I TabPFN by the ICLR 2023 paper — TabPFN: A Transformer That Solves Small Tabular Classification Issues in a Second. The paper launched TabPFN, an open-source transformer mannequin constructed particularly for tabular datasets, an area that has probably not benefited from deep studying and the place gradient boosted determination tree fashions nonetheless dominate.
At the moment, TabPFN supported solely as much as 1,000 coaching samples and 100 purely numerical options, so its use in real-world settings was pretty restricted. Over time, nonetheless, there have been a number of incremental enhancements together with TabPFN-2, which was launched in 2025 by the paper — Correct Predictions on Small Knowledge with a Tabular Basis Mannequin (TabPFN-2).

Extra just lately, TabPFN-2.5 was launched and this model can deal with near 100,000 information factors and round 2,000 options, which makes it pretty sensible for actual world prediction duties. I’ve spent lots of my skilled years working with tabular datasets, so this naturally caught my curiosity and pushed me to look deeper. On this article, I give a excessive stage overview of TabPFN and likewise stroll by a fast implementation utilizing a Kaggle competitors that will help you get began.
What’s TabPFN
TabPFN stands for Tabular Prior-data Fitted Community, a basis mannequin that is predicated on the concept of becoming a mannequin to a prior over tabular datasets, quite than to a single dataset, therefore the title.
As I learn by the technical experiences, there have been lots fascinating bits and items to those fashions. As an illustration, TabPFN can ship robust tabular predictions with very low latency, typically corresponding to tuned ensemble strategies, however with out repeated coaching loops.
From a workflow perspective additionally there isn’t a studying curve because it suits naturally into present setups by a scikit-learn model interface. It might probably deal with lacking values, outliers and combined characteristic sorts with minimal preprocessing which we’ll cowl throughout the implementation, later on this article.
The necessity for a basis mannequin for tabular information
Earlier than moving into how TabPFN works, let’s first attempt to perceive the broader drawback it tries to deal with.
With conventional machine studying on tabular datasets, you often practice a brand new mannequin for each new dataset. This typically includes lengthy coaching cycles, and it additionally signifies that a beforehand educated mannequin can’t actually be reused.
Nevertheless, if we take a look at the muse fashions for textual content and pictures, their concept is radically completely different. As an alternative of retraining from scratch, a considerable amount of pre-training is finished upfront throughout many datasets and the ensuing mannequin can then be utilized to new datasets with out retraining most often.
This in my view is the hole the mannequin is making an attempt to shut for tabular information i.e decreasing the necessity to practice a brand new mannequin from scratch for each dataset and this appears to be like like a promising space of analysis.
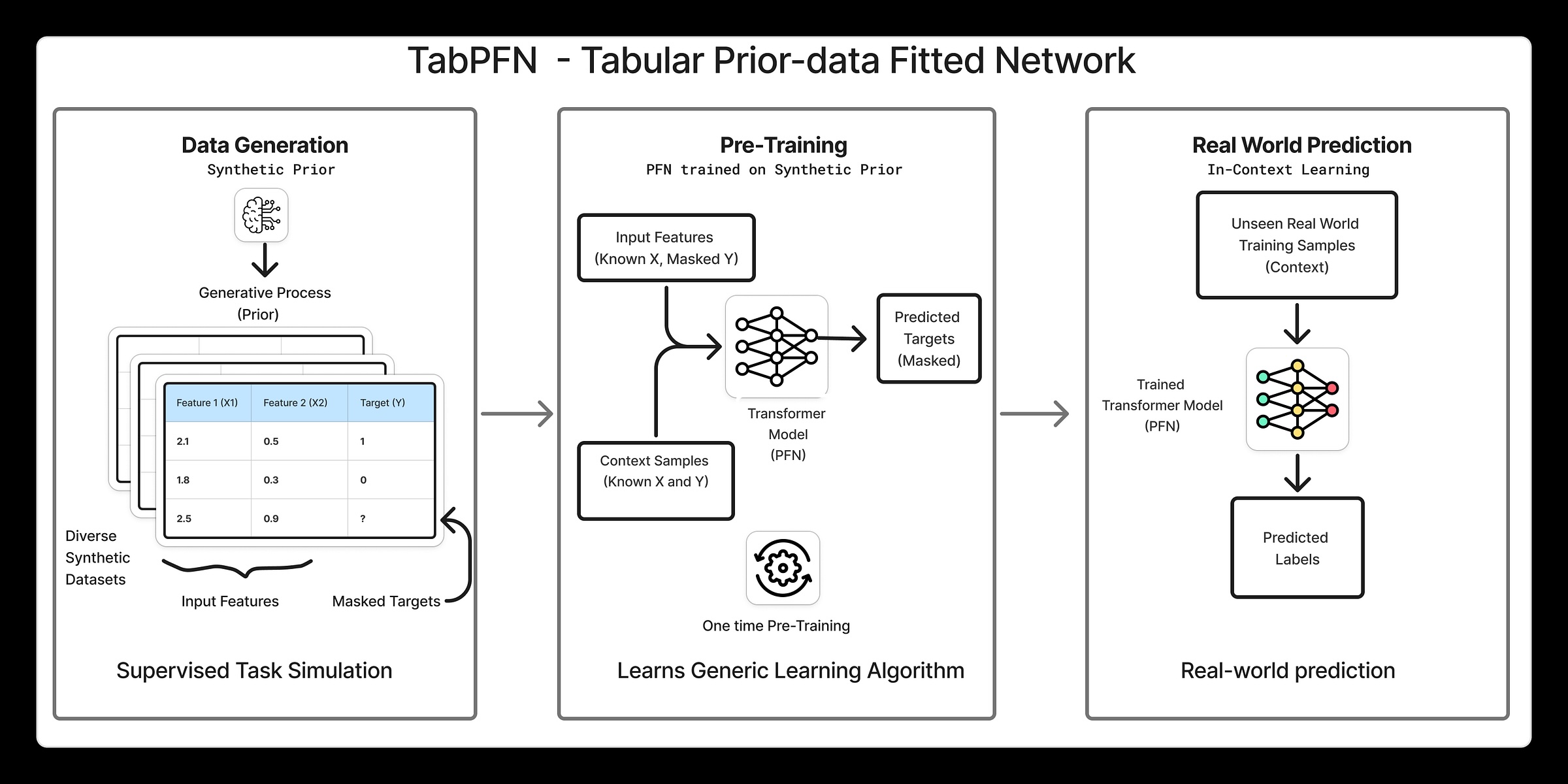
TabPFN coaching & Inference pipeline at a excessive stage

TabPFN utilises in-context studying to suit a neural community to a previous over tabular datasets. What this implies is that as an alternative of studying one activity at a time, the mannequin learns how tabular issues are likely to look generally after which makes use of that information to make predictions on new datasets by a single ahead cross. Right here is an excerpt from TabPFN’s Nature paper:
TabPFN leverages in-context studying (ICL), the identical mechanism that led to the astounding efficiency of huge language fashions, to generate a robust tabular prediction algorithm that’s totally discovered. Though ICL was first noticed in massive language fashions, latest work has proven that transformers can be taught easy algorithms corresponding to logistic regression by ICL.
The pipeline may be divided into three main steps:
1. Producing Artificial Datasets
TabPFN treats a whole dataset as a single information level (or a token) fed into the community. This implies it requires publicity to a really massive variety of datasets throughout coaching. Because of this, coaching TabPFN begins with artificial tabular datasets. Why artificial? Not like textual content or pictures, there are usually not many massive and various actual world tabular datasets obtainable, which makes artificial information a key a part of the setup. To place it into perspective, TabPFN 2 was educated on 130 million datasets.
The method of producing artificial datasets is fascinating in itself. TabPFN makes use of a extremely parametric structural causal mannequin to create tabular datasets with various constructions, characteristic relationships, noise ranges and goal capabilities. By sampling from this mannequin, a big and various set of datasets may be generated, every performing as a coaching sign for the community. This encourages the mannequin to be taught common patterns throughout many varieties of tabular issues, quite than overfitting to any single dataset.
2. Coaching
The determine beneath has been taken from the Nature paper, talked about above clearly demonstrates the coaching and inference course of.

Throughout coaching, an artificial tabular dataset is sampled and cut up into X practice,Y practice, X check, and Y check. The Y check values are held out, and the remaining elements are handed to the neural community which outputs a chance distribution for every Y check information level, as proven within the left determine.
The held out Y check values are then evaluated beneath these predicted distributions. A cross entropy loss is then computed and the community is up to date to decrease this loss. This completes one backpropagation step for a single dataset and this course of is then repeated for hundreds of thousands of artificial datasets.
3. Inference
At check time, the educated TabPFN mannequin is utilized to an actual dataset. This corresponds to the determine on the best, the place the mannequin is used for inference. As you’ll be able to see, the interface stays the identical as throughout coaching. You present X practice, Y practice, and X check, and the mannequin outputs predictions for Y check by a single ahead cross.
Most significantly, there isn’t a retraining at check time and TabPFN performs what’s successfully zero-shot inference, producing predictions instantly with out updating its weights.
Structure

Let’s additionally contact upon the core structure of the mannequin as talked about within the paper. At a excessive stage, TabPFN adapts the transformer structure to higher go well with tabular information. As an alternative of flattening a desk into an extended sequence, the mannequin treats every worth within the desk as its personal unit. It makes use of a two-stage consideration mechanism whereby it first learns how options relate to one another inside a single row after which learns how the identical characteristic behaves throughout completely different rows.
This fashion of structuring consideration is important because it matches how tabular information is definitely organized. This additionally means the mannequin doesn’t care in regards to the order of rows or columns which suggests it may well deal with tables which are bigger than these it was educated on.
Implementation
Lets now stroll by an implementation of TabPFN-2.5 and examine it in opposition to a vanilla XGBoost classifier to offer a well-known level of reference. Whereas the mannequin weights may be downloaded from Hugging Face, utilizing Kaggle Notebooks is extra easy for the reason that mannequin is available there and GPU assist comes out of the field for sooner inference. In both case, it is advisable settle for the mannequin phrases earlier than utilizing it. After including the TabPFN mannequin to the Kaggle pocket book setting, run the next cell to import it.
# importing the mannequin
import os
os.environ["TABPFN_MODEL_CACHE_DIR"] = "/kaggle/enter/tabpfn-2-5/pytorch/default/2"Yow will discover the whole code within the accompanying Kaggle pocket book right here.
Set up
You possibly can entry TabPFN in two methods both as a Python bundle and run it regionally or as an API shopper to run the mannequin within the cloud:
# Python bundle
pip set up tabpfn
# As an API shopper
pip set up tabpfn-clientDataset: Kaggle Playground competitors dataset
To get a greater sense of how TabPFN performs in an actual world setting, I examined it on a Kaggle Playground competitors that concluded few months in the past. The duty, Binary Prediction with a Rainfall Dataset (MIT license), requires predicting the chance of rainfall for every id within the check set. Analysis is finished utilizing ROC–AUC, which makes this match for probability-based fashions like TabPFN. The coaching information appears to be like like this:
Coaching a TabPFN Classifier
Coaching TabPFN Classifier is easy and follows a well-known scikit-learn model interface. Whereas there isn’t a task-specific coaching within the conventional sense, it’s nonetheless vital to allow GPU assist, in any other case inference may be noticeably slower. The next code snippet walks by making ready the information, coaching a TabPFN classifier and evaluating its efficiency utilizing ROC–AUC rating.
# Importing crucial libraries
from tabpfn import TabPFNClassifier
import pandas as pd, numpy as np
from sklearn.model_selection import train_test_split
# Choose characteristic columns
FEATURES = [c for c in train.columns if c not in ["rainfall",'id']]
X = practice[FEATURES].copy()
y = practice["rainfall"].copy()
# Cut up information into practice and validation units
train_index, valid_index = train_test_split(
practice.index,
test_size=0.2,
random_state=42
)
x_train = X.loc[train_index].copy()
y_train = y.loc[train_index].copy()
x_valid = X.loc[valid_index].copy()
y_valid = y.loc[valid_index].copy()
# Initialize and practice TabPFN
model_pfn = TabPFNClassifier(gadget=["cuda:0", "cuda:1"])
model_pfn.match(x_train, y_train)
# Predict class possibilities
probs_pfn = model_pfn.predict_proba(x_valid)
# # Use chance of the optimistic class
pos_probs = probs_pfn[:, 1]
# # Consider utilizing ROC AUC
print(f"ROC AUC: {roc_auc_score(y_valid, pos_probs):.4f}")
-------------------------------------------------
ROC AUC: 0.8722Subsequent let’s practice a fundamental XGBoost classifier.
Coaching an XGBoost Classifier
from xgboost import XGBClassifier
# Initialize XGBoost classifier
model_xgb = XGBClassifier(
goal="binary:logistic",
tree_method="hist",
gadget="cuda",
enable_categorical=True,
random_state=42,
n_jobs=1
)
# Prepare the mannequin
model_xgb.match(x_train, y_train)
# Predict class possibilities
probs_xgb = model_xgb.predict_proba(x_valid)
# Use chance of the optimistic class
pos_probs_xgb = probs_xgb[:, 1]
# Consider utilizing ROC AUC
print(f"ROC AUC: {roc_auc_score(y_valid, pos_probs_xgb):.4f}")
------------------------------------------------------------
ROC AUC: 0.8515As you’ll be able to see, TabPFN performs fairly nicely out of the field. Whereas XGBoost can definitely be tuned additional, my intent right here is to match fundamental, vanilla implementations quite than optimised fashions. It positioned me on a twenty second rank on the general public leaderboard. Beneath are the highest 3 scores for reference.

What about mannequin explainability?
Transformer fashions are usually not inherently interpretable and therefore to grasp the predictions, post-hoc interpretability strategies like SHAP (SHapley Additive Explanations) are generally used to research particular person predictions and have contributions. TabPFN supplies a devoted Interpretability Extension that integrates with SHAP, making it simpler to examine and motive in regards to the mannequin’s predictions. To entry that you just’ll want to put in the extension first:
# Set up the interpretability extension:
pip set up "tabpfn-extensions[interpretability]"
from tabpfn_extensions import interpretability
# Calculate SHAP values
shap_values = interpretability.shap.get_shap_values(
estimator=model_pfn,
test_x=x_test[:50],
attribute_names=FEATURES,
algorithm="permutation",
)
# Create visualization
fig = interpretability.shap.plot_shap(shap_values)
The plot on the left exhibits the common SHAP characteristic significance throughout your entire dataset, giving a worldwide view of which options matter most to the mannequin. The plot on the best is a SHAP abstract (beeswarm) plot, which supplies a extra granular view by exhibiting SHAP values for every characteristic throughout particular person predictions.
From the above plots, it’s evident that cloud cowl, sunshine, humidity, and dew level have the most important total influence on the mannequin’s predictions, whereas options corresponding to wind route, stress, and temperature-related variables play a relatively smaller position.
It is very important observe that SHAP explains the mannequin’s discovered relationships, not bodily causality.
Conclusion
There’s much more to TabPFN than what I’ve coated on this article. What I personally preferred is each the underlying concept and the way straightforward it’s to get began. There are lot of facets that I’ve not touched on right here, corresponding to TabPFN use in time collection forecasting, anomaly detection, producing artificial tabular information, and extracting embeddings from TabPFN fashions.
One other space I’m significantly inquisitive about exploring is fine-tuning, the place these fashions may be tailored to information from a selected area. That mentioned, this text was meant to be a lightweight introduction based mostly on my first hands-on expertise. I plan to discover these further capabilities in additional depth in future posts. For now, the official documentation is an efficient place to dive deeper.
Notice: All pictures, until in any other case acknowledged, are created by the writer.



{kind=link}