments keep compliance with the newest safety requirements and ensure speedy deployment aligns seamlessly with sturdy safety, belief, and reliability.
Deal with steady enchancment
As Salesforce’s generative AI wants scale, and with the ever-changing mannequin panorama, the staff regularly works to enhance their deployment infrastructure—ongoing analysis and growth efforts are centered on enhancing the efficiency, scalability, and effectivity of LLM deployments. The staff is exploring new optimization strategies with SageMaker, together with:
- Superior quantization strategies (INT-4, AWQ, FP8)
- Tensor parallelism (splitting tensors throughout a number of GPUs)
- Extra environment friendly batching utilizing caching methods inside DJL-Serving to spice up throughput and scale back latency
The staff can also be investigating rising applied sciences like AWS AI chips (AWS Trainium and AWS Inferentia) and AWS Graviton processors to additional enhance value and power effectivity. Collaboration with open supply communities and public cloud suppliers like AWS makes positive that the newest developments are included into deployment pipelines whereas additionally pushing the boundaries additional. Salesforce is collaborating with AWS to incorporate superior options into DJL, which makes the utilization even higher and extra sturdy, comparable to extra configuration parameters, surroundings variables, and extra granular metrics for logging. A key focus is refining multi-framework assist and distributed inference capabilities to offer seamless mannequin integration throughout varied environments.
Efforts are additionally underway to reinforce FMOps practices, comparable to automated testing and deployment pipelines, to expedite manufacturing readiness. These initiatives intention to remain on the forefront of AI innovation, delivering cutting-edge options that align with enterprise wants and meet buyer expectations. They’re in shut collaboration with the SageMaker staff to proceed to discover potential options and capabilities to assist these areas.
Conclusion
Although actual metrics range by use case, the Salesforce AI Mannequin Serving staff noticed substantial enhancements by way of deployment pace and cost-efficiency with their technique on SageMaker AI. They skilled quicker iteration cycles, measured in days and even hours as an alternative of weeks. With SageMaker AI, they decreased their mannequin deployment time by as a lot as 50%.
To be taught extra about how SageMaker AI enhances Einstein’s LLM latency and throughput, see Revolutionizing AI: How Amazon SageMaker Enhances Einstein’s Massive Language Mannequin Latency and Throughput. For extra data on the right way to get began with SageMaker AI, discuss with Information to getting arrange with Amazon SageMaker AI.
Concerning the authors
 Sai Guruju is working as a Lead Member of Technical Workers at Salesforce. He has over 7 years of expertise in software program and ML engineering with a deal with scalable NLP and speech options. He accomplished his Bachelor’s of Know-how in EE from IIT-Delhi, and has revealed his work at InterSpeech 2021 and AdNLP 2024.
Sai Guruju is working as a Lead Member of Technical Workers at Salesforce. He has over 7 years of expertise in software program and ML engineering with a deal with scalable NLP and speech options. He accomplished his Bachelor’s of Know-how in EE from IIT-Delhi, and has revealed his work at InterSpeech 2021 and AdNLP 2024.
 Nitin Surya is working as a Lead Member of Technical Workers at Salesforce. He has over 8 years of expertise in software program and machine studying engineering, accomplished his Bachelor’s of Know-how in CS from VIT College, with an MS in CS (with a significant in Synthetic Intelligence and Machine Studying) from the College of Illinois Chicago. He has three patents pending, and has revealed and contributed to papers on the CoRL Convention.
Nitin Surya is working as a Lead Member of Technical Workers at Salesforce. He has over 8 years of expertise in software program and machine studying engineering, accomplished his Bachelor’s of Know-how in CS from VIT College, with an MS in CS (with a significant in Synthetic Intelligence and Machine Studying) from the College of Illinois Chicago. He has three patents pending, and has revealed and contributed to papers on the CoRL Convention.
 Srikanta Prasad is a Senior Supervisor in Product Administration specializing in generative AI options, with over 20 years of expertise throughout semiconductors, aerospace, aviation, print media, and software program know-how. At Salesforce, he leads mannequin internet hosting and inference initiatives, specializing in LLM inference serving, LLMOps, and scalable AI deployments. Srikanta holds an MBA from the College of North Carolina and an MS from the Nationwide College of Singapore.
Srikanta Prasad is a Senior Supervisor in Product Administration specializing in generative AI options, with over 20 years of expertise throughout semiconductors, aerospace, aviation, print media, and software program know-how. At Salesforce, he leads mannequin internet hosting and inference initiatives, specializing in LLM inference serving, LLMOps, and scalable AI deployments. Srikanta holds an MBA from the College of North Carolina and an MS from the Nationwide College of Singapore.
 Rielah De Jesus is a Principal Options Architect at AWS who has efficiently helped varied enterprise clients within the DC, Maryland, and Virginia space transfer to the cloud. In her present function, she acts as a buyer advocate and technical advisor centered on serving to organizations like Salesforce obtain success on the AWS platform. She can also be a staunch supporter of ladies in IT and may be very obsessed with discovering methods to creatively use know-how and knowledge to unravel on a regular basis challenges.
Rielah De Jesus is a Principal Options Architect at AWS who has efficiently helped varied enterprise clients within the DC, Maryland, and Virginia space transfer to the cloud. In her present function, she acts as a buyer advocate and technical advisor centered on serving to organizations like Salesforce obtain success on the AWS platform. She can also be a staunch supporter of ladies in IT and may be very obsessed with discovering methods to creatively use know-how and knowledge to unravel on a regular basis challenges.



{kind=link}