I the idea of federated studying (FL) by way of a comedian by Google in 2019. It was an excellent piece and did a terrific job at explaining how merchandise can enhance with out sending person information to the cloud. Currently, I’ve been wanting to grasp the technical aspect of this discipline in additional element. Coaching information has develop into such an essential commodity as it’s important for constructing good fashions however a whole lot of this will get unused as a result of it’s fragmented, unstructured or locked inside silos.
As I began exploring this discipline, I discovered the Flower framework to be probably the most easy and beginner-friendly approach to get began in FL. It’s open supply, the documentation is obvious, and the neighborhood round it is rather energetic and useful. It is without doubt one of the motive for my renewed curiosity on this discipline.
This text is the primary a part of a sequence the place I discover federated studying in additional depth, overlaying what it’s, how it’s carried out, the open issues it faces, and why it issues in privacy-sensitive settings. Within the subsequent instalments, I’ll go deeper into sensible implementation with the Flower framework, talk about privateness in federated studying and study how these concepts prolong to extra superior use circumstances.
When Centralised Machine studying isn’t superb
We all know AI fashions depend upon massive quantities of information, but a lot of probably the most helpful information is delicate, distributed, and exhausting to entry. Consider information inside hospitals, telephones, automobiles, sensors, and different edge programs. Privateness issues, native guidelines, restricted storage, and community limits make shifting this information to a central place very tough and even unattainable. Consequently, massive quantities of invaluable information stay unused. In healthcare, this downside is particularly seen. Hospitals generate tens of petabytes of information yearly, but research estimate that as much as 97% of this information goes unused.
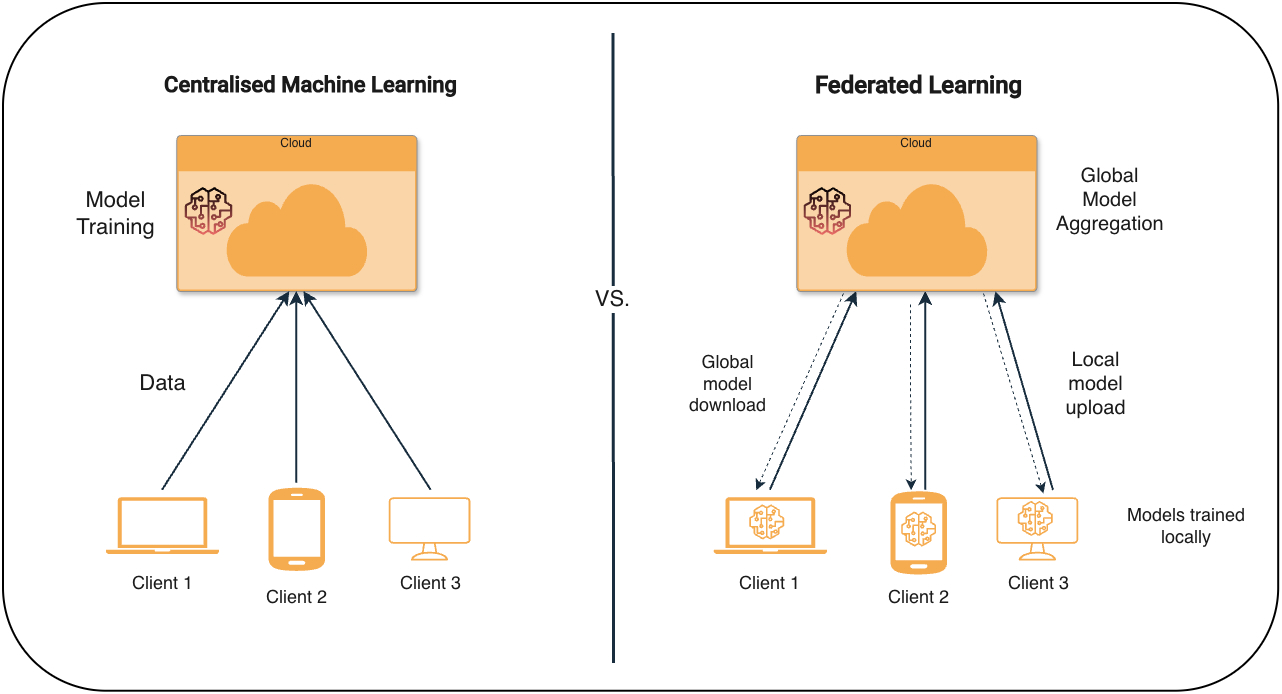
Conventional machine studying assumes that every one coaching information could be collected in a single place, often on a centralized server or information heart. This works when information could be freely moved, nevertheless it breaks down when information is non-public or protected. In apply, centralised coaching additionally relies on steady connectivity, sufficient bandwidth, and low latency, that are tough to ensure in distributed or edge environments.

In such circumstances, two widespread decisions seem. One choice is to not use the info in any respect, which suggests invaluable data stays locked inside silos.
The opposite choice is to let every native entity practice a mannequin by itself information and share solely what the mannequin learns, whereas the uncooked information by no means leaves its authentic location. This second choice types the premise of federated studying, which permits fashions to be taught from distributed information with out shifting it. A well known instance is Google Gboard on Android, the place options like next-word prediction and Sensible Compose run throughout a whole lot of tens of millions of units.
Federated Studying: Transferring the Mannequin to the Information
Federated studying could be considered a collaborative machine studying setup the place coaching occurs with out amassing information in a single central place. Earlier than taking a look at the way it works underneath the hood, let’s see just a few real-world examples that present why this method issues in high-risk settings, spanning domains from healthcare to security-sensitive environments.
Healthcare
In healthcare, federated studying enabled early COVID screening by way of Curial AI, a system educated throughout a number of NHS hospitals utilizing routine important indicators and blood exams. As a result of affected person information couldn’t be shared throughout hospitals, coaching was carried out domestically at every web site and solely mannequin updates had been exchanged. The ensuing international mannequin generalized higher than fashions educated at particular person hospitals, particularly when evaluated on unseen websites.
Medical Imaging

Federated studying can be being explored in medical imaging. Researchers at UCL and Moorfields Eye Hospital are utilizing it to fine-tune massive imaginative and prescient basis fashions on delicate eye scans that can not be centralized.
Protection
Past healthcare, federated studying can be being utilized in security-sensitive domains equivalent to protection and aviation. Right here, fashions are educated on distributed physiological and operational information that should stay native.
Various kinds of Federated Studying
At a high-level, Federated studying could be grouped into just a few widespread sorts primarily based on who the purchasers are and how the info is cut up.
• Cross-System vs Cross-Silo Federated Studying
Cross-device federated studying entails use of many purchasers which can go as much as tens of millions, like private units or telephones, every with a small quantity of native information and unreliable connectivity. At a given time, nonetheless, solely a small fraction of units take part in any given spherical. Google Gboard is a typical instance of this setup.
Cross-silo federated studying, however, entails a a lot smaller variety of purchasers, often organizations like hospitals or banks. Every shopper holds a big dataset and has steady compute and connectivity. Most real-world enterprise and healthcare use circumstances appear like cross-silo federated studying.
• Horizontal vs Vertical Federated Studying

Horizontal federated studying describes how information is cut up throughout purchasers. On this case, all purchasers share the identical characteristic house, however every holds totally different samples. For instance, a number of hospitals might file the identical medical variables, however for various sufferers. That is the commonest type of federated studying.
Vertical federated studying is used when purchasers share the identical set of entities however have totally different options. For instance, a hospital and an insurance coverage supplier might each have information about the identical people, however with totally different attributes. Coaching, on this case requires safe coordination as a result of characteristic areas differ, and this setup is much less widespread than horizontal federated studying.
These classes aren’t mutually unique. An actual system is usually described utilizing each axes, for instance, a cross-silo, horizontal federated studying setup.
How Federated Studying works
Federated studying follows a easy, repeated course of coordinated by a central server and executed by a number of purchasers that maintain information domestically, as proven within the diagram beneath.

Coaching in federated studying proceeds by way of repeated federated studying rounds. In every spherical, the server selects a small random subset of purchasers, sends them the present mannequin weights, and waits for updates. Every shopper trains the mannequin domestically utilizing stochastic gradient descent, often for a number of native epochs by itself batches, and returns solely the up to date weights. At a excessive degree it follows the next 5 steps:
- Initialisation
A worldwide mannequin is created on the server, which acts because the coordinator. The mannequin could also be randomly initialized or begin from a pretrained state.
2. Mannequin distribution
In every spherical, the server selects a set of purchasers(primarily based on random sampling or a predefined technique) which participate in coaching and sends them the present international mannequin weights. These purchasers could be telephones, IoT units or particular person hospitals.
3. Native coaching
Every chosen shopper then trains the mannequin domestically utilizing its personal information. The info by no means leaves the shopper and all computation occurs on gadget or inside a company like hospital or a financial institution.
4. Mannequin replace communication
After the native coaching, purchasers ship solely the up to date mannequin parameters (could possibly be weights or gradients) again to the server whereas uncooked information is shared at any level.
5. Aggregation
The server aggregates the shopper updates to supply a brand new international mannequin. Whereas Federated Averaging (Fed Avg) is a typical method for aggregation, different methods are additionally used. The up to date mannequin is then despatched again to purchasers, and the method repeats till convergence.
Federated studying is an iterative course of and every cross by way of this loop is named a spherical. Coaching a federated mannequin often requires many rounds, generally a whole lot, relying on components equivalent to mannequin dimension, information distribution and the issue being solved.
Mathematical Instinct behind Federated Averaging
The workflow described above will also be written extra formally. The determine beneath reveals the unique Federated Averaging (Fed Avg) algorithm from Google’s seminal paper. This algorithm later grew to become the principle reference level and demonstrated that federated studying can work in apply. This formulation actually grew to become the reference level for many federated studying programs in the present day.

The unique Federated Averaging algorithm, displaying the server–shopper coaching loop and weighted aggregation of native fashions.
On the core of Federated Averaging is the aggregation step, the place the server updates the worldwide mannequin by taking a weighted common of the domestically educated shopper fashions. This may be written as:

This equation makes it clear how every shopper contributes to the worldwide mannequin. Purchasers with extra native information have a bigger affect, whereas these with fewer samples contribute proportionally much less. In apply, this straightforward concept is the rationale why Fed Avg grew to become the default baseline for federated studying.
A easy NumPy implementation
Let’s have a look at a minimal instance the place 5 purchasers have been chosen. For the sake of simplicity, we assume that every shopper has already completed native coaching and returned its up to date mannequin weights together with the variety of samples it used. Utilizing these values, the server computes a weighted sum that produces the brand new international mannequin for the subsequent spherical. This mirrors the Fed Avg equation immediately, with out introducing coaching or client-side particulars.
import numpy as np
# Shopper fashions after native coaching (w_{t+1}^ok)
client_weights = [
np.array([1.0, 0.8, 0.5]), # shopper 1
np.array([1.2, 0.9, 0.6]), # shopper 2
np.array([0.9, 0.7, 0.4]), # shopper 3
np.array([1.1, 0.85, 0.55]), # shopper 4
np.array([1.3, 1.0, 0.65]) # shopper 5
]
# Variety of samples at every shopper (n_k)
client_sizes = [50, 150, 100, 300, 4000]
# m_t = whole variety of samples throughout chosen purchasers S_t
m_t = sum(client_sizes) # 50+150+100+300+400
# Initialize international mannequin w_{t+1}
w_t_plus_1 = np.zeros_like(client_weights[0])
# FedAvg aggregation:
# w_{t+1} = sum_{ok in S_t} (n_k / m_t) * w_{t+1}^ok
# (50/1000) * w_1 + (150/1000) * w_2 + ...
for w_k, n_k in zip(client_weights, client_sizes):
w_t_plus_1 += (n_k / m_t) * w_k
print("Aggregated international mannequin w_{t+1}:", w_t_plus_1)
-------------------------------------------------------------
Aggregated international mannequin w_{t+1}: [1.27173913 0.97826087 0.63478261]
How the aggregation is computed
Simply to place issues into perspective, we are able to develop the aggregation step for simply two purchasers and see how the numbers line up.

Challenges in Federated Studying Environments
Federated studying comes with its personal set of challenges. One of many main points when implementing it’s that the info throughout purchasers is usually non-IID (non-independent and identically distributed). This implies totally different purchasers might even see very totally different information distributions which in flip can sluggish coaching and make the worldwide mannequin much less steady. As an illustration, Hospitals in a federation can serve totally different populations that may comply with totally different patterns.
Federated programs can contain something from just a few organizations to tens of millions of units and managing participation, dropouts and aggregation turns into harder because the system scales.
Whereas federated studying retains uncooked information native, it doesn’t absolutely remedy privateness by itself. Mannequin updates can nonetheless leak non-public data if not protected and so further privateness strategies are sometimes wanted. Lastly, communication could be a supply of bottleneck. Since networks could be sluggish or unreliable and sending frequent updates could be pricey.
Conclusion and what’s subsequent
On this article, we understood how federated studying works at a excessive degree and likewise walked by way of a merely Numpy implementation. Nevertheless, as a substitute of writing the core logic by hand, there are frameworks like Flower which gives a easy and versatile approach to construct federated studying programs. Within the subsequent half, we’ll utilise Flower to do the heavy lifting for us in order that we are able to deal with the mannequin and the info fairly than the mechanics of federated studying. We’ll additionally take a look at federated LLMs, the place mannequin dimension, communication value, and privateness constraints develop into much more essential.
Notice: All photographs, except in any other case acknowledged, are created by the creator.



{kind=link}