
This publish is co-written by Fan Zhang, Sr Principal Engineer / Architect from Palo Alto Networks.
Palo Alto Networks’ Gadget Safety staff needed to detect early warning indicators of potential manufacturing points to offer extra time to SMEs to react to those rising issues. The first problem they confronted was that reactively processing over 200 million each day service and utility log entries resulted in delayed response occasions to those important points, leaving them in danger for potential service degradation.
To handle this problem, they partnered with the AWS Generative AI Innovation Middle (GenAIIC) to develop an automatic log classification pipeline powered by Amazon Bedrock. The answer achieved 95% precision in detecting manufacturing points whereas decreasing incident response occasions by 83%.
On this publish, we discover how you can construct a scalable and cost-effective log evaluation system utilizing Amazon Bedrock to rework reactive log monitoring into proactive subject detection. We talk about how Amazon Bedrock, by means of Anthropic’ s Claude Haiku mannequin, and Amazon Titan Textual content Embeddings work collectively to mechanically classify and analyze log information. We discover how this automated pipeline detects important points, study the answer structure, and share implementation insights which have delivered measurable operational enhancements.
Palo Alto Networks affords Cloud-Delivered Safety Companies (CDSS) to deal with machine safety dangers. Their answer makes use of machine studying and automatic discovery to offer visibility into linked gadgets, implementing Zero Belief rules. Groups going through related log evaluation challenges can discover sensible insights on this implementation.
Resolution overview
Palo Alto Networks’ automated log classification system helps their Gadget Safety staff detect and reply to potential service failures forward of time. The answer processes over 200 million service and utility logs each day, mechanically figuring out important points earlier than they escalate into service outages that affect clients.
The system makes use of Amazon Bedrock with Anthropic’s Claude Haiku mannequin to grasp log patterns and classify severity ranges, and Amazon Titan Textual content Embeddings allows clever similarity matching. Amazon Aurora gives a caching layer that makes processing large log volumes possible in actual time. The answer integrates seamlessly with Palo Alto Networks’ current infrastructure, serving to the Gadget Safety staff concentrate on stopping outages as an alternative of managing complicated log evaluation processes.
Palo Alto Networks and the AWS GenAIIC collaborated to construct an answer with the next capabilities:
- Clever deduplication and caching – The system scales by intelligently figuring out duplicate log entries for a similar code occasion. Reasonably than utilizing a big language mannequin (LLM) to categorise each log individually, the system first identifies duplicates by means of actual matching, then makes use of overlap similarity, and eventually employs semantic similarity provided that no earlier match is discovered. This method cost-effectively reduces the 200 million each day logs by over 99%, to logs solely representing distinctive occasions. The caching layer allows real-time processing by decreasing the necessity for redundant LLM invocations.
- Context retrieval for distinctive logs – For distinctive logs, Anthropic’s Claude Haiku mannequin utilizing Amazon Bedrock classifies every log’s severity. The mannequin processes the incoming log together with related labeled historic examples. The examples are dynamically retrieved at inference time by means of vector similarity search. Over time, labeled examples are added to offer wealthy context to the LLM for classification. This context-aware method improves accuracy for Palo Alto Networks’ inner logs and programs and evolving log patterns that conventional rule-based programs battle to deal with.
- Classification with Amazon Bedrock – The answer gives structured predictions, together with severity classification (Precedence 1 (P1), Precedence 2 (P2), Precedence 3 (P3)) and detailed reasoning for every determination. This complete output helps Palo Alto Networks’ SMEs rapidly prioritize responses and take preventive motion earlier than potential outages happen.
- Integration with current pipelines for motion – Outcomes combine with their current FluentD and Kafka pipeline, with information flowing to Amazon Easy Storage Service (Amazon S3) and Amazon Redshift for additional evaluation and reporting.
The next diagram (Determine 1) illustrates how the three-stage pipeline processes Palo Alto Networks’ 200 million each day log quantity whereas balancing scale, accuracy, and cost-efficiency. The structure consists of the next key parts:
- Knowledge ingestion layer – FluentD and Kafka pipeline and incoming logs
- Processing pipeline – Consisting of the next phases:
- Stage 1: Good caching and deduplication – Aurora for actual matching and Amazon Titan Textual content Embeddings for semantic matching
- Stage 2: Context retrieval – Amazon Titan Textual content Embeddings to allow historic labeled examples, and vector similarity search
- Stage 3: Classification – Anthropic’s Claude Haiku mannequin for severity classification (P1/P2/P3)
- Output layer – Aurora, Amazon S3, Amazon Redshift, and SME assessment interface
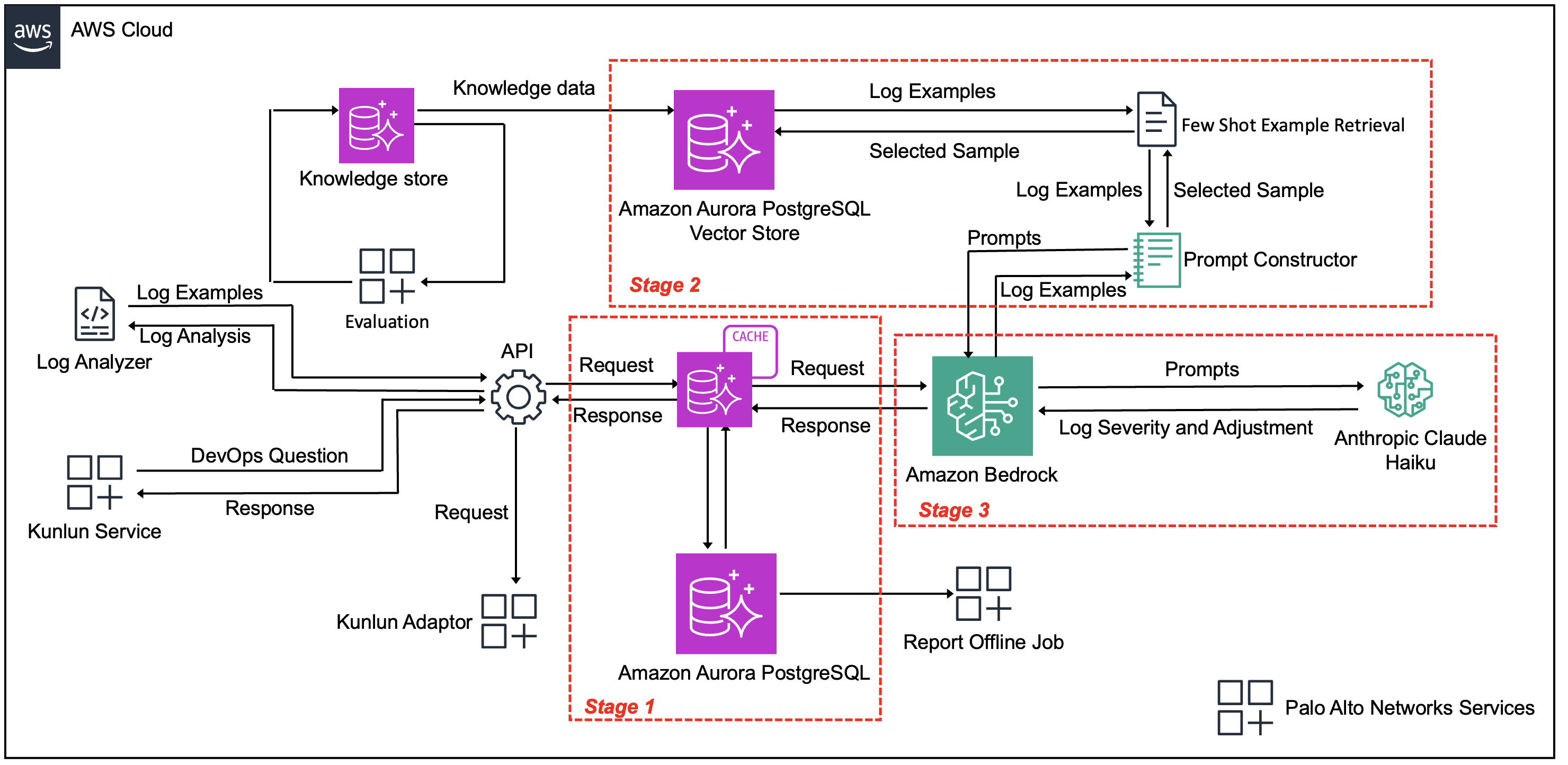
Determine 1: Automated log classification system structure
The processing workflow strikes by means of the next phases:
- Stage 1: Good caching and deduplication – Incoming logs from Palo Alto Networks’ FluentD and Kafka pipeline are instantly processed by means of an Aurora primarily based caching layer. The system first applies actual matching, then falls again to overlap similarity, and eventually makes use of semantic similarity by means of Amazon Titan Textual content Embeddings if no earlier match is discovered. Throughout testing, this method recognized that greater than 99% of logs corresponded to duplicate occasions, though they contained totally different time stamps, log ranges, and phrasing. The caching system lowered response occasions for cached outcomes and lowered pointless LLM processing.
- Stage 2: Context retrieval for distinctive logs – The remaining lower than 1% of really distinctive logs require classification. For these entries, the system makes use of Amazon Titan Textual content Embeddings to establish probably the most related historic examples from Palo Alto Networks’ labeled dataset. Reasonably than utilizing static examples, this dynamic retrieval makes positive every log receives contextually applicable steering for classification.
- Stage 3: Classification with Amazon Bedrock – Distinctive logs and their chosen examples are processed by Amazon Bedrock utilizing Anthropic’s Claude Haiku mannequin. The mannequin analyzes the log content material alongside related historic examples to provide severity classifications (P1, P2, P3) and detailed explanations. Outcomes are saved in Aurora and the cache and built-in into Palo Alto Networks’ current information pipeline for SME assessment and motion.
This structure allows cost-effective processing of large log volumes whereas sustaining 95% precision for important P1 severity detection. The system makes use of fastidiously crafted prompts that mix area experience with dynamically chosen examples:
system_prompt = """
You might be an professional log evaluation system liable for classifying manufacturing system logs primarily based on severity. Your evaluation helps engineering groups prioritize their response to system points and keep service reliability.
P1 (Essential): Requires fast motion - system-wide outages, repeated utility crashes
P2 (Excessive): Warrants consideration throughout enterprise hours - efficiency points, partial service disruption
P3 (Low): May be addressed when sources accessible - minor bugs, authorization failures, intermittent community points
2024-08-17 01:15:00.00 [warn] failed (104: Connection reset by peer) whereas studying response header from upstream
severity: P3
class: Class A
2024-08-18 17:40:00.00 Error: Request failed with standing code 500 at settle
severity: P2
class: Class B
Log: {incoming_log_snippet}
Location: {system_location}
"""
Present severity classification (P1/P2/P3) and detailed reasoning.Implementation insights
The core worth of Palo Alto Networks’ answer lies in making an insurmountable problem manageable: AI helps their staff analyze 200 million of each day volumes effectively, whereas the system’s dynamic adaptability makes it potential to increase the answer into the long run by including extra labeled examples. Palo Alto Networks’ profitable implementation of their automated log classification system yielded key insights that may assist organizations constructing production-scale AI options:
- Steady studying programs ship compounding worth – Palo Alto Networks designed their system to enhance mechanically as SMEs validate classifications and label new examples. Every validated classification turns into a part of the dynamic few-shot retrieval dataset, enhancing accuracy for related future logs whereas rising cache hit charges. This method creates a cycle the place operational use enhances system efficiency and reduces prices.
- Clever caching allows AI at manufacturing scale – The multi-layered caching structure processes greater than 99% of logs by means of cache hits, reworking costly per-log LLM operations into an economical system able to dealing with 200 million each day volumes. This basis makes AI processing economically viable at enterprise scale whereas sustaining response occasions.
- Adaptive programs deal with evolving necessities with out code adjustments – The answer accommodates new log classes and patterns with out requiring system modifications. When efficiency wants enchancment for novel log sorts, SMEs can label extra examples, and the dynamic few-shot retrieval mechanically incorporates this data into future classifications. This adaptability permits the system to scale with enterprise wants.
- Explainable classifications drive operational confidence – SMEs responding to important alerts require confidence in AI suggestions, notably for P1 severity classifications. By offering detailed reasoning alongside every classification, Palo Alto Networks allows SMEs to rapidly validate selections and take applicable motion. Clear explanations rework AI outputs from predictions into actionable intelligence.
These insights show how AI programs designed for steady studying and explainability grow to be more and more worthwhile operational belongings.
Conclusion
Palo Alto Networks’ automated log classification system demonstrates how generative AI powered by AWS helps operational groups handle huge volumes in actual time. On this publish, we explored how an structure combining Amazon Bedrock, Amazon Titan Textual content Embeddings, and Aurora processes 200 million of each day logs by means of clever caching and dynamic few-shot studying, enabling proactive detection of important points with 95% precision. Palo Alto Networks’ automated log classification system delivered concrete operational enhancements:
- 95% precision, 90% recall for P1 severity logs – Essential alerts are correct and actionable, minimizing false alarms whereas catching 9 out of 10 pressing points, leaving the remaining alerts to be captured by current monitoring programs
- 83% discount in debugging time – SMEs spend much less time on routine log evaluation and extra time on strategic enhancements
- Over 99% cache hit price – The clever caching layer processes 20 million each day quantity cost-effectively by means of subsecond responses
- Proactive subject detection – The system identifies potential issues earlier than they affect clients, stopping the multi-week outages that beforehand disrupted service
- Steady enchancment – Every SME validation mechanically improves future classifications and will increase cache effectivity, leading to lowered prices
For organizations evaluating AI initiatives for log evaluation and operational monitoring, Palo Alto Networks’ implementation affords a blueprint for constructing production-scale programs that ship measurable enhancements in operational effectivity and price discount. To construct your individual generative AI options, discover Amazon Bedrock for managed entry to basis fashions. For extra steering, try the AWS Machine Studying sources and browse implementation examples within the AWS Synthetic Intelligence Weblog.
The collaboration between Palo Alto Networks and the AWS GenAIIC demonstrates how considerate AI implementation can rework reactive operations into proactive, scalable programs that ship sustained enterprise worth.
To get began with Amazon Bedrock, see Construct generative AI options with Amazon Bedrock.
Concerning the authors

Rizwan Mushtaq
Rizwan is a Principal Options Architect at AWS. He helps clients design revolutionary, resilient, and cost-effective options utilizing AWS companies. He holds an MS in Electrical Engineering from Wichita State College.

Hector Lopez
Hector Lopez, PhD is an Utilized Scientist in AWS’s Generative AI Innovation Middle, the place he focuses on delivering production-ready generative AI options and proof-of-concepts throughout numerous business purposes. His experience spans conventional machine studying and information science in life and bodily sciences. Hector implements a first-principles method to buyer options, working backwards from core enterprise wants to assist organizations perceive and leverage generative AI instruments for significant enterprise transformation.

Meena Menon
Meena Menon is a Sr. Buyer Success Supervisor at AWS with over 20 years of expertise delivering enterprise buyer outcomes and digital transformation. At AWS, she companions with strategic ISVs together with Palo Alto Networks, Proofpoint, New Relic, and Splunk to speed up cloud modernization and migrations.

Fan Zhang
Fan is a Senior Principal Engineer/Architect at Palo Alto Networks, main the IoT Safety staff’s infrastructure and information pipeline, in addition to its generative AI infrastructure.



{kind=link}