
Now you can obtain vital efficiency enhancements when utilizing Amazon Bedrock Customized Mannequin Import, with decreased end-to-end latency, quicker time-to-first-token, and improved throughput via superior PyTorch compilation and CUDA graph optimizations. With Amazon Bedrock Customized Mannequin Import you possibly can to convey your personal basis fashions to Amazon Bedrock for deployment and inference at scale.
These efficiency enhancements sometimes include mannequin initialization overhead that would affect container cold-start occasions. Amazon Bedrock addresses this with compilation artifact caching. This innovation delivers efficiency enhancements whereas sustaining current cold-start efficiency metrics that clients anticipate from CMI.
When deploying fashions with these optimizations, clients will expertise a one-time initialization delay throughout the first mannequin startup, however every subsequent mannequin occasion will spin up with out this overhead—balancing efficiency with quick startup occasions throughout scaling.
On this submit, we introduce the right way to use the enhancements in Amazon Bedrock Customized Mannequin Import.
How the optimization works
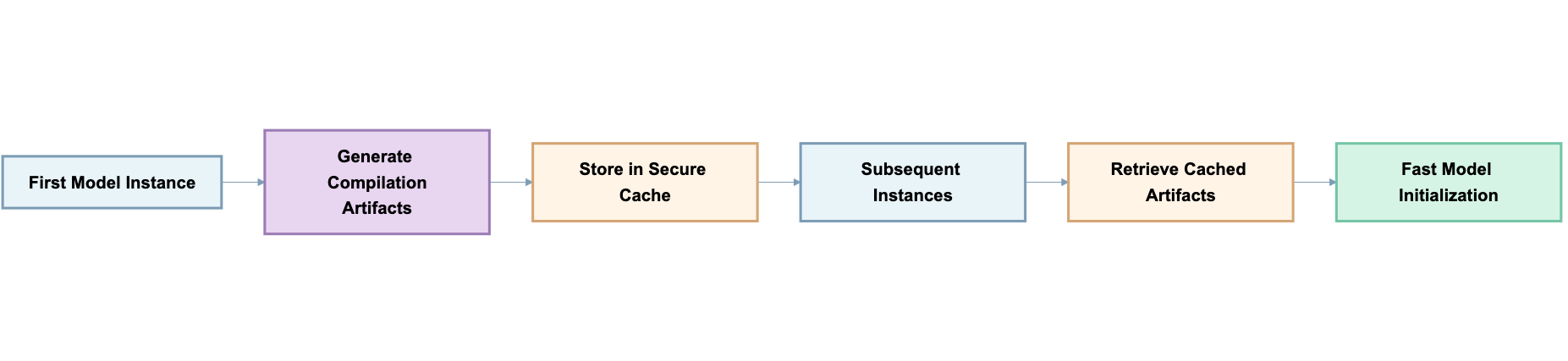
The inference engine caches compilation artifacts, eradicating repeated computational work at startup. When the primary mannequin occasion begins, it generates compilation artifacts together with optimized computational graphs and kernel configurations. These artifacts are saved and reused by later situations, so that they skip the compilation course of and begin quicker.
The system computes a singular identifier primarily based on mannequin configuration parameters resembling batch measurement, context size, and {hardware} specs. This identifier confirms cached artifacts match every mannequin occasion’s necessities, to allow them to be safely reused.
Saved artifacts embrace integrity verification to detect corruption throughout switch or storage. If corruption happens, the system clears the cache and regenerates artifacts. Fashions stay out there throughout this course of.
Efficiency enhancements
We examined efficiency throughout totally different mannequin sizes and workload patterns. The benchmarks in contrast fashions earlier than and after the compilation caching optimizations, measuring key inference metrics below varied concurrency ranges from 1 to 32 concurrent requests.
Technical implementation: Compilation caching structure
With a compilation caching structure, efficiency improves as a result of the system now not repeats computational work at startup. When the primary occasion of a mannequin begins, the inference engine performs a number of computationally intensive operations:
- Computational Graph Optimization: The engine analyzes the mannequin’s neural community structure and generates an optimized execution plan tailor-made to the goal {hardware}. This contains operator fusion, reminiscence format optimization, and figuring out alternatives for parallel execution.
- Kernel Compilation: GPU kernels are compiled and optimized for the precise mannequin configuration, batch measurement, and sequence size. This compilation course of generates extremely optimized CUDA code that maximizes GPU utilization.
- Reminiscence Planning: The engine determines optimum reminiscence allocation methods, together with tensor placement and buffer reuse patterns that reduce reminiscence fragmentation and information motion.
Beforehand, every new mannequin occasion repeated these operations independently, consuming vital initialization time. With compilation caching, the primary occasion generates these artifacts and helps retailer them securely. Subsequent situations retrieve and reuse these pre-compiled artifacts, bypassing the compilation section completely. The system makes use of a configuration-based identifier (incorporating mannequin structure, batch measurement, context size, and {hardware} specs) to verify cached artifacts match precisely with occasion necessities, sustaining correctness whereas facilitating constant optimized efficiency throughout the situations. The system contains checksum verification to detect corrupted cache information. If verification fails, the system mechanically falls again to full compilation, facilitating reliability whereas sustaining the efficiency advantages when cache is offered.
Benchmarking arrange
We benchmarked below situations that mirror manufacturing environments:
Check configuration: Every benchmark run deployed a single mannequin copy per occasion with out auto-scaling enabled. This remoted configuration makes certain that efficiency measurements mirror the true capabilities of the optimization with out interference from scaling behaviors or useful resource rivalry between a number of mannequin copies. By sustaining this managed atmosphere, we are able to attribute efficiency enhancements on to the compilation caching enhancements reasonably than infrastructure scaling results.
Workload patterns: We evaluated two consultant I/O patterns that span frequent use circumstances:
- 1000/250 tokens (1000 enter, 250 output): Represents medium-length prompts with reasonable response lengths, typical of conversational AI purposes, code completion duties, and interactive Q&A methods
- 2000/500 tokens (2000 enter, 500 output): Represents longer context home windows with extra substantial responses, frequent in doc evaluation, detailed code technology, and complete content material creation duties
We selected these patterns as a result of latency varies with the input-to-output ratio. throughout totally different token distributions, as latency traits can range considerably primarily based on the ratio of enter processing to output technology.
Concurrency ranges: Exams had been performed at six concurrency ranges (1, 2, 4, 8, 16, 32 concurrent requests) to judge efficiency below various load situations. This development follows powers of two, permitting us to watch how the system scales from single-user situations to reasonable multi-user hundreds. The concurrency testing reveals whether or not optimizations preserve their advantages below elevated load and helps establish the potential bottlenecks that emerge at increased request volumes.
Metrics: We captured complete latency statistics throughout the check runs, together with minimal, most, common, P50 (median), P95, and P99 percentile values. This entire statistical distribution offers insights into each typical efficiency and tail latency habits. The charts within the following part present common latency, which supplies a balanced view of general efficiency. The total statistical breakdown is offered within the accompanying information tables for readers fascinated by deeper evaluation of latency distributions.
Efficiency metrics definitions
We measured the next efficiency metrics:
- Time to First Token (TTFT) – The time elapsed from when a request is submitted till the mannequin generates and returns the primary token of its response. This metric is essential for person expertise in interactive purposes, because it determines how rapidly customers see the mannequin start responding. Decrease TTFT values create a extra responsive really feel, particularly necessary for streaming purposes the place customers are ready for the response to start.
- Finish-to-Finish Latency (E2E) – The full time from request submission to finish response supply, encompassing the processing phases together with enter processing, token technology, and output supply. This represents the complete wait time for an entire response.
- Throughput – The full variety of tokens (each enter and output) processed per second throughout the concurrent requests. Larger throughput means you possibly can serve extra customers with the identical {hardware}.
- Output Tokens Per Second (OTPS) – The speed at which the mannequin generates output tokens throughout the response technology section. This metric particularly measures technology velocity and is especially related for streaming purposes the place customers see tokens showing in real-time. Larger OTPS values lead to smoother, faster-appearing textual content technology, enhancing the perceived responsiveness of streaming responses.
Inference efficiency beneficial properties
The compilation caching optimizations ship substantial enhancements throughout the measured metrics, essentially serving to improve the person expertise and infrastructure effectivity. The next outcomes showcase the efficiency beneficial properties achieved with two consultant fashions, illustrating how the optimizations scale throughout totally different mannequin architectures and use circumstances.
Granite 20B Code Mannequin
As a bigger mannequin optimized for code technology duties, the Granite 20B mannequin demonstrates notably spectacular beneficial properties from compilation caching. The next P50 (median) metrics had been measured utilizing the 1000 enter / 250 output token workload sample:
- Time to First Token (TTFT): Lowered from 989.9ms to 120.9ms (87.8% enchancment). Customers see preliminary responses 8x quicker.
- Finish-to-Finish Latency (E2E): Lowered from 12,829ms to five,290ms (58.8% enchancment). Full requests end in half the time for quicker dialog turns.
- Throughput: Elevated from 360.5 to 450.8 tokens/sec (25.0% improve). Every occasion processes 25% extra tokens per second.
- Output Tokens Per Second (OTPS): Elevated from 44.8 to 48.3 tokens/sec (7.8% improve). Quicker token technology improves streaming response high quality.
The next is a comparability of the metrics within the previous and new containers for the granite-20b-code-base-8k mannequin, utilizing the typical values in every case for an Enter/Output sample of 1000/250 tokens respectively. 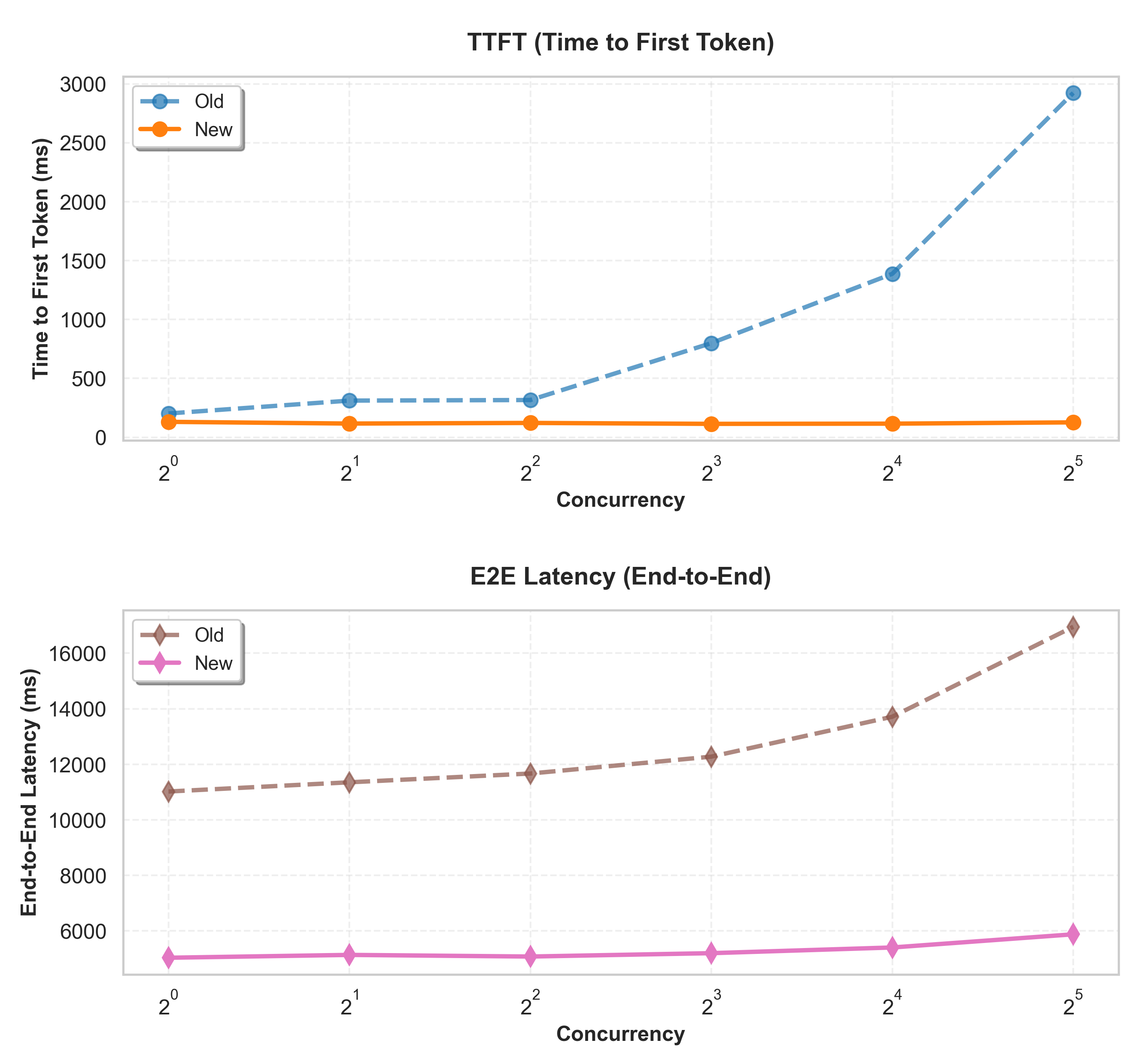

Llama 3.1 8B Instruct Mannequin
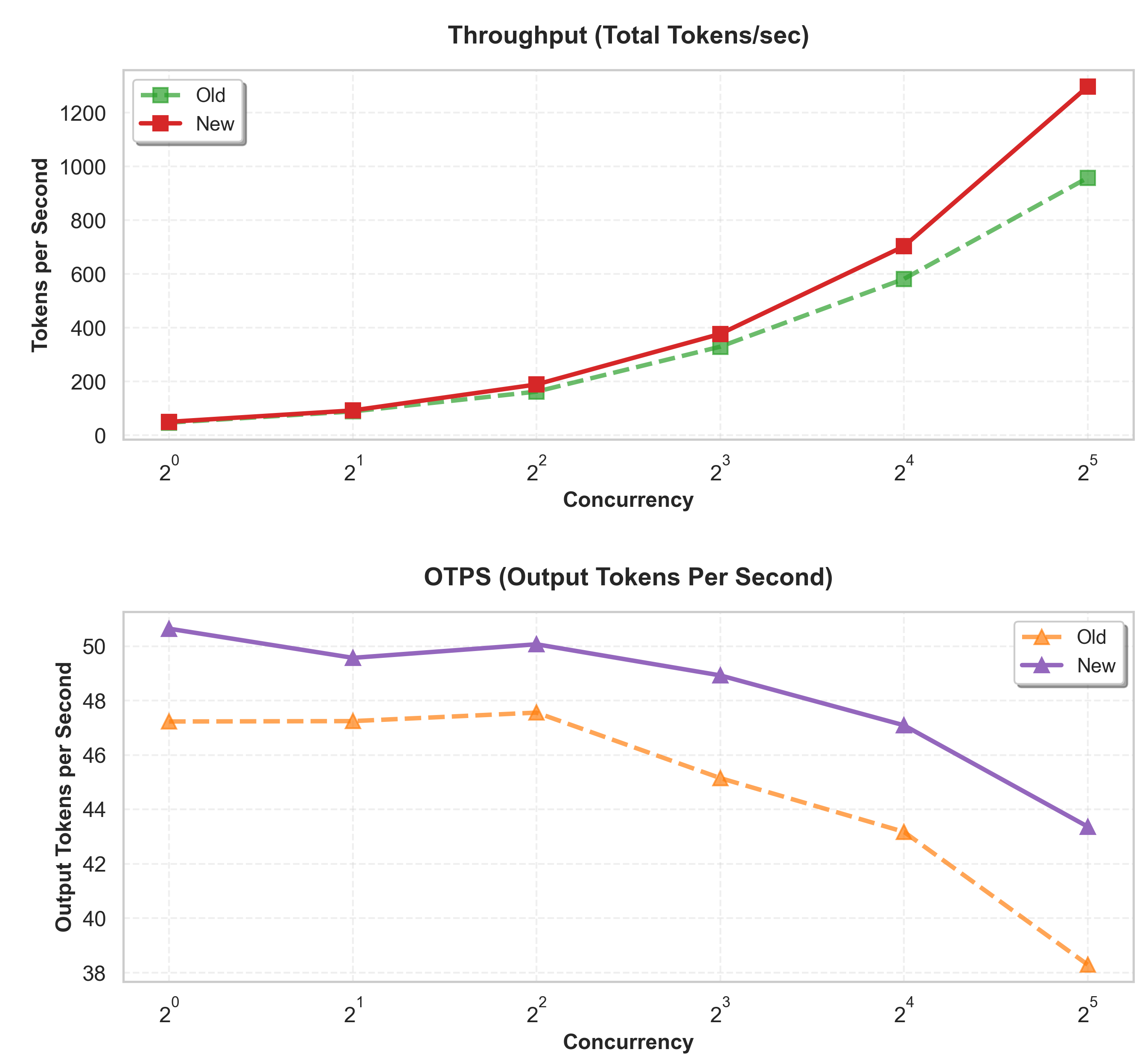
The smaller Llama 3.1 8B mannequin, designed for normal instruction-following duties, additionally exhibits vital efficiency enhancements that exhibit the broad applicability of compilation caching throughout totally different mannequin architectures. The next P50 (median) metrics had been measured utilizing the 1000 enter / 250 output token workload sample:
- Time to First Token (TTFT): Lowered from 366.9ms to 85.5ms (76.7% enchancment).
- Finish-to-Finish Latency: Lowered from 3,102ms to 2,532ms (18.4% enchancment).
- Throughput: Elevated from 714.3 tokens/sec to 922.0 tokens/sec (29.1% improve).
- Output Tokens Per Second (OTPS): Elevated from 93.9 tokens/sec to 102.4 tokens/sec) (9.1% improve).
The next is a comparability of the metrics within the previous and new containers for the llama3.1-8b mannequin, utilizing the typical values in every case for an Enter/Output sample of 1000/250 tokens respectively.
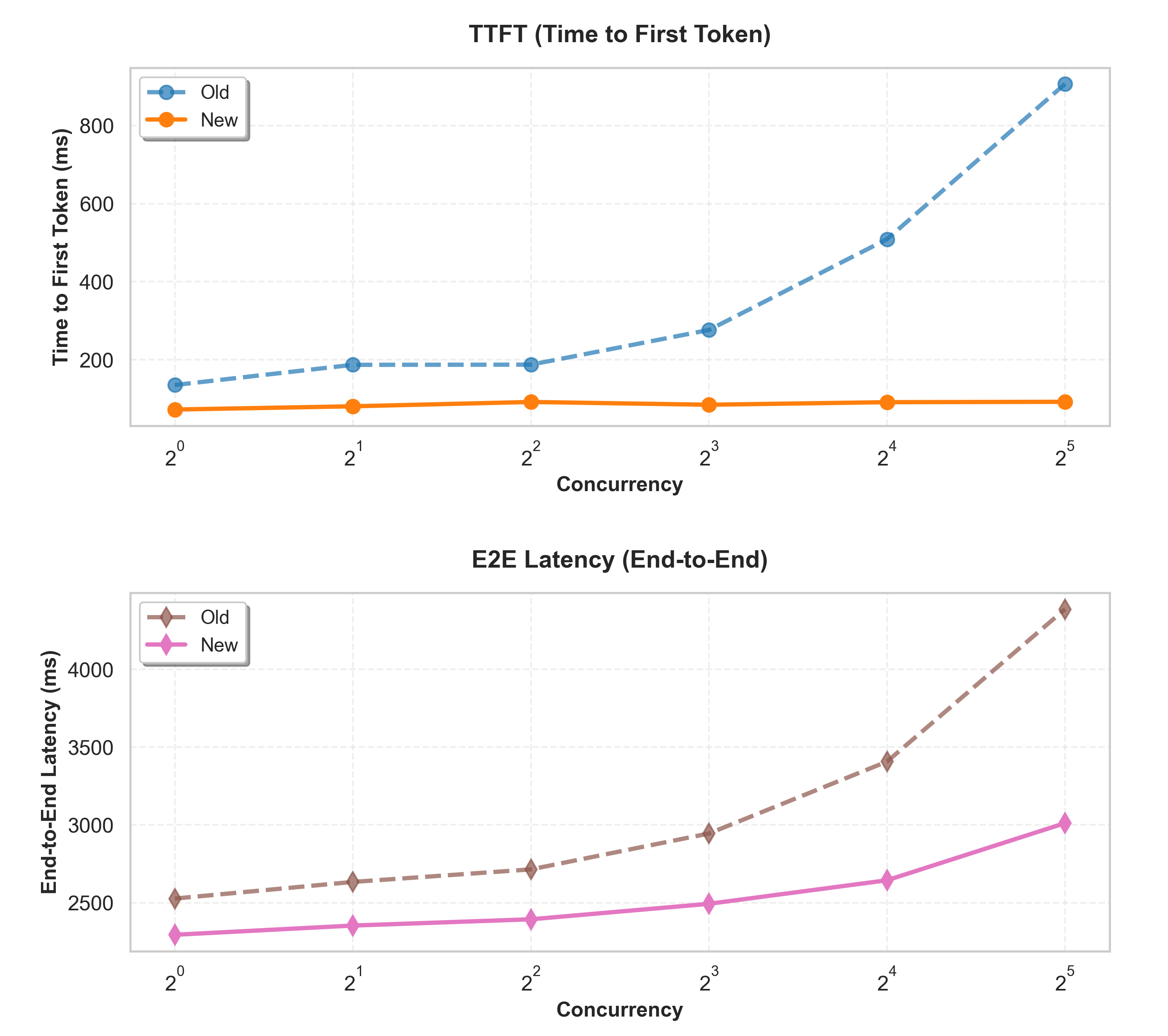
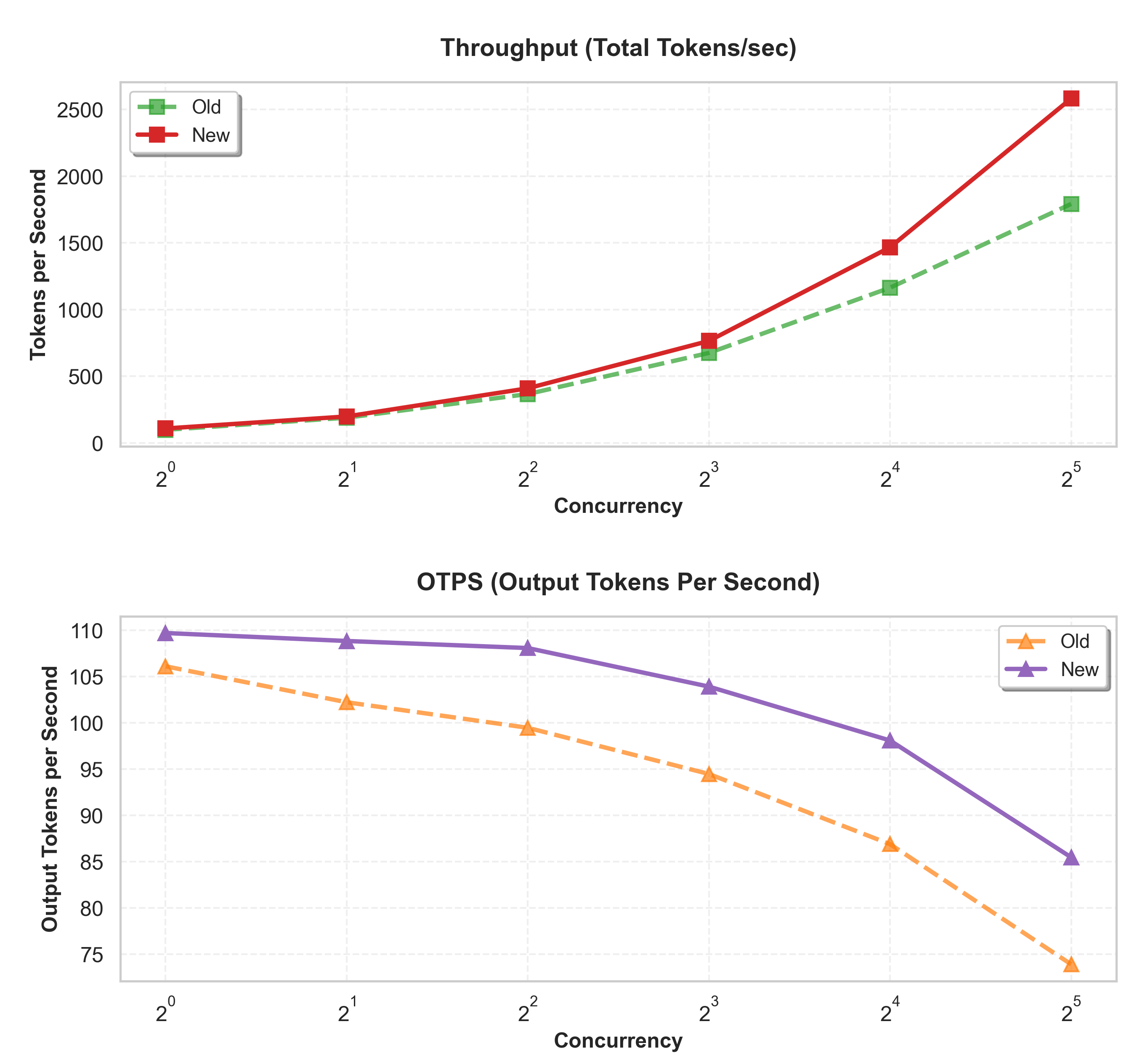

The next desk exhibits the complete benchmarking metrics for Llama-3.1-8B-Instruct, single mannequin copy, I/O tokens of 2000/500 respectively. Instances are in milliseconds and RPS stands for requests per second.
| Container | Concurrency | TTFT_P50_sec | TTFT_P99_sec | E2E_P50_sec | E2E_P99_sec | OTPS_P50 | OTPS_P99 | Throughput_tokens_sec | RPS |
|---|---|---|---|---|---|---|---|---|---|
| Outdated | 1 | 113.54 | 253.24 | 4892.57 | 5015.59 | 105.67 | 41.99 | 101.81 | 0.2 |
| 2 | 112.41 | 288.53 | 5044.94 | 5242.21 | 102.05 | 41.14 | 196.02 | 0.39 | |
| 4 | 211.84 | 359.12 | 5263.9 | 5412.86 | 98.07 | 39.75 | 377.78 | 0.76 | |
| 8 | 319.95 | 509.61 | 5666.83 | 5905.78 | 93.87 | 38.63 | 701.95 | 1.4 | |
| 16 | 558.5 | 694.03 | 6424.99 | 6816.19 | 85.65 | 35.75 | 1235.08 | 2.47 | |
| 32 | 1032.31 | 1282.82 | 8055.76 | 8486.76 | 71.96 | 30.77 | 1967.64 | 3.94 | |
| New | 1 | 93.5 | 255.85 | 4550.11 | 4763.6 | 109.54 | 42.99 | 108.8 | 0.22 |
| 2 | 83.27 | 215.43 | 4670.78 | 4813.82 | 108.48 | 41.38 | 212.4 | 0.43 | |
| 4 | 82.05 | 207.42 | 4731.98 | 4848.53 | 107.91 | 43.76 | 419.6 | 0.84 | |
| 8 | 88.08 | 332.42 | 4938.4 | 5176.46 | 103.44 | 39.03 | 786.99 | 1.61 | |
| 16 | 89.75 | 287.81 | 5270.84 | 5449.96 | 96.31 | 43.92 | 1489.01 | 3.02 | |
| 32 | 105.04 | 242.07 | 6057.48 | 6212.99 | 84.62 | 16.2 | 2557.93 | 5.2 | |
| % Enchancment | 1 | -17.65 | 1.03 | -7 | -5.02 | 3.66 | 2.37 | 6.87 | 6.93 |
| 2 | -25.93 | -25.34 | -7.42 | -8.17 | 6.3 | 0.59 | 8.36 | 8.47 | |
| 4 | -61.27 | -42.24 | -10.1 | -10.43 | 10.04 | 10.1 | 11.07 | 10.88 | |
| 8 | -72.47 | -34.77 | -12.85 | -12.35 | 10.2 | 1.04 | 12.11 | 14.47 | |
| 16 | -83.93 | -58.53 | -17.96 | -20.04 | 12.45 | 22.83 | 20.56 | 22.1 | |
| 32 | -89.82 | -81.13 | -24.81 | -26.79 | 17.59 | -47.37 | 30 | 31.93 |
The next desk exhibits the complete benchmarking metrics for Llama-3.1-8B-Instruct, single mannequin copy, I/O tokens of 1000/250 respectively. Instances are in milliseconds and RPS stands for requests per second.
The next desk exhibits the complete benchmarking metrics for granite-20B-code-base-8K, single mannequin copy, I/O tokens of 2000/500 respectively. Instances are in milliseconds and RPS stands for requests per second.
| Container | Concurrency | TTFT_P50_sec | TTFT_P99_sec | E2E_P50_sec | E2E_P99_sec | OTPS_P50 | OTPS_P99 | Throughput_tokens_sec | RPS |
|---|---|---|---|---|---|---|---|---|---|
| Outdated | 1 | 135.27 | 213.6 | 2526.95 | 2591.58 | 106.12 | 36.84 | 98.43 | 0.39 |
| 2 | 187.01 | 307.35 | 2633.8 | 2795.73 | 102.24 | 37.81 | 189.18 | 0.76 | |
| 4 | 187.41 | 284.01 | 2714.32 | 2917.68 | 99.48 | 35.73 | 366.71 | 1.47 | |
| 8 | 276.33 | 430.2 | 2944.84 | 3080.28 | 94.49 | 36.38 | 674.93 | 2.7 | |
| 16 | 508.86 | 729.68 | 3406.78 | 3647.68 | 86.9 | 35.47 | 1164.12 | 4.66 | |
| 32 | 906.54 | 1129.19 | 4385.52 | 4777.26 | 73.92 | 26.92 | 1792.15 | 7.21 | |
| New | 1 | 72.45 | 188.21 | 2294.31 | 2442.67 | 109.72 | 41.38 | 108.46 | 0.43 |
| 2 | 80.74 | 207.28 | 2353.47 | 2525.61 | 108.86 | 43.97 | 198.58 | 0.84 | |
| 4 | 91.84 | 222.23 | 2393.76 | 2543.41 | 108.1 | 44.75 | 409.74 | 1.64 | |
| 8 | 84.72 | 215.28 | 2493.32 | 2644.12 | 103.93 | 41.34 | 765.04 | 3.14 | |
| 16 | 91.28 | 206.43 | 2644.35 | 2754.45 | 98.11 | 36.65 | 1467.22 | 5.95 | |
| 32 | 92.26 | 329.83 | 3011.46 | 3243.96 | 85.48 | 36.59 | 2582.78 | 10.4 | |
| % Enchancment | 1 | -46.44 | -11.88 | -9.21 | -5.75 | 3.39 | 12.32 | 10.19 | 10.19 |
| 2 | -56.82 | -32.56 | -10.64 | -9.66 | 6.48 | 16.29 | 4.97 | 10.12 | |
| 4 | -51 | -21.75 | -11.81 | -12.83 | 8.66 | 25.26 | 11.73 | 11.73 | |
| 8 | -69.34 | -49.96 | -15.33 | -14.16 | 9.99 | 13.63 | 13.35 | 16.21 | |
| 16 | -82.06 | -71.71 | -22.38 | -24.49 | 12.89 | 3.31 | 26.04 | 27.78 | |
| 32 | -89.82 | -70.79 | -31.33 | -32.1 | 15.64 | 35.95 | 44.12 | 44.11 |
The next desk exhibits the complete benchmarking metrics for Llama-3.1-8B-Instruct, single mannequin copy, I/O tokens of 1000/250 respectively. Instances are in milliseconds and RPS stands for requests per second.
| Container | Concurrency | TTFT_P50_sec | TTFT_P99_sec | E2E_P50_sec | E2E_P99_sec | OTPS_P50 | OTPS_P99 | Throughput_tokens_sec | RPS |
| Outdated | 1 | 258.19 | 294.23 | 11085.06 | 11264.87 | 47.12 | 26.02 | 46.11 | 0.09 |
| 2 | 312.07 | 602.62 | 11339.43 | 11628.22 | 46.41 | 24.51 | 88.36 | 0.18 | |
| 4 | 465.34 | 694.23 | 11600.97 | 11766.2 | 46.23 | 25.05 | 173.9 | 0.34 | |
| 8 | 836.29 | 1270.29 | 12387.4 | 12891.58 | 45.43 | 9.46 | 322.8 | 0.64 | |
| 16 | 1480.41 | 1879.95 | 13732.05 | 13923.09 | 43.01 | 19.96 | 585.75 | 1.17 | |
| 32 | 2532.85 | 3513.06 | 17117.17 | 17674.92 | 37.85 | 9.57 | 949.86 | 1.87 | |
| New | 1 | 132.15 | 253.91 | 9951.79 | 10171.01 | 50.58 | 27.87 | 50.09 | 0.1 |
| 2 | 110.34 | 337.33 | 10124.09 | 10391.73 | 49.94 | 27.8 | 91.72 | 0.2 | |
| 4 | 118.09 | 227.23 | 10023.25 | 10119.27 | 50.33 | 28.02 | 189.9 | 0.42 | |
| 8 | 155.44 | 299.35 | 10286.87 | 10431.96 | 49.18 | 26.09 | 377.21 | 0.83 | |
| 16 | 151.86 | 722.09 | 10632.11 | 11183.4 | 47.64 | 24.09 | 704.44 | 1.51 | |
| 32 | 161.64 | 291.93 | 11633.81 | 11754.09 | 43.78 | 25.25 | 1289.45 | 2.8 | |
| % Enchancment | 1 | -48.82 | -13.71 | -10.22 | -9.71 | 7.35 | 7.09 | 8.63 | 13.93 |
| 2 | -64.64 | -44.02 | -10.72 | -10.63 | 7.62 | 13.41 | 3.79 | 13.6 | |
| 4 | -74.62 | -67.27 | -13.6 | -14 | 8.87 | 11.85 | 9.2 | 21.68 | |
| 8 | -81.41 | -76.43 | -16.96 | -19.08 | 8.25 | 175.82 | 16.86 | 29.2 | |
| 16 | -89.74 | -61.59 | -22.57 | -19.68 | 10.78 | 20.73 | 20.26 | 29.73 | |
| 32 | -93.62 | -91.69 | -32.03 | -33.5 | 15.66 | 163.9 | 35.75 | 49.6 |
The next desk exhibits the complete benchmarking metrics for granite-20B-code-base-8K, single mannequin copy, I/O tokens of 1000/250 respectively. Instances are in milliseconds and RPS stands for requests per second.
| Container | Concurrency | TTFT_P50_sec | TTFT_P99_sec | E2E_P50_sec | E2E_P99_sec | OTPS_P50 | OTPS_P99 | Throughput_tokens_sec | RPS |
|---|---|---|---|---|---|---|---|---|---|
| Outdated | 1 | 202.02 | 501.28 | 11019.77 | 11236.29 | 47.23 | 27.81 | 46.32 | 0.09 |
| 2 | 311.32 | 430.68 | 11351.65 | 11446.29 | 47.25 | 9.15 | 88 | 0.18 | |
| 4 | 316.22 | 773.8 | 11667.41 | 11920.88 | 47.56 | 9.11 | 161.67 | 0.34 | |
| 8 | 799.08 | 1074.4 | 12274.93 | 12436.3 | 45.15 | 22.08 | 328.94 | 0.65 | |
| 16 | 1387.43 | 1919.39 | 13711.78 | 14158.22 | 43.17 | 17.91 | 580.98 | 1.17 | |
| 32 | 2923.09 | 3466.83 | 16948.35 | 17582.53 | 38.29 | 14.34 | 957.06 | 1.89 | |
| New | 1 | 131.05 | 469.14 | 5036.18 | 5392.59 | 50.64 | 26.87 | 49.3 | 0.21 |
| 2 | 116.53 | 266.52 | 5138.18 | 5289.51 | 49.57 | 27.64 | 91.67 | 0.39 | |
| 4 | 121.73 | 297.81 | 5079.28 | 5276.06 | 50.07 | 27.2 | 188.33 | 0.78 | |
| 8 | 114.02 | 296.05 | 5201.04 | 5331.99 | 48.93 | 25.8 | 376.41 | 1.53 | |
| 16 | 115.65 | 491.06 | 5405.52 | 5759.79 | 47.09 | 24.91 | 702.54 | 2.94 | |
| 32 | 126.58 | 372.97 | 5879.65 | 6109.53 | 43.37 | 23.5 | 1296.34 | 5.43 | |
| % Enchancment | 1 | -35.13 | -6.41 | -54.3 | -52.01 | 7.22 | -3.41 | 6.43 | 129.21 |
| 2 | -62.57 | -38.12 | -54.74 | -53.79 | 4.92 | 202.08 | 4.17 | 119.45 | |
| 4 | -61.5 | -61.51 | -56.47 | -55.74 | 5.28 | 198.64 | 16.49 | 128.25 | |
| 8 | -85.73 | -72.44 | -57.63 | -57.13 | 8.36 | 16.83 | 14.43 | 134.13 | |
| 16 | -91.66 | -74.42 | -60.58 | -59.32 | 9.08 | 39.11 | 20.92 | 150.92 | |
| 32 | -95.67 | -89.24 | -65.31 | -65.25 | 13.25 | 63.92 | 35.45 | 186.81 |
Efficiency consistency throughout load situations
These enhancements stay constant throughout totally different concurrency ranges (1-32 concurrent requests), demonstrating the optimization’s effectiveness below various load situations. The decreased latency and elevated throughput allow purposes to serve extra customers with higher response occasions whereas utilizing the identical infrastructure.
The advantages stay constant throughout scaling occasions. When auto-scaling provides new situations to deal with elevated visitors, these situations leverage cached compilation artifacts to ship the identical optimized efficiency. This facilitates constant inference efficiency throughout the situations, sustaining a high-quality person expertise throughout visitors spikes.
Buyer affect
These optimizations enhance efficiency throughout preliminary deployment, scaling, and occasion substitute. The compilation artifact caching makes certain that the efficiency advantages stay constant as new situations are added, with out requiring every occasion to repeat the compilation course of.
Chatbots and AI content material turbines can add capability quicker throughout peak utilization, lowering wait occasions. Improvement groups expertise shorter deployment cycles when updating fashions or testing configurations.
Lowered Time to First Token makes purposes really feel extra responsive. Larger Output Tokens Per Second means you possibly can serve extra customers with current infrastructure. You’ll be able to deal with bigger workloads with out including proportional compute assets.
Quicker occasion initialization makes auto-scaling extra predictable. You’ll be able to preserve efficiency throughout visitors spikes with out over-provisioning.
Conclusion
Amazon Bedrock Customized Mannequin Import now delivers substantial enhancements in inference efficiency via compilation artifact caching and superior optimization methods. These enhancements cut back time-to-first-token, end-to-end latency, and improve throughput with out requiring buyer intervention. The compilation artifact caching system makes certain that efficiency beneficial properties stay constant as your utility scales to fulfill demand.
Current customers can profit instantly. New customers can see enhanced efficiency from their first deployment. To expertise these efficiency enhancements, import your customized fashions to Amazon Bedrock Customized Mannequin Import right now. For implementation steering and supported mannequin architectures, discuss with the Customized Mannequin Import documentation.
Concerning the authors
 Nick McCarthy is a Senior Generative AI Specialist Options Architect on the Amazon Bedrock workforce, targeted on mannequin customization. He has labored with AWS shoppers throughout a variety of industries — together with healthcare, finance, sports activities, telecommunications, and vitality — serving to them speed up enterprise outcomes via the usage of AI and machine studying. Exterior of labor, Nick loves touring, exploring new cuisines, and studying about science and expertise. He holds a Bachelor’s diploma in Physics and a Grasp’s diploma in Machine Studying.
Nick McCarthy is a Senior Generative AI Specialist Options Architect on the Amazon Bedrock workforce, targeted on mannequin customization. He has labored with AWS shoppers throughout a variety of industries — together with healthcare, finance, sports activities, telecommunications, and vitality — serving to them speed up enterprise outcomes via the usage of AI and machine studying. Exterior of labor, Nick loves touring, exploring new cuisines, and studying about science and expertise. He holds a Bachelor’s diploma in Physics and a Grasp’s diploma in Machine Studying.
 Prashant Patel is a Senior Software program Improvement Engineer in AWS Bedrock. He’s captivated with scaling giant language fashions for enterprise purposes. Previous to becoming a member of AWS, he labored at IBM on productionizing large-scale AI/ML workloads on Kubernetes. Prashant has a grasp’s diploma from NYU Tandon College of Engineering. Whereas not at work, he enjoys touring and taking part in together with his canines.
Prashant Patel is a Senior Software program Improvement Engineer in AWS Bedrock. He’s captivated with scaling giant language fashions for enterprise purposes. Previous to becoming a member of AWS, he labored at IBM on productionizing large-scale AI/ML workloads on Kubernetes. Prashant has a grasp’s diploma from NYU Tandon College of Engineering. Whereas not at work, he enjoys touring and taking part in together with his canines.
 Yashowardhan Shinde is a Software program Improvement Engineer captivated with fixing advanced engineering challenges in giant language mannequin (LLM) inference and coaching, with a concentrate on infrastructure and optimization. He has labored throughout business and analysis settings, contributing to constructing scalable GenAI methods. Yashowardhan has a grasp’s diploma in Machine Studying from the College of California, San Diego. Exterior of labor, he enjoys touring, attempting out new meals, and taking part in soccer.
Yashowardhan Shinde is a Software program Improvement Engineer captivated with fixing advanced engineering challenges in giant language mannequin (LLM) inference and coaching, with a concentrate on infrastructure and optimization. He has labored throughout business and analysis settings, contributing to constructing scalable GenAI methods. Yashowardhan has a grasp’s diploma in Machine Studying from the College of California, San Diego. Exterior of labor, he enjoys touring, attempting out new meals, and taking part in soccer.
 Yanyan Zhang is a Senior Generative AI Knowledge Scientist at Amazon Internet Providers, the place she has been engaged on cutting-edge AI/ML applied sciences as a Generative AI Specialist, serving to clients use generative AI to attain their desired outcomes. Yanyan graduated from Texas A&M College with a PhD in Electrical Engineering. Exterior of labor, she loves touring, figuring out, and exploring new issues.
Yanyan Zhang is a Senior Generative AI Knowledge Scientist at Amazon Internet Providers, the place she has been engaged on cutting-edge AI/ML applied sciences as a Generative AI Specialist, serving to clients use generative AI to attain their desired outcomes. Yanyan graduated from Texas A&M College with a PhD in Electrical Engineering. Exterior of labor, she loves touring, figuring out, and exploring new issues.



{kind=link}