This put up is co-written with David Gildea and Tom Nijs from Druva.
Druva is a number one supplier of information safety options, and is trusted by over 6,000 clients, together with 65 of the Fortune 500. Clients use the Druva Knowledge Safety Cloud, a completely managed SaaS answer, to safe and get better knowledge from all threats. Unbiased software program distributors (ISVs) like Druva are integrating AI assistants into their options to make software program extra accessible.
Dru, the Druva backup AI copilot, allows real-time interplay and personalised responses, with customers partaking in a pure dialog with the software program. From discovering inconsistencies and errors throughout the setting to scheduling backup jobs and setting retention insurance policies, customers want solely ask and Dru responds. Dru can even suggest actions to enhance the setting, treatment backup failures, and establish alternatives to boost safety.
On this put up, we present how Druva approached pure language querying (NLQ)—asking questions in English and getting tabular knowledge as solutions—utilizing Amazon Bedrock, the challenges they confronted, pattern prompts, and key learnings.
Use case overview
The next screenshot illustrates the Dru dialog interface.

In a single dialog interface, Dru gives the next:
- Interactive reporting with real-time insights – Customers can request knowledge or custom-made stories with out in depth looking or navigating via a number of screens. Dru additionally suggests follow-up questions to boost person expertise.
- Clever responses and a direct conduit to Druva’s documentation – Customers can achieve in-depth information about product options and functionalities with out guide searches or watching coaching movies. Dru additionally suggests sources for additional studying.
- Assisted troubleshooting – Customers can request summaries of prime failure causes and obtain advised corrective measures. Dru on the backend decodes log knowledge, deciphers error codes, and invokes API calls to troubleshoot.
- Simplified admin operations, with elevated seamlessness and accessibility – Customers can carry out duties like creating a brand new backup coverage or triggering a backup, managed by Druva’s current role-based entry management (RBAC) mechanism.
- Custom-made web site navigation via conversational instructions – Customers can instruct Dru to navigate to particular web site places, eliminating the necessity for guide menu exploration. Dru additionally suggests follow-up actions to hurry up process completion.
Challenges and key learnings
On this part, we talk about the challenges and key learnings of Druva’s journey.
General orchestration
Initially, we adopted an AI agent strategy and relied on the muse mannequin (FM) to make plans and invoke instruments utilizing the reasoning and appearing (ReAct) technique to reply person questions. Nevertheless, we discovered the target too broad and complex for the AI agent. The AI agent would take greater than 60 seconds to plan and reply to a person query. Generally it will even get caught in a thought-loop, and the general success price wasn’t passable.
We determined to maneuver to the immediate chaining strategy utilizing a directed acyclic graph (DAG). This strategy allowed us to interrupt the issue down into a number of steps:
- Establish the API route.
- Generate and invoke non-public API calls.
- Generate and run knowledge transformation Python code.
Every step turned an impartial stream, so our engineers may iteratively develop and consider the efficiency and pace till they labored effectively in isolation. The workflow additionally turned extra controllable by defining correct error paths.
Stream 1: Establish the API route
Out of the tons of of APIs that energy Druva merchandise, we would have liked to match the precise API the appliance must name to reply the person query. For instance, “Present me my backup failures for the previous 72 hours, grouped by server.” Having comparable names and synonyms in API routes make this retrieval drawback extra advanced.
Initially, we formulated this process as a retrieval drawback. We tried totally different strategies, together with k-nearest neighbor (k-NN) search of vector embeddings, BM25 with synonyms, and a hybrid of each throughout fields together with API routes, descriptions, and hypothetical questions. We discovered that the best and most correct means was to formulate it as a classification process to the FM. We curated a small listing of examples in question-API route pairs, which helped enhance the accuracy and make the output format extra constant.
Stream 2: Generate and invoke non-public API calls
Subsequent, we API name with the proper parameters and invoke it. FM hallucination of parameters, significantly these with free-form JSON object, is without doubt one of the main challenges in the entire workflow. For instance, the unsupported key server can seem within the generated parameter:
We tried totally different prompting methods, corresponding to few-shot prompting and chain of thought (CoT), however the success price was nonetheless unsatisfactory. To make API name era and invocation extra sturdy, we separated this process into two steps:
- First, we used an FM to generate parameters in a JSON dictionary as a substitute of a full API request headers and physique.
- Afterwards, we wrote a postprocessing perform to take away parameters that didn’t conform to the API schema.
This technique supplied a profitable API invocation, on the expense of getting extra knowledge than required for downstream processing.
Stream 3: Generate and run knowledge transformation Python code
Subsequent, we took the response from the API name and reworked it to reply the person query. For instance, “Create a pandas dataframe and group it by server column.” Just like stream 2, FM hallucination is once more an impediment. Generated code can include syntax errors, corresponding to complicated PySpark features with Pandas features.
After attempting many various prompting methods with out success, we seemed on the reflection sample, asking the FM to self-correct code in a loop. This improved the success price on the expense of extra FM invocations, which had been slower and dearer. We discovered that though smaller fashions are quicker and cheaper, at occasions they’d inconsistent outcomes. Anthropic’s Claude 2.1 on Amazon Bedrock gave extra correct outcomes on the second attempt.
Mannequin selections
Druva chosen Amazon Bedrock for a number of compelling causes, with safety and latency being crucial. A key issue on this choice was the seamless integration with Druva’s companies. Utilizing Amazon Bedrock aligned naturally with Druva’s current setting on AWS, sustaining a safe and environment friendly extension of their capabilities.
Moreover, one in all our major challenges in creating Dru concerned deciding on the optimum FMs for particular duties. Amazon Bedrock successfully addresses this problem with its in depth array of obtainable FMs, every providing distinctive capabilities. This selection enabled Druva to conduct the speedy and complete testing of assorted FMs and their parameters, facilitating the collection of probably the most appropriate one. The method was streamlined as a result of Druva didn’t must delve into the complexities of operating or managing these various FMs, due to the sturdy infrastructure supplied by Amazon Bedrock.
Via the experiments, we discovered that totally different fashions carried out higher in particular duties. For instance, Meta Llama 2 carried out higher with code era process; Anthropic Claude Occasion was good in environment friendly and cost-effective dialog; whereas Anthropic Claude 2.1 was good in getting desired responses in retry flows.
These had been the most recent fashions from Anthropic and Meta on the time of this writing.
Answer overview
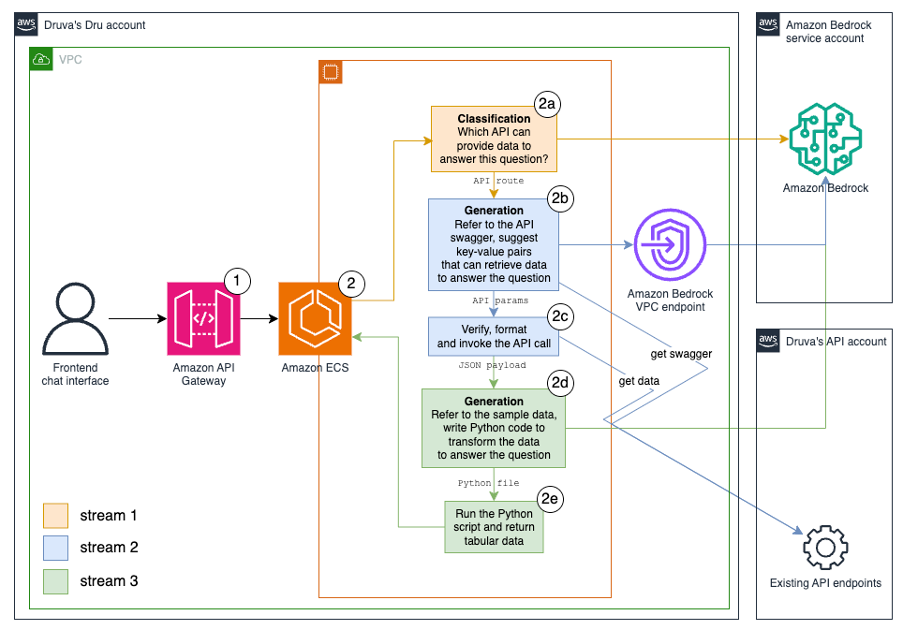
The next diagram exhibits how the three streams work collectively as a single workflow to reply person questions with tabular knowledge.

The next are the steps of the workflow:
- The authenticated person submits a query to Dru, for instance, “Present me my backup job failures for the final 72 hours,” as an API name.
- The request arrives on the microservice on our current Amazon Elastic Container Service (Amazon ECS) cluster. This course of consists of the next steps:
- A classification process utilizing the FM gives the out there API routes within the immediate and asks for the one which finest matches with person query.
- An API parameters era process utilizing the FM will get the corresponding API swagger, then asks the FM to recommend key-value pairs to the API name that may retrieve knowledge to reply the query.
- A customized Python perform verifies, codecs, and invokes the API name, then passes the info in JSON format to the subsequent step.
- A Python code era process utilizing the FM samples a number of information of information from the earlier step, then asks the FM to put in writing Python code to remodel the info to reply the query.
- A customized Python perform runs the Python code and returns the reply in tabular format.
To take care of person and system safety, we ensure that in our design that:
- The FM can’t immediately connect with any Druva backend companies.
- The FM resides in a separate AWS account and digital non-public cloud (VPC) from the backend companies.
- The FM can’t provoke actions independently.
- The FM can solely reply to questions despatched from Druva’s API.
- Regular buyer permissions apply to the API calls made by Dru.
- The decision to the API (Step 1) is just doable for authenticated person. The authentication part lives outdoors the Dru answer and is used throughout different inside options.
- To keep away from immediate injection, jailbreaking, and different malicious actions, a separate module checks for these earlier than the request reaches this service (Amazon API Gateway in Step 1).
For extra particulars, confer with Druva’s Secret Sauce: Meet the Expertise Behind Dru’s GenAI Magic.
Implementation particulars
On this part, we talk about Steps 2a–2e within the answer workflow.
2a. Lookup the API definition
This step makes use of an FM to carry out classification. It takes the person query and a full listing of obtainable API routes with significant names and descriptions because the enter, and responds The next is a pattern immediate:
2b. Generate the API name
This step makes use of an FM to generate API parameters. It first seems to be up the corresponding swagger for the API route (from Step 2a). Subsequent, it passes the swagger and the person query to an FM and responds with some key-value pairs to the API route that may retrieve related knowledge. The next is a pattern immediate:
2c. Validate and invoke the API name
Within the earlier step, even with an try and floor responses with swagger, the FM can nonetheless hallucinate incorrect or nonexistent API parameters. This step makes use of a programmatic approach to confirm, format, and invoke the API name to get knowledge. The next is the pseudo code:
second. Generate Python code to remodel knowledge
This step makes use of an FM to generate Python code. It first samples a number of information of enter knowledge to scale back enter tokens. Then it passes the pattern knowledge and the person query to an FM and responds with a Python script that transforms knowledge to reply the query. The next is a pattern immediate:
2e. Run the Python code
This step entails a Python script, which imports the generated Python package deal, runs the transformation, and returns the tabular knowledge as the ultimate response. If an error happens, it is going to invoke the FM to attempt to appropriate the code. When every thing fails, it returns the enter knowledge. The next is the pseudo code:
Conclusion
Utilizing Amazon Bedrock for the answer basis led to exceptional achievements in accuracy, as evidenced by the next metrics in our evaluations utilizing an inside dataset:
- Stream 1: Establish the API route – Achieved an ideal accuracy price of 100%
- Stream 2: Generate and invoke non-public API calls – Maintained this commonplace with a 100% accuracy price
- Stream 3: Generate and run knowledge transformation Python code – Attained a extremely commendable accuracy of 90%
These outcomes are usually not simply numbers; they’re a testomony to the robustness and effectivity of the Amazon Bedrock primarily based answer. With such excessive ranges of accuracy, Druva is now poised to confidently broaden their horizons. Our subsequent purpose is to increase this answer to embody a wider vary of APIs throughout Druva merchandise. The following growth will likely be scaling up utilization and considerably enrich the expertise of Druva clients. By integrating extra APIs, Druva will provide a extra seamless, responsive, and contextual interplay with Druva merchandise, additional enhancing the worth delivered to Druva customers.
To study extra about Druva’s AI options, go to the Dru answer web page, the place you may see a few of these capabilities in motion via recorded demos. Go to the AWS Machine Studying weblog to see how different clients are utilizing Amazon Bedrock to unravel their enterprise issues.
In regards to the Authors
 David Gildea is the VP of Product for Generative AI at Druva. With over 20 years of expertise in cloud automation and rising applied sciences, David has led transformative tasks in knowledge administration and cloud infrastructure. Because the founder and former CEO of CloudRanger, he pioneered progressive options to optimize cloud operations, later resulting in its acquisition by Druva. At present, David leads the Labs staff within the Workplace of the CTO, spearheading R&D into generative AI initiatives throughout the group, together with tasks like Dru Copilot, Dru Examine, and Amazon Q. His experience spans technical analysis, industrial planning, and product improvement, making him a outstanding determine within the area of cloud know-how and generative AI.
David Gildea is the VP of Product for Generative AI at Druva. With over 20 years of expertise in cloud automation and rising applied sciences, David has led transformative tasks in knowledge administration and cloud infrastructure. Because the founder and former CEO of CloudRanger, he pioneered progressive options to optimize cloud operations, later resulting in its acquisition by Druva. At present, David leads the Labs staff within the Workplace of the CTO, spearheading R&D into generative AI initiatives throughout the group, together with tasks like Dru Copilot, Dru Examine, and Amazon Q. His experience spans technical analysis, industrial planning, and product improvement, making him a outstanding determine within the area of cloud know-how and generative AI.
 Tom Nijs is an skilled backend and AI engineer at Druva, captivated with each studying and sharing information. With a concentrate on optimizing programs and utilizing AI, he’s devoted to serving to groups and builders deliver progressive options to life.
Tom Nijs is an skilled backend and AI engineer at Druva, captivated with each studying and sharing information. With a concentrate on optimizing programs and utilizing AI, he’s devoted to serving to groups and builders deliver progressive options to life.
 Corvus Lee is a Senior GenAI Labs Options Architect at AWS. He’s captivated with designing and creating prototypes that use generative AI to unravel buyer issues. He additionally retains up with the most recent developments in generative AI and retrieval methods by making use of them to real-world situations.
Corvus Lee is a Senior GenAI Labs Options Architect at AWS. He’s captivated with designing and creating prototypes that use generative AI to unravel buyer issues. He additionally retains up with the most recent developments in generative AI and retrieval methods by making use of them to real-world situations.
 Fahad Ahmed is a Senior Options Architect at AWS and assists monetary companies clients. He has over 17 years of expertise constructing and designing software program purposes. He lately discovered a brand new ardour of creating AI companies accessible to the plenty.
Fahad Ahmed is a Senior Options Architect at AWS and assists monetary companies clients. He has over 17 years of expertise constructing and designing software program purposes. He lately discovered a brand new ardour of creating AI companies accessible to the plenty.



{kind=link}