AI-powered apps and AI-powered service supply are key differentiators within the enterprise area right this moment. A generative AI-based useful resource can tremendously cut back the onboarding time for brand new staff, improve enterprise search, help in drafting content material, test for compliance, perceive the authorized language of knowledge, and extra.
Generative AI purposes are an rising and sought-after answer within the enterprise world for buyer care facilities, buyer relationship administration facilities, and assist desks.
Infosys Topaz, an AI-first providing that accelerates enterprise worth for enterprises utilizing generative AI, is integrating AWS generative AI capabilities to future proof enterprise AI options together with Infosys Cortex, Infosys Personalised Sensible Video (PSV), Infosys Conversational AI Suite, Infosys Stay Enterprise Automation Platform (LEAP), and Infosys Cyber Subsequent.
On this publish, we study the use case of a big vitality provider whose technical assist desk help brokers reply buyer calls and help meter technicians within the discipline. We use Amazon Bedrock, together with capabilities from Infosys Topaz, to construct a generative AI utility that may cut back name dealing with instances, automate duties, and enhance the general high quality of technical help.
Enterprise challenges
Meter technicians go to buyer areas to put in, trade, service, and restore meters. Generally they name help brokers from the technical assist desk to get steering and help to repair points that they will’t repair by themselves. The approximate quantity of those calls is 5,000 per week, roughly 20,000 monthly.
Among the challenges confronted by help brokers and meter technicians embrace:
- Finding the suitable data or sources to handle inquiries or issues successfully.
- The common dealing with time for these calls varies primarily based on the difficulty class, however calls within the prime 10 classes, which characterize over 60% of calls, are over 5 minutes.
- 60–70% points are repetitive, and the remainder are new points.
Sustaining an enough workforce to offer immediate responses may be pricey. It’s costly and never scalable to rent extra help brokers and prepare them with the information wanted to offer help. We constructed an AI-powered technical assist desk that may ingest previous name transcripts and new name transcripts in close to actual time. This can assist help brokers present resolutions primarily based on previous calls, thereby decreasing handbook search time to allow them to attend to different priorities.
Answer overview
The answer entails making a information base by ingesting and processing name transcripts, in order that the AI assistant can present resolutions primarily based on historical past. The advantages of an AI-powered technical assist desk embrace:
- Offering all-day availability
- Saving effort for the assistance desk brokers
- Permitting companies to deal with new points
- Lowering wait time and shortening name period
- Automating actions that the assistance desk brokers tackle the backend primarily based on their evaluation of the difficulty
- Enhancing the standard of technical assist desk responses, and thereby communication and outcomes
This publish showcases the implementation particulars, together with user-based entry controls, caching mechanisms for environment friendly FAQ retrieval and updates, person metrics monitoring, and response technology with time-tracking capabilities.
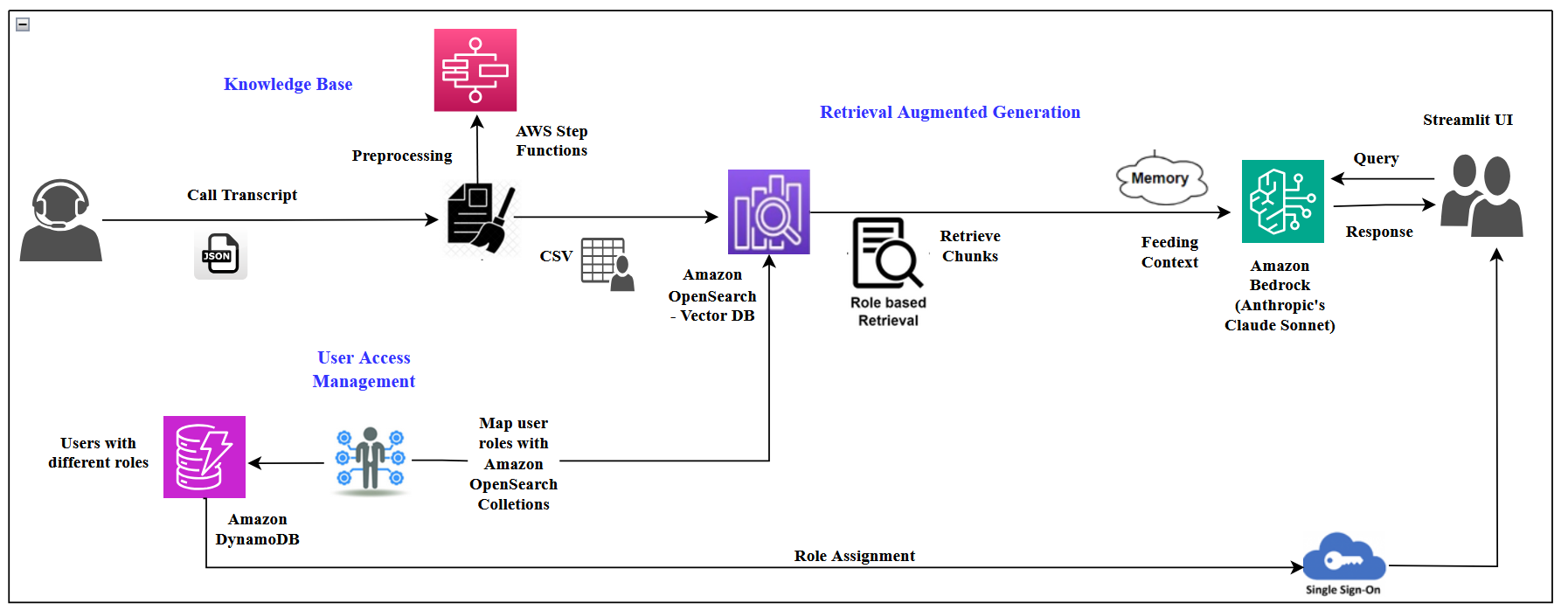
The next diagram exhibits the circulation of knowledge and processes from left to proper, beginning with name transcripts, going via preprocessing, storage, and retrieval, and ending with person interplay and response technology. It emphasizes the role-based entry management all through the system.
We used Amazon Bedrock as a result of it integrates seamlessly with different AWS companies proven within the diagram, akin to AWS Step Capabilities, Amazon DynamoDB, and Amazon OpenSearch Service. This integration improves knowledge circulation and administration inside a single cloud system.
Constructing the information base: Knowledge circulation
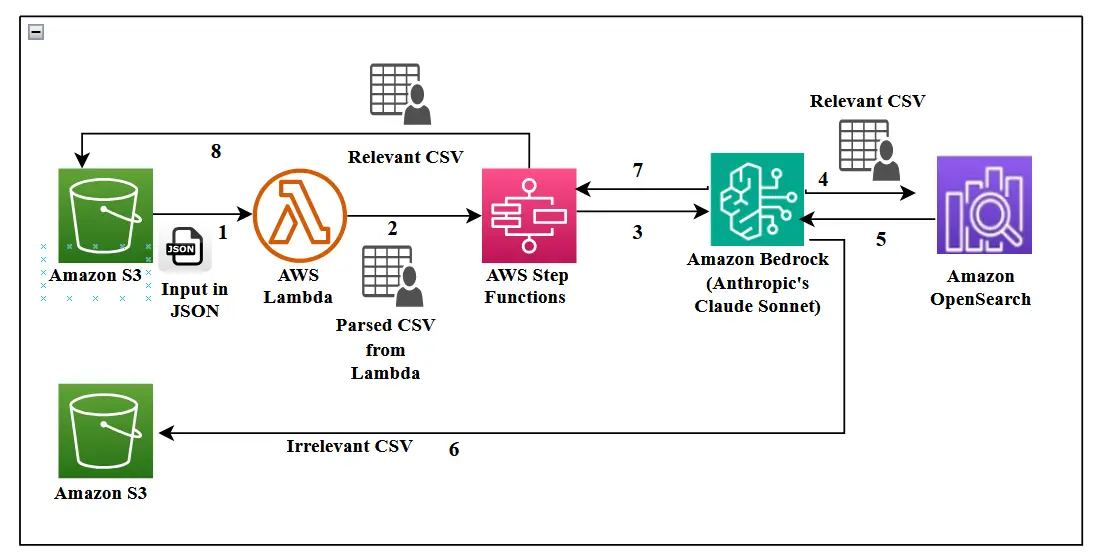
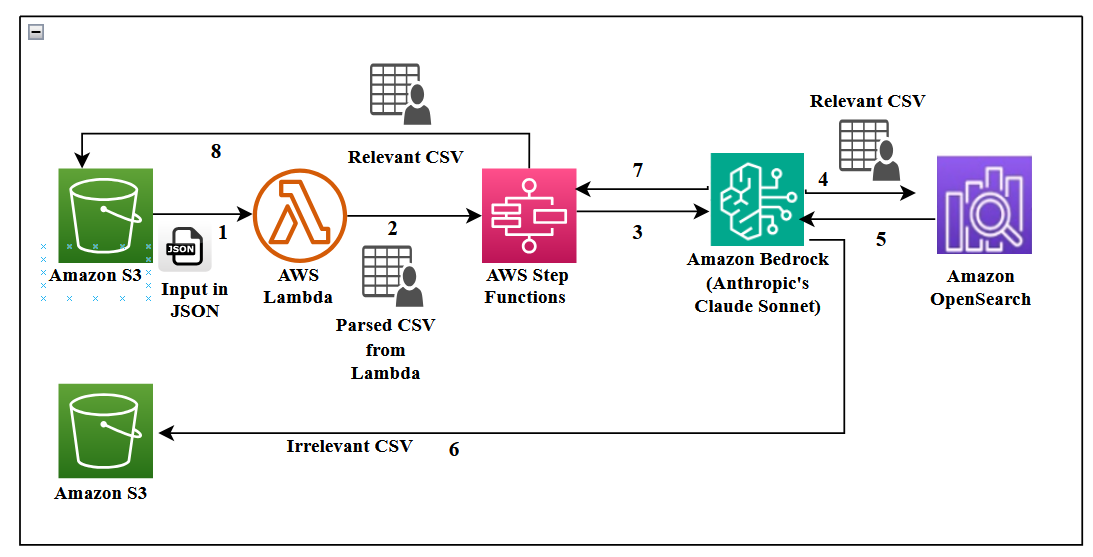
Calls to the technical assist desk are recorded for high quality and evaluation functions, and the transcripts are saved in JSON format in an AWS Easy Storage Service (Amazon S3) bucket.
The conversations are parsed right into a CSV file for sorting and a big language mannequin (LLM), akin to Anthropic’s Claude Sonnet on Amazon Bedrock, is used to summarize the dialog and decide if the context has helpful data, primarily based on the size of the decision, key phrases that point out related context, and so forth.
The shortlisted conversations are chunked, and embeddings are generated and saved in an Amazon OpenSearch Serverless vector retailer. The conversations decided to be irrelevant go into one other S3 bucket for future reference. This course of is automated, as proven within the following determine.
A digital assistant is then constructed on prime of the information base that may help the help agent.
The conversations are parsed right into a CSV file for easy sorting and an LLM akin to Anthropic’s Claude Sonnet on Amazon Bedrock is used to summarize the dialog and decide if the context has helpful data, primarily based on the size of the decision, key phrases that point out related context, and so forth.
An event-driven AWS Lambda operate is triggered when new name transcripts are loaded into the S3 bucket. This can set off a Step Capabilities workflow.
From the uncooked CSV file of name transcripts, just a few fields are extracted: a contact ID that’s distinctive for a specific name session between a buyer and a help agent, the participant column indicating the speaker (who may be both a help agent or a buyer) and the content material column, which is the dialog.
To construct the information base, we used Step Capabilities to ingest the uncooked CSV information, as proven within the following workflow.
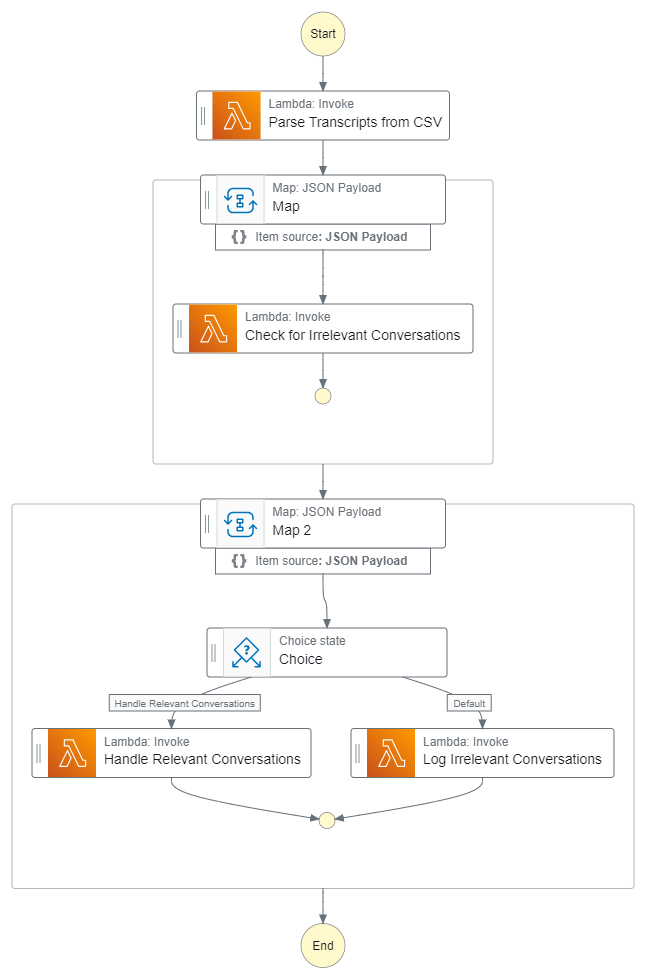
The automated workflow begins when a person uploads the JSON file to an S3 bucket.
- The Step Capabilities workflow receives the Amazon S3 URL of the CSV transcripts from a Lambda operate. The
contactidis exclusive for a specific name session between the shopper and the agent, who’re the contributors, and thecontent materialis the precise dialog. - The Lambda operate (Parse Transcripts from CSV) makes use of this Amazon S3 URL to obtain the CSV information and makes use of Pandas to preprocess the CSV in a format with the contact ID and transcript solely. Conversations with the identical contact ID are concatenated right into a single row.
- The second step is a classification activity that ingests, classifies, and retains or discards conversions. The conversations are handed to the map state. In map state, conversations are dealt with concurrently. For every dialog row, this state triggers concurrent execution of one other Lambda operate (Test for Irrelevant Conversations) that may classify every dialog as related or irrelevant.
- For this classification activity, the Lambda operate makes use of Anthropic’s Claude Sonnet mannequin on Amazon Bedrock. It makes use of zero-shot chain-of-thought prompting, to first summarize the dialog after which to find out the relevance. If the dialog is disconnected or disjointed (due to sign disturbances or different causes), or has no significant context (when the agent is unable to offer decision), it’s categorised as irrelevant.
- Lastly, the map state takes every occasion of the dialog (categorised as related or irrelevant) and passes to the selection state, which is able to log the irrelevant conversations into an S3 bucket and related conversations are handed to a different Lambda operate (Deal with Related Conversations) for additional processing.
- The ultimate Lambda operate (Log Irrelevant Conversations) reads the related conversations and generates the abstract, downside, and determination steps utilizing Anthropic’s Claude Sonnet. The abstract generated is used for creating the abstract embeddings.
The next is an instance of an irrelevant dialog that’s discarded.
| Contactid | Participant | Content material |
66da378c-8d74-467b-86ca-7534158b63c2 |
AGENT | Assist the college talking |
66da378c-8d74-467b-86ca-7534158b63c2 |
CUSTOMER | Your morning name it mentioned Chris Simpson close to me, TX 75 is, uh, locked out spinning disc |
66da378c-8d74-467b-86ca-7534158b63c2 |
AGENT | No downside. What’s your carry, please? |
66da378c-8d74-467b-86ca-7534158b63c2 |
CUSTOMER | Because of see 27492. |
66da378c-8d74-467b-86ca-7534158b63c2 |
AGENT | Thanks. Proper, you’ll be kicked off. |
66da378c-8d74-467b-86ca-7534158b63c2 |
AGENT | Single noise. Something anyway, mate. If you look again in, you’ll be nice |
66da378c-8d74-467b-86ca-7534158b63c2 |
CUSTOMER | Yep. |
66da378c-8d74-467b-86ca-7534158b63c2 |
CUSTOMER | Alright, Proper. Thanks. Select them. |
66da378c-8d74-467b-86ca-7534158b63c2 |
AGENT | I believe she’s made a bit Proper bye. |
The next is an instance of a related dialog.
| Contactid | Participant | Content material |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
CUSTOMER | Hi there. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
AGENT | Assist these gathers Reagan. Sure. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
CUSTOMER | Stand up, after which I’ll converse to somebody about clearing the money on my T C 75. So, can do. Off job definitely issues since you received’t let me sorry minutes, simply saying Couldn’t set up community connection. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
CUSTOMER | Yeah, I’ve bought a sign. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
AGENT | Yeah, it’s not attempting to do is related. We bought three D 14. It’s up, proper? |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
CUSTOMER | What ought to occur as a result of I’m within the 4 G space. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
AGENT | Yeah, dragged down the display twice from the highest for me. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
CUSTOMER | Yep. He? Yeah. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
AGENT | Yep. And test that survey is eight hasn’t turned itself off. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
CUSTOMER | Want. Okay, strive once more. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
AGENT | There you go, proper exhibiting us related. We will |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
CUSTOMER | All proper. Are you able to clear the cat 12 can sign is day to see this message. Contact the T. H. D. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
AGENT | Yep. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
AGENT | There you go. That ought to take you out any second, okay? |
The next desk exhibits the ultimate information base schema.
| k_id | conversation_history | Abstract | Downside | resolution_steps | summary_embeddings |
| 1 | AGENT: Hello, how can I show you how to CUSTOMER: Hello, I’m going through a black display situation.… | Buyer is going through with a situation … | Black Display screen situation |
… |
[0.5078125,-0.071777344,0.15722656,0.46679688,0.56640625,-0.037353516,-0.08544922,0.00012588501, …] |
Constructing an efficient RAG pipeline
The success of retrieval methods depends on an efficient embedding mannequin. The Amazon Titan Textual content Embeddings mannequin is optimized for textual content retrieval to allow Retrieval Augmented Technology (RAG). As an alternative of processing huge paperwork on the similar time, we used chunking methods to enhance retrieval. We used a piece measurement of 1,000 with an overlapping window of 150–200 for finest outcomes. Chunking mixed with web page boundaries is an easy but extremely efficient strategy. Sentence window retrieval additionally returns correct outcomes.
Prompting strategies play a vital function in acquiring efficient outcomes. For instance, as an alternative of “pointers for sensible meter set up,” an expanded immediate akin to “directions, procedures, laws, and finest practices together with agent experiences for set up of a wise meter” yields higher outcomes.
Constructing production-ready RAG purposes requires a performant vector database as nicely. The vector engine for OpenSearch Serverless offers a scalable and high-performing vector storage and search functionality; key options embrace including, updating, and deleting vector embeddings in close to actual time with out impacting question efficiency. See Construct a contextual chatbot utility utilizing Amazon Bedrock Data Bases for extra data.
Safety issues
This structure implements complete safety measures throughout the parts. We use AWS Secrets and techniques Supervisor to securely retailer and handle delicate credentials, API keys, and database passwords, with computerized rotation insurance policies in place. S3 buckets are encrypted utilizing AWS Key Administration Service (AWS KMS) with AES-256 encryption, and versioning is enabled for audit functions. Personally identifiable data (PII) is dealt with with excessive care— PII knowledge is encrypted and entry is strictly managed via AWS Id and Entry Administration (IAM) insurance policies and AWS KMS. For OpenSearch Serverless implementation, we ensure knowledge is encrypted each at relaxation utilizing AWS KMS and in transit utilizing TLS 1.2. Session administration consists of timeout for inactive periods, requiring re-authentication for continued entry. The system interacts with entry management checklist (ACL) knowledge saved in DynamoDB via a safe middleware layer, the place the DynamoDB desk is encrypted at relaxation utilizing AWS managed KMS keys. Knowledge transmissions between companies are encrypted in transit utilizing TLS 1.2, and we keep end-to-end encryption throughout our complete infrastructure. Entry controls are granularly outlined and repeatedly audited via AWS CloudTrail.
Implementing role-based entry management
We used three totally different personas to implement role-based entry management: an administrator with full entry, a technical desk analyst with a medium degree of entry, and a technical agent with minimal entry. We used OpenSearch Serverless collections to handle totally different entry ranges. Completely different name transcripts are ingested into totally different collections; that is to allow person entry to the content material they’re licensed to primarily based on their roles. A listing of person IDs and their roles and allowed entry are saved in a DynamoDB desk together with the OpenSearch assortment and index identify.
We used the authenticate.login methodology in a Streamlit authenticator to retrieve the person ID.
Consumer interface and agent expertise
We used Streamlit as a frontend framework to construct the TECHNICAL HELP DESK, with entry to the content material managed by the person’s function. The UI options an FAQ part displayed on the prime of the principle web page and a search metrics insights part within the sidebar, as proven within the following screenshot.
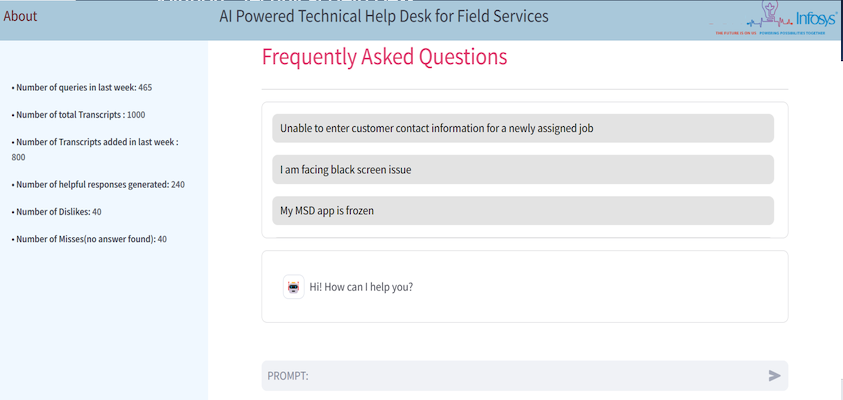
The UI consists of the next parts:
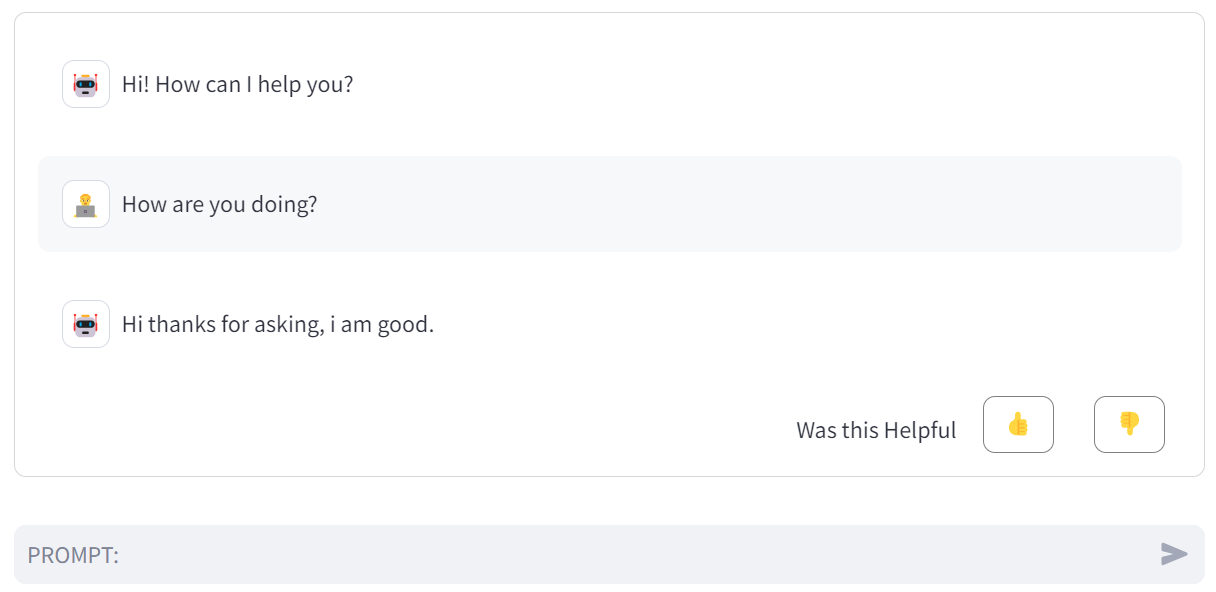
- Dialog part – The dialog part comprises interactions between the person and the assistance desk assistant. Customers can present suggestions by selecting both the like or dislike button for every response obtained, as proven within the following screenshot. This suggestions is endured in a DynamoDB desk.
- Consumer metrics insights – As proven within the following screenshot, the sidebar comprises metrics data, together with:
- Variety of queries within the final week
- Variety of complete transcripts
- Variety of transcripts added within the final week
- Variety of useful responses generated
- Variety of dislikes
- Variety of misses (no reply discovered)

These fields are up to date asynchronously after every person question. Extra metrics are additionally saved, akin to sentiment, tone of the audio system, nature of responses generated, and satisfaction proportion.
- FAQ – The queries are saved in a DynamoDB desk together with a question rely column. When the assistance desk agent indicators in, the queries with essentially the most counts are displayed on this part, as proven within the following desk.
| Partition key | Kind key | International secondary index |
| Doc identify | Questions | Counter |
| Microsoft Authenticator | Overview of MFA | 1 |
| What’s TAP in MFA | 2 | |
| Frequent points in MFA | 1 |
The Counter column is created as the worldwide secondary index to retrieve the highest 5 FAQs.
After the person submits a question, the technical assist desk fetches the highest related gadgets from the information base. That is in contrast with the person’s question and, when a match is discovered, the Counter column is incremented.
Cache administration
We used the st.cache_data() operate in Streamlit to retailer the legitimate ends in reminiscence. The outcomes are endured throughout the person periods.
The caching operate employs an inner hashing mechanism that may be overridden if required. The cached knowledge may be saved both in reminiscence or on disk. Moreover, we are able to set the info persistence period as wanted for the use case. Cache invalidation or updates may be carried out when the info adjustments or after each hour. This, together with the FAQ part, has considerably enhanced efficiency of the technical assist desk, creating sooner response instances and bettering the person expertise for purchasers and help brokers.
Conclusion
On this publish, we confirmed you ways we constructed a generative AI utility to considerably cut back name dealing with instances, automate repetitive duties, and enhance the general high quality of technical help.
The enterprise AI assistant from the Infosys Agentic Foundry, a part of Infosys Topaz, now handles 70% of the beforehand human-managed calls. For the highest 10 situation classes, common dealing with time has decreased from over 5 minutes to below 2 minutes, a 60% enchancment. The continual enlargement of the information base has decreased the proportion of points requiring human intervention from 30–40% to twenty% throughout the first 6 months after deployment.
Put up-implementation surveys present a 30% improve in buyer satisfaction scores associated to technical help interactions.
To study extra about different options constructed with Amazon Bedrock and Infosys Topaz, see Create a multimodal assistant with superior RAG and Amazon Bedrock and Infosys Topaz Unlocks Insights with Superior RAG Processing for Oil & Gasoline Drilling Knowledge.
Concerning the authors
 Meenakshi Venkatesan is a Principal Marketing consultant at Infosys and part of the AWS Centre Of Excellence at Infosys Topaz. She helps design, develop, and deploy options in AWS environments and has pursuits in exploring the brand new choices and companies.
Meenakshi Venkatesan is a Principal Marketing consultant at Infosys and part of the AWS Centre Of Excellence at Infosys Topaz. She helps design, develop, and deploy options in AWS environments and has pursuits in exploring the brand new choices and companies.
 Karthikeyan Senthilkumar is a Senior Programs Engineer at Infosys and part of the AWS COE at iCETS. He makes a speciality of AWS generative AI and database companies.
Karthikeyan Senthilkumar is a Senior Programs Engineer at Infosys and part of the AWS COE at iCETS. He makes a speciality of AWS generative AI and database companies.
 Aninda Chakraborty is a Senior Programs Engineer at Infosys and part of the AWS COE at iCETS. He makes a speciality of generative AI and is obsessed with leveraging expertise to create progressive options that drive progress on this discipline.
Aninda Chakraborty is a Senior Programs Engineer at Infosys and part of the AWS COE at iCETS. He makes a speciality of generative AI and is obsessed with leveraging expertise to create progressive options that drive progress on this discipline.
 Ashutosh Dubey is an completed software program technologist and Technical Chief at Amazon Net Providers, the place he makes a speciality of Generative AI options structure. With a wealthy background in software program improvement and knowledge engineering, he architects enterprise-scale AI options that bridge innovation with sensible implementation. A revered voice within the tech neighborhood, he repeatedly contributes to business discourse via talking engagements and thought management on Generative AI purposes, Knowledge engineering, and moral AI practices.
Ashutosh Dubey is an completed software program technologist and Technical Chief at Amazon Net Providers, the place he makes a speciality of Generative AI options structure. With a wealthy background in software program improvement and knowledge engineering, he architects enterprise-scale AI options that bridge innovation with sensible implementation. A revered voice within the tech neighborhood, he repeatedly contributes to business discourse via talking engagements and thought management on Generative AI purposes, Knowledge engineering, and moral AI practices.
 Vishal Srivastava is a Senior Options Architect with a deep specialization in Generative AI. In his present function, he collaborates intently with NAMER System Integrator (SI) companions, offering skilled steering to architect enterprise-scale AI options. Vishal’s experience lies in navigating the advanced panorama of AI applied sciences and translating them into sensible, high-impact implementations for companies. As a thought chief within the AI area, Vishal is actively engaged in shaping business conversations and sharing information. He’s a frequent speaker at public occasions, webinars, and conferences, the place he affords insights into the most recent tendencies and finest practices in Generative AI.
Vishal Srivastava is a Senior Options Architect with a deep specialization in Generative AI. In his present function, he collaborates intently with NAMER System Integrator (SI) companions, offering skilled steering to architect enterprise-scale AI options. Vishal’s experience lies in navigating the advanced panorama of AI applied sciences and translating them into sensible, high-impact implementations for companies. As a thought chief within the AI area, Vishal is actively engaged in shaping business conversations and sharing information. He’s a frequent speaker at public occasions, webinars, and conferences, the place he affords insights into the most recent tendencies and finest practices in Generative AI.
 Dhiraj Thakur is a Options Architect with Amazon Net Providers, specializing in Generative AI and knowledge analytics domains. He works with AWS prospects and companions to architect and implement scalable analytics platforms and AI-driven options. With deep experience in Generative AI companies and implementation, end-to-end machine studying implementation, and cloud-native knowledge architectures, he helps organizations harness the facility of GenAI and analytics to drive enterprise transformation. He may be reached by way of LinkedIn.
Dhiraj Thakur is a Options Architect with Amazon Net Providers, specializing in Generative AI and knowledge analytics domains. He works with AWS prospects and companions to architect and implement scalable analytics platforms and AI-driven options. With deep experience in Generative AI companies and implementation, end-to-end machine studying implementation, and cloud-native knowledge architectures, he helps organizations harness the facility of GenAI and analytics to drive enterprise transformation. He may be reached by way of LinkedIn.



{kind=link}