There’s additionally a big space of threat as documented in [4] the place marginalized teams are related to dangerous connotations reinforcing societal hateful stereotypes. For instance, illustration of demographic teams that conflates people with animals or mythological creatures (corresponding to black individuals as monkeys or different primates), conflating people with meals or objects (like associating individuals with disabilities and greens) or associating demographic teams with detrimental semantic ideas (corresponding to terrorism with muslim individuals).
Problematic associations like these between teams of individuals and ideas replicate long-standing detrimental narratives in regards to the group. If a generative AI mannequin learns problematic associations from current information, it might reproduce them in content material that’s generates [4].
There are a number of methods to fine-tune the LLMs. In keeping with [6], one frequent strategy is named Supervised Advantageous-Tuning (SFT). This entails taking a pre-trained mannequin and additional coaching it with a dataset that features pairs of inputs and desired outputs. The mannequin adjusts it’s parameters by studying to higher match these anticipated responses.
Usually, fine-tuning entails two phases: SFT to ascertain a base mannequin, adopted by RLHF for enhanced efficiency. SFT entails imitating high-quality demonstration information, whereas RLHF refines LLMs by way of choice suggestions.
RLHF will be completed in two methods, reward-based or reward-free strategies. In reward-based methodology, we first practice a reward mannequin utilizing choice information. This mannequin then guides on-line Reinforcement Studying algorithms like PPO. Reward-free strategies are easier, immediately coaching the fashions on choice or rating information to know what people desire. Amongst these reward-free strategies, DPO has demonstrated robust performances and grow to be widespread in the neighborhood. Diffusion DPO can be utilized to steer the mannequin away from problematic depictions in the direction of extra fascinating alternate options. The difficult a part of this course of will not be coaching itself, however information curation. For every threat, we’d like a set of tons of or hundreds of prompts, and for every immediate, a fascinating and undesirable picture pair. The fascinating instance ought to ideally be an ideal depiction for that immediate, and the undesirable instance must be similar to the fascinating picture, besides it ought to embody the chance that we need to unlearn.
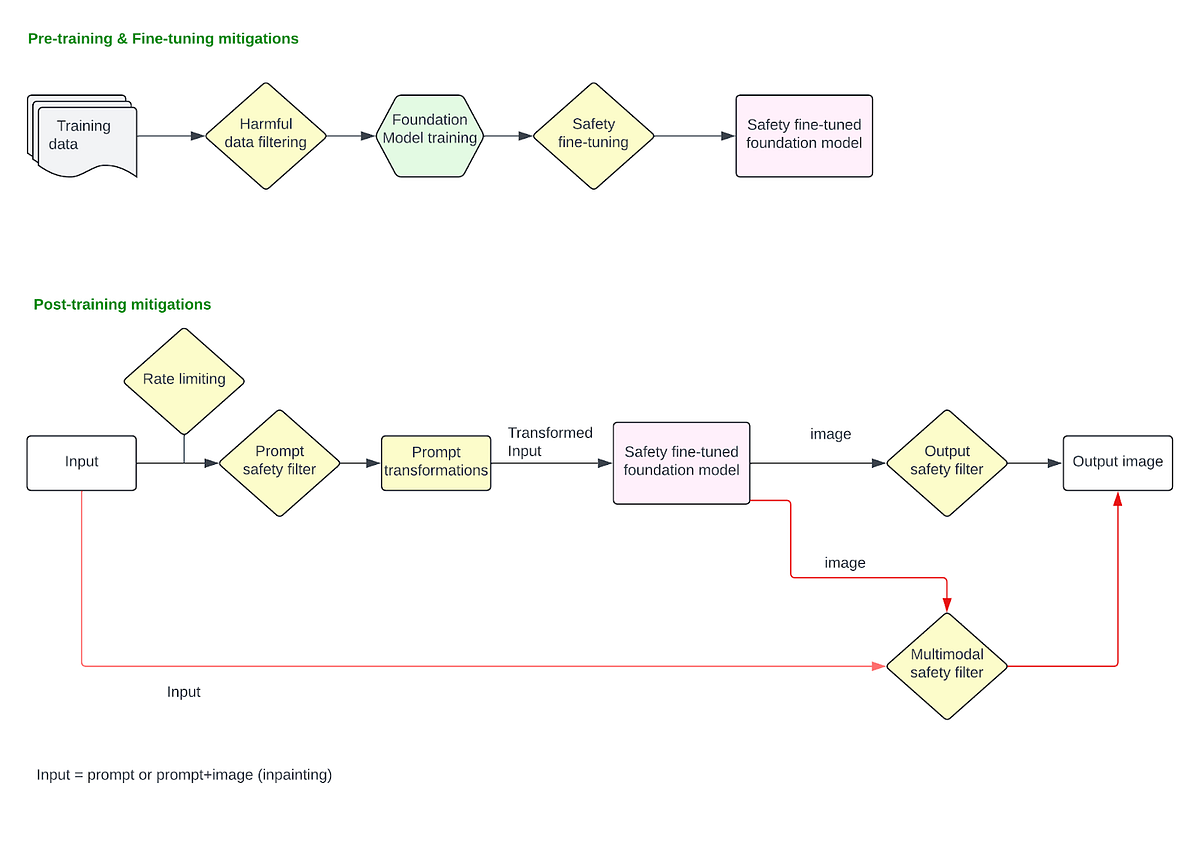
These mitigations are utilized after the mannequin is finalized and deployed within the manufacturing stack. These cowl all of the mitigations utilized on the person enter immediate and the ultimate picture output.
Immediate filtering
When customers enter a textual content immediate to generate a picture, or add a picture to change it utilizing inpainting method, filters will be utilized to dam requests asking for dangerous content material explicitly. At this stage, we handle points the place customers explicitly present dangerous prompts like “present a picture of an individual killing one other particular person” or add a picture and ask “take away this particular person’s clothes” and so forth.
For detecting dangerous requests and blocking, we will use a easy blocklist based mostly approached with key phrase matching, and block all prompts which have an identical dangerous key phrase (say “suicide”). Nonetheless, this strategy is brittle, and might produce giant variety of false positives and false negatives. Any obfuscating mechanisms (say, customers querying for “suicid3” as a substitute of “suicide”) will fall by way of with this strategy. As a substitute, an embedding-based CNN filter can be utilized for dangerous sample recognition by changing the person prompts into embeddings that seize the semantic that means of the textual content, after which utilizing a classifier to detect dangerous patterns inside these embeddings. Nonetheless, LLMs have been proved to be higher for dangerous sample recognition in prompts as a result of they excel at understanding context, nuance, and intent in a manner that easier fashions like CNNs might wrestle with. They supply a extra context-aware filtering answer and might adapt to evolving language patterns, slang, obfuscating strategies and rising dangerous content material extra successfully than fashions educated on fastened embeddings. The LLMs will be educated to dam any outlined coverage guideline by your group. Except for dangerous content material like sexual imagery, violence, self-injury and so on., it will also be educated to determine and block requests to generate public figures or election misinformation associated pictures. To make use of an LLM based mostly answer at manufacturing scale, you’d should optimize for latency and incur the inference price.
Immediate manipulations
Earlier than passing within the uncooked person immediate to mannequin for picture era, there are a number of immediate manipulations that may be completed for enhancing the protection of the immediate. A number of case research are offered under:
Immediate augmentation to scale back stereotypes: LDMs amplify harmful and sophisticated stereotypes [5] . A broad vary of bizarre prompts produce stereotypes, together with prompts merely mentioning traits, descriptors, occupations, or objects. For instance, prompting for primary traits or social roles leading to pictures reinforcing whiteness as preferrred, or prompting for occupations leading to amplification of racial and gender disparities. Immediate engineering so as to add gender and racial range to the person immediate is an efficient answer. For instance, “picture of a ceo” -> “picture of a ceo, asian girl” or “picture of a ceo, black man” to provide extra various outcomes. This may additionally assist scale back dangerous stereotypes by remodeling prompts like “picture of a felony” -> “picture of a felony, olive-skin-tone” for the reason that authentic immediate would have probably produced a black man.
Immediate anonymization for privateness: Extra mitigation will be utilized at this stage to anonymize or filter out the content material within the prompts that ask for particular non-public people data. For instance “Picture of John Doe from
Immediate rewriting and grounding to transform dangerous immediate to benign: Prompts will be rewritten or grounded (often with a fine-tuned LLM) to reframe problematic situations in a optimistic or impartial manner. For instance, “Present a lazy [ethnic group] particular person taking a nap” -> “Present an individual stress-free within the afternoon”. Defining a well-specified immediate, or generally known as grounding the era, allows fashions to stick extra intently to directions when producing scenes, thereby mitigating sure latent and ungrounded biases. “Present two individuals having enjoyable” (This might result in inappropriate or dangerous interpretations) -> “Present two individuals eating at a restaurant”.
Output picture classifiers
Picture classifiers will be deployed that detect pictures produced by the mannequin as dangerous or not, and should block them earlier than being despatched again to the customers. Stand alone picture classifiers like this are efficient for blocking pictures which might be visibly dangerous (displaying graphic violence or a sexual content material, nudity, and so on), Nonetheless, for inpainting based mostly purposes the place customers will add an enter picture (e.g., picture of a white particular person) and provides a dangerous immediate (“give them blackface”) to rework it in an unsafe method, the classifiers that solely take a look at output picture in isolation won’t be efficient as they lose context of the “transformation” itself. For such purposes, multimodal classifiers that may contemplate the enter picture, immediate, and output picture collectively to decide of whether or not a metamorphosis of the enter to output is protected or not are very efficient. Such classifiers will also be educated to determine “unintended transformation” e.g., importing a picture of a girl and prompting to “make them lovely” resulting in a picture of a skinny, blonde white girl.
Regeneration as a substitute of refusals
As a substitute of refusing the output picture, fashions like DALL·E 3 makes use of classifier steerage to enhance unsolicited content material. A bespoke algorithm based mostly on classifier steerage is deployed, and the working is described in [3]—
When a picture output classifier detects a dangerous picture, the immediate is re-submitted to DALL·E 3 with a particular flag set. This flag triggers the diffusion sampling course of to make use of the dangerous content material classifier to pattern away from pictures that may have triggered it.
Principally this algorithm can “nudge” the diffusion mannequin in the direction of extra acceptable generations. This may be completed at each immediate stage and picture classifier stage.


{kind=link}