Generative AI question-answering purposes are pushing the boundaries of enterprise productiveness. These assistants may be powered by numerous backend architectures together with Retrieval Augmented Technology (RAG), agentic workflows, fine-tuned giant language fashions (LLMs), or a mixture of those strategies. Nonetheless, constructing and deploying reliable AI assistants requires a strong floor reality and analysis framework.
Floor reality information in AI refers to information that’s identified to be factual, representing the anticipated use case final result for the system being modeled. By offering an anticipated final result to measure towards, floor reality information unlocks the power to deterministically consider system high quality. Working deterministic analysis of generative AI assistants towards use case floor reality information allows the creation of customized benchmarks. These benchmarks are important for monitoring efficiency drift over time and for statistically evaluating a number of assistants in undertaking the identical job. Moreover, they allow quantifying efficiency adjustments as a operate of enhancements to the underlying assistant, all inside a managed setting. With deterministic analysis processes such because the Factual Data and QA Accuracy metrics of FMEval, floor reality era and analysis metric implementation are tightly coupled. To make sure the very best high quality measurement of your query answering software towards floor reality, the analysis metric’s implementation should inform floor reality curation.
On this submit, we talk about finest practices for making use of LLMs to generate floor reality for evaluating question-answering assistants with FMEval on an enterprise scale. FMEval is a complete analysis suite from Amazon SageMaker Make clear, and supplies standardized implementations of metrics to evaluate high quality and accountability. To be taught extra about FMEval, see Consider giant language fashions for high quality and accountability of LLMs. Moreover, see the Generative AI Safety Scoping Matrix for steering on moderating confidential and personally identifiable data (PII) as a part of your generative AI answer.
By following these pointers, information groups can implement excessive constancy floor reality era for question-answering use case analysis with FMEval. For floor reality curation finest practices for query answering evaluations with FMEval that you should use to design FMEval floor reality immediate templates, see Floor reality curation and metric interpretation finest practices for evaluating generative AI query answering utilizing FMEval.
Producing floor reality for FMEval question-answering analysis
One choice to get began with floor reality era is human curation of a small question-answer dataset. The human curated dataset must be small (based mostly on bandwidth), excessive in sign, and ideally ready by use case material consultants (SMEs). The train of producing this dataset forces an information alignment train early within the analysis course of, elevating necessary questions and conversations amongst use case stakeholders about what questions are necessary to measure over time for the enterprise. The outcomes for this train are three-fold:
- Stakeholder alignment on the highest N necessary questions
- Stakeholder consciousness of the analysis course of
- A high-fidelity starter floor reality dataset for the primary proof of idea analysis as a operate of consciousness and analysis
Whereas an SME floor reality curation train is a robust begin, on the scale of an enterprise data base, pure SME era of floor reality will change into prohibitively time and useful resource intensive. To scale floor reality era and curation, you possibly can apply a risk-based strategy together with a prompt-based technique utilizing LLMs. It’s necessary to notice that LLM-generated floor reality isn’t an alternative to use case SME involvement. For instance, if floor reality is generated by LLMs earlier than the involvement of SMEs, SMEs will nonetheless be wanted to establish which questions are elementary to the enterprise after which align the bottom reality with enterprise worth as a part of a human-in-the-loop course of.
To show, we offer a step-by-step walkthrough utilizing Amazon’s 2023 letter to shareholders as supply information.
In line with floor reality curation finest practices for FMEval question-answering, floor reality is curated as question-answer-fact triplets. The query and reply are curated to swimsuit the best question-answering assistant response by way of content material, size, and elegance. The truth is a minimal illustration of the bottom reality reply, comprising a number of topic entities of the query.
For instance, think about how the next supply doc chunk from the Amazon 2023 letter to shareholders may be transformed to question-answering floor reality.
Expensive Shareholders:
Final 12 months right now, I shared my enthusiasm and optimism for Amazon’s future. Right now, I’ve much more. The explanations are many, however begin with the progress we’ve made in our monetary outcomes and buyer experiences, and lengthen to our continued innovation and the exceptional alternatives in entrance of us. In 2023, Amazon’s complete income grew 12% year-over-year (“Y oY”) from $514B to $575B. By section, North America income elevated 12% Y oY from $316B to $353B, Worldwide income grew 11% Y oY from$118B to $131B, and AWS income elevated 13% Y oY from $80B to $91B. Additional, Amazon’s working earnings and Free Money Circulation (“FCF”) dramatically improved. Working earnings in 2023 improved 201% YoY from $12.2B (an working margin of two.4%) to $36.9B (an working margin of 6.4%).
To transform the supply doc excerpt into floor reality, we offer a base LLM immediate template. Within the template, we instruct the LLM to take a fact-based strategy to deciphering the chunk utilizing chain-of-thought logic. For our instance, we work with Anthropic’s Claude LLM on Amazon Bedrock. The template is suitable with and may be modified for different LLMs, akin to LLMs hosted on Amazon Sagemaker Jumpstart and self-hosted on AWS infrastructure. To switch the immediate to be used by different LLMs, a distinct strategy to denoting immediate sections than XML tags is perhaps required. For instance, Meta Llama fashions apply tags akin to [INST] and <
The LLM is assigned a persona to set its perspective for finishing up the duty. Within the directions, the LLM identifies info as entities from the supply doc chunk. For every truth, a question-answer-fact triplet is assembled based mostly on the very fact detected and its surrounding context. Within the immediate, we offer detailed examples for controlling the content material of floor reality questions. The examples concentrate on questions on chunk-wise enterprise data whereas ignoring irrelevant metadata that is perhaps contained in a bit. You possibly can customise the immediate examples to suit your floor reality use case.
We additional instruct the LLM to use floor reality curation finest practices for FMEval, akin to producing a number of variations of info to suit a number of attainable unit expressions. Extra curation parts topic to the duty at hand—akin to model language and tone—may be launched into the bottom reality era immediate. With the next template, we verified that Anthropic’s Claude Sonnet 3.5 can generate customized floor reality attributes accommodating FMEval options, such because the
The era output is offered as fact-wise JSONLines data within the following format, the place parts in sq. brackets signify values from a line in Desk 1.
Listed here are just a few examples of generated floor reality:
| Query | Floor Reality Reply | Reality |
| What was Amazon’s complete income development in 2023? | Amazon’s complete income grew 12% year-over-year from $514B to $575B in 2023. | 12% |
| How a lot did North America income improve in 2023? | North America income elevated 12% year-over-year from $316B to $353B. | 12% |
| What was the expansion in Worldwide income for Amazon in 2023? | Worldwide income grew 11% year-over-year from $118B to $131B. | 11% |
| How a lot did AWS income improve in 2023? | AWS income elevated 13% year-over-year from $80B to $91B. | 13% |
| What was Amazon’s working earnings enchancment in 2023? | Working earnings in 2023 improved 201% year-over-year from $12.2B to $36.9B. | 201% |
| What was Amazon’s working margin in 2023? | Amazon’s working margin in 2023 was 6.4%. | 6.4% |
Scaling floor reality era with a pipeline
To automate floor reality era, we offer a serverless batch pipeline structure, proven within the following determine. At a excessive stage, the AWS Step Features pipeline accepts supply information in Amazon Easy Storage Service (Amazon S3), and orchestrates AWS Lambda features for ingestion, chunking, and prompting on Amazon Bedrock to generate the fact-wise JSONLines floor reality.

There are three consumer inputs to the step operate:
- A customized identify for the bottom reality dataset
- The enter Amazon S3 prefix for the supply information
- The share to pattern for overview.
Extra configurations are set by Lambda surroundings variables, such because the S3 supply bucket and Amazon Bedrock Mannequin ID to invoke on era.
After the preliminary payload is handed, a validation operate assembles the worldwide occasion payload construction by way of system enter and consumer enter.
After validation, the primary distributed map state iterates over the recordsdata within the enter bucket to begin the doc ingestion and chunking processes with horizontal scaling. The ensuing chunks are saved in an intermediate S3 bucket.
The second distributed map is the era core of the pipeline. Every chunk generated by the earlier map is fed as an enter to the bottom reality era immediate on Amazon Bedrock. For every chunk, a JSONLines file containing the question-answer-fact triplets is validated and saved in an S3 bucket on the output prefix.
The next determine reveals a view of the information construction and lineage from doc paragraphs to the ultimate floor reality chunk throughout the chunking and era map states. The numbering between the 2 figures signifies the information construction current at every level within the pipeline. Lastly, the JSONLines recordsdata are aggregated in an Amazon SageMaker Processing Job, together with the project of a random pattern for human overview based mostly on consumer enter.

The final step of the pipeline is the aggregation step utilizing a SageMaker Processing job. The aggregation step consists of concatenating the JSONLines data generated by each youngster execution of the era map right into a single floor reality output file. A randomly chosen share of the data within the output file are sampled and flagged for overview as a part of a human-in-the-loop course of.
Judging floor reality for FMEval question-answering analysis
On this part, we talk about two key parts of evaluating floor reality high quality: human within the loop and making use of an LLM as a Decide. Measuring floor reality high quality is a vital part of the analysis lifecycle.
Human-in-the-loop
The extent of floor reality human overview required is set by the chance of getting incorrect floor reality, and its destructive implications. Floor reality overview by use case SMEs can confirm if crucial enterprise logic is appropriately represented by the bottom reality. The method of floor reality overview by people known as human-in-the-loop (HITL), and an instance the HITL course of is proven within the following determine.
The steps of HTIL are:
- Classify danger: performing a danger evaluation will set up the severity and chance of destructive occasions occurring on account of incorrect floor reality used for analysis of a generative AI use-case. Based mostly on the result of the evaluation, assign the bottom reality dataset a danger stage: Low, Medium, Excessive or Important. The desk beneath outlines the connection between occasion severity, chance, and danger stage. See Learn to assess the chance of AI methods for a deep dive on performing AI danger evaluation.
- Human overview: Based mostly on the assigned danger stage, use-case professional reviewers look at a proportional quantity of the use-case floor reality. Organizations can set acceptability thresholds for share of HITL intervention based mostly on their tolerance for danger. Equally, if a floor reality dataset is promoted from a low danger to a medium danger use case, an elevated stage of HITL intervention will probably be vital.
- Determine findings: Reviewers can establish any hallucinations relative to supply information, challenges with data veracity in accordance with their experience, or different standards set by the group. On this submit, we concentrate on hallucination detection and data veracity.
- Motion outcomes: Reviewers can take enterprise actions based mostly on their judgement, akin to updating and deleting data, or re-writing relevant supply paperwork. Bringing in LLMOps SMEs to use dataset curation finest practices can be an final result.

Placing the chance desk from Learn to assess the chance of AI methods into motion, the severity and chance of dangers for a floor reality dataset validating a manufacturing chatbot with frequent buyer use could be better than an inner analysis dataset utilized by builders to advance a prototype.
| Chance | |||||
| Severity | Uncommon | Unlikely | Attainable | Probably | Frequent |
| Excessive | Low | Medium | Excessive | Important | Important |
| Main | Very low | Low | Medium | Excessive | Important |
| Reasonable | Very low | Low | Medium | Medium | Excessive |
| Low | Very low | Very low | Low | Low | Medium |
| Very Low | Very low | Very low | Very low | Very low | Low |
Subsequent, we stroll by way of the step-by-step strategy of conducting a human overview for hallucination detection and data veracity. Human overview is carried out by evaluating the bottom reality chunk enter to the LLM immediate to the generated question-answer-fact triplets. This view is proven within the following desk.
| Supply information chunk | Floor reality triplets |
|
Expensive Shareholders: Final 12 months right now, I shared my enthusiasm and optimism for Amazon’s future. Right now, I’ve much more. The explanations are many, however begin with the progress we’ve made in our monetary outcomes and buyer experiences, and lengthen to our continued innovation and the exceptional alternatives in entrance of us. In 2023, Amazon’s complete income grew 12% year-over-year (“YoY”) from $514B to $575B. By section, North America income elevated 12% Y oY from $316B to $353B, Worldwide income grew 11% YoY from $118B to $131B, and AWS income elevated 13% YoY from $80B to $91B. |
{“query”: “What was Amazon’s complete income development in 2023?”, “ground_truth_answer”: “Amazon’s complete income grew 12% year-over-year from $514B to $575B in 2023.”, “truth”: “12% {“query”: “How a lot did North America income improve in 2023?”, “ground_truth_answer”: “North America income elevated 12% year-over-year from $316B to $353B.”, “truth”: “12% {“query”: “What was the expansion in Worldwide income for Amazon in 2023?”, “ground_truth_answer”: “Worldwide income grew 11% year-over-year from $118B to $131B.”, “truth”: “11% |
Human reviewers then establish and take motion based mostly on findings to appropriate the system. LLM hallucination is the phenomenon the place LLMs generate plausible-sounding however factually incorrect or nonsensical data, introduced confidently as factual. Organizations can introduce further qualities for evaluating and scoring floor reality, as suited to the chance stage and use case necessities.
In hallucination detection, reviewers search to establish textual content that has been incorrectly generated by the LLM. An instance of hallucination and remediation is proven within the following desk. A reviewer would discover within the supply information that Amazon’s complete income grew 12% 12 months over 12 months, but the bottom reality reply hallucinated a 15% determine. In remediation, the reviewer can change this again to 12%.
| Supply information chunk | Instance hallucination | Instance hallucination remediation |
| In 2023, Amazon’s complete income grew 12% year-over-year (“YoY”) from $514B to $575B. |
{“query”: “What was Amazon’s complete income development in 2023?”, “ground_truth_answer”: “Amazon’s complete income grew 15% year-over-year from $514B to $575B in 2023.”, “truth”: “12% |
{“query”: “What was Amazon’s complete income development in 2023?”, “ground_truth_answer”: “Amazon’s complete income grew 12% year-over-year from $514B to $575B in 2023.”, “truth”: “12% |
In SME overview for veracity, reviewers search to validate if the bottom reality is the truth is truthful. For instance, the supply information used for the bottom reality era immediate is perhaps old-fashioned or incorrect. The next desk reveals the attitude of an HITL overview by a site SME.
| Supply information chunk | Instance SME overview | Instance hallucination remediations |
| Efficient June 1st, 2023, AnyCompany is happy to announce the implementation of “Informal Friday” as a part of our up to date costume code coverage. On Fridays, staff are permitted to put on enterprise informal apparel, together with neat denims, polo shirts, and cozy closed-toe sneakers. |
“As an HR Specialist, this appears incorrect to me. We didn’t implement the Informal Friday coverage in any case at AnyCompany – the supply information for this floor reality should be old-fashioned.” |
|
Conventional machine studying purposes can even inform the HITL course of design. For examples of HITL for conventional machine studying, see Human-in-the-loop overview of mannequin explanations with Amazon SageMaker Make clear and Amazon A2I.
LLM-as-a-judge
When scaling HITL, LLM reviewers can carry out hallucination detection and remediation. This concept is named self-reflective RAG, and can be utilized to lower—however not eradicate—the extent of human effort within the course of for hallucination detection. As a method of scaling LLM-as-a-judge overview, Amazon Bedrock now affords the power to make use of LLM reviewers and to carry out automated reasoning checks with Amazon Bedrock Guardrails for mathematically sound self-validation towards predefined insurance policies. For extra details about implementation, see New RAG analysis and LLM-as-a-judge capabilities in Amazon Bedrock and Forestall factual errors from LLM hallucinations with mathematically sound Automated Reasoning checks (preview).
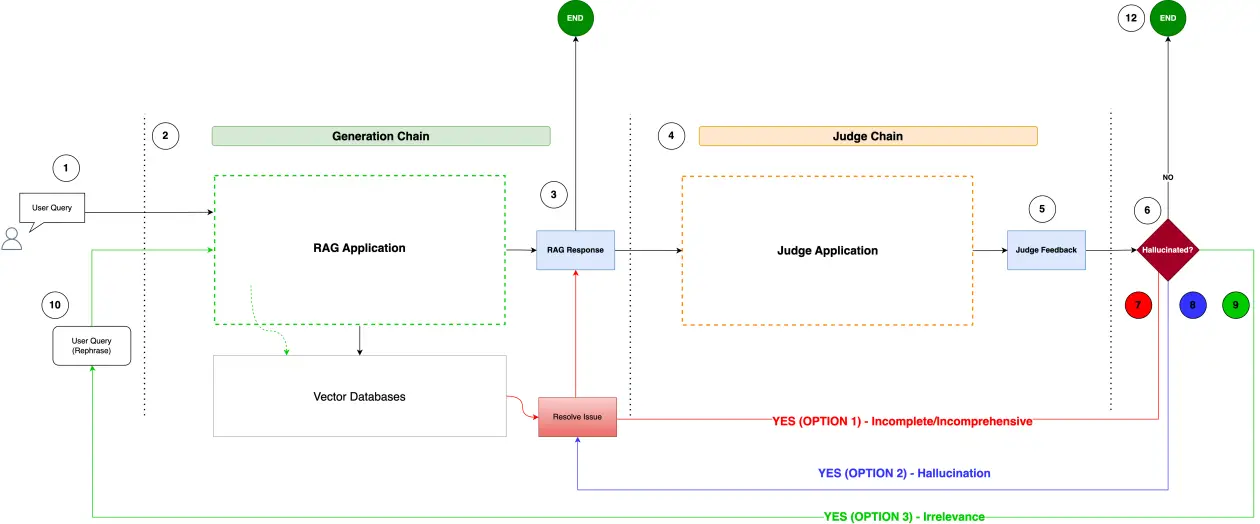
The next determine reveals an instance high-level diagram of a self-reflective RAG sample. A generative AI software based mostly on RAG yields responses fed to a decide software. The decide software displays on whether or not responses are incomplete, hallucinated, or irrelevant. Based mostly on the judgement, information is routed alongside the corresponding remediation.

The golden rule in implementing HITL or LLM-as-a-judge as a part of floor reality era is to verify the group’s overview course of aligns with the accepted danger stage for the bottom reality dataset.
Conclusion
On this submit, we offered steering on producing and reviewing floor reality for evaluating question-answering purposes utilizing FMEval. We explored finest practices for making use of LLMs to scale floor reality era whereas sustaining high quality and accuracy. The serverless batch pipeline structure we introduced affords a scalable answer for automating this course of throughout giant enterprise data bases. We offer a floor reality era immediate that you should use to get began with evaluating data assistants utilizing the FMEval Factual Data and QA Accuracy analysis metrics.
By following these pointers, organizations can comply with accountable AI finest practices for creating high-quality floor reality datasets for deterministic analysis of question-answering assistants. Use case-specific evaluations supported by well-curated floor reality play a vital position in growing and deploying AI options that meet the very best requirements of high quality and accountability.
Whether or not you’re growing an inner instrument, a customer-facing digital assistant, or exploring the potential of generative AI to your group, we encourage you to undertake these finest practices. Begin implementing a strong floor reality era and overview processes to your generative AI question-answering evaluations right this moment with FMEval.
Concerning the authors
 Samantha Stuart is a Knowledge Scientist with AWS Skilled Companies, and has delivered for purchasers throughout generative AI, MLOps, and ETL engagements. Samantha has a analysis grasp’s diploma in engineering from the College of Toronto, the place she authored a number of publications on data-centric AI for drug supply system design. Outdoors of labor, she is almost certainly noticed taking part in music, spending time with family and friends, on the yoga studio, or exploring Toronto.
Samantha Stuart is a Knowledge Scientist with AWS Skilled Companies, and has delivered for purchasers throughout generative AI, MLOps, and ETL engagements. Samantha has a analysis grasp’s diploma in engineering from the College of Toronto, the place she authored a number of publications on data-centric AI for drug supply system design. Outdoors of labor, she is almost certainly noticed taking part in music, spending time with family and friends, on the yoga studio, or exploring Toronto.
 Philippe Duplessis-Guindon is a cloud guide at AWS, the place he has labored on a variety of generative AI initiatives. He has touched on most features of those initiatives, from infrastructure and DevOps to software program growth and AI/ML. After incomes his bachelor’s diploma in software program engineering and a grasp’s in laptop imaginative and prescient and machine studying from Polytechnique Montreal, Philippe joined AWS to place his experience to work for purchasers. When he’s not at work, you’re more likely to discover Philippe outdoor—both mountain climbing or going for a run.
Philippe Duplessis-Guindon is a cloud guide at AWS, the place he has labored on a variety of generative AI initiatives. He has touched on most features of those initiatives, from infrastructure and DevOps to software program growth and AI/ML. After incomes his bachelor’s diploma in software program engineering and a grasp’s in laptop imaginative and prescient and machine studying from Polytechnique Montreal, Philippe joined AWS to place his experience to work for purchasers. When he’s not at work, you’re more likely to discover Philippe outdoor—both mountain climbing or going for a run.
 Rahul Jani is a Knowledge Architect with AWS Skilled Service. He collaborates intently with enterprise clients constructing fashionable information platforms, generative AI purposes, and MLOps. He’s specialised within the design and implementation of huge information and analytical purposes on the AWS platform. Past work, he values high quality time with household and embraces alternatives for journey.
Rahul Jani is a Knowledge Architect with AWS Skilled Service. He collaborates intently with enterprise clients constructing fashionable information platforms, generative AI purposes, and MLOps. He’s specialised within the design and implementation of huge information and analytical purposes on the AWS platform. Past work, he values high quality time with household and embraces alternatives for journey.
 Ivan Cui is a Knowledge Science Lead with AWS Skilled Companies, the place he helps clients construct and deploy options utilizing ML and generative AI on AWS. He has labored with clients throughout numerous industries, together with software program, finance, pharmaceutical, healthcare, IoT, and leisure and media. In his free time, he enjoys studying, spending time along with his household, and touring.
Ivan Cui is a Knowledge Science Lead with AWS Skilled Companies, the place he helps clients construct and deploy options utilizing ML and generative AI on AWS. He has labored with clients throughout numerous industries, together with software program, finance, pharmaceutical, healthcare, IoT, and leisure and media. In his free time, he enjoys studying, spending time along with his household, and touring.



{kind=link}