This submit is cowritten with Jimmy Cancilla from Rapid7.
Organizations are managing more and more distributed techniques, which span on-premises infrastructure, cloud providers, and edge gadgets. As techniques turn into interconnected and alternate knowledge, the potential pathways for exploitation multiply, and vulnerability administration turns into essential to managing danger. Vulnerability administration (VM) is the method of figuring out, classifying, prioritizing, and remediating safety weaknesses in software program, {hardware}, digital machines, Web of Issues (IoT) gadgets, and comparable property. When new vulnerabilities are found, organizations are beneath stress to remediate them. Delayed responses can open the door to exploits, knowledge breaches, and reputational hurt. For organizations with 1000’s or tens of millions of software program property, efficient triage and prioritization for the remediation of vulnerabilities are essential.
To help this course of, the Frequent Vulnerability Scoring System (CVSS) has turn into the trade normal for evaluating the severity of software program vulnerabilities. CVSS v3.1, printed by the Discussion board of Incident Response and Safety Groups (FIRST), offers a structured and repeatable framework for scoring vulnerabilities throughout a number of dimensions: exploitability, affect, assault vector, and others. With new threats rising consistently, safety groups want standardized, close to real-time knowledge to reply successfully. CVSS v3.1 is utilized by organizations equivalent to NIST and main software program distributors to prioritize remediation efforts, help danger assessments, and adjust to requirements.
There’s, nonetheless, a essential hole that emerges earlier than a vulnerability is formally standardized. When a brand new vulnerability is disclosed, distributors aren’t required to incorporate a CVSS rating alongside the disclosure. Moreover, third-party organizations equivalent to NIST aren’t obligated or certain by particular timelines to investigate vulnerabilities and assign CVSS scores. Because of this, many vulnerabilities are made public with out a corresponding CVSS rating. This example can go away prospects unsure about how one can reply: ought to they patch the newly found vulnerability instantly, monitor it for a couple of days, or deprioritize it? Our purpose with machine studying (ML) is to supply Rapid7 prospects with a well timed reply to this essential query.
Rapid7 helps organizations defend what issues most so innovation can thrive in an more and more linked world. Rapid7’s complete know-how, providers, and community-focused analysis take away complexity, cut back vulnerabilities, monitor for malicious conduct, and shut down assaults. On this submit, we share how Rapid7 applied end-to-end automation for the coaching, validation, and deployment of ML fashions that predict CVSS vectors. Rapid7 prospects have the data they should precisely perceive their danger and prioritize remediation measures.
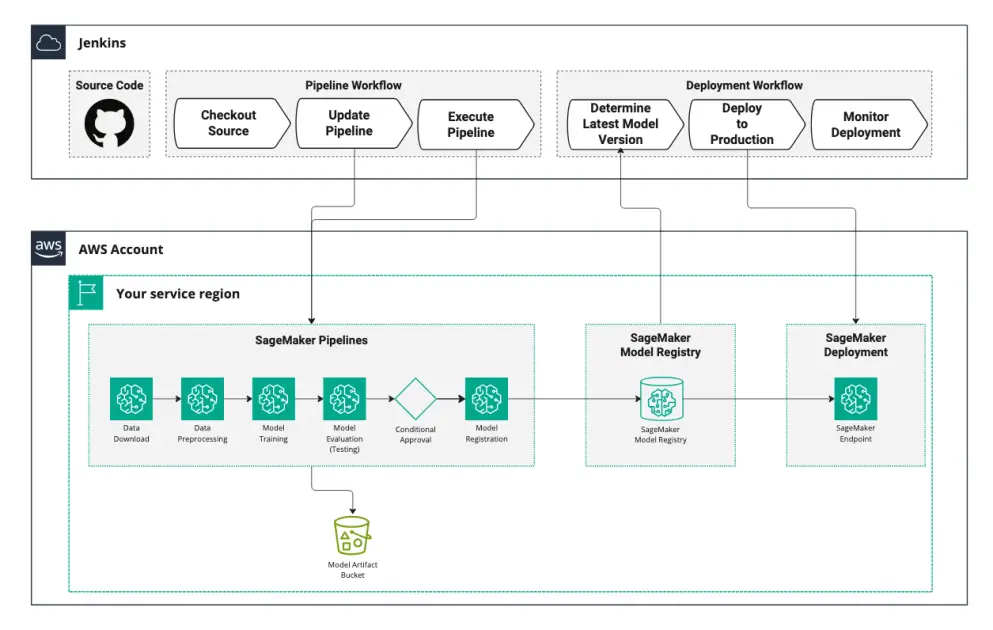
Rapid7’s answer structure
Rapid7 constructed their end-to-end answer utilizing Amazon SageMaker AI, the Amazon Internet Providers (AWS) absolutely managed ML service to construct, practice, and deploy ML fashions into manufacturing environments. SageMaker AI offers highly effective compute for ephemeral duties, orchestration instruments for constructing automated pipelines, a mannequin registry for monitoring mannequin artifacts and variations, and scalable deployment to configurable endpoints.
Rapid7 built-in SageMaker AI with their DevOps instruments (GitHub for model management and Jenkins for construct automation) to implement steady integration and steady deployment (CI/CD) for the ML fashions used for CVSS scoring. By automating mannequin coaching and deployment, Rapid7’s CVSS scoring options keep updated with the newest knowledge with out further operational overhead.
The next diagram illustrates the answer structure.

Orchestrating with SageMaker AI Pipelines
Step one within the journey towards end-to-end automation was eradicating handbook actions beforehand carried out by knowledge scientists. This meant migrating experimental code from Jupyter notebooks to production-ready Python scripts. Rapid7 established a undertaking construction to help each growth and manufacturing. Every step within the ML pipeline—knowledge obtain, preprocessing, coaching, analysis, and deployment—was outlined as a standalone Python module in a standard listing.
Designing the pipeline
After refactoring, pipeline steps have been moved to SageMaker Coaching and Processing jobs for distant execution. Steps within the pipeline have been outlined utilizing Docker pictures with the required libraries, and orchestrated utilizing SageMaker Pipelines within the SageMaker Python SDK.
CVSS v3.1 vectors encompass eight unbiased metrics mixed right into a single vector. To provide an correct CVSS vector, eight separate fashions have been skilled in parallel. Nevertheless, the information used to coach these fashions was an identical. This meant that the coaching course of may share widespread obtain and preprocessing steps, adopted by separate coaching, validation, and deployment steps for every metric. The next diagram illustrates the high-level structure of the applied pipeline.

Information loading and preprocessing
The info used to coach the mannequin comprised current vulnerabilities and their related CVSS vectors. This knowledge supply is up to date consistently, which is why Rapid7 determined to obtain the newest knowledge out there at coaching time and uploaded it to Amazon Easy Storage Service (Amazon S3) for use by subsequent steps. After being up to date, Rapid7 applied a preprocessing step to:
- Construction the information to facilitate ingestion and use in coaching.
- Break up the information into three units: coaching, validation, and testing (80%, 10%, and 10%).
The preprocessing step was outlined with a dependency on the information obtain step in order that the brand new dataset was out there earlier than a brand new preprocessing job was began. The outputs of the preprocessing job—the ensuing coaching, validation, and check units—are additionally uploaded to Amazon S3 to be consumed by the coaching steps that observe.
Mannequin coaching, analysis, and deployment
For the remaining pipeline steps, Rapid7 executed every step eight occasions—one time for every metric within the CVSS vector. Rapid7 iterated by way of every of the eight metrics to outline the corresponding coaching, analysis, and deployment steps utilizing the SageMaker Pipelines SDK.
The loop follows an analogous sample for every metric. The method begins with a coaching job utilizing PyTorch framework pictures supplied by Amazon SageMaker AI. The next is a pattern script for outlining a coaching job.
The PyTorch Estimator creates mannequin artifacts which might be routinely uploaded to the Amazon S3 location outlined within the output path parameter. The identical script is used for every one of many CVSS v3.1 metrics whereas specializing in a unique metric by passing a unique cvss_metric to the coaching script as an surroundings variable.
The SageMaker Pipeline is configured to set off the execution of a mannequin analysis step when the mannequin coaching job for that CVSS v3.1 metric is completed. The mannequin analysis job takes the newly skilled mannequin and check knowledge as inputs, as proven within the following step definition.
The processing job is configured to create a PropertyFile object to retailer the outcomes from the analysis step. Here’s a pattern of what may be discovered on this file:
This info is essential within the final step of the sequence adopted for every metric within the CVSS vector. Rapid7 desires to make sure that fashions deployed in manufacturing meet high quality requirements, they usually do this through the use of a ConditionStep that enables solely fashions whose accuracy is above a essential worth to be registered within the SageMaker Mannequin Registry. This course of is repeated for all eight fashions.
Defining the pipeline
With all of the steps outlined, a pipeline object is created with all of the steps for all eight fashions. The graph for the pipeline definition is proven within the following picture.

Managing fashions with SageMaker Mannequin Registry
SageMaker Mannequin Registry is a repository for storing, versioning, and managing ML fashions all through the machine studying operations (MLOps) lifecycle. The mannequin registry allows the Rapid7 staff to trace mannequin artifacts and their metadata (equivalent to efficiency metrics), and streamline mannequin model administration as their CVSS fashions evolve. Every time a brand new mannequin is added, a brand new model is created beneath the identical mannequin group, which helps observe mannequin iterations over time. As a result of new variations are evaluated for accuracy earlier than registration, they’re registered with an Accredited standing. If a mannequin’s accuracy falls under this threshold, the automated deployment pipeline will detect this and ship an alert to inform the staff concerning the failed deployment. This permits Rapid7 to take care of an automatic pipeline that serves probably the most correct mannequin out there so far with out requiring handbook overview of latest mannequin artifacts.
Deploying fashions with inference elements
When a set of CVSS scoring fashions has been chosen, they are often deployed in a SageMaker AI endpoint for real-time inference, permitting them to be invoked to calculate a CVSS vector as quickly as new vulnerability knowledge is accessible. SageMaker AI endpoints are accessible URLs the place purposes can ship knowledge and obtain predictions. Internally, the CVSS v3.1 vector is ready utilizing predictions from the eight scoring fashions, adopted by postprocessing logic. As a result of every invocation runs every of the eight CVSS scoring fashions one time, their deployment might be optimized for environment friendly use of compute sources.
When the deployment script runs, it checks the mannequin registry for brand spanking new variations. If it detects an replace, it instantly deploys the brand new model to a SageMaker endpoint.
Making certain Price Effectivity
Price effectivity was a key consideration in designing this workflow. Utilization patterns for vulnerability scoring are bursty, with intervals of excessive exercise adopted by lengthy idle intervals. Sustaining devoted compute sources for every mannequin can be unnecessarily costly given these idle occasions. To handle this situation, Rapid7 applied Inference Elements of their SageMaker endpoint. Inference elements enable a number of fashions to share the identical underlying compute sources, considerably enhancing price effectivity—significantly for bursty inference patterns. This method enabled Rapid7 to deploy all eight fashions on a single occasion. Efficiency exams confirmed that inference requests might be processed in parallel throughout all eight fashions, persistently reaching sub-second response occasions (100-200ms).
Monitoring fashions in manufacturing
Rapid7 regularly displays the fashions in manufacturing to make sure excessive availability and environment friendly use of compute sources. The SageMaker AI endpoint routinely uploads logs and metrics into Amazon CloudWatch, that are then forwarded and visualized in Grafana. As a part of common operations, Rapid7 displays these dashboards to visualise metrics equivalent to mannequin latency, the variety of cases behind the endpoint, and invocations and errors over time. Moreover, alerts are configured on response time metrics to take care of system responsiveness and forestall delays within the enrichment pipeline. For extra info on the assorted metrics and their utilization, consult with the AWS weblog submit, Finest practices for load testing Amazon SageMaker real-time inference endpoints.
Conclusion
Finish-to-end automation of vulnerability scoring mannequin growth and deployment has given Rapid7 a constant, absolutely automated course of. The earlier handbook course of for retraining and redeploying these fashions was fragile, error-prone, and time-intensive. By implementing an automatic pipeline with SageMaker, the engineering staff now saves at the very least 2–3 days of upkeep work every month. By eliminating 20 handbook operations, Rapid7 software program engineers can deal with delivering higher-impact work for his or her prospects. Moreover, through the use of inference elements, all fashions might be consolidated onto a single ml.m5.2xlarge occasion, moderately than deploying a separate endpoint (and occasion) for every mannequin. This method almost halves the hourly compute price, leading to roughly 50% cloud compute financial savings for this workload. In constructing this pipeline, Rapid7 benefited from options that lowered time and value throughout a number of steps. For instance, utilizing customized containers with the mandatory libraries improved startup occasions, whereas inference elements enabled environment friendly useful resource utilization—each have been instrumental in constructing an efficient answer.
Most significantly, this automation signifies that Rapid7 prospects all the time obtain probably the most just lately printed CVEs with a CVSSv3.1 rating assigned. That is particularly vital for InsightVM as a result of Lively Danger Scores, Rapid7’s newest danger technique for understanding vulnerability affect, depend on the CVSSv3.1 rating as a key part of their calculation. Offering correct and significant danger scores is essential for the success of safety groups, empowering them to prioritize and handle vulnerabilities extra successfully.
In abstract, automating mannequin coaching and deployment with Amazon SageMaker Pipelines has enabled Rapid7 to ship scalable, dependable, and environment friendly ML options. By embracing these finest practices and classes realized, groups can streamline their workflows, cut back operational overhead, and stay centered on driving innovation and worth for his or her prospects.
In regards to the authors
 Jimmy Cancilla is a Principal Software program Engineer at Rapid7, centered on making use of machine studying and AI to resolve advanced cybersecurity challenges. He leads the event of safe, cloud-based options that use automation and data-driven insights to enhance risk detection and vulnerability administration. He’s pushed by a imaginative and prescient of AI as a instrument to enhance human work, accelerating innovation, enhancing productiveness, and enabling groups to realize extra with higher pace and affect.
Jimmy Cancilla is a Principal Software program Engineer at Rapid7, centered on making use of machine studying and AI to resolve advanced cybersecurity challenges. He leads the event of safe, cloud-based options that use automation and data-driven insights to enhance risk detection and vulnerability administration. He’s pushed by a imaginative and prescient of AI as a instrument to enhance human work, accelerating innovation, enhancing productiveness, and enabling groups to realize extra with higher pace and affect.
Felipe Lopez is a Senior AI/ML Specialist Options Architect at AWS. Previous to becoming a member of AWS, Felipe labored with GE Digital and SLB, the place he centered on modeling and optimization merchandise for industrial purposes.
is a Senior AI/ML Specialist Options Architect at AWS. Previous to becoming a member of AWS, Felipe labored with GE Digital and SLB, the place he centered on modeling and optimization merchandise for industrial purposes.
 Steven Warwick is a Senior Options Architect at AWS, the place he leads buyer engagements to drive profitable cloud adoption and makes a speciality of SaaS architectures and Generative AI options. He produces academic content material together with weblog posts and pattern code to assist prospects implement finest practices, and has led applications on GenAI matters for answer architects. Steven brings many years of know-how expertise to his position, serving to prospects with architectural evaluations, price optimization, and proof-of-concept growth.
Steven Warwick is a Senior Options Architect at AWS, the place he leads buyer engagements to drive profitable cloud adoption and makes a speciality of SaaS architectures and Generative AI options. He produces academic content material together with weblog posts and pattern code to assist prospects implement finest practices, and has led applications on GenAI matters for answer architects. Steven brings many years of know-how expertise to his position, serving to prospects with architectural evaluations, price optimization, and proof-of-concept growth.



{kind=link}